种豆得豆,种瓜得瓜 : 你的网络就是一片自留地
Posted 卓晴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了种豆得豆,种瓜得瓜 : 你的网络就是一片自留地相关的知识,希望对你有一定的参考价值。

▲ 图1.1 记录辐射脉冲的计数器上的数码管数字
§01 数码管识别
1.1 背景介绍
记得在前年利用Python软件处理图片中 数码管数字识别 问题的时候,是为了能够方便处理 基于放射性烟雾传感器放射脉冲计数的问题。后来利用相同的方式对于 红外测温计 显示的数字进行处理,也取得了很好的效果。
但在使用过程中也发现这种机遇图像处理的方式要求设定图像处理参数较多,对图像摄取光线要求较大。利用 卷积神经网络识别数码管 具有很好的灵活性。原来设想准备应用其作为 今年人工神经网络课程第四次作业 的练习题,后来因为临时原因没有能够将数据集合准备好,也就没有将它列为作业题目。
为了给以后课程准备材料,在昨天晚上从网络上寻找了300多个带有七段数字的图片,截取下来用于训练神经网络的数据集合。下面是部分图片。

▲ 图1.2 网络上搜集到部分数码管图片
将这些图片中每个数字分割之后,转换成48×48的灰度图片,总共有1335个数字,再按照不同放大尺度又扩增了4倍,形成了初步的训练集合。
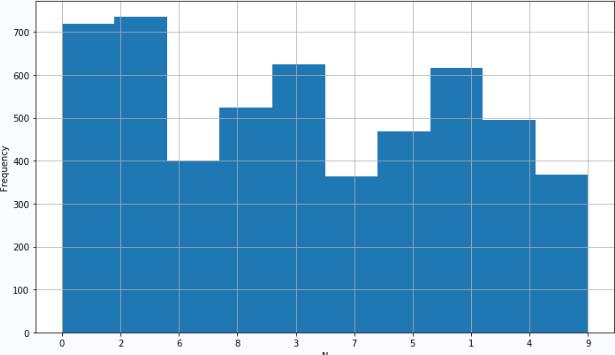
▲ 图1.1.3 训练集合中十个数字的分布
这学期百度公司给我的人工神经网络课程学生赠送了一些算力卡,手边还有一些计时,利用AI Studio上的算力,将上述集合训练标准的LeNet网络。借助于至尊版配置的GPU算力,前后不到3分钟,将LeNet训练的妥妥的。
1.2 奇怪的问题
1.2.1 问题的提出
经过测试效果还不错,但有一个简单的图片的识别结果却存在这一个莫名其妙的问题。下面图片内容被 识别为“07729”,第一个简单的数字“1”被识别成“0”,这个结果很出乎以外。

▲ 图1.3 图片内容被识别为07729
查看了一下分割后,神经网络输入的图片48×48灰度图,每个数字也没有太大的问题。特别是前面的数字“1”相当完整。
那么问题来了:为什么数字1会被识别成0?

▲ 图1.4 分割后用于网络模型输入的灰度图片:48×48
不像利用计算机图形算法,可以通过算法的中间结果来逐步定位上面的“1”数字识别错误的问题。由CNN给出的结果,与网络中间层的计算结果关系的可解释性不强,这是利用神经网络结果图像识别问题过程中的一个麻烦的地方。
1.2.2 初步分析
初步分析,上述图片中的“1”被识别成“0”的主要原因是图片中的1笔画的位置过于靠近图片的中心。
在七段数码管显示数字的时候,数字1往往使用最右侧上下两段来显示,因此在前面所搜集到的图片中,所有数字1对应的图像,笔画应该都位于图片的最右侧。而上述图像中,它来自于一个四位半的计数器,它的最左边实际上只能显示数字“1”,因此在图像分割的时候,分割出来的1的笔画位于图像的中心,这在网络训练数据集合中没有,因此就被错误分类为“0”。
1.2.3 分析验证
为了验证模型出现的问题,将原来图像的最左边,补上一小段背景颜色,使得分割后的数字“1”的笔画位于图像的靠右边,如下图所示。经过测试发现训练好的CNN识别结果正确了。

▲ 图1.2.3 图像左边补充背景颜色后,分割数字结果
1.3 如何改进?
对于数字1,在七段数码显示中的确会存在上面的问题。对于一些三位半、四位半、五位半显示的仪表,最左边往往留给数字1的宽度很窄。为了解决模型对1错判的问题,需要对原来数据集中所有的数字1进行平移扩增。也就是将它们 往右平移 不同的位置,添加到训练数据集合中。

▲ 图1.3.1 将数字1往左平移不同的距离
将训练数字几何中的所有1的图片都分别往左平移12, 24 个像素,增加到原来训练数据集合中,重新训练LeNet网络。对于训练后的结果测试,可以验证前面碰到的图片识别的问题解决了。
如果对所有的数字都进行平移扩增,将原本5000多个样本扩增到40000多个,训练后的网络的性能可以的达到99.1%。在所有最初的303个数码管图像识别中,只有两个图片识别错误。
- 图片被识别为:1824。说实在的,这个图片被错误识别也是挺奇怪的。

▲ 图1.3.2 图片被识别为:1824
- 图片被识别为:1466。下面这个图片识别错误的主要原因是原始的图片分辨率太低了。

▲ 图1.3.3 图片被识别为:1466
§02 种瓜得瓜
通过上述分析可以看到,利用深度学习的方式解决图像识别问题,相比于传统机器视觉方面,它具有更大的应用灵活性,但在学习算法设计过程中,对于训练数据及he 有着更强的要求。
需要能够根据在实际应用过程中可能碰到的场景,对于标准的图片集合进行增强。这样才能够使得训练模型有着更强的推广泛化的能力。
“种瓜得瓜,种豆得豆”。你的深度学习网络就像一片自留地,随着你播种的数据不同,它长出来的功能也不一样。
■ 相关文献链接:
● 相关图表链接:
- 图1.1 记录辐射脉冲的计数器上的数码管数字
- 图1.2 网络上搜集到部分数码管图片
- 图1.1.3 训练集合中十个数字的分布
- 图1.3 图片内容被识别为07729
- 图1.4 分割后用于网络模型输入的灰度图片:48×48
- 图1.2.3 图像左边补充背景颜色后,分割数字结果
- 图1.3.1 将数字1往左平移不同的距离
- 图1.3.2 图片被识别为:1824
- 图1.3.3 图片被识别为:1466
◎ 公众号(TSINGHUAZHUOQING)留言:
-
ZhouJin:可以在训练的时候对数据做预处理,使得网络具有更好的泛化效果 -
o_x:还是怕出错 万一识别错误了 -
🌛:啥时候种百度车模可以发货- 作者: 据说是过了年。
-
Fighting:同款电机,这个电机后面有带驱动,但也有不带驱动的款式,大概5块钱左右一个(淘宝说拆机)。- 作者: 如果带驱动就先放弃吧。考虑自己实现驱动。
-
z里先森:看原文使用的是lenet,是否增加网络深度能改善上述问题呢? -
刘明坤:最近参加了个阿里云比赛,有点感触,也可以尝试加入一些高斯和椒盐噪声的样本或者加入fgsm对抗样本提升模型的可靠性 -
随风而起:卓大,往返赛道三岔要怎么跑是一个过去另外一个回来吗?- 作者: 往返三岔路,按照规则中给出的图形,是一个往返端口,车模通过该岔道口原路返回。
-
嘉:卓大多车跟随可以两辆车都用stc或wch吧,规则的意思应该不会是一辆用一种芯片吧- 作者: 现在公布的规则要求:对于跟随的两辆车,至少有一辆使用STC,所以:(1)两个跟随车都使用STC;(2)一个使用STC,一个使用WCH,这两个方案都是允许的。
-
有何不可:卓大多车跟随可以两辆车都用stc或wch吧,规则的意思应该不会是一辆用一种芯片吧- 作者: 现在公布的规则要求:对于跟随的两辆车,至少有一辆使用STC,所以:(1)两个跟随车都使用STC;(2)一个使用STC,一个使用WCH,这两个方案都是允许的。但(3)l个都使用WCH这个方案是不允许的。
以上是关于种豆得豆,种瓜得瓜 : 你的网络就是一片自留地的主要内容,如果未能解决你的问题,请参考以下文章