node.js事件轮询
Posted jay-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了node.js事件轮询相关的知识,希望对你有一定的参考价值。
事件轮询(引用)
事件轮询是node的核心内容。一个系统(或者说一个程序)中必须至少包含一个大的循环结构(我称之为“泵”),它是维持系统持续运行的前提。nodejs中一样包含这样的结构,我们叫它“事件轮询”,它存在于主线程中,负责不停地调用开发者编写的代码。我们可以查看nodejs官方网站上对nodejs的说明:
Node is similar in design to and influenced by systems like Ruby\'s Event Machine or Python\'s Twisted. Node takes the event model a bit further, it presents the event loop as a language construct instead of as a library. In other systems there is always a blocking call to start the event-loop. Typically one defines behavior through callbacks at the beginning of a script and at the end starts a server through a blocking call like EventMachine::run(). In Node there is no such start-the-event-loop call. Node simply enters the event loop after executing the input script. Node exits the event loop when there are no more callbacks to perform. This behavior is like browser javascript -— the event loop is hidden from the user.
node在设计上类似于Ruby的Event Machine或Python的Twisted等系统,并受其影响。 node进一步采用事件模型,它将事件循环呈现为语言构造而不是库。 在其他系统中,总是有一个阻塞调用来启动事件循环。 通常,通过在脚本开头的回调定义行为,最后通过阻塞调用(如EventMachine :: run())启动服务器。 在Node中没有这样的启动 - 事件循环调用。 node在执行输入脚本后简单地进入事件循环。 当没有更多的回调要执行时,Node退出事件循环。 这种行为就像浏览器JavaScript - 事件循环对用户是隐藏的。
从中可以看出,其他语言当存在阻塞的时候才会调用event loop,而node会在输入脚本的时候就会进入事件循环。
我们可以看到,在nodejs中这个“循环”结构对开发者来讲是不可见的。(借用别人的图)
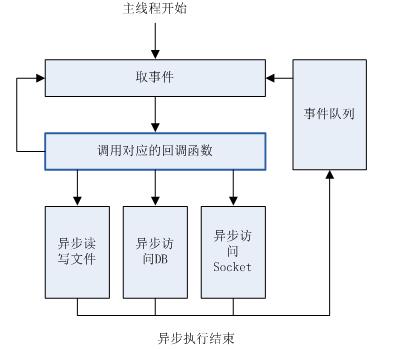
如上图所示,每个异步函数执行结束后,都会在事件队列中追加一个事件(同时保存一些必要参数)(这里面有如下内容1.node怎么判断这个异步程序执行完了 2.执行完后,是怎么放入到事件队列中的)。事件轮询下一次循环便可取出事件,然后会调用(这个事件对应的)异步方法对应的回调函数(参数,Q:怎么区分这个回调函数是属于这个事件(或者说是这个异步方法的?))。这样一来,nodejs便能保证开发者编写的每行代码(每个回调)均在主线程中执行。
1.异步程序的过程中,如果出错,则该异步结果会直接进入到事件队列中,传入的参数将会是回调函数的第一个参数。
2.如果开发者在回调函数中调用了阻塞方法,那么整个事件轮询就会阻塞,事件队列中的事件得不到及时处理,node就会卡死,随后就会崩溃。正因为这样,nodejs中的一些库方法均是异步的,也提倡用户调用异步方法。如果在回调函数中产生错误,则从 调用对应的异步函数 -> 取事件 造成阻塞,node就会崩溃。
其实看到这里的时候,如果有对Windows编程(尤其对Windows界面编程)比较了解的读者可能已经联想到了Windows消息循环。
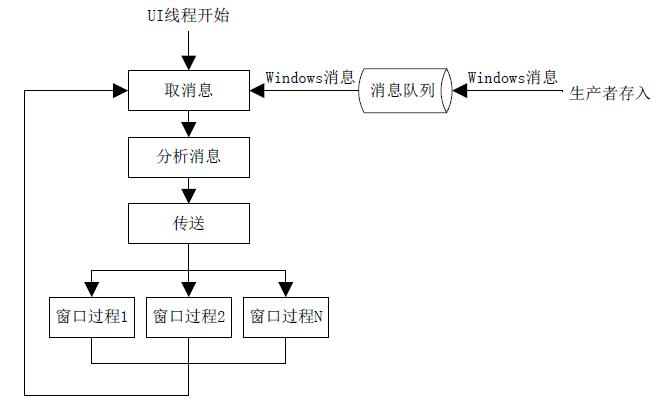
没错,nodejs中的事件轮询原理跟Windows消息循环的原理类似。开发者编写的代码均运行在主线程中,如果你编写了阻塞代码,在Windows桌面程序中,由于消息得不到及时处理,界面就会卡死。
咱们再来看一下下面的nodejs代码:
var fs = require(\'fs\');
fs.readFile(\'hello.txt\', function (err, data) { //异步读取文件
console.log("read file end");
});
while(1){
console.log("call readFile over");
}
如上,虽然我们使用异步方法读取文件,但是文件读取完毕后“read file end”永远不会输出,也就是说readFile方法的回调函数不会执行。原因很简单,因为后面的主进程的while循环一直没退出,导致下一次事件轮询不能开始,所以回调函数不能执行(包括其他所有回调)。事实再次证明,开发者编写的所有代码均只能运行在同一线程之中(姑且称之为主线程吧)。
关于异步方法
所谓异步方法,就是调用该方法不会阻塞调用线程,哪怕方法内部要进行耗时操作。你可以理解为方法内部单独开辟了一个新线程去处理任务(主进程一直进行工作,而开的新线程处理异步的工作),而调用异步方法仅仅是开启这个新线程。下面的代码模拟一个异步方法的内部结构(仅仅是模拟,不代表实际):
在.NET中,每个异步方法的回调函数均在另外一个线程中执行(非调用线程),而在nodejs中,每个异步方法的回调函数仍然还在调用线程上(可以理解为主线程)执行。至于为什么,大家可以看一下前面讲事件轮询的部分,nodejs中每个回调函数均由主线程中的事件轮询来调用。这样才能保证在nodejs中,开发者编写的任何代码均在同一个线程中运行(所谓的单线程)。http://www.cnblogs.com/xiaozhi_5638/p/4268223.html
消息循环就应该是"泵",消息队列就应该是"数据容器",Windows消息就应该是"数据",而窗口过程就应该是"处理者",那么整个结构应该
既然框架能够保证最终应用程序的持续正常工作,按照本章前面的结论,那说明框架内部必然有一种结构能够重复性处理问题,这种结构就是"泵",泵的"持续性"和"动力性"特性完全满足框架的需求。如果需要将这种抽象关系图形化显示出来,见下图10-18:
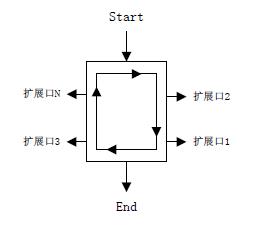
既然我们最终的应用程序是在框架的基础之上扩展出来的,这说明应用程序的主要运行逻辑、主要的流程控制均是由框架决定的,框架控制应用程序的启动、决定主要的流程转向,负责调用框架使用者编写的"扩展代码",总之,框架能够保证最终应用程序的持续正常工作。
这些 扩展代码 就是经常说到的 Hook函数(或者一些属性),然后模板的其他的内容就是写死的。只有Hook是固定的。
以上是关于node.js事件轮询的主要内容,如果未能解决你的问题,请参考以下文章