Redis 学习笔记总结
Posted IT_Holmes
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis 学习笔记总结相关的知识,希望对你有一定的参考价值。
文章目录
- 1. 开发中,必须遇到的两个问题?
- 2. 什么是集群?
- 3. 搭建 无中心化的redis集群
- 4. redis集群 操作和故障恢复
- 5. redis集群的 Jedis 开发
- 6. redis集群的 优缺点
- 7. Redis 应用问题 之 缓存穿透
- 8. Redis 应用问题 之 缓存击穿
- 9. Redis 应用问题 之 缓存雪崩
- 10. 分布式锁
- 11. Redis 6.0 新功能 之 ACL
- 12. Redis 6.0 新功能 之 IO多线程
- 13. Redis 6.0 新功能 之 工具支持Cluster
1. 开发中,必须遇到的两个问题?
容量不够,redis如何进行扩容?
并发写操作,redis如何分摊?
曾经我们使用 代理主机 来解决上面的问题:
(客户端必须先经过代理主机,再去响应的逻辑。)
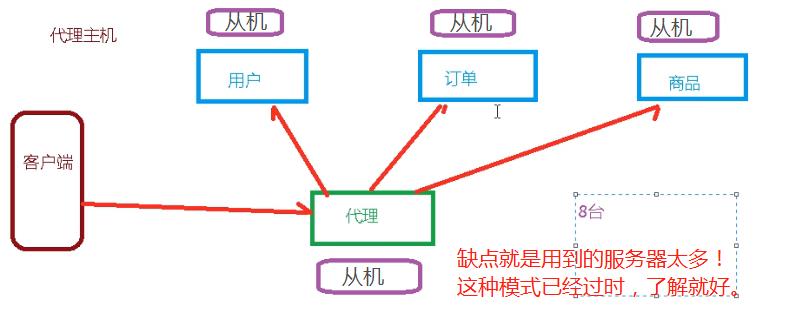
redis 3.0 开始就提供了一个无中心化集群配置。

2. 什么是集群?

3. 搭建 无中心化的redis集群
3.1 第一步:创建6个不同的redis.conf配置文件
第一步:创建6个不同的redis.conf配置文件。
修改redis6379.conf,redis6380.conf,redis6381.conf配置文件,添加集群配置:
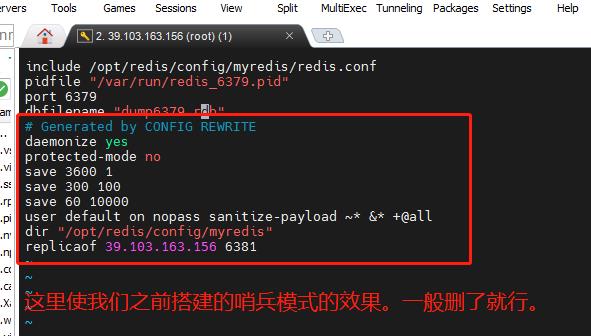
需要添加的配置如:
- cluster-enabled yes : 打开集群模式。
- cluster-config-file nodes-6379.conf:设置节点配置文件名。
- cluster-node-timeout 15000:设定节点失联事件,超过该事件(毫秒),集群自动进行主从切换。
添加redis6389.conf,redis6390.conf,redis6391.conf文件。直接cp就行,然后修改修改文件名端口啥的。

修改过程中,需要换不同字段可以使用vim下的查找替换操作(简便):
(下面的意思就是将所有的6379换成6390)
3.2 第二步:启动6个redis服务
第二步:启动6个redis服务
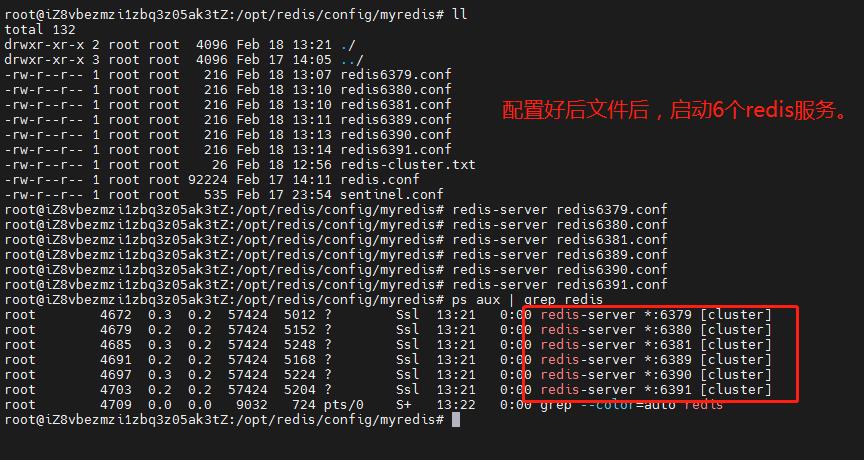
因为我们设置了cluster-config-file配置节点配置文件名称,对应的也就生成出来了:
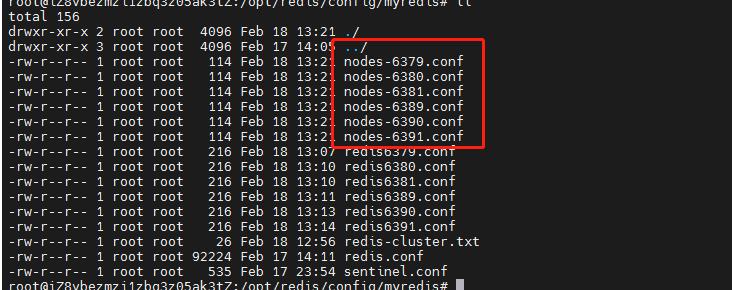
达到上面效果,说明redis的6个服务已经启动成功了。
3.3 第三步:将6个节点合成一个无中心化集群
组合之前,redis实例必须正常启动,node-xxx.conf文件都正常生成才行!
注意:ruby环境!(redis6默认有这环境,但是老版本redis需要搭建ruby环境。)

去我们解压的redis目录下,进入src目录,执行下面的命令:
redis-cli --cluster create --cluster-replicas 1 39.103.163.156:6379 39.103.163.156:6380 39.103.163.156:6381 39.103.163.156:6389 39.103.163.156:6390 39.103.163.156:6391
# 解释一下这里的 1 是什么意思。
#--replicas 1 采用最简单的方式配置集群(一主一从),我们这里有6台redis服务,就会分配成为3个1主1从的组合。
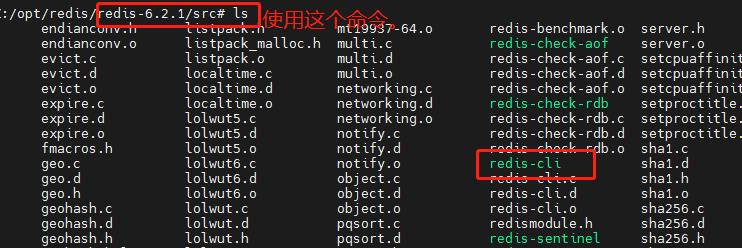
这里我又碰到了一个坑,如果你的云端服务器不修改安全规则(开发端口)的话,就会一直卡住,直到timeout。

之后我以为云端出入规则开放端口号就没有坑了,没想到又碰到一个!每个Redis群集节点都需要打开两个TCP连接。用于为客户端提供服务的普通Redis TCP端口,例如6379,加上通过向数据端口添加10000获得的端口,因此示例中为16379。
也就是6个节点的端口号 + 10000 ,就是6个集群总线端口都需要开启。
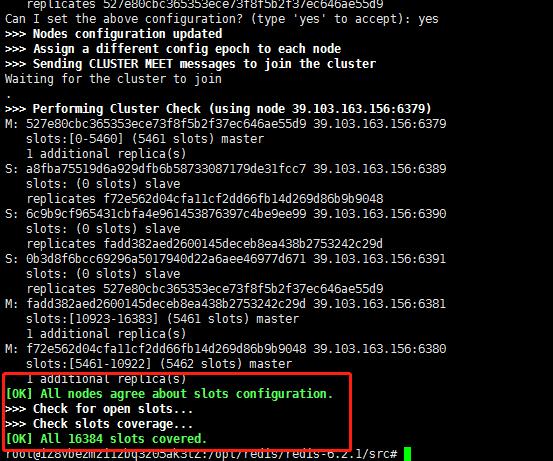
出现下面这种结果,就表示redis集群搭建成功了。
3.4 第四步:通过集群连接(测试)
我们搭建了集群,再连接redis客户端就必须要用集群的策略来连接了。
- 参数 -c :采用集群策略连接,设置数据会自动切换到响应的写主机。

使用cluster nodes 命令来查看集群信息。

4. redis集群 操作和故障恢复
4.1 redis cluster 如何分配这六个节点?
一个集群至少要有三个主节点。
redis集群节点的分配原则:是尽量保证每个主数据库运行在不同的ip地址,每个从库和主库不在一个IP地址上。

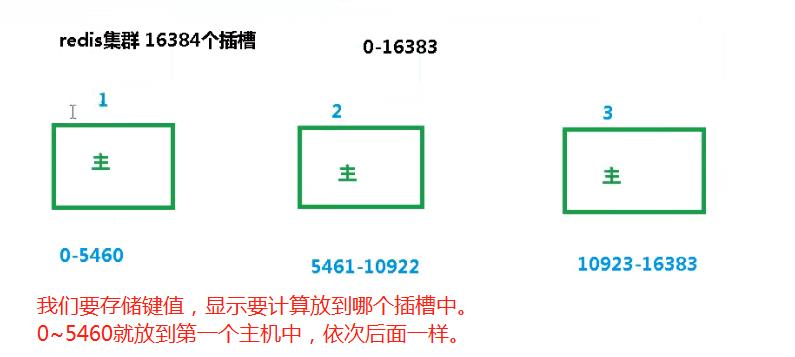
4.2 什么是slots(插槽)?
我们在执行将6个节点整合为一个redis集群,成功时给我们返回了下面这段话:
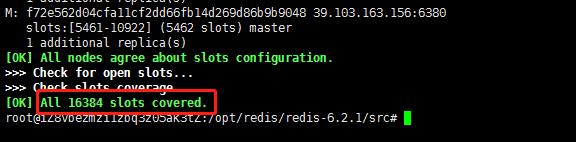
一个redis集群包含16384个插槽(hash slot),数据库中的每个键都属于这16384个插槽(0~16383)的其中一个。
这里我们有三个主机服务,它就会将这16384个插槽平分到三个主机上面,我们可以通过cluster nodes命令查看到平分效果。

而在我们往redis数据库中添加键key时,集群先使用公式 CRC16(key) % 16384 计算出key应该属于哪个插槽。(CRC16(key)是一个算法,用于计算键key的CRC16校验和)
4.3 在redis集群中 录入键值
现在我们带卡一个主机的客户端(哪一个都行,因为是无中心化redis集群),进行一个插入操作。
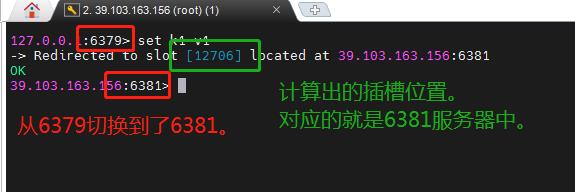
你会发现,它会根据key的值来计算插槽,从而找到插槽对应的主机中,并且切换到该主机中。
不在一个插槽下的键值,是不能进行mset命令的。

如果,我想一次性添加多个就可以通过 组的方式来进行操作,从而使key中 内相同内容的键值对放到一个slot中去。

4.4 在redis集群中 查询集群中的值
cluster keyslot [key] 命令:查询key的slot插槽值(插槽号)。

cluster countkeysinslot [slot] 命令:查询当前slot插槽种有多少个key。(注意:这里的查询slot必须是当前服务所在范围的那个slot插槽,因为所有的插槽是均分到三台主机中的,也就是当前服务(主机)只能查询到自己包括的插槽slot,其他主机的插槽不能使用该命令获取。)

cluster getkeysinslot [slot] [count] 命令:返回count个slot槽中的键。

4.5 redis集群的 故障恢复
如果在redis集群中,一台主机发生了故障宕机了,比如:6379主机宕机了,redis集群会让6379的从机6391成为主机,继续进行集群效果。

如果宕机的6379又恢复了,那它就变为从机来操作了。

再往后考虑,如果主机和从机都宕机了出问题了! 那么redis集群还能正常运行么?这和 cluster-require-full-coverage配置 有关系!
- 设置为yes,就是整个集群都关闭。
- 设置为no,就只是宕机的主从机的插槽不能使用也不能储存。其他主从机依然能提供服务。

5. redis集群的 Jedis 开发
知道 HostAndPort 和 JedisCluster 对象。
package com.itholmes.cluster;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.JedisCluster;
public class RedisClusterDemo
public static void main(String[] args)
/*
* 创建HostAndPort对象,这里的ip和端口设置谁都无所谓。
* 因为,在集群中是无中心化的,相互之间可以切换。也就是说任何一个地方都可以作为集群的入口。
* */
HostAndPort hostAndPort = new HostAndPort("39.103.163.156",6379);
//创建JedisCluster对象
JedisCluster cluster = new JedisCluster(hostAndPort);
//进行操作
cluster.set("b2", "value2");
String value = cluster.get("b2");
System.out.println();
cluster.close();
package com.itholmes.cluster;
import java.util.HashSet;
import java.util.Set;
import redis.clients.jedis.HostAndPort;
import redis.clients.jedis.JedisCluster;
public class RedisClusterDemo2
public static void main(String[] args)
//通过set方式来操作
Set<HostAndPort> set = new HashSet<HostAndPort>();
set.add(new HostAndPort("39.103.163.156",6379));
JedisCluster cluster = new JedisCluster(set);
cluster.set("key10","value10");
String key10 = cluster.get("key10");
System.out.println();
cluster.close();
6. redis集群的 优缺点
优点:

缺点:

7. Redis 应用问题 之 缓存穿透
7.1 什么是缓存穿透?
当用户访问量突然增大,并且大部分数据在redis缓存中并没有命中(就是不在redis缓存中),就需要去数据库中查询,这样大量的数据就去查询数据库中的内容,从而导致数据库系统崩溃了,这样的现象就叫做缓存穿透。
一般出现缓存穿透如以下几点:
- redis命令率降低,大量用户一直查询数据库。
- 出现很多非正常url访问(攻击服务器,让服务器进行瘫痪)。
解释一下非正常url访问是如何攻击服务器,当用户进行一个非正常的url访问(拼接参数)例如:获取一个数据库中没有的图片,并且一直发送请求获取,这样数据库一直查询,并且查询不到,也没法同步到缓存中,这样慢慢的mysql的数据库就会崩溃了(这就类似黑客或者用户的恶意攻击)。

7.2 如何解决缓存穿透?

对上面的简略总结:
- 对空值缓存方案:只能说一种应急方案,因为设置过期时间过期后,
仍然要去访问查询数据库。 - 设置可访问的名单(白名单):这个虽然比空值缓存方案强,但是每次访问都要经过这个白名单的比较,效率就会下降。
- 布隆过滤器:优化了白名单的bitmaps原理,但是也有缺点!
- 记性实时监控:设置黑名单限制服务。
8. Redis 应用问题 之 缓存击穿
8.1 什么是缓存击穿?
redis缓存中里面没有出现大量的key过期,并且redis缓存正常运行。但是redis缓存中的某个key过期了,并且用户有很多访问都使用到这个key,那么redis缓存就没有命中到这个key,就会导致大量访问瞬时查询数据库,从而导致数据库崩溃,这个现象叫做缓存击穿。
注意:缓存穿透和缓存击穿还是有区别的。
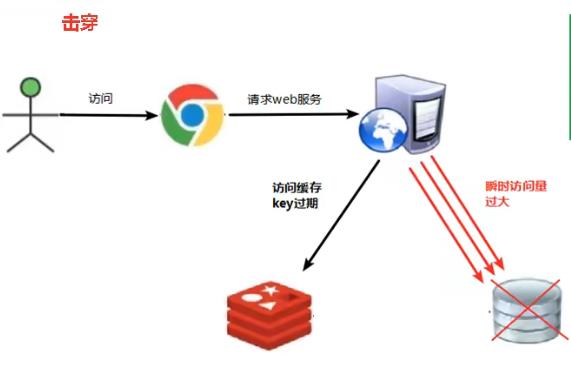
8.2 如何解决缓存击穿?

9. Redis 应用问题 之 缓存雪崩
9.1 什么是缓存雪崩?
在极少时间段,查询大量的key的集中过期情况,从而导致数据库压力变大,数据库因为压力太大崩溃了,进而整个服务器,redis也崩溃了。这种现象就叫做雪崩问题。

9.2 如何解决缓存雪崩?

10. 分布式锁
10.1 分布式锁的问题描述
原单体单机部署系统 演化成为 分布式集群系统。
由于分布式系统多线程,多进程都分布在不同机器上,上锁就成为了难题。为了解决这个问题就需要一种跨JVM的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题。

如何实现分布式锁:

接下来就是用redis来实现分布式锁。
10.2 在redis中实现分布式锁
我们可以使用setnx来设置锁,使用del来删除锁。来实现一个共享锁的效果。
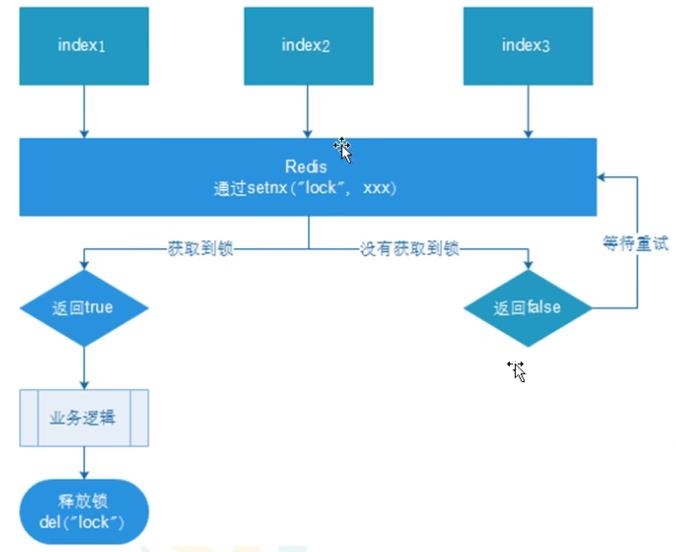
如果我们使用了setnx设置了一个lock锁,但是这个锁一直没有释放,那么问题就大了,因此我们会设置expire过期时间。

像下面这个命令就是即上锁又设置过期时间。
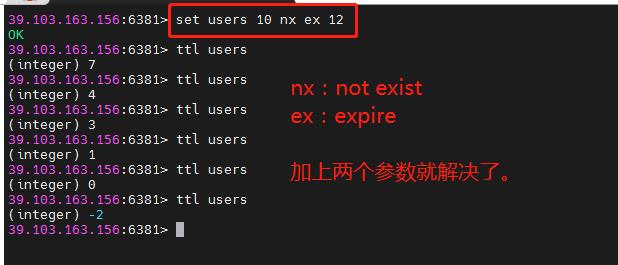
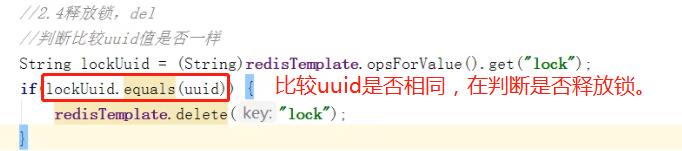
10.3 分布式锁优化 之 UUID 防止误删
之所以引出 UUID 防止误删的概念,就是因为下面图中的问题:

因为上面的问题,就可以通过UUID来进行避免:

对面上面set lock uuid nx ex 10 命令:java代码同样通过传参来做到。

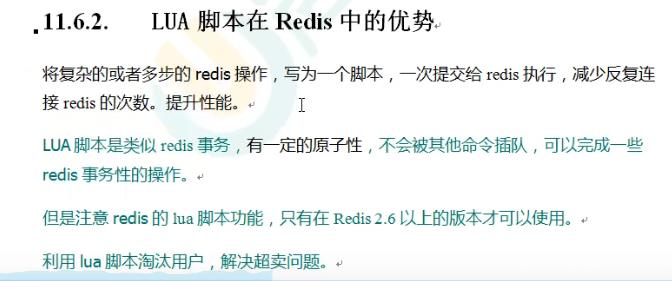
10.4 分布式锁优化 之 lua脚本保证删除锁的原子性
因为redis的del删除操作是没有原子性的,这样就会又造成一个严重的问题!

为了解决删除的原子性问题,我们可以使用lua脚本来操作。lua脚本是具有原子性的。
在java代码中,写lua脚本。

10.5 分布式锁必须满足下面的四个条件

11. Redis 6.0 新功能 之 ACL
11.1 什么是ACL?

11.2 ACL的命令



对于创建用户aclsetuser命令,见下图详解:


12. Redis 6.0 新功能 之 IO多线程
注意,这里的多线程是指IO多线程,redis执行命令还是单线程的。
redis的io多线程只是用来处理网络数据的读写和协议解析。
我们可以在redis.conf配置文件中开启io多线程。

13. Redis 6.0 新功能 之 工具支持Cluster
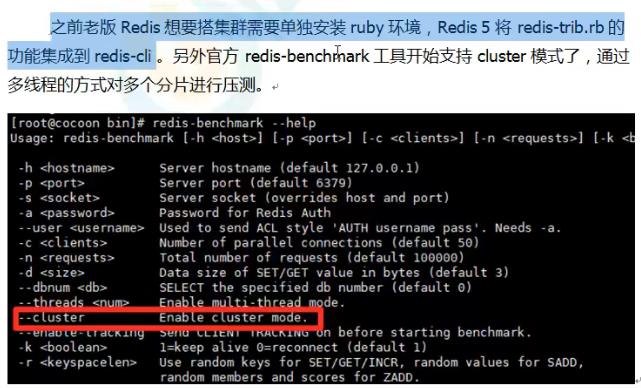
以上是关于Redis 学习笔记总结的主要内容,如果未能解决你的问题,请参考以下文章