Spark编程题
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark编程题相关的知识,希望对你有一定的参考价值。
参考技术A 现有100W+条数据存储在hdfs中的userinfo文件夹中的多个文件中,数据格式如下:张三|男|23|未婚|北京|海淀
李四|女|25|已婚|河北|石家庄
求:
1.数据中所有人的平均年龄
2.数据中所有男性未婚的人数和女性未婚人数
3.数据中20-30已婚数量前3的省份
答案:
package spark08
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.SparkConf, SparkContext
/**
*张三|男|23|未婚|北京|海淀
*李四|女|25|已婚|河北|石家庄
*
*统计:
* 1.数据中所有人的平均年龄
* 2.数据中所有男性未婚的人数和女性未婚人数
* 3.数据中20-30已婚数量前3的省份
* 4.未婚比例(未婚人数/该城市总人数)最高的前3个城市
*/
object UserInfo
def main(args: Array[String]): Unit =
val conf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName)
.setMaster("local[*]")
val sc = new SparkContext(conf)
//读取原始文件
val strFile: RDD[String] = sc.textFile("D:\\data\\data\\userinfo")
val srcRdd: RDD[(String, String, Int, String, String, String)] = strFile.map(t =>
val strings: Array[String] = t.split("\\|")
val name: String = strings(0)
val gender = strings(1)
val age = strings(2).toInt
val isMarry: String = strings(3)
val province = strings(4)
val city = strings(5)
(name, gender, age, isMarry, province, city)
)
srcRdd.cache()
//1.数据中所有人的平均年龄 李四|女|25|已婚|河北|石家庄
val ageAccumulator: LongAccumulator = sc.longAccumulator //使用累加器统计总人数
val ageCount: Int = srcRdd.map(t =>
ageAccumulator.add(1)
t._3
).reduce(_ + _)
val ageNumber = ageAccumulator.value
val avgAge = ageCount.toLong/(ageNumber*1.0)
println(s"所有人的平均年龄为$avgAge")
//2.数据中所有男性未婚的人数和女性未婚人数
val genderAndMarryRDD: RDD[(String, Iterable[(String, String)])] = srcRdd.map(t =>
(t._1, t._3) //性别,婚否
).filter(_._2.equals("未婚")).groupBy(_._1) //按性别分组
val res2RDD: RDD[(String, Int)] = genderAndMarryRDD.mapValues(t=>t.size)
res2RDD.collect().foreach(println)
//数据中20-30已婚数量前3的省份 李四|女|25|已婚|河北|石家庄
val res3: Array[(Int, String)] = srcRdd.filter(t =>
t._3 >= 20 && t._3 <= 30 && t._4.equals("已婚")
)//删选出满足20-30已婚的数据,按省份分组,求v的size即是20-30已婚数量
.groupBy(_._5).mapValues(_.size)
//k,v互换取前3
.map(t => (t._2, t._1)).top(3)
res3.foreach(println)
//(城市,(未婚人数,已婚人数))
//未婚比例(未婚人数/该城市总人数)最高的前3个城市 李四|女|25|已婚|河北|石家庄
Spark & Scala scala编程案例:统计学生成绩
Scala 统计学生成绩
题干
学生的成绩清单格式如下所示,第一行为表头,各字段意思分别为学号、性别、课程名 1、课程名 2 等,后面每一行代表一个学生的信息,各字段之间用空白符隔开
Id gender Math English Physics
301610 male 80 64 78
301611 female 65 87 58
…
给定任何一个如上格式的清单(不同清单里课程数量可能不一样),要求尽可能采用函 数式编程,统计出各门课程的平均成绩,最低成绩,和最高成绩;另外还需按男女同学分开, 分别统计各门课程的平均成绩,最低成绩,和最高成绩。
源代码(命令台交互式)
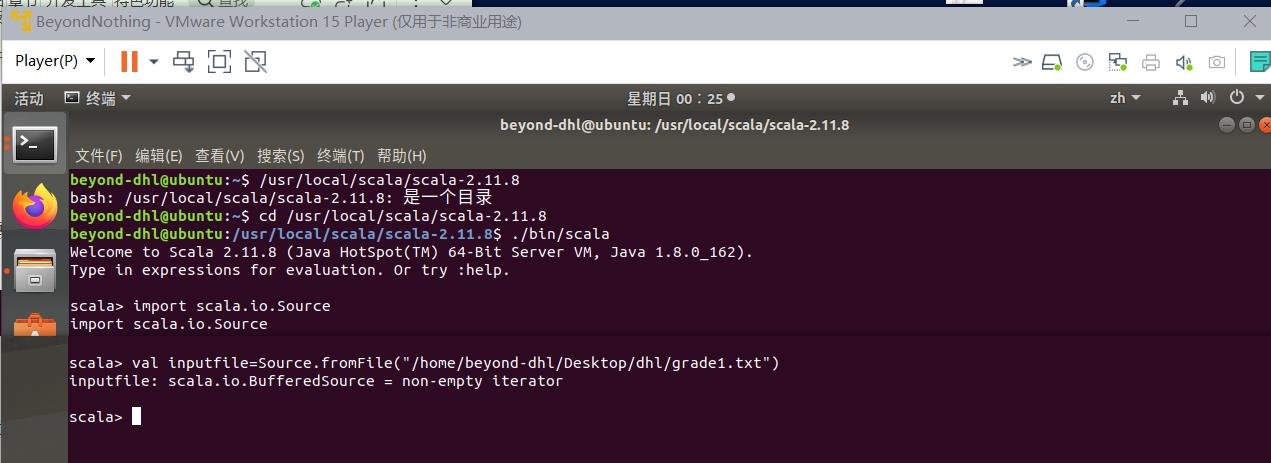
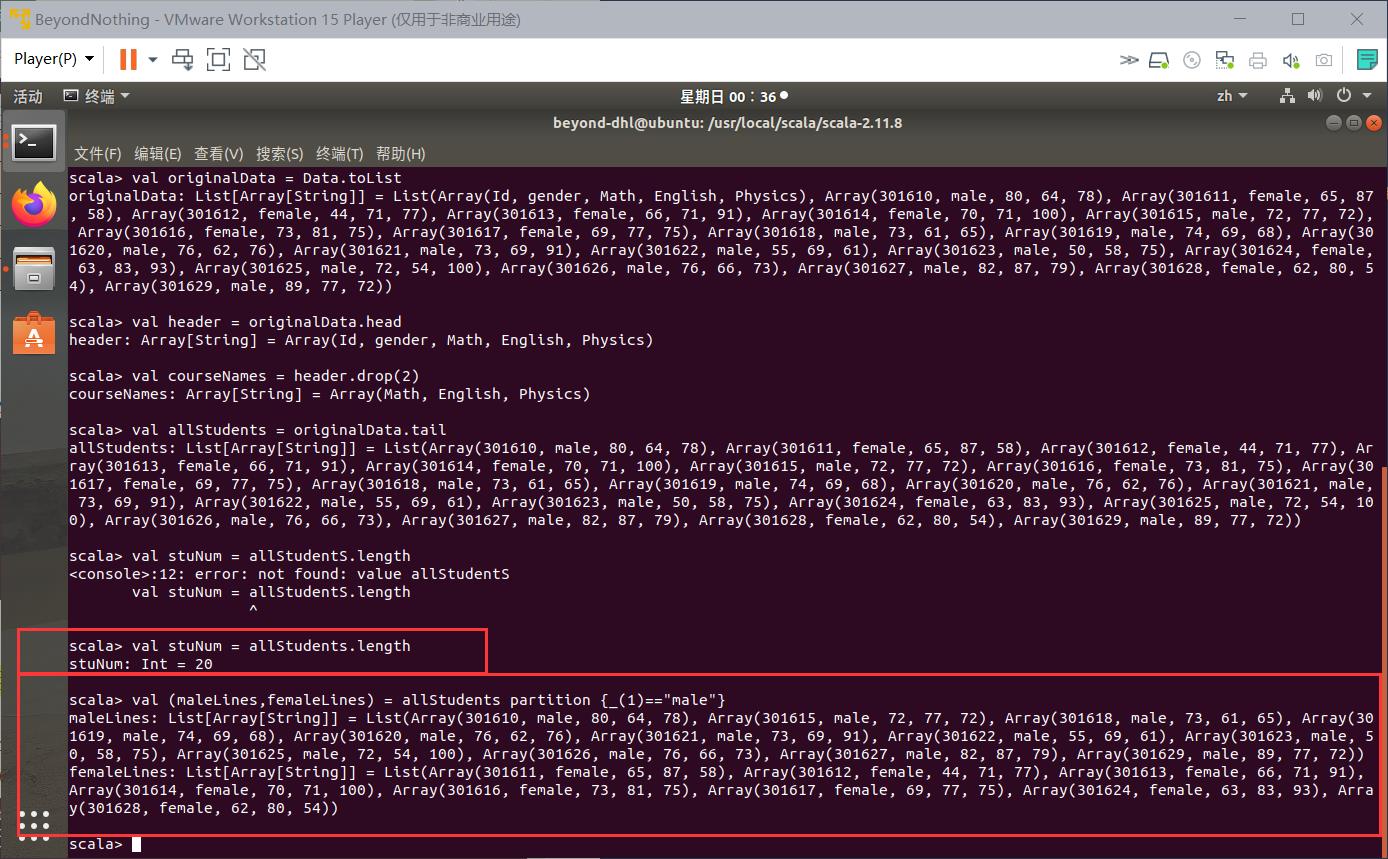
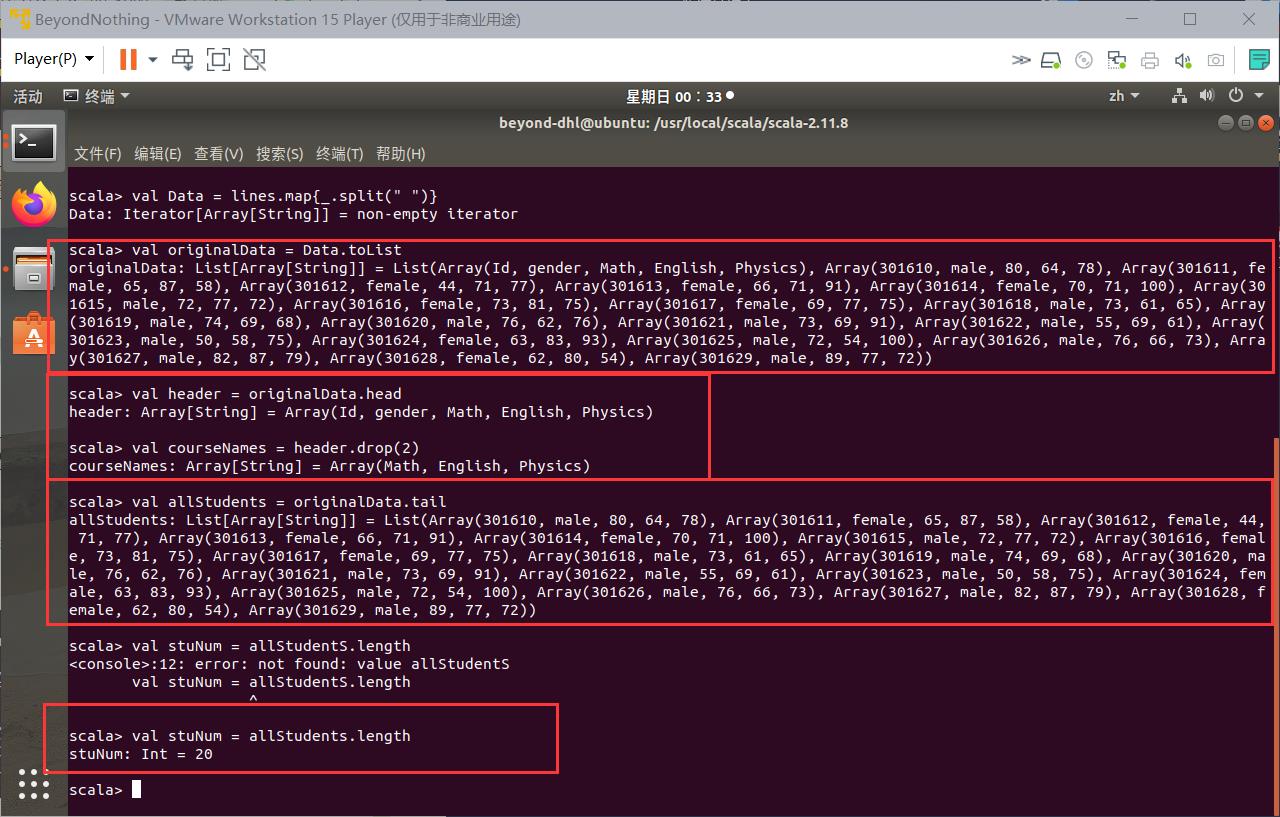
import scala.io.Source
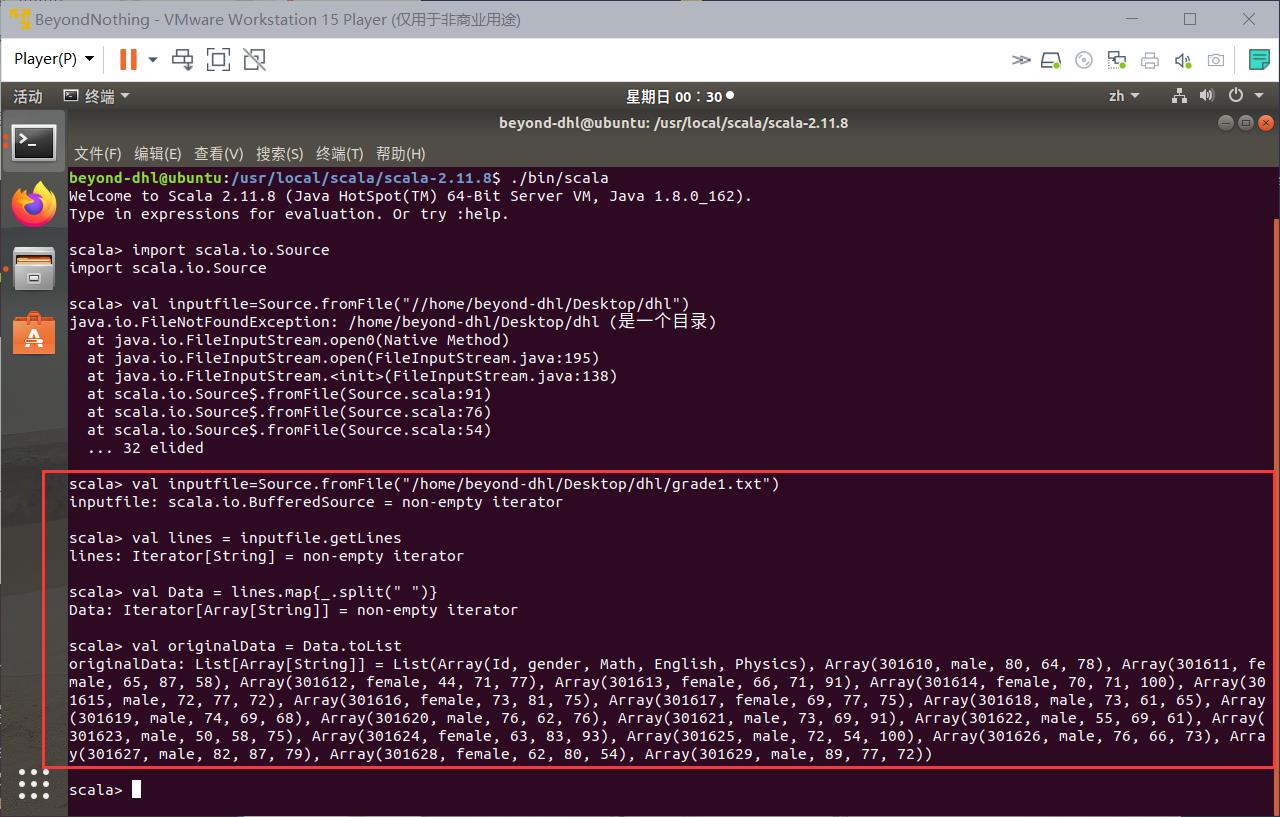
val inputfile=Source.fromFile("/home/beyond-dhl/Desktop/dhl/grade1.txt")
val lines = inputfile.getLines
val Data = lines.map_.split(" ")
val header = originalData.head
val courseNames = header.drop(2)
val allStudents = originalData.tail
val stuNum = allStudents.length
val (maleLines,femaleLines) = allStudents partition _(1)=="male"
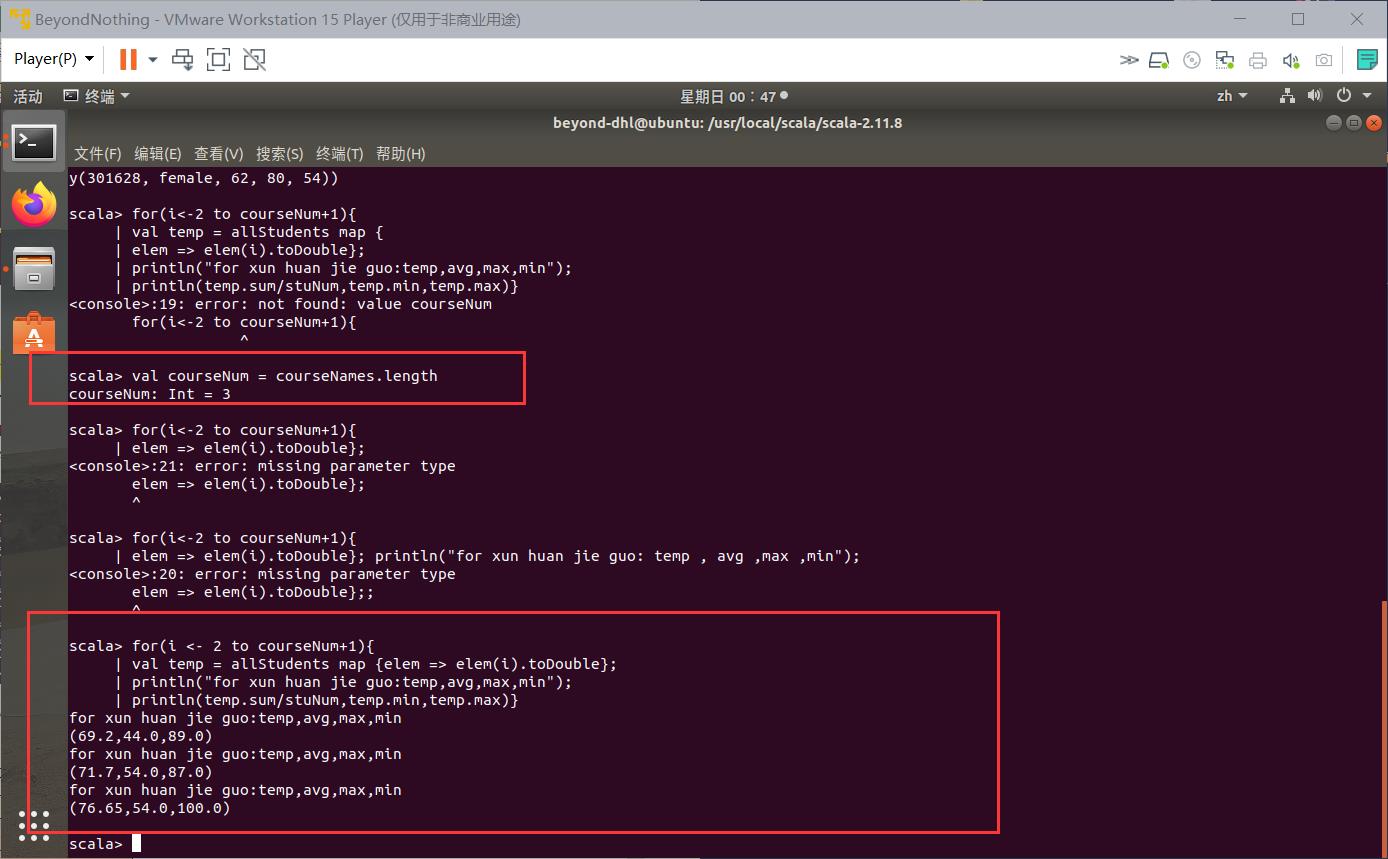
val courseNum = courseNames.length
for(i <- 2 to courseNum+1)
| val temp = allStudents map elem => elem(i).toDouble;
| println("for xun huan jie guo:temp,avg,max,min");
| println(temp.sum/stuNum,temp.min,temp.max)
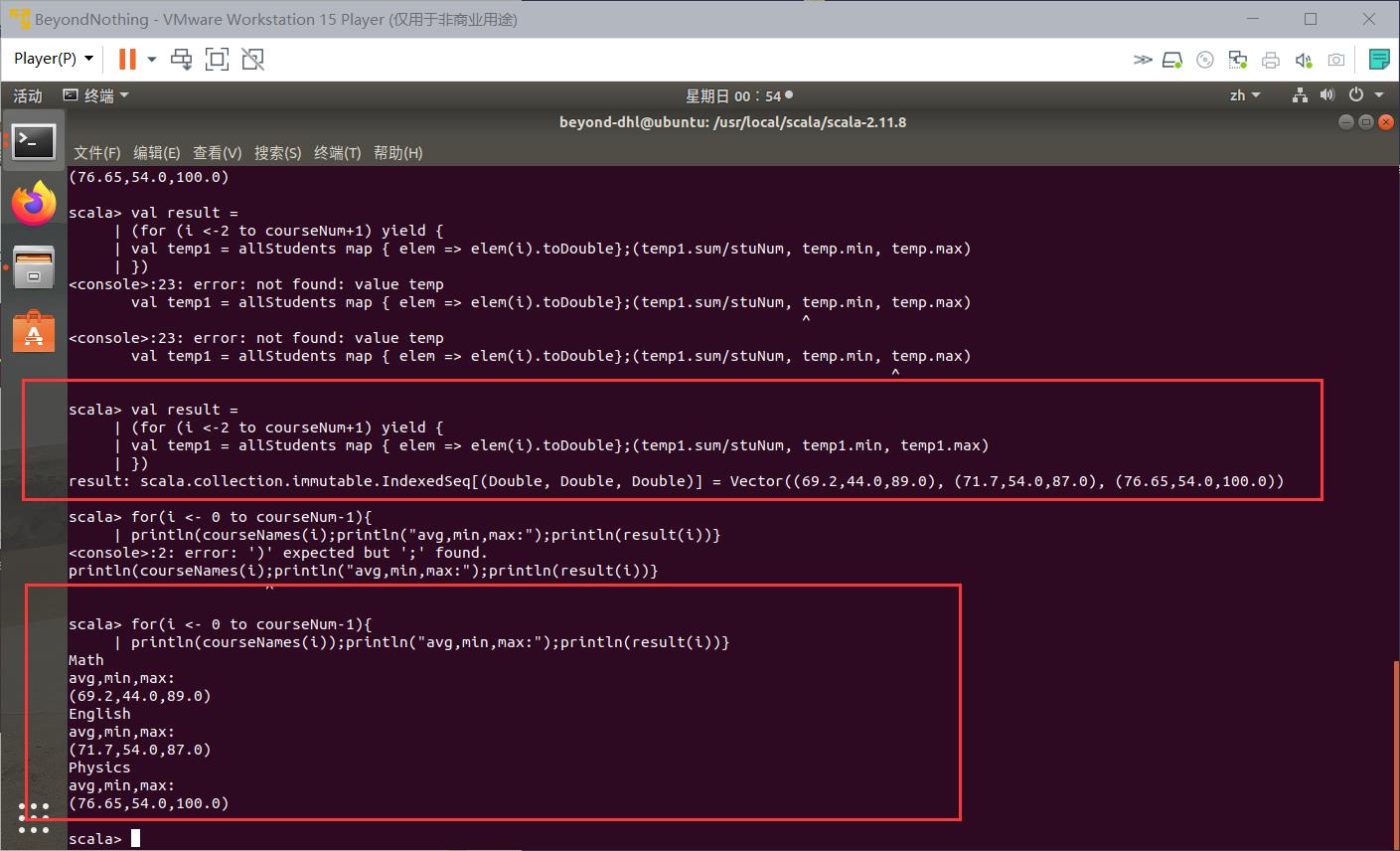
val result =
| (for (i <-2 to courseNum+1) yield
| val temp1 = allStudents map elem => elem(i).toDouble;(temp1.sum/stuNum, temp1.min, temp1.max)
| )
for(i <- 0 to courseNum-1)
| println(courseNames(i));println("avg,min,max:");println(result(i))
相应结果
以上是关于Spark编程题的主要内容,如果未能解决你的问题,请参考以下文章