GooseFS 在云端数据湖存储上的降本增效实践
Posted 腾讯云开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GooseFS 在云端数据湖存储上的降本增效实践相关的知识,希望对你有一定的参考价值。

导语 | 本文推选自腾讯云开发者社区-【技思广益 · 腾讯技术人原创集】专栏。该专栏是腾讯云开发者社区为腾讯技术人与广泛开发者打造的分享交流窗口。栏目邀约腾讯技术人分享原创的技术积淀,与广泛开发者互启迪共成长。本文作者是腾讯高级工程师于飏。
基于云端对象存储的大数据和数据湖存算分离场景已经被广泛铺开,计算节点的独立扩缩容极大地优化了系统的整体运行和维护成本,云端对象存储的无限容量与高吞吐也保证了计算任务的高效和稳定。然而,云端存算分离架构也面临数据本地性、网络吞吐与带宽成本等问题。因此,腾讯云对象存储研发团队进一步演进了近客户侧的加速存储系统GooseFS用以解决上述问题。本文将通过一个独特新颖的客户实践来着重介绍使用GooseFS对有大数据/数据湖业务平台的降本增效。

前言
GooseFS是腾讯云对象存储团队面向下一代云原生数据湖场景推出的存储加速利器,提供与HDFS对标的Hadoop Compatible FileSystem接口实现,旨在解决存算分离架构下的云端大数据/数据湖平台所面临的查询性能瓶颈和网络读写带宽成本等问题。使得基于腾讯云COS/CHDFS的大数据/数据湖平台在现有生产集群上获得等同甚至超越本地HDFS性能的计算体验。其设计应用场景如下:

图 1 GooseFS 预期的应用场景
经过一年多的打磨,目前已经稳定承载了多家云端大数据/数据湖平台客户的超大规模查询效能提升以及原有带宽成本的优化。单个客户查询效能提升峰值达到46%,同时后端带宽峰值下降了200Gbps。
本文将着重介绍某音乐类大客户通过使用GooseFS提升其大数据业务效能,从而相应缩减计算资源的实践来归纳GooseFS在云端大数据/数据湖平台的降本增效上的关键作用。

GooseFS核心架构首先,我们先来看一下GooseFS的核心架构设计,采用了与传统主-从式的本地HDFS架构一致的分布式内存文件系统设计方案,数据的持久化托管给底层存储系统(Under File System),默认支持腾讯云COS/CHDFS作为云端UFS。默认所有的写入操作都会持久化到UFS上以保证数据可靠性,而所有的读取操作,都会尽力从缓存中存取以加速读取效能。
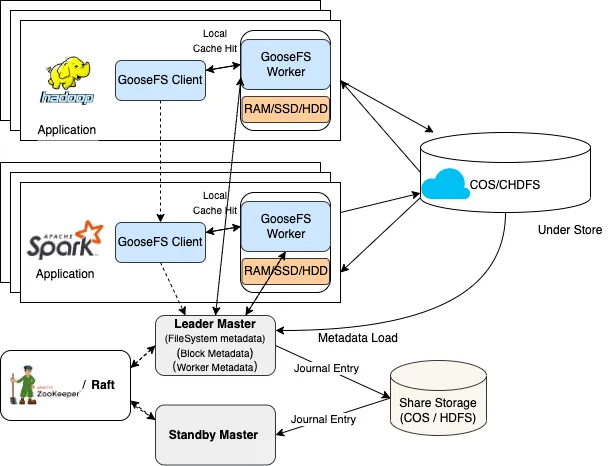
图 2 GooseFS 核心架构
(一)云端数据的本地加速缓存
所有被访问到云端数据都会被缓存到GooseFS的Worker节点中,Worker 节点本身支持多级存储介质:RAM(内存RamDisk)、SSD以及HDD,支持不同层级存储介质之间的Quota配置,用户可以合理地组合集群上的闲置存储介质以达到性能和计算成本的最优。
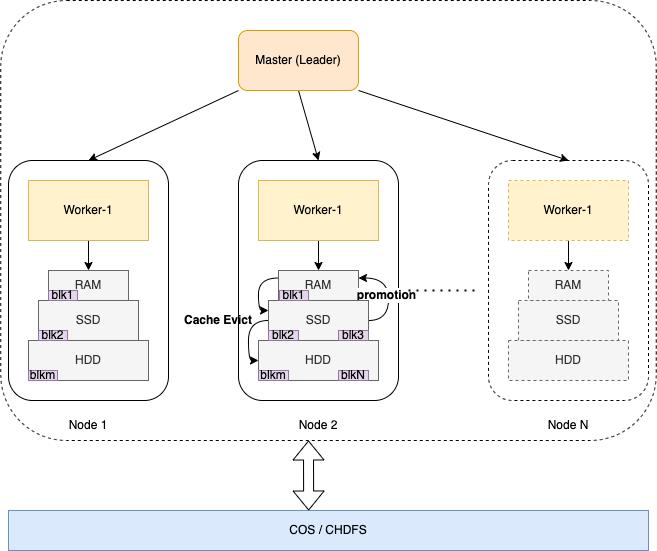
图 3 GooseFS Worker 的多层存储介质
缓存数据块支持在多级存储介质之间流转,GooseFS内部支持多种缓存块的管理策略,其中包括LRU、LRFU以及PartialLRU等。用户根据实际业务场景合理配置集群存储介质以及缓存块的管理策略后,可以在访问性能和资源成本上取得明显优于本地HDFS的成绩。
GooseFS的HCFS文件系统层实现了getFileBlockLocations方法来获得一个文件待读取块的位置信息,因此,GooseFS跟本地HDFS可以支持上层计算系统的数据本地化调度。在Hadoop MapReduce/Spark等计算系统中均可以支持将计算任务移动到里待读数据块最近的位置来读取。
为了实现数据本地读取的最大效能,GooseFS支持了短路度读的能力,能够让计算Task从本机读取数据时,能够省掉RPC通信调用带来的性能损耗,而直接获得读取本地文件的效能(如果Block在RamDisk中甚至可获得近内存级的访问时延)。
同样,GooseFS的Block支持配置副本数,让用户可以在存取性能和缓存利用率上取得最优的配比。即使计算Task存在跨节点的读取(图2中remote cache hit),用户依然这个流程中能够获得近似持平于本地HDFS的访问性能。同时,GooseFS研发团队也在基于Zero Copy协议相关的技术开发跨节点读取的Remote DMA访存特性,届时,GooseFS在整个数据访问上将全部取得近似于本机Cache命中的性能体验。
(二)10亿级以上海量元数据支持
我们都知道,在HDFS中Namenode节点在支撑海量元数据上存在比较大的内存压力。GooseFS则使用了RocksDB嵌入式的本地KV存储扩展了Master节点的元数据管理能力,同时GooseFS在RocksDB的使用上支持了多种元数据层面的淘汰算法,例如LRU等,可以配合特定场景使用。

图 4 GooseFS Master 配合 RocksDB 扩展元数据存储的架构
被频繁访问到的文件和目录的元数据会尽力存放到HEAP内存中,以获得足够低的延迟。但是,对于超过HEAP Quota配置的Inode和Edge(还包含其他BlockLocations等)会被降级到RocksDB的本地磁盘上(InodeTable 和EdgeTable中)。再次被访问的时候的,也会采用双区查找的方式来取出元数据。在实际生产环境中,我们配合了本地NVME SSD磁盘作为扩展MetaStore时,再配合良好的Evict算法使用,取得了近似于纯HEAP内存管理的性能体验。
目前,GooseFS自身产品压测已经到了10亿文件数目,实际客户生产环境中也稳定支撑超过了3亿小文件加速缓存的机器学习训练业务。
(三)GooseFS高可用性(High availability)
GooseFS的高可用主要是基于zookeeper和raft两种方式实现:
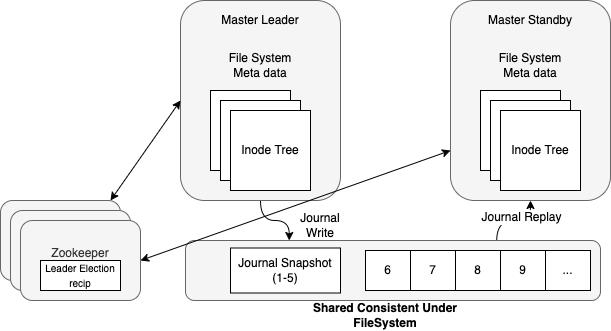
图 5 GooseFS 基于 Zookeeper 的 HA 架构
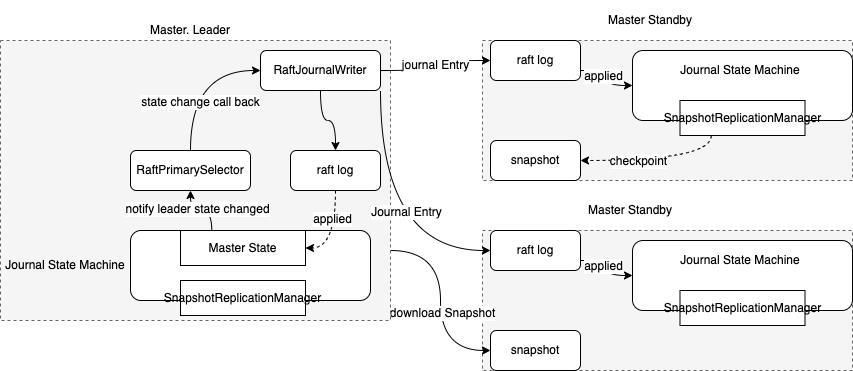
图 6 GooseFS 基于 Raft 的 HA 架构
Zookeeper的HA架构需要引入强一致的共享底层存储作为主备节点的Journal传递,这里一般选用HDFS作为Journal UFS。如果是完全的存算分离平台,则建议直接可以使用CHDFS或者CosN作为Shared Journal UFS。(需要注意的是,使用CHDFS时需要开启fs.ofs.upload.flush.flag选项以支持同步刷盘,同样,使用CosN时需要开启fs.cosn.posix_extension.enabled选项以支持POSIX的Flush Visibility语义。)
Raft架构则不需要额外的共享组件,只需要保证在Raft Group内节点的 9202端口能够正常通信即可,同时自治域中的节点数为奇数个即可。基于Raft的HA架构可以不用引入任何第三方组件即可完成主从自治,非常适合于无任何大数据相关依赖的独立加速场景,如基于Fuse接口的机器学习训练场景等。
在上述基础架构之上,GooseFS还良好地支持了大规模DistributedLoad和Hive Table/Partition的管理,用户的可将Hive DB和Table挂载到GooseFS上,然后按照Hive Table和Partition维度对需要访问的热数据做预热,这项特性极大地方便了用户按照业务特征来管理整个数据缓存。

图 7 GooseFS Hive Table/Partition 管理架构
除了上述基础特性以外,GooseFS在产品易用性上支持Namespace缓存策略管理能力,基于Namespace的透明加速能力及其一键热开关、Kerberos/Ranger以及云原生的日志和监控告警等。
下文就将基于某音乐类大客户的大数据平台为例介绍GooseFS如何助力其降本增效KPI的完成。

某音乐大客户的大数据平台案例
(一)业务需求
在我们的存量大数据存储客户中,有一家音乐大客户使用COS/CHDFS作为其BI数仓平台的底层存储,承载其用户访问行为流水查询和分析、用户画像以及推荐相关的业务场景,系统的整体架构大致如下:
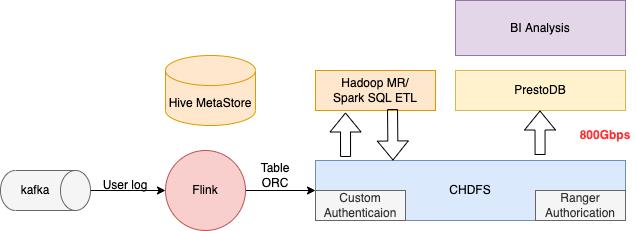
图 8 客户的数仓平台架构
目前,该客户场景对于腾讯云存储团队来说面临一个很大的挑战:快速增长的业务量带来了数据下行带宽的快速增长,客户侧的数据访问峰值已经达到了700Gbps,与承诺800Gbps接近了。然而,客户侧还希望继续加大读取带宽,使得计算任务能够如期完成的同时,帮助他们缩减相应的计算资源成本。
我们在分析了客户的业务场景后,发现其PrestoDB的数仓平台是任务当中 IO密集性比较明显的一块业务。Spark SQL做ETL那块也会存在一定的IO访问量,不过主要性能瓶颈点并不在IO上。同时,我们发现客户使用IT5集群上有大量闲置的NVME SSD的磁盘资源,总计大约有500TB左右,足以存放其近期需要高频访问的热数据。
因此,我们建议客户引入GooseFS作为其云端存储的加速缓存层,利用其闲置的NVME SSD的磁盘资源进行混合部署。如果能够加速IO密集型的Task,那么就能够缩短整个计算Job的执行时间,从而帮助他们达到保证计算响应的同时,相应的缩减计算资源成本。
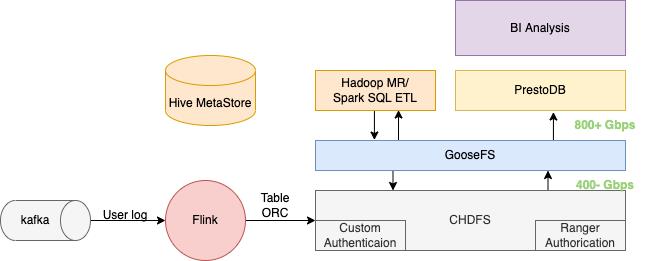
图 9 引入 GooseFS 作为本地加速缓存层
同时,由于热数据大多缓存到了GooseFS中,因此极大地降低GooseFS的带宽负载,达到一举两得的目的。
但是,我们需要解决如下三个问题:
- 如何让用户不做任何改动的引入GooseFS。同时,如果GooseFS故障能否切换到底层存储UFS,而不影响业务的访问体验。
- 如何防止首次查询带来的下行访问峰值,否则对于后端减负就没有意义。
- 如何尽可能地提高缓存资源的利用率。
以下,我们将针对上述问题,分别阐述GooseFS的解决方案。
(二)透明加速以及故障转移
为了解决用户不做任何改动引入GooseFS加速缓存层的需求,我们开发了透明加速能力,为用户提供了一种可以的无感利用GooseFS加速底层存储系统(UFS)访问的能力,即使用户业务代码中原先使用cosn://bucket-appid/object_path或ofs://mountid/file_path,只需要将原先依赖的CosN或者CHDFS HCFS实现改成依赖GooseFS的HCFS client即可实现不用更改任何业务路径,直接使用GooseFS加速对应的底层存储访问。
透明加速的特性的整体设计如下:

图 10 透明加速的整体设计方案
在GooseFS 的HCFS客户端上,我们实现了一个AbstractCompatibleFileSystem来对接多个底层存储系统的HCFS实现,同样它也继承于GooseFS自身的HCFS实现类。当底层文件的访问URI传入进来后,这个CompatibleFileSystem就可以根据GooseFS Namespace 中的挂载映射关系找到对应的GooseFS路径访问。那么,这里会有一个问题:如果访问的UFS路径没有在GooseFS路径中,应该如何处理呢?
这里我们采用了配置可选项的方式,通过指定透明加速的scope范围(提供了GFS/GFS_UFS两种scope),那么在超出Namespace挂载路径范围外的请求,会直接通过调用UFS的HCFS接口来代理访问请求,这就相当于跟原先的裸UFS使用方式完全一致。如果请求的是Namespace挂载的位置,那么就会通过GooseFS加速整个UFS访问请求。
在此基础上,我们甚至开发了自动和手动切换两种方式的故障转移逻辑。其中手动切换,可以在不重启任何业务组件的前提下,运维同学一键热开关切换到UFS上访问,其主要是依赖于监听客户端配置变化来实现。针对自动化运维场景,我们开发了自动降级访问的逻辑来应对:
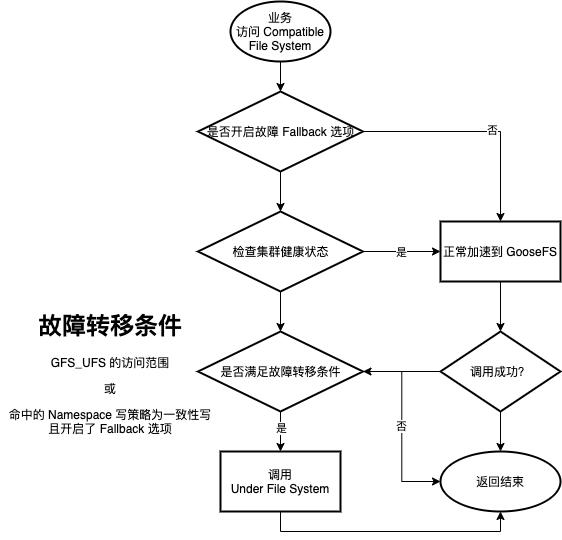
图 11 透明加速的故障转移逻辑
至此,这个特性就很好地满足了客户希望完全不改变当前的存储访问方式,透明地解决上述问题的需求。
实际的生产环境中,客户将透明加速的scope设置为GFS_UFS,然后将对应的Hive DB或Table挂载到GooseFS的namespace上来灰度迁移业务到GooseFS中做加速。若遇到问题,也会使用故障转移逻辑做自动容错,待故障排除后,再人工开启热开关切换回来。
(三)Distributed Load预热与Hive Table/Partition管理
针对于首次访问可能会对后端带来的带宽峰值冲击,我们采用了 DistributedLoad(控制并行Load数目)+Qos(后端)的控制访问,用户可在闲时将需要访问热表数据提前预热到GooseFS中,在需要访问时就可以取到极高访问带宽:
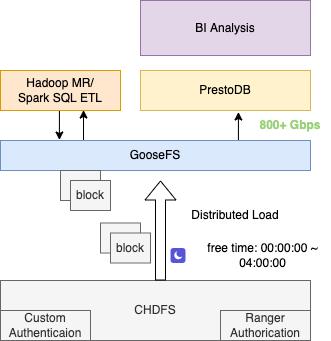
图 12 热数据的闲时预热方式
这里GooseFS的Distributed Load使用了独立于GooseFS基础架构中 Master和Worker之外的JobMaster和JobWorker外围架构来完成这种异步任务:
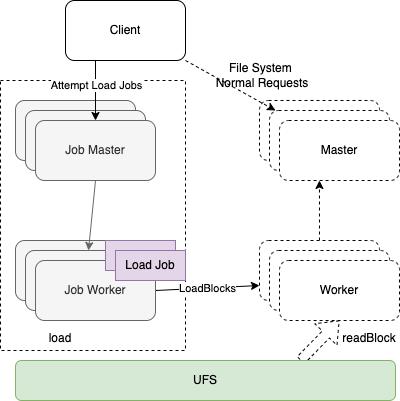
图 13 DistributedLoad 架构
所有的Load作业均有异步方式独立运行在Job Server上,所以几乎不会给缓存层的Master和Worker带来负担。同时,并行运行的Load任务数可自由控制,这样就合理地控制机器资源占用与需求时间。
目前,客户会基于工作流调度在闲时使用 DistributedLoad 命令提前预热第二天需要分析的热表数据以此达到首次访问比较好的命中率:

图 14 客户实际生产的 GooseFS 命中率
同时,客户引入了Hive Table/Partition管理架构(如图6 所示)以方便地管理需要预热的表和分区数据,客户不再关心具体需要预热哪些路径,而是直接按照Hive Table/Partition的维度来预热数据。
(四)asyncCache与索引数据文件的处理
GooseFS默认会开启asyncCache流程,当读取某个文件时,会异步地缓存命中的block块上来。但是这个带来了极大的读放大以及缓存容量的浪费,尤其是以ORC和Parquet为代表的索引数据文件会产生小块的随机读,如下图所示:
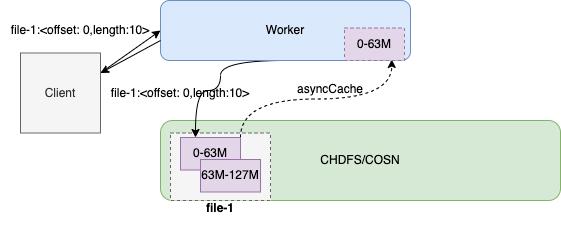
图 15 读取流程中 asyncCache Block 的流程
但是,关闭GooseFS的asyncCache流程后,对于,ORC和Parquet两种文件始终无法缓存到GooseFS中。因此这块在客户的实际环境中做了一个折中。针对于Parquet和ORC等索引文件(通过识别文件类型),让它能够在首次读取时,仍然缓存命中的块,其他类型文件均需要使用遵循asyncCache的开关规则控制。
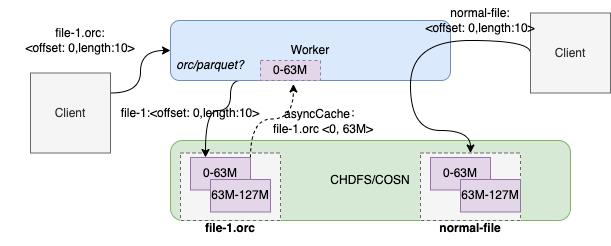
图 15(2) 读取流程中 asyncCache Block 的流程
这样可以有效平衡读放大与索引文件随机读场景下的缓存命中率的矛盾。
(五)实际生产效果
目前,该客户已经混合部署了超过200个节点规模的GooseFS作为其数仓/数据湖业务的加速缓存,累计缓存近千万文件数目:
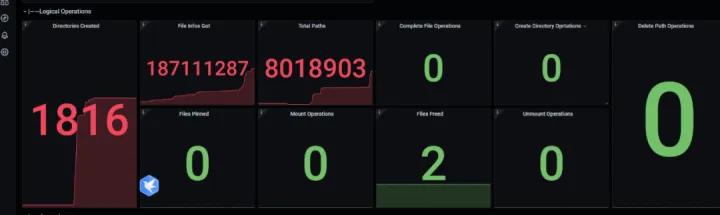
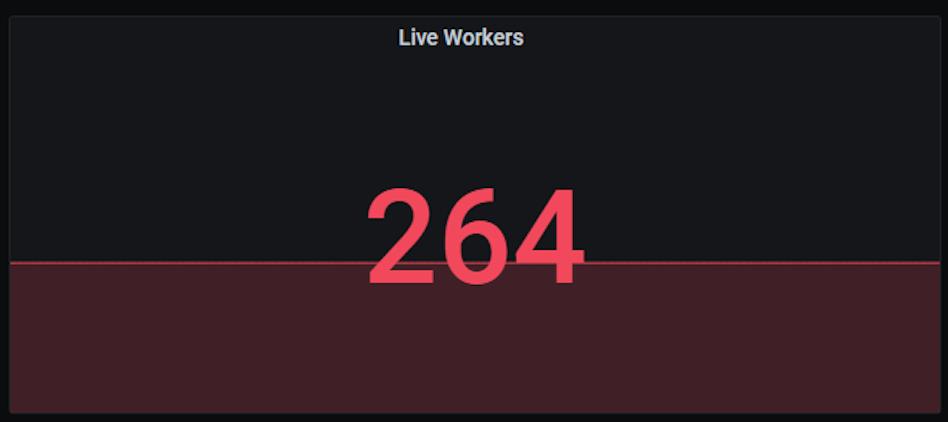
图 16 客户生产环境的缓存文件数目和 Live Workers 监控
- Presto SQL查询性能的提升
在客户的实际生产中,抽查单个Presto SQL Query的读取带宽从最初的 34.6 Gbps提升到了50.6 Gbps的读取带宽,下图为客户生产环境的实际查询截图:
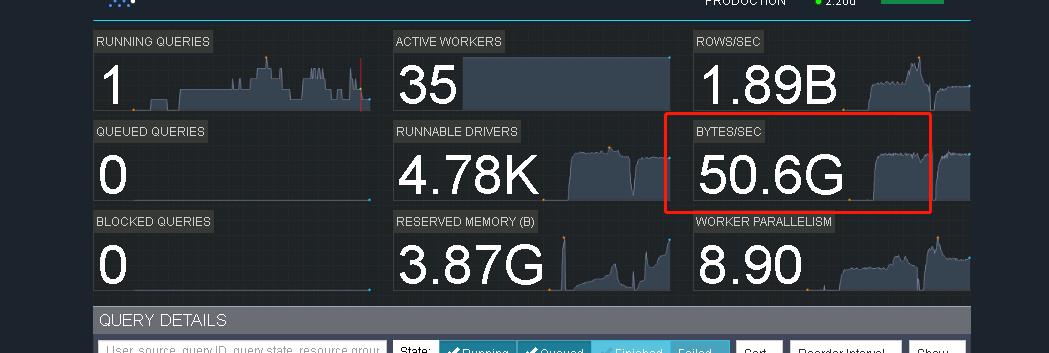
图 17 客户生产环境 Presto 任务读取带宽
以下是可视化的对比:
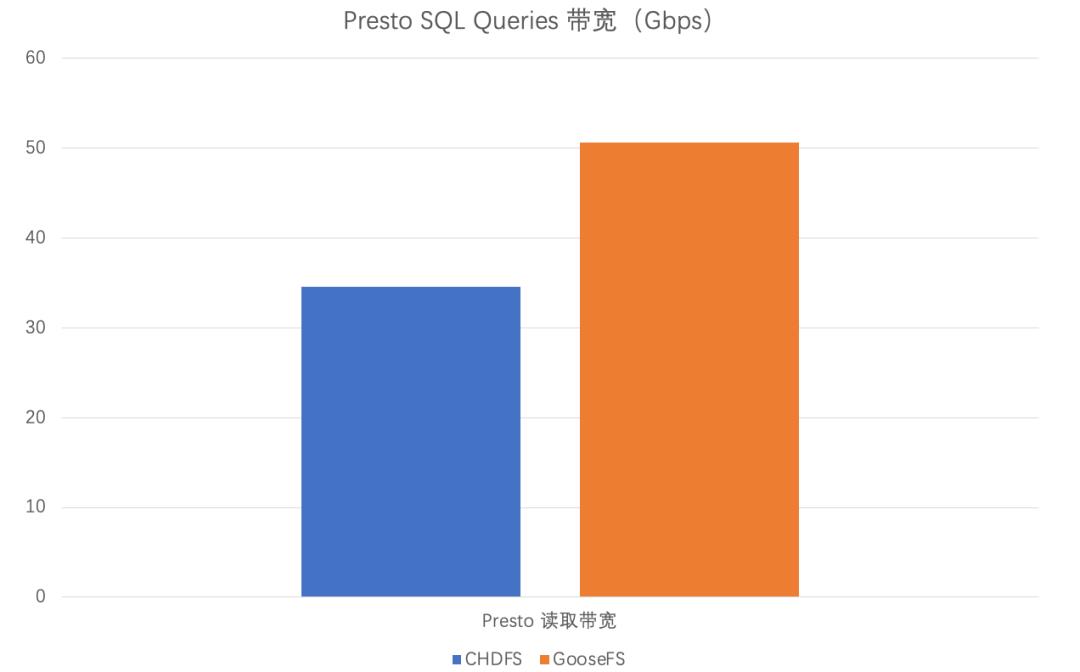
图 18 单个大查询的 Presto 读取带宽的提升对比
在读取带宽层面来看,整体查询性能提升了约46%的性能。
客户侧成本优化
客户侧通过统计了YARN container的memorySeconds的消耗,来估算了整体资源利用率的提升。下面的表格是memorySeconds(GooseFS) - memorySeconds(UFS) 的百分比,即使在IO密集型特征的计算任务中GooseFS最多也可节省约8.06%资源消耗。

图 19 YARN 的 MemorySeconds 资源消耗
统计这部分业务,用户可根据实际情况缩减5%~8%的计算节点成本。
- 带宽成本降低
在采用GooseFS之前的云内网下行带宽峰值维持在接近700 Gbps:

图 20 客户在部署 GooseFS 之前访问 COS 数据的内网总下行带宽监控(包含其他业务)
在采用了GooseFS之后,云内网下行带宽峰值已经降低到了400Gbps左右:

图 21 客户在部署 GooseFS 之后访问 COS 数据的内网下行带宽监控(包含其他业务)
需要说明的是,上述带宽是该客户的所有业务带宽,因此采用GooseFS的业务带宽降低可能会比上述结果还要多。即使如此,整体带宽成本也缩减了42%以上。

GooseFS安全
原先客户环境依赖的CHDFS采用了自定义身份认证方案以及Ranger鉴权,GooseFS可无缝地接入UFS的认证和鉴权:
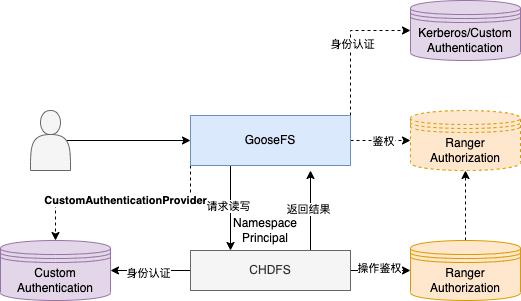
GooseFS实际会将GooseFS Namespace创建者Principal带给存储系统做身份认证,同时配合请求操作的UFS路径借助Ranger完成鉴权。
这里值得注意的是:
目前,GooseFS还无法直接将客户端的身份信息直接带给UFS做认证和鉴权,因此,这里只能向下传入Namespace创建者的身份信息。那么这里是否就不能做访问和权限管控了呢?答案是否定。
针对于身份认证,我们针对客户实现了自定义 CustomAuthenticationProvider对接到UFS 上的 CustomAuthentication 模块。而针对Ranger鉴权,由于UFS的 Ranger Policy的格式大不相同,因此当前只能定制Policy同步工具来做转换。在客户生产实践中,用户还是采用了单独配置GooseFS Ranger Policy的使用方式;另外,GooseFS新版本中也提供了完整Kerberos标准认证机制,届时有需求的用户也可依赖于此完成身份认证。

总结
客户采用了GooseFS加速CHDFS的方案后,在Presto SQL的数仓分析业务上提升了超过46%性能,Spark SQL ETL的YARN memorySeconds的资源消耗可缩减5%~8%计算节点成本,同时由于GooseFS全程利用的是原有计算集群上空闲的SSD磁盘,而除去Master节点外,其余Worker节点的CPU和内存消耗量较低,因此,GooseFS基本不会给客户带来额外的成本消耗,可以名副其实承担起大数据平台降本增效的利器。

未来工作
目前,GooseFS还在不断地优化打磨中,在身份认证方式上将会拓展支持除 Kerberos和自定义认证以外的更多标准认证方式,在海量元数据管理上将会不断地优化Master节点的内存消耗以及所能支撑的文件数目,同时还会完善缓存与UFS之间的数据生命周期管理策略,帮助客户更好地优化成本支出。
在数据湖批流一体场景下,GooseFS会针对Iceberg、Hudi等格式做适配支持,同时还会探索更多的Catalog管理能力。
在文件系统语义支持上,会重点完善POSIX文件系统接口支持,支撑除Hadoop生态以外的更多业务场景。针对高性能计算业务,GooseFS也会基于Zero Copy技术推出超高IOPS和极低数据访问延时的能力等。
如果你是腾讯技术内容创作者,腾讯云开发者社区诚邀您加入【腾讯云原创分享计划】,领取礼品,助力职级晋升。
以上是关于GooseFS 在云端数据湖存储上的降本增效实践的主要内容,如果未能解决你的问题,请参考以下文章