脑裂以及Redis主从同步中的坑
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了脑裂以及Redis主从同步中的坑相关的知识,希望对你有一定的参考价值。
参考技术A所谓的脑裂,就是指在主从集群中,同时有两个主节点,它们都能接收写请求。而脑裂最直接的影响,就是客户端不知道应该往哪个主节点写入数据,结果就是不同的客户端会往不同的主节点上写入数据。而且,严重的话,脑裂会进一步导致数据丢失。
主库是由于某些原因无法处理请求,也没有响应哨兵的心跳,才被哨兵错误地判断为客观下线的。结果,在被判断下线之后,原主库又重新开始处理请求了,而此时,哨兵还没有完成主从切换,客户端仍然可以和原主库通信,客户端发送的写操作就会在原主库上写入数据了。下图展示了脑裂的发生过程。
Redis 提供了两个配置项来限制主库的请求处理,分别是 min-slaves-to-write 和 min-slaves-max-lag。
这两个配置项组合后的要求是, 主库连接的从库中至少有 N 个从库,和主库进行数据复制时的 ACK 消息延迟不能超过 T 秒,否则,主库就不会再接收客户端的请求了 。
假设我们将 min-slaves-to-write 设置为 1,把 min-slaves-max-lag 设置为 12s,把哨兵的 down-after-milliseconds 设置为 10s,主库因为某些原因卡住了 15s,导致哨兵判断主库客观下线,开始进行主从切换。同时,因为原主库卡住了 15s,没有一个从库能和原主库在 12s 内进行数据复制,原主库也无法接收客户端请求了。这样一来,主从切换完成后,也只有新主库能接收请求,不会发生脑裂,也就不会发生数据丢失的问题了。
主从数据不一致,就是指客户端从从库中读取到的值和主库中的最新值并不一致。举个例子,假设主从库之前保存的用户年龄值是 19,但是主库接收到了修改命令,已经把这个数据更新为 20 了,但是,从库中的值仍然是 19。那么,如果客户端从从库中读取用户年龄值,就会读到旧值。
出现主从数据不一致的主要原因是 主从库间的命令复制是异步进行的。 从库会滞后执行数据同步命令的原因主要有两个
应对主从数据不一致的解决方案:
我们可以开发一个监控程序,先用 INFO replication 命令查到主、从库的进度,然后,我们用 master_repl_offset 减去 slave_repl_offset,这样就能得到从库和主库间的复制进度差值了。 如果某个从库的进度差值大于我们预设的阈值,我们可以让客户端不再和这个从库连接进行数据读取,这样就可以减少读到不一致数据的情况 。不过,为了避免出现客户端和所有从库都不能连接的情况,我们需要把复制进度差值的阈值设置得大一些。可以周期性地运行这个流程来监测主从库间的不一致情况。
Redis 同时使用了两种策略来删除过期的数据,分别是 惰性删除策略和定期删除策略 。关于删除策略可以参考: https://www.jianshu.com/p/183e310d182d
如果你使用的是 Redis 3.2 之前的版本,那么,从库在服务读请求时,并不会判断数据是否过期,而是会返回过期数据。在 3.2 版本后,Redis 做了改进,如果读取的数据已经过期了,从库虽然不会删除,但是会返回空值,这就避免了客户端读到过期数据。所以,在应用主从集群时, 尽量使用 Redis 3.2 及以上版本。
设置数据过期时间的命令一共有 4 个,我们可以把它们分成两类:
当主从库全量同步时,如果主库接收到了一条 EXPIRE 命令,那么,主库会直接执行这条命令。这条命令会在全量同步完成后,发给从库执行。而从库在执行时,就会在当前时间的基础上加上数据的存活时间,这样一来,从库上数据的过期时间就会比主库上延后了。
假设当前时间是 2021 年 5 月 5 日晚上 9 点,主从库正在同步,主库收到了一条命令:EXPIRE testkey 60,这就表示,testkey 的过期时间就是 5 日晚上 9 点 1 分,主库直接执行了这条命令。
但是,主从库全量同步花费了 2 分钟才完成。等从库开始执行这条命令时,时间已经是 9 点 2 分了。而 EXPIRE 命令是把 testkey 的过期时间设置为当前时间的 60s 后,也就是 9 点 3 分。如果客户端在 9 点 2 分 30 秒时在从库上读取 testkey,仍然可以读到 testkey 的值。但是,testkey 实际上已经过期了。
为了避免这种情况, 在业务应用中使用 EXPIREAT/PEXPIREAT 命令,把数据的过期时间设置为具体的时间点,避免读到过期数据。
redis集群(主从)脑裂及解决方案
什么是redis的集群脑裂?
redis的集群脑裂是指因为网络问题,导致redis master节点跟redis slave节点和sentinel集群处于不同的网络分区,此时因为sentinel集群无法感知到master的存在,所以将slave节点提升为master节点。此时存在两个不同的master节点,就像一个大脑分裂成了两个。
集群脑裂问题中,如果客户端还在基于原来的master节点继续写入数据,那么新的master节点将无法同步这些数据,当网络问题解决之后,sentinel集群将原先的master节点降为slave节点,此时再从新的master中同步数据,将会造成大量的数据丢失。
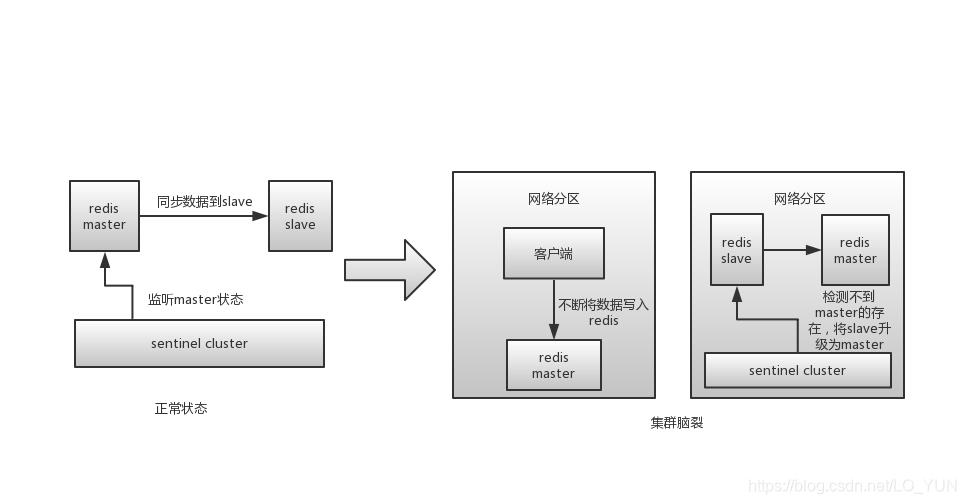
解决方案
redis的配置文件中,存在两个参数
min-slaves-to-write 3
min-slaves-max-lag 10
第一个参数表示连接到master的最少slave数量
第二个参数表示slave连接到master的最大延迟时间
按照上面的配置,要求至少3个slave节点,且数据复制和同步的延迟不能超过10秒,否则的话master就会拒绝写请求,配置了这两个参数之后,如果发生集群脑裂,原先的master节点接收到客户端的写入请求会拒绝,就可以减少数据同步之后的数据丢失。(也就是说配置的节点数量和小于延迟时间都满足的情况下才能正常写入,否则就拒绝)
注意:较新版本的redis.conf文件中的参数变成了。
min-replicas-to-write 3
min-replicas-max-lag 10
redis中的异步复制情况下的数据丢失问题也能使用这两个参数。
以上是关于脑裂以及Redis主从同步中的坑的主要内容,如果未能解决你的问题,请参考以下文章