MySQL基础教程---数据表相关操作
Posted 敲代码的xiaolang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL基础教程---数据表相关操作相关的知识,希望对你有一定的参考价值。
文章目录
前言
一、创建数据表
1.基本定义
CREATE TABLE table_name
(
field1 datatype,
field2 datatype,
field3 datatype
)character set 字符集 collate 校对规则 engine 存储引擎
field: 指定列名
datatype: 指定列类型
character set: 字符集,如果不指定,则按所在数据库的字符集为准
collate: 校对规则,如果不指定,则按数据库校对规则为准
engine: 引擎
看一个栗子:
创建一个表,包含以下数据类型:
id —> 整型;
name —>字符串;
password —>字符串
birthday —>日期
我们先使用图形化方法做一遍:
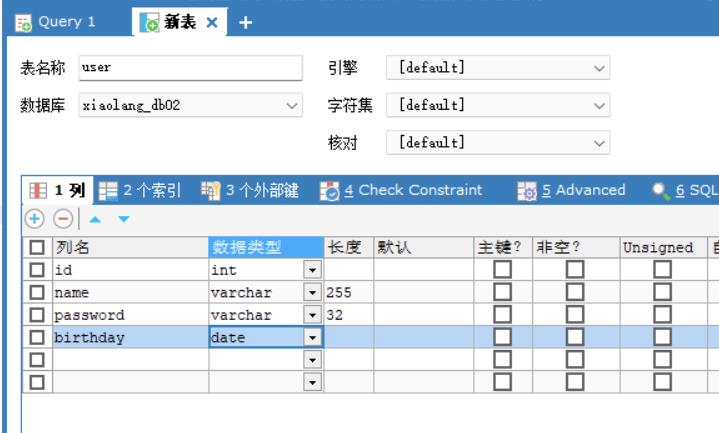
下面再写一下用指令的方式:
CREATE TABLE `user` (
id INT,
`name` VARCHAR(255),
`password` VARCHAR(255),
`birthday` DATE)
CHARACTER SET utf8 COLLATE utf8_bin ENGINE INNODB;
2.常用数据类型
官方文档:https://dev.mysql.com/doc/refman/5.7/en/data-types.html
这里主要写一下整型,浮点型,字符型,日期型
mysql:https://www.runoob.com/mysql/mysql-data-types.html
作为SQL标准的扩展,MySQL也支持整数类型TINYINT、MEDIUMINT和BIGINT。下面的表显示了需要的每个整数类型的存储和范围。
整型和浮点数类型
类型 大小 范围(有符号) 范围(无符号) 用途 TINYINT 1 byte (-128,127) (0,255) 小整数值 SMALLINT 2 bytes (-32 768,32 767) (0,65 535) 大整数值 MEDIUMINT 3 bytes (-8 388 608,8 388 607) (0,16 777 215) 大整数值 INT或INTEGER 4 bytes (-2 147 483 648,2 147 483 647) (0,4 294 967 295) 大整数值 BIGINT 8 bytes (-9,223,372,036,854,775,808,9 223 372 036 854 775 807) (0,18 446 744 073 709 551 615) 极大整数值 FLOAT 4 bytes (-3.402 823 466 E+38,-1.175 494 351 E-38),0,(1.175 494 351 E-38,3.402 823 466 351 E+38) 0,(1.175 494 351 E-38,3.402 823 466 E+38) 单精度 浮点数值 DOUBLE 8 bytes (-1.797 693 134 862 315 7 E+308,-2.225 073 858 507 201 4 E-308),0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) 0,(2.225 073 858 507 201 4 E-308,1.797 693 134 862 315 7 E+308) 双精度 浮点数值 DECIMAL 对DECIMAL(M,D) ,如果M>D,为M+2否则为D+2 依赖于M和D的值 依赖于M和D的值 小数值
日期和时间类型
表示时间值的日期和时间类型为DATETIME、DATE、TIMESTAMP、TIME和YEAR。
每个时间类型有一个有效值范围和一个"零"值,当指定不合法的MySQL不能表示的值时使用"零"值。
TIMESTAMP类型有专有的自动更新特性,将在后面描述。
类型 大小 ( bytes) 范围 格式 用途 DATE 3 1000-01-01/9999-12-31 YYYY-MM-DD 日期值 TIME 3 ‘-838:59:59’/‘838:59:59’ HH:MM:SS 时间值或持续时间 YEAR 1 1901/2155 YYYY 年份值 DATETIME 8 1000-01-01 00:00:00/9999-12-31 23:59:59 YYYY-MM-DD HH:MM:SS 混合日期和时间值 TIMESTAMP 4 1970-01-01 00:00:00/2038结束时间是第 2147483647 秒,北京时间 2038-1-19 11:14:07,格林尼治时间 2038年1月19日 凌晨 03:14:07 YYYYMMDD HHMMSS 混合日期和时间值,时间戳
字符串类型
字符串类型指CHAR、VARCHAR、BINARY、VARBINARY、BLOB、TEXT、ENUM和SET。该节描述了这些类型如何工作以及如何在查询中使用这些类型。
类型 大小 用途 CHAR 0-255 bytes 定长字符串 VARCHAR 0-65535 bytes 变长字符串 TINYBLOB 0-255 bytes 不超过 255 个字符的二进制字符串 TINYTEXT 0-255 bytes 短文本字符串 BLOB 0-65 535 bytes 二进制形式的长文本数据 TEXT 0-65 535 bytes 长文本数据 MEDIUMBLOB 0-16 777 215 bytes 二进制形式的中等长度文本数据 MEDIUMTEXT 0-16 777 215 bytes 中等长度文本数据 LONGBLOB 0-4 294 967 295 bytes 二进制形式的极大文本数据 LONGTEXT 0-4 294 967 295 bytes 极大文本数据 注意:char(n) 和 varchar(n) 中括号中 n 代表字符的个数,并不代表字节个数,比如 CHAR(30) 就可以存储 30 个字符。
练习:创建一个员工的数据表,选用适当的数据类型,包含员工的姓名,性别,ID,生日,以及其他相关信息。
CREATE TABLE `emp`(
id INT,
`name` VARCHAR(32),
sex CHAR(1),
brithday DATE,
entry_date DATETIME,
job VARCHAR(32),
salary DOUBLE,
`resume` TEXT) CHARSET utf8 COLLATE utf8_bin ENGINE INNODB;
-- 字段 属性
-- Id 整形
-- name 字符型
-- sex 字符型
-- brithday 日期型(date)
-- entry_date 日期型 (date)
-- job 字符型
-- Salary 小数型
-- resume 文本型
添加一条数据:
-- 添加一条数据
INSERT INTO `emp`
VALUES(001, 'xiaolang', '男', '1010-10-10',
'1111-11-11 11:11:11', '专业摸鱼', 100, '我的心是冰冰的');
SELECT * FROM `emp`;
运行结果:

二、修改数据表
我们可以使用可视化界面直接修改表,但是实际在开发时,我们通常使用程序操控指令,对数据库进行操作。
#添加列
ALTER TABLE tablename
ADD (column datatype [DEFAULT expr]
[, column datatype]...);
#修改列
ALTER TABLE tablename
MODIFY (column datatype [DEFAULT expr]
[, column datatype]...);
#删除列
ALTER TABLE tablename
DROP (column);
#查看表的结构:desc 表名; --可以查看表的列
#修改表名
Rename table 表名 to 新表名
#修改表字符集
alter table 表名 character set 字符集;
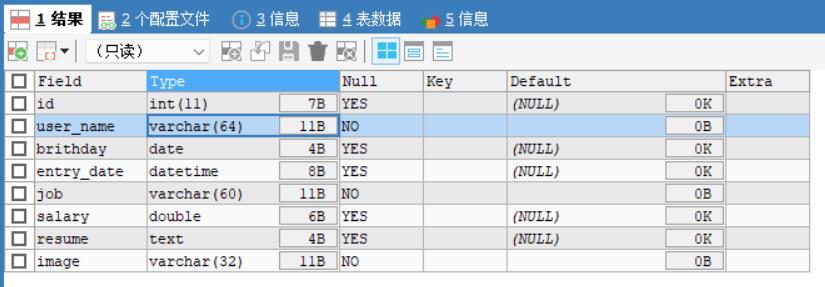
练习:在上面的员工表emp里面增加一个image列,varchar类型(要求在resume后面)。修改job列,使其长度为60。删除sex列。表名改为employee。修改表的字符集是utf8。列名name改为user_name。
#参考语句
-- 员工表emp的上增加一个image列,varchar类型(要求在resume后面)。
ALTER TABLE emp
ADD image VARCHAR(32) NOT NULL DEFAULT ''
AFTER RESUME
DESC emp -- 显示表结构,可以查看表的所有列
-- 修改job列,使其长度为60。
ALTER TABLE emp
MODIFY job VARCHAR(60) NOT NULL DEFAULT ''
-- 删除sex列。
ALTER TABLE emp
DROP sex
-- 表名改为employee。
RENAME TABLE emp TO employee
-- 修改表的字符集为utf8
ALTER TABLE employee CHARACTER SET utf8
-- 列名name修改为user_name
ALTER TABLE employee
CHANGE `name` `user_name` VARCHAR(64) NOT NULL DEFAULT ''
DESC employee
执行完所有sql语句后的结果:
三、Insert语句
INSERT INTO table_name [(column [, column...])]
VALUES (value [, value...]);
栗子:创建一个商品表goods(id int , goods_name varchar(10) , price double ); 任意添加两条记录。
CREATE TABLE `goods`(
id INT,
goods_name VARCHAR(10),
price DOUBLE);
-- 添加数据
INSERT INTO `goods` (id, goods_name, price)
VALUES(1, '苹果', 10);
INSERT INTO `goods` (id, goods_name, price)
VALUES(2, '葡萄', 13);
SELECT * FROM goods;
下面举一些有问题的栗子:
#说明insert 语句的细节
-- 1.插入的数据应与字段的数据类型相同。
-- 比如 把 'abc' 添加到 int 类型会错误
INSERT INTO `goods` (id, goods_name, price)
VALUES('abc', '西瓜', 20);
-- 2. 数据的长度应在列的规定范围内。
INSERT INTO `goods` (id, goods_name, price)
VALUES(40, 'GGBAOGGBAOGGBAOGGBAOGGBAOGGBAO', 3000);
-- 3. 在values中列出的数据位置必须与被加入的列的排列位置相对应。
INSERT INTO `goods` (id, goods_name, price) -- 不对
VALUES('柠檬',60, 40);
-- 4. 字符和日期型数据应包含在单引号中。
INSERT INTO `goods` (id, goods_name, price)
VALUES(40, 波罗蜜, 3000); -- 错误的 波罗蜜 应该 '波罗蜜'
-- 5. 列可以插入空值[前提是该字段允许为空],insert into table value(null)
INSERT INTO `goods` (id, goods_name, price)
VALUES(10, '波罗蜜', NULL);
-- 6. insert into tab_name (列名..) values (),(),() 形式添加多条记录
INSERT INTO `goods` (id, goods_name, price)
VALUES(21, '喜羊羊', 20),(34, '懒羊羊', 18);
-- 7. 如果是给表中的所有字段添加数据,可以不写前面的字段名称
INSERT INTO `goods`
VALUES(70, '榴莲', 50);
-- 8. 默认值的使用,当不给某个字段值时,如果有默认值就会添加默认值,否则报错
-- 如果某个列 没有指定 not null ,那么当添加数据时,没有给定值,则会默认给null
-- 如果我们希望指定某个列的默认值,可以在创建表时指定
INSERT INTO `goods` (id, goods_name)
VALUES(16, '皮卡丘');
四、update语句
UPDATE tb1_name
SET co_name1=expr1 [, col_namme2=expr2 ...]
[WHERE where_definition]
我们看几个例子:
-- 1. 将所有员工薪水修改为6666元。[如果没有带where 条件,会修改所有的记录。]
UPDATE employee SET salary = 6666
-- 2. 将姓名为xiaolang的工资修改为2222元。
UPDATE employee
SET salary = 2222
WHERE user_name = 'xiaolang'
-- 3. 将姓名为xiaowang的工资在原有基础上增加1000元
INSERT INTO employee
VALUES(2, 'xiaowang', '1234-05-06', '4321-06-05 22:22:22', '业余划水', 3333, '我的心也是冰冰的','d:// test.jpg');
UPDATE employee
SET salary = salary + 1000
WHERE user_name = 'xiaowang'
-- 修改多个列的值
UPDATE employee
SET salary = salary + 1000 , job = '业余摸鱼'
WHERE user_name = 'xiaowang'
运行结果:

五、delete语句
delete from tb1_name
[WHERE where_definition]
举几个栗子:
-- 删除表中名称为’xiaowang’的记录。
DELETE FROM employee
WHERE user_name = 'xiaowang';
-- 删除表中所有记录
DELETE FROM employee;
-- Delete语句不能删除某一列的值(可使用update 设为 null 或者 '')
UPDATE employee SET job = '' WHERE user_name = 'xiaolang';
-- 要删除这个表
DROP TABLE employee;
- 如果不使用where语句,那么就会删除表的所有数据。
- Delete语句不能删除某一列的值(可使用update 设为 null 或者 ‘’)
- 使用delete语句不删除表的本身,只会删除记录。如果要删除表,使用drop table语句。
六、select语句
SELECT [DISTINCT] *| column1, column2, column3..
FROM table_name;
#Select指定查询哪些列的数据。
#column指定列名。
#*号代表查询所有列。
#From指定查询哪张表。
#DISTINCT可选,指显示结果时,是否去掉重复数据
大栗子:
我们先存入一个sql文件,里面有一些学生的成绩。
CREATE TABLE student(
id INT NOT NULL DEFAULT 1,
NAME VARCHAR(20) NOT NULL DEFAULT '',
chinese FLOAT NOT NULL DEFAULT 0.0,
english FLOAT NOT NULL DEFAULT 0.0,
math FLOAT NOT NULL DEFAULT 0.0
);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(1,'小王',89,78,90);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(2,'大王',67,98,56);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(3,'老王',87,78,77);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(4,'小李',88,98,90);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(5,'大李',82,84,67);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(6,'大李',55,85,45);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(7,'王李',75,65,30);
INSERT INTO student(id,NAME,chinese,english,math) VALUES(8,'李王',45,65,99);
可以进行如下简单的操作:
-- 查询表中所有学生的信息。
SELECT * FROM student;
-- 查询表中所有学生的姓名和对应的英语成绩。
SELECT `name`,english FROM student;
-- 过滤表中重复数据 distinct 。
SELECT DISTINCT english FROM student;
-- 要查询的记录,每个字段都相同,才会去重
SELECT DISTINCT `name`, english FROM student;
#使用表达式对查询的列进行运算
SELECT *| column1 | expression, column2| expression, ..
FROM tablename;
#在select语句中可使用as语句
SELECT column_name as 别名 from 表名;
小栗子:
-- 统计每个学生的总分
SELECT `name`, (chinese+english+math) FROM student;
-- 在所有学生总分加10分的情况
SELECT `name`, (chinese + english + math + 10) FROM student;
-- 使用名字表示学生分数。
SELECT `name` AS '名字', (chinese + english + math + 10) AS total_score
FROM student;
使用SQL WHERE 子句
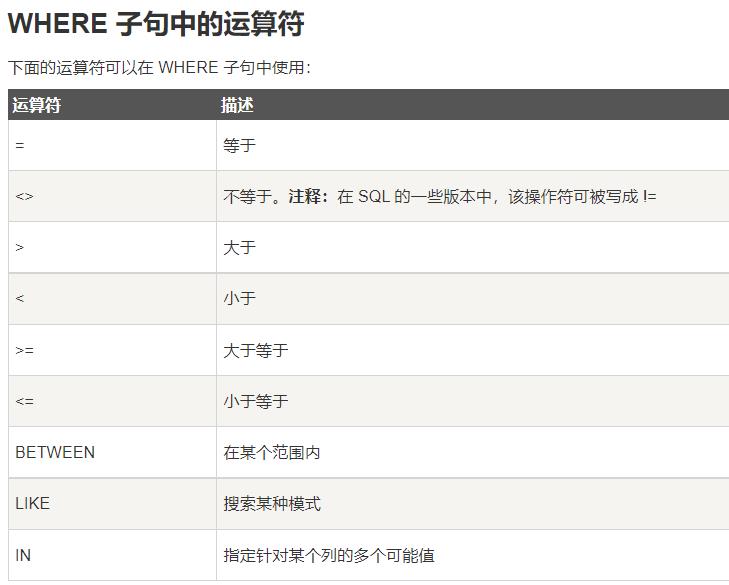
小栗子:
-- 查询姓名为老王的学生成绩
SELECT * FROM student
WHERE `name` = '老王'
-- 查询英语成绩大于90分的同学
SELECT * FROM student
WHERE english > 90
-- 查询总分大于200分的所有同学
SELECT * FROM student
WHERE (chinese + english + math) > 200
-- 查询math大于60 并且(and) id大于4的学生成绩
SELECT * FROM student
WHERE math >60 AND id > 4
-- 查询英语成绩大于语文成绩的同学
SELECT * FROM student
WHERE english > chinese
-- 查询总分大于200分 并且 数学成绩小于语文成绩 , 并且姓老的学生。
-- 小% 表示 名字以小开头的就可以
SELECT * FROM student
WHERE (chinese + english + math) > 200 AND
math < chinese AND `name` LIKE '小%'
-- 查询英语分数在 80-90之间的同学。
SELECT * FROM student
WHERE english >= 80 AND english <= 90;
SELECT * FROM student
WHERE english BETWEEN 80 AND 90; -- between .. and .. 是 闭区间
-- 查询数学分数为89,90,91的同学。
SELECT * FROM student
WHERE math = 89 OR math = 90 OR math = 91;
SELECT * FROM student
WHERE math IN (89, 90, 91);
-- 查询所有姓大的学生成绩。
SELECT * FROM student
WHERE `name` LIKE '大%'
子句排序查询
SELECT column_name,column_name
FROM table_name
ORDER BY column_name,column_name ASC|DESC;
#ORDER BY 关键字用于对结果集按照一个列或者多个列进行排序。
#ORDER BY 关键字默认按照升序对记录进行排序。如果需要按照降序对记录进行排序,可以使用DESC关键字。
#ORDER BY 关键字应该位与select语句的结尾。
小栗子:
-- 对数学成绩排序后输出【升序】。
SELECT * FROM student
ORDER BY math;
-- 对总分按从高到低的顺序输出 [降序] -- 使用别名排序
SELECT `name` , (chinese + english + math) AS total_score FROM student
ORDER BY total_score DESC;
-- 对姓大的学生成绩[总分]排序输出(升序) where + order by
SELECT `name`, (chinese + english + math) AS total_score FROM student
WHERE `name` LIKE '大%'
ORDER BY total_score;
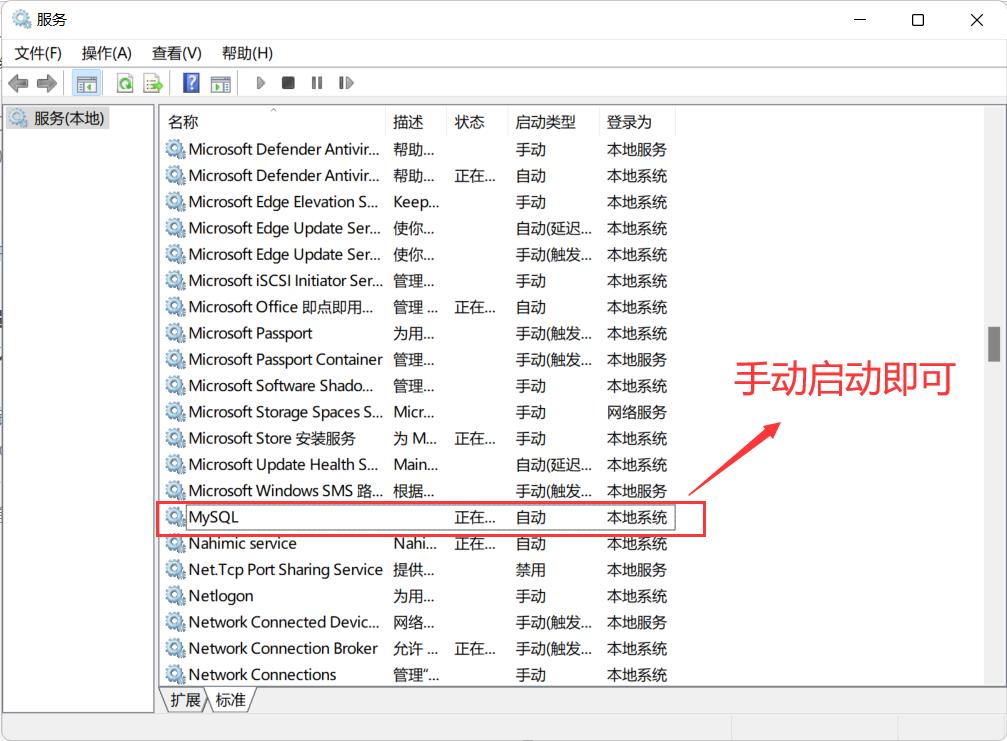
今天遇到了一个错误,PS:连接本地mysql时出现2003-Can’t connect to MySql server on ‘localhost’(10061)错误。
提供一种解决思路:
1.Windows+R ,输入services.msc回车
2.手动启动 mysql 服务项
以上是关于MySQL基础教程---数据表相关操作的主要内容,如果未能解决你的问题,请参考以下文章