如何用EXCEL进行数据分组
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何用EXCEL进行数据分组相关的知识,希望对你有一定的参考价值。
工具/材料:Microsoft Office Word2016版,Excel表格。
1、首先选中Excel表格,双击打开。
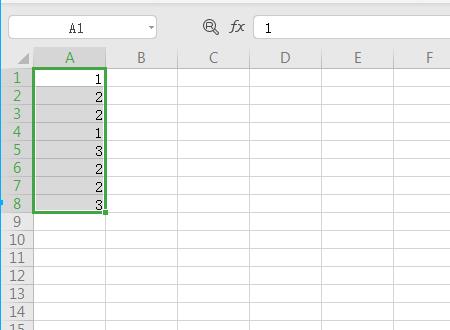
2、其次在该界面中,选中要进行数据分组的所在单元格。
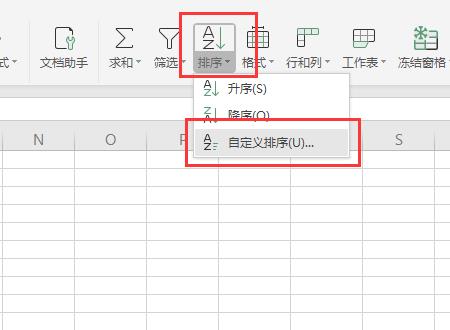
3、继续在该界面中,点击上方工具栏里“排序”里“自定义排序”按钮。
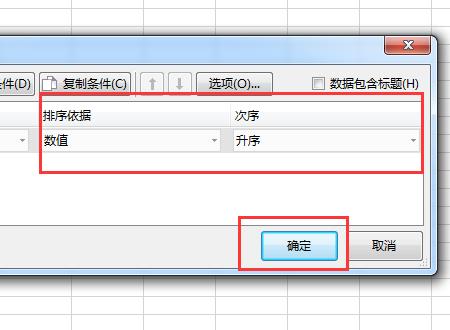
4、然后在该界面中,选择“排序依据”和“次序”,点击“确定”按钮。
5、最后在该界面中,显示数据分组。
工具原料:电脑+office2007
用EXCEL进行数据分组方法如下:
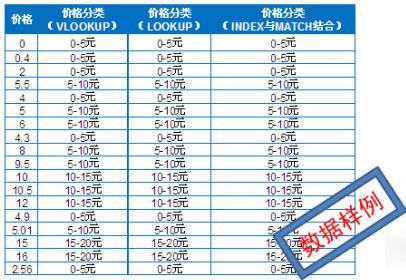
一、在日常数据分析中,经常需要对某个数年变量进行分组汇总,如图所示的价格数据,对价格进香区间划分:用VLOOKUPP、LOOKUP、INDEX与MATCH结合的三种函数数据分组用法
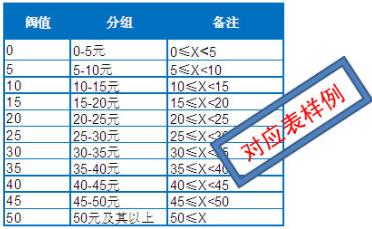
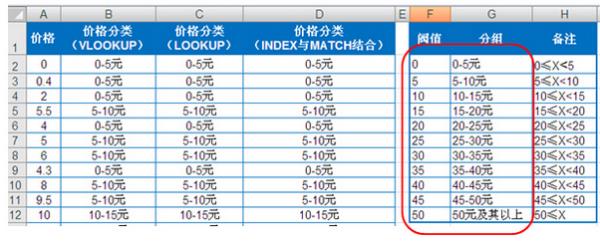
二、准备一个分组对应表,根据自己的需求确定分组的组距,分组数所需 范围见下表,阀值设置为每个分组最低值,例如样例中第二给5-10元(5≤x<10),则阀值设置为5,其它阀值设置以此类推
三、用VLOOKUPP、LOOKUP、INDEX与MATCH结合
VLOOKUP:在B2输入=VLOOKUP(A2,$F$2:$G$12,2)
LOOKUP:在C2输入=LOOKUP(A2,$F$2:$G$12,2)
INDEX与MATCH结合:在D2输入=INDEX($G$2:$G$12,MATCH($F$2:$F$12))
以上三种函数方法可自行对照下表单元范围进行理解函数参数设置
2、先对统计数据用数据透视表。步骤略。
3、对数据透视表中的年龄字段进行分组:在年龄数据上点鼠标右键,选分组,在弹出窗口中设置要分组的间隔和初始、终止值即可。
如何用非数字值对数据框进行分组和透视。
我使用Python,我有一个由6列组成的数据集,分别是R、Rc、J、T、Ca和Cb。我需要先对 "R "列进行 "聚合",然后再对 "J "列进行 "聚合",这样每一个R,每一行都是一个唯一的 "J"。Rc是R的特征,Ca和Cb是T的特征,看下面的表格会更有意义。
我需要从。
#______________________ ________________________________________________________________
#| R Rc J T Ca Cb| |# R Rc J Ca(T=1) Ca(T=2) Ca(T=3) Cb(T=1) Cb(T=2) Cb(T=3)|
#| a p 1 1 x d| |# a p 1 x y z d e f |
#| a p 1 2 y e| |# b o 1 w g |
#| a p 1 3 z f| -----> |# b o 2 v h |
#| b o 1 1 w g| |# b o 3 s i |
#| b o 2 1 v h| |# c n 1 t r j k |
#| b o 3 1 s i| |# c n 2 u l |
#| c n 1 1 t j| |________________________________________________________________|
#| c n 1 2 r k|
#| c n 2 1 u l|
#|____________________|
data = {'R' : ['a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'c'],
'Rc': ['p', 'p', 'p', 'o', 'o', 'o', 'n', 'n', 'n'],
'J' : [1, 1, 1, 1, 2, 3, 1, 1, 2],
'T' : [1, 2, 3, 1, 1, 1, 1, 2, 1],
'Ca': ['x', 'y', 'z', 'w', 'v', 's', 't', 'r', 'u'],
'Cb': ['d', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l']}
df = pd.DataFrame(data=data)
我不想丢失Rc,Ca,Cb的数据。
Rc(或每个以'c'结尾的列)对每个R来说都是一样的,所以可以直接和R归为一组。
但Ca和Cb(或每一列以'c'开头的数据)对每个T来说是唯一的,会被汇总,否则会丢失。这些需要保存在新的列中,命名为Ca(T=1)表示当T=1时,Ca(T=2)表示当T=2时,Ca(T=3)表示当T=3时。Cb也是如此。
所以利用T,我需要为给定T的Ca和Cb分别创建T个数的列,即把Ca和Cb的数据写入新的列中。
PS.如果有帮助的话,J列和T列的数量是一样的,我需要为每个Ca和Cb创建T列,将Ca和Cb的数据写入新的列中。如果有帮助的话,J列和T列都多了一个唯一ID的列。
J_ID = [1,1,1,2,3,4,5,5,6]
T_ID = [1,2,3,4,5,6,7,8,9]
目前我试过的。
(
df.groupby(['R','J'])
.apply(lambda x: x.Ca.tolist()).apply(pd.Series)
.rename(columns=lambda x: f'Ca{x+1}')
.reset_index()
)
问题: 只能用其中的一个C来做,我失去了Rc。
任何帮助都将是非常感激的!
你可以使用 pivot_table (这里的文档),其lambda函数为 aggfunc 参数。
table = pd.pivot_table(df, index = ['R','Rc','J'],values = ['Ca','Cb'],
columns = ['T'], fill_value = '', aggfunc = lambda x: ''.join(str(v) for v in x)).reset_index()
R Rc J Ca Cb
T 1 2 3 1 2 3
0 a p 1 x y z d e f
1 b o 1 w g
2 b o 2 v h
3 b o 3 s i
4 c n 1 t r j k
5 c n 2 u l
然后,你可以删除多索引列,并重新命名如下(取自于 这个伟大的答案):
table.columns = ['%s%s' % (a, ' (T = %s)' % b if b else '') for a, b in table.columns]
R Rc J Ca (T = 1) Ca (T = 2) Ca (T = 3) Cb (T = 1) Cb (T = 2) Cb (T = 3)
0 a p 1 x y z d e f
1 b o 1 w g
2 b o 2 v h
3 b o 3 s i
4 c n 1 t r j k
5 c n 2 u l
如果我明白你的需求,你可以简单地找到需要的行,就像这样。
df['Ca(T=1)']=df['Ca'].loc[df['T']==1]
你必须为不同的T重复这样做。
以上是关于如何用EXCEL进行数据分组的主要内容,如果未能解决你的问题,请参考以下文章