大数据计算 Spark的安装和基础编程
Posted 小生凡一
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据计算 Spark的安装和基础编程相关的知识,希望对你有一定的参考价值。
文章目录
1. 使用Spark Sell编写代码
1.1启动Spark Shell
- 启动
spark先要先启动hdfs

- 打开spark-shell
./bin/spark-shell
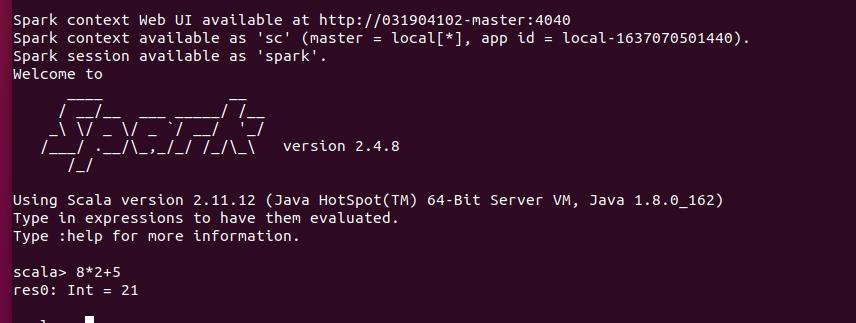
1.2 读取文件
- 读取本地文件

- 读取HDFS文件


1.3 编写词频统计程序
- 读取文件
val textFile = sc.textFile("file:///usr/local/spark-2.4.8/README.md")
- 统计词频
val wordCount = textFile.flatMap(line => line.split(" ")).map(word=> (word, 1)).reduceByKey((a, b) => a + b)
- 输出结果
wordCount.collect()

2. 编写Spark独立应用程序
2.1 用Scala语言编写Spark独立应用程序
-
安装好sbt
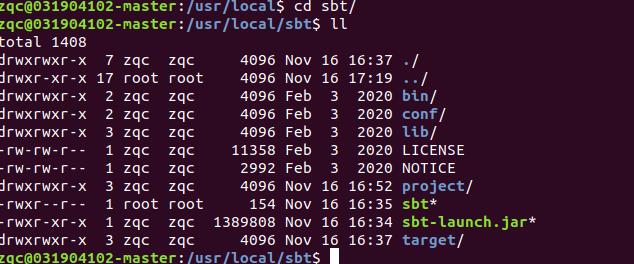
-
检查目录结构

-
查看结果

如果遇到了java命令不存在的情况,但是自己系统变量里面又有的话。
像下面这种情况

排除完版本的问题之后!就按照他这样所提示的,可以直接在系统安装一个java环境。多个java环境不影响。
- 更新
sudo apt-get update
- 安装
sudo apt-get install openjdk-8-jdk
2.2 用Java语言编写Spark独立应用程序
/usr/local/spark/bin/spark-submit --class "SimpleApp" ~/sparkapp2/target/simple-project-1.0.jar
3. 编程题
3.1 第一题
对于两个输入文件A和B, 编写Spark独立应用程序(推荐使用Scala 语言),对两个文件进行合并,并剔除其中重复的内容,得到一个新的文件C。(文件A,B如下)
- 代码
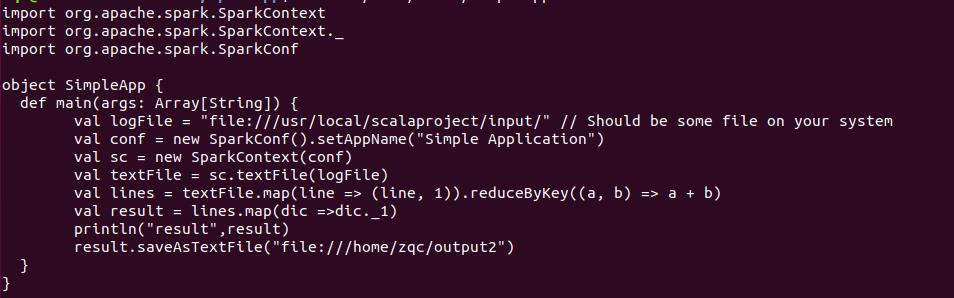
-
打包

-
输出结果
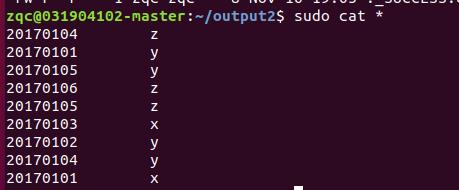
3.2 第二题
编写独立应用程序实现求平均值问题,每个输入文件表示班级学生某个学科的成绩,每行内筒由两个字段组成,第一个是学生名字,第二个是学生的成绩;编写Spark独立应用程序(推荐使用Scale语言)求出所有学生的平均成绩,并输入到一个新文件中。
- 新建三个文件并写入三个数据

- 在spark-shell编写完之后,转移到scala文件
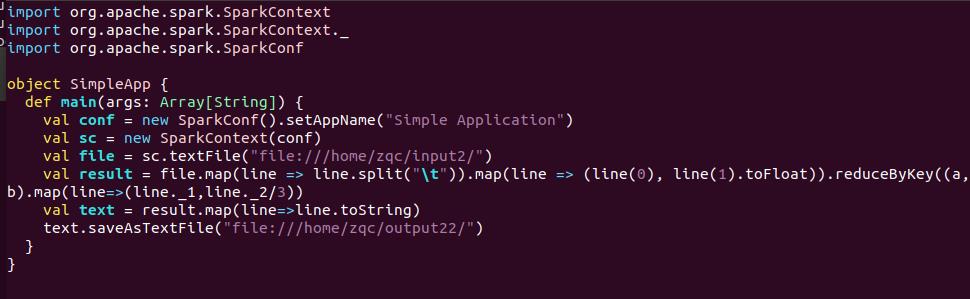
- 输出结果
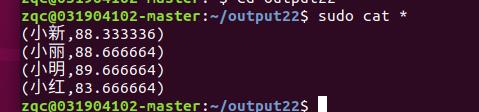
以上是关于大数据计算 Spark的安装和基础编程的主要内容,如果未能解决你的问题,请参考以下文章