python爬虫应该怎样使用代理IP
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python爬虫应该怎样使用代理IP相关的知识,希望对你有一定的参考价值。
先网站上在线提取代理IP,提取数量、代理协议、端口位数等都可以自定义
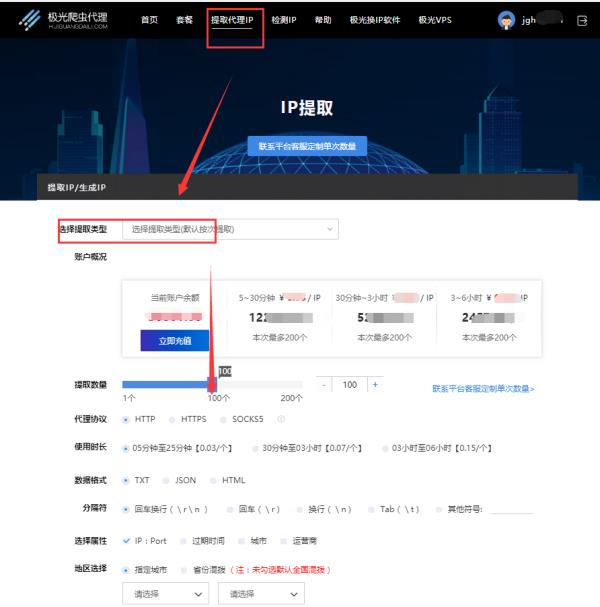
请点击输入图片描述
然后 生成api链接,复制或打开链接,就可以使用提取的ip了
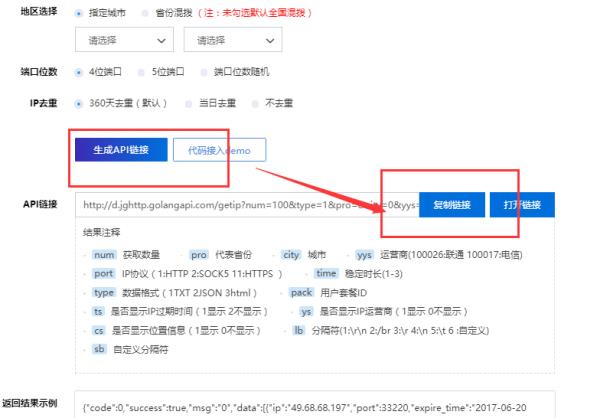
请点击输入图片描述
参考技术A 打开软件使用就行了极光ip代理,高匿名,延迟低
线路多……
如何处理python爬虫ip被封
1、放慢爬取速度,减小对于目标网站造成的压力。但是这样会减少单位时间类的爬取量。第二种方法是通过设置IP等手段,突破反爬虫机制继续高频率爬取。网站的反爬机制会检查来访的IP地址,为了防止IP被封,这时就可以使用HTTP,来切换不同的IP爬取内容。使用代理IP简单的来讲就是让代理服务器去帮我们得到网页内容,然后再转发回我们的电脑。要选择高匿的ip,IPIDEA提供高匿稳定的IP同时更注重用户隐私的保护,保障用户的信息安全。
2、这样目标网站既不知道我们使用代理,更不会知道我们真实的IP地址。
3、建立IP池,池子尽可能的大,且不同IP均匀轮换。
如果你需要大量爬去数据,建议你使用HTTP代理IP,在IP被封掉之前或者封掉之后迅速换掉该IP,这里有个使用的技巧是循环使用,在一个IP没有被封之前,就换掉,过一会再换回来。这样就可以使用相对较少的IP进行大量访问。以上就是关于爬虫IP地址受限问题的相关介绍。 参考技术A
从程序本身是无法解决的。
可以试一下以下方式:
(1)伪装消息头,伪装成浏览器,使用urllib.request.build_opener添加User-agent消息头,示例如下:
opener.addheaders = [('User-agent','Mozilla/5.0 (SymbianOS/9.3; Series60/3.2 NokiaE72-1/021.021; ' +
'Profile/MIDP-2.1 Configuration/CLDC-1.1 ) AppleWebKit/525 (KHTML, like Gecko)' +
' Version/3.0 BrowserNG/7.1.16352'),
('Cookie', 自定义cookie信息),
('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8')]
(2)自己装几个虚拟机,分别不同IP在上面跑爬虫的时候频率别太高了,加个过程里加个 time.sleep(1)或(2),通常情况只要频率不是太高是无法区别是正常阅读还是爬东西的。
(3)找proxy用代理,respose发现异常就换新的代理IP
(4)如果为拨号,则被封后断线重新拔号,更换新IP
如何防止ip被限制
1.对请求Headers进行限制
这应该是最常见的,最基本的反爬虫手段,主要是初步判断你是不是真实的浏览器在操作。
这个一般很好解决,把浏览器中的Headers信息复制上去就OK了。
特别注意的是,很多网站只需要userAgent信息就可以通过,但是有的网站还需要验证一些其他的信息,例如知乎,有一些页面还需要authorization的信息。所以需要加哪些Headers,还需要尝试,可能还需要Referer、Accept-encoding等信息。
2.对请求IP进行限制
有时我们的爬虫在爬着,突然冒出页面无法打开、403禁止访问错误,很有可能是IP地址被网站封禁,不再接受你的任何请求。
3.对请求cookie进行限制
当爬虫遇到登陆不了、没法保持登录状态情况,请检查你的cookie.很有可能是你爬虫的cookie被发现了。
以上便是关于反爬虫策略,对于这几个方面,爬虫要做好应对的方法,不同的网站其防御也是不同的。 参考技术C 从程序本身是无法解决的。
可以试一下以下方式:
(1)伪装消息头,伪装成浏览器,使用urllib.request.build_opener添加User-agent消息头,示例如下:
addheaders = [('User-agent',
'Mozilla/5.0 (SymbianOS/9.3; Series60/3.2 NokiaE72-1/021.021; ' +
'Profile/MIDP-2.1 Configuration/CLDC-1.1 ) AppleWebKit/525 (KHTML, like Gecko)' +
' Version/3.0 BrowserNG/7.1.16352'),
('Cookie', 自定义cookie信息),
('Accept', 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8')]
(2)自己装几个虚拟机,分别不同IP在上面跑爬虫的时候频率别太高了,加个过程里加个 time.sleep(1)或(2),通常情况只要频率不是太高是无法区别是正常阅读还是爬东西的。
(3)找proxy用代理,respose发现异常就换新的代理IP
(4)如果为拨号,则被封后断线重新拔号,更换新IP 参考技术D 这个需要代理ip软件吧,我看我们公司的技术都会用芝麻HTTP代理去做爬虫
以上是关于python爬虫应该怎样使用代理IP的主要内容,如果未能解决你的问题,请参考以下文章
Python爬虫:运用多线程IP代理模块爬取百度图片上小姐姐的图片
Python爬虫:运用多线程IP代理模块爬取百度图片上小姐姐的图片