hadoop入门容易吗?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop入门容易吗?相关的知识,希望对你有一定的参考价值。
hadoop入门容易吗?
不是很容易,但是推荐一些Hadoop家族系列文章,主要介绍Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括,YARN, Hcatalog, Oozie, Cassandra, Hama, Whirr, Flume, Bigtop, Crunch, Hue等。一、学习路线图
Hadoop家族学习路线图 开篇必读
Hive学习路线图
Mahout学习路线图
二、编程实践
Hadoop历史版本安装
用Maven构建Hadoop项目
Hadoop编程调用HDFS
用Maven构建Mahout项目
Mahout推荐算法API详解
用MapReduce实现矩阵乘法
从源代码剖析Mahout推荐引擎
Mahout分步式程序开发 基于物品的协同过滤ItemCF
Mahout分步式程序开发 聚类Kmeans
PageRank算法并行实现
三、案例分析
海量Web日志分析 用Hadoop提取KPI统计指标
用Hadoop构建电影推荐系统
用Mahout构建职位推荐引擎
Mahout构建图书推荐系统
PeopleRank从社交网络中发现个体价值 参考技术A 想学习Hadoop,可是苦于自己没有任何的基础,不知道该如何bai下手,也不知道自己能不能学会。其实零基础学习hadoop,没有想象的那么困难。现在我把自己的学习思路整理一下,希望对大家有帮助。
怎么才能学好Hadoop,进入云的世界,这里给几点建议:
1.打好你的Java基础,C我就不说了,那是基本功。
2.详细研究,理解一下现在大型网站包括Sina,腾讯网(门户),Weibo,天猫,京东(电商)的架构与实现,先从自己的角度去理解,然后去跟实际情况做比对,提升自己对数据和技术的敏感程度。在这个阶段,如果能分门别类的规划出不同类型网站的需求和使用的特定方向的技术,对“云”和“大数据”的理解就更加透彻而非表层停留。
3.科班的同学,在学校的以基础为根基,在公司的以业务为导向,这样的技术才不盲目,这样的技术才脚踏实地。对很多人来说,技术都不是一生的职业导向,那么,提升自己的眼界,站在更高的角度思考问题就显得尤为重要,从自己,到团队,公司,再到整个业界,眼界宽广了,技术也就是你的左膀右臂。
Hadoop分为两个大块:HDFS和MapReduce。
HDFS - Hadoop Distributed FileSystem。这个概念很好,但是其实我不觉得很实用。但是如果你之后要往Non SQL方面深入的话这个还是很重要,HDFS是HBASE的基础,Hbase又可以延伸到Big Table,DynamoDB,Mango等。HDFS概念不难,Hadoop The Definitive Guide里面讲的很清楚,看书就好。
MapReduce -前面说最好看英文版,因为不管中文怎么翻译,Map,Reduce都是没办法像读英文那样容易理解的。这里面有个YARN的概念,是最最最重要的。MapReduce是管数据怎么流动的,YARN是管集群中的资源怎么分配的。除了YARN以外,MapReduce还有几个很重要的概念,比如Partition, combine, shuffle, sort,都在书里很小的位置,但是都对理解整个MapReduce非常有帮助。
关于Hadoop的使用方式:
感觉现在各个公司使用Hadoop的方式都不一样,主要我觉得有两种吧。
第一种是long running cluster形式,比如Yahoo,不要小看这个好像已经没什么存在感的公司,Yahoo可是Hadoop的元老之一。这种就是建立一个Data Center,然后有几个上千Node的Hadoop Cluster一直在运行。比较早期进入Big Data领域的公司一般都在使用或者使用过这种方式。
另一种是只使用MapReduce类型。毕竟现在是Cloud时代,比如AWS的Elastic MapReduce。这种是把数据存在别的更便宜的地方,比如s3,自己的data center, sql database等等,需要分析数据的时候开启一个Hadoop Cluster,Hive/Pig/Spark/Presto/Java分析完了就关掉。不用自己做Admin的工作,方便简洁。
所以个人如果要学Hadoop的话我也建议第二种,AWS有免费试用时间,可以在这上面学习。最重要的是你可以尝试各种不同的配置对于任务的影响,比如不同的版本,不同的container size,memory大小等等,这对于学习Spark非常有帮助。
我直接是白手起家搞hadoop的,没有看权威指南,不懂就google之。我开始也没研究源代码,我先研究Hadoop是怎么跑起来的,怎么工作的。然后过了一段时间,我去看《Hadoop权威指南》,和实践相印证,上手很快。Hadoop这个课题太大,人家花了几年时间研究出来的,你想搞个毕设就想剖析清楚,这个有点不现实。
我的建议是,只研究hadoop的一到两个模块就行了。在这几个中间选一两个研究就可以了。
目前炒的很热,可以说是“如日中天”,好像不会Hadoop、不知道MapReduce就不是搞大规模数据处理似的;貌似数据库的一些人不喜欢Hadoop。
随着互联网或者数据库数据量的不断增大,分布式真的可以替代数据中心吗?这个值得考虑,毕竟框架是Google提出来的,提出时势必会考虑google自身的技术和经济能力,试问当下有几个公司有google的实力?
有人说过(具体名字忘了),在中国,云计算就是忽悠,是炒作;也有人说,云计算是必然的发展趋势,毕竟好多公司都在这么玩。在Copy to China的年代,云计算到底是什么,好像很难说清楚吧?
结论:当下很火,找工作绝对不成问题,看这种形式,似乎也是未来发展的方向;但是这种行业预测的问题,大佬们都经常犯错,我们没到那个级别,还跟着瞎预测啥啊,好好练好内功,这才是关键。
Hadoop入门
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
Hadoop入门
1 Hadoop概述
1.1 Hadoop是什么
-
Hadoop是一个由Apache基金会所开发的
分布式系统基础架构。 -
主要解决,海量数据的
存储和海量数据的分析计算问题。 -
广义上来说,Hadoop通常是指一个更广泛的概念——Hadoop生态圈。
1.2 Hadoop 发展历史(了解)
-
Hadoop创始人Doug Cutting,为 了实 现与Google类似的全文搜索功能,他在Lucene框架基础上进行优 化升级,查询引擎和索引引擎
-
2001年年底Lucene成为Apache基金会的一个子项目
-
对于海量数据的场景,Lucene框 架面 对与Google同样的困难,存 储海量数据困难,检 索海 量速度慢。
-
学习和模仿Google解决这些问题的办法 :微型版Nutch
-
可以说Google是Hadoop的思想之源(Google在大数据方面的三篇论文)
-
2003-2004年,Google公开了部分GFS和MapReduce思想的细节,以此为基础Doug Cutting等人用 了2年业余时间实现了DFS和MapReduce机制,使Nutch性能飙升。
-
2005 年Hadoop 作为 Lucene的子项目 Nutch的一部分正式引入Apache基金会。
-
2006 年 3 月份,Map-Reduce和Nutch Distributed File System (NDFS)分别被纳入到 Hadoop 项目 中,Hadoop就此正式诞生,标志着大数据时代来临。
-
名字来源于Doug Cutting儿子的玩具大象
1.3 Hadoop 三大发行版本(了解)
Hadoop 三大发行版本:Apache、Cloudera、Hortonworks。
Apache 版本最原始(最基础)的版本,对于入门学习最好。2006
Cloudera 内部集成了很多大数据框架,对应产品 CDH。2008
Hortonworks 文档较好,对应产品 HDP。2011
Hortonworks 现在已经被 Cloudera 公司收购,推出新的品牌 CDP。
1.4 Hadoop 优势(4 高)
-
高可靠性:Hadoop底层维护多个数据副本,所以即使Hadoop某个计算元 素或存储出现故障,也不会导致数据的丢失。 -
高扩展性:在集群间分配任务数据,可方便的扩展数以千计的节点。 -
高效性:在MapReduce的思想下,Hadoop是并行工作的,以加快任务处 理速度。 -
高容错性:能够自动将失败的任务重新分配。
1.5 Hadoop 组成(面试重点)
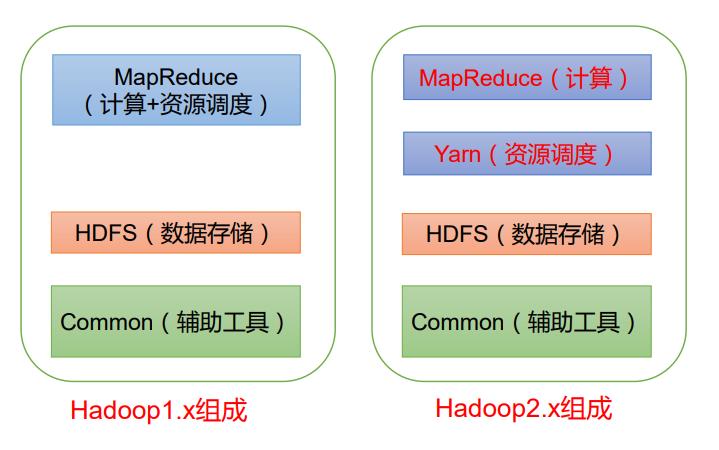
在 Hadoop1.x 时 代 , Hadoop中 的MapReduce同 时处理业务逻辑运算和资 源的调度,耦合性较大。 在Hadoop2.x时 代,增 加 了Yarn。Yarn只负责 资 源 的 调 度 , MapReduce 只负责运算。 Hadoop3.x在组成上没 有变化。
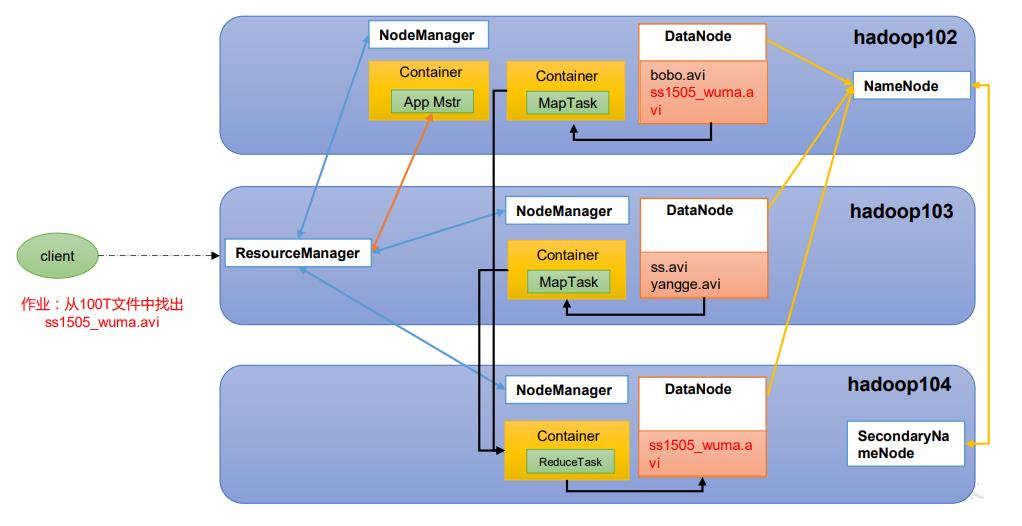
1.5.1 HDFS 架构概述
-
NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、 文件权限),以及每个文件的块列表和块所在的DataNode等。
-
DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
-
Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。
1.5.2 YARN 架构概述
MapReduce 将计算过程分为两个阶段:Map 和 Reduce
-
Map 阶段并行处理输入数据
-
Reduce 阶段对 Map 结果进行汇总
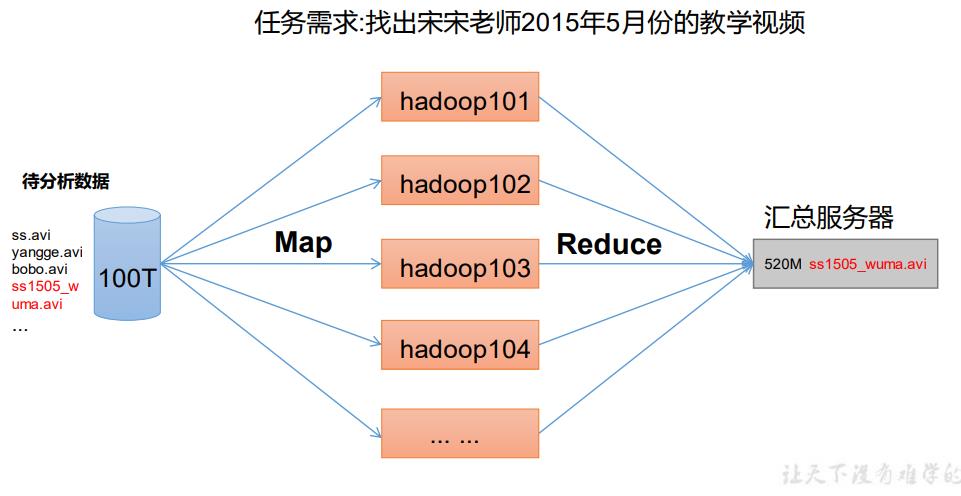
1.5.4 HDFS、YARN、MapReduce 三者关系
1.6 大数据技术生态体系
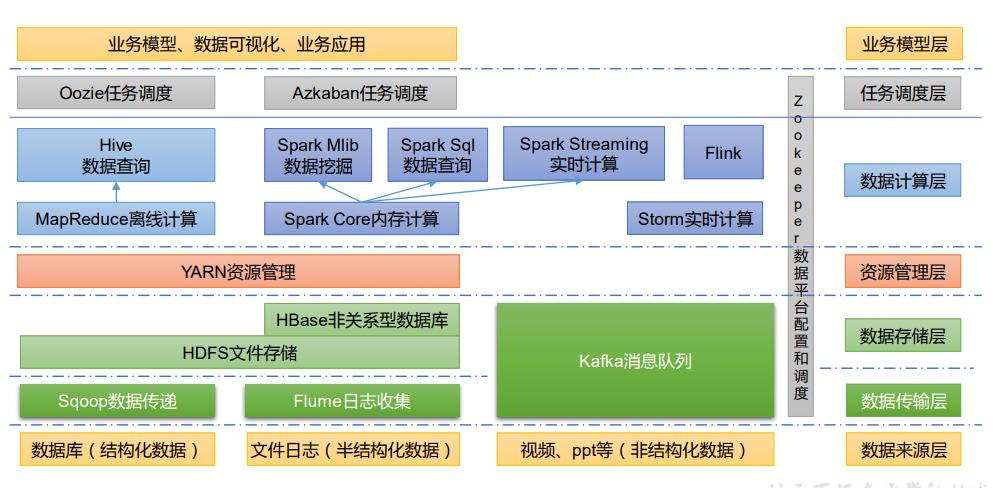
-
Sqoop:Sqoop 是一款开源的工具,主要用于在 Hadoop、Hive 与传统的数据库(MySQL) 间进行数据的传递,可以将一个关系型数据库(例如 :MySQL,Oracle 等)中的数据导进 到 Hadoop 的 HDFS 中,也可以将 HDFS 的数据导进到关系型数据库中。
-
Flume:Flume 是一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统, Flume 支持在日志系统中定制各类数据发送方,用于收集数据;
-
Kafka:Kafka 是一种高吞吐量的分布式发布订阅消息系统;
-
Spark:Spark 是当前最流行的开源大数据内存计算框架。可以基于 Hadoop 上存储的大数 据进行计算。
-
Flink:Flink 是当前最流行的开源大数据内存计算框架。用于实时计算的场景较多。
-
Oozie:Oozie 是一个管理 Hadoop 作业(job)的工作流程调度管理系统。
-
Hbase:HBase 是一个分布式的、面向列的开源数据库。HBase 不同于一般的关系数据库, 它是一个适合于非结构化数据存储的数据库。
-
Hive:Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张 数据库表,并提供简单的 SQL 查询功能,可以将 SQL 语句转换为 MapReduce 任务进行运 行。其优点是学习成本低,可以通过类 SQL 语句快速实现简单的 MapReduce 统计,不必开 发专门的 MapReduce 应用,十分适合数据仓库的统计分析。
-
ZooKeeper:它是一个针对大型分布式系统的可靠协调系统,提供的功能包括:配置维护、 名字服务、分布式同步、组服务等。
1.7 推荐系统框架图
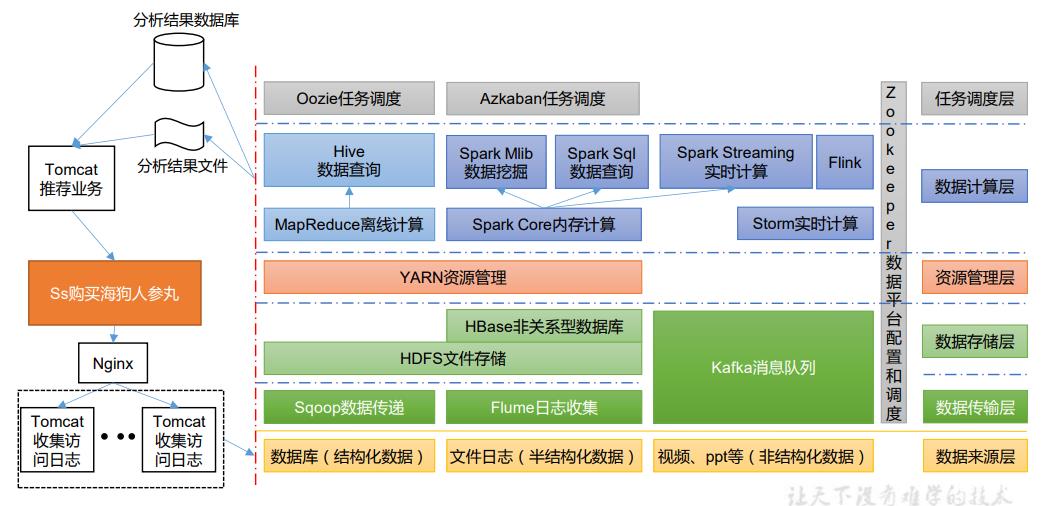
2 Hadoop 运行环境搭建(开发重点)
-
虚拟机要求: 4G内存,50G硬盘
-
要有jdk8环境
2.1 下载安装
#安装 epel-release
yum install -y epel-release
#net-tool:工具包集合,包含 ifconfig 等命令
yum install -y net-tools
#关闭防火墙
systemctl stop firewalld
#关闭防火墙开机启动
systemctl disable firewalld
#解压
tar -zxf hadoop-3.1.3.tar.gz
#移动
mv hadoop-3.1.3 /opt/
#配置环境变量
vim /etc/profile.d/my_env.sh
#放入以下内容
###########JavaEnvironment##############
export JAVA_HOME=/usr/local/src/jdk1.8.0_291
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
########################################
###########HadoopEnvironment############
export HADOOP_HOME=/opt/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
########################################
#测试Hadoop环境变量是否配置成功
hadoop version
#新建用户(hadoop不能用root启动)
useradd chen
passwd chen
2.2 Hadoop 目录结构
-
bin 目录:存放对 Hadoop 相关服务(hdfs,yarn,mapred)进行操作的脚本
-
etc 目录:Hadoop 的配置文件目录,存放 Hadoop 的配置文件
-
lib 目录:存放 Hadoop 的本地库(对数据进行压缩解压缩功能)
-
sbin 目录:存放启动或停止 Hadoop 相关服务的脚本
-
share 目录:存放 Hadoop 的依赖 jar 包、文档、和官方案例
3 Hadoop 运行模式
-
Hadoop 官方网站:http://hadoop.apache.org/
-
Hadoop 运行模式包括:
本地模式、伪分布式模式以及完全分布式模式。
➢ 本地模式:单机运行,只是用来演示一下官方案例。生产环境不用。 尚人工智能资料下载,可百度访问:尚硅谷官网
➢ 伪分布式模式:也是单机运行,但是具备 Hadoop 集群的所有功能,一台服务器模 拟一个分布式的环境。个别缺钱的公司用来测试,生产环境不用。
➢ 完全分布式模式:多台服务器组成分布式环境。生产环境使用。
3.1 本地运行模式(官方 WordCount)
#创建文件夹进行测试
cd /opt/hadoop-3.1.3/ && mkdir wcinput
#编辑word.txt文件
vim wcinput/word.txt
#插入以下内容
hadoop yarn
hadoop mapreduce
atguigu
atguigu
#examples:示例 使用wordcount 输入wcinput 输出wcoutput(输入路径不能存在)
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput/ wcoutput
#查看统计
cat wcoutput/part-r-00000
3.2 完全分布式运行模式(开发重点)
以前面的虚拟机作为模板,完全拷贝3台: 分别为hadoop141 hadoop142 hadoop143
scp(secure copy)安全拷贝
scp 可以实现服务器与服务器之间的数据拷贝。(from server1 to server2)
示例(-r 代表递归):
scp -r chen.txt root@hadoop142:/opt
rsync 远程同步工具
rsync 主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync 和 scp 区别:用 rsync 做文件的复制要比 scp 的速度快,rsync 只对差异文件做更 新。scp 是把所有文件都复制过去。
示例:
rsync -av /opt/hadoop-3.1.3/ root@hadoop142:/opt/hadoop-3.1.3/
xsync 集群分发脚本
#创建传本
mkdir -p /root/bin/ && vim /root/bin/xsync
#编写脚本
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop141 hadoop142 hadoop143
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
#给权限
chmod +x /root/bin/xsync
3.2.1 SSH 无密登录配置
#生成秘钥
ssh-keygen -t rsa
#拷贝秘钥到142 143
ssh-copy-id hadoop141
ssh-copy-id hadoop142
ssh-copy-id hadoop143
#连接142 143
ssh hadoop141
ssh hadoop142
ssh hadoop143
3.2.2 集群配置
集群部署规划
➢ NameNode 和 SecondaryNameNode 不要安装在同一台服务器
➢ ResourceManager 也很消耗内存,不要和 NameNode、SecondaryNameNode 配置在 同一台机器上。
| hadoop141 | hadoop142 | hadoop143 | |
|---|---|---|---|
| HDFS | NameNode | SecondaryNameNode | |
| DataNode | DataNode | DataNode | |
| YARN | ResourceManager | ||
| NodeManager | NodeManager | NodeManager |
配置文件说明
Hadoop 配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认 配置值时,才需要修改自定义配置文件,更改相应属性值。
默认配置文件:
| 要获取的默认文件 | 文件存放在 Hadoop 的 jar 包中的位置 |
|---|---|
| [core-default.xml] | hadoop-common-3.1.3.jar/core-default.xml |
| [hdfs-default.xml] | hadoop-hdfs-3.1.3.jar/hdfs-default.xml |
| [yarn-default.xml] | hadoop-yarn-common-3.1.3.jar/yarn-default.xml |
| [mapred-default.xml] | hadoop-mapreduce-client-core-3.1.3.jar/mapred-default.xml |
自定义配置文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml 四个配置文件存放在 $HADOOP_HOME/etc/hadoop 这个路径上,用户可以根据项目需求重新进行修改配置。
配置集群
配置 core-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop141:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.1.3/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 chen -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>chen</value>
</property>
</configuration>
配置 hdfs-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop141:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop143:9868</value>
</property>
</configuration>
配置 yarn-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MR 走 shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop142</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
配置 mapred-site.xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置 workers(默认localhost,删掉)
hadoop141
hadoop142
hadoop143
在集群上分发配置好的 Hadoop 配置文件
xsync /opt/hadoop-3.1.3
启动集群
#进入sbin目录
cd /opt/hadoop-3.1.3/sbin/
#启动集群(不能用root启动,会报错)
./start-dfs.sh
#浏览器访问
192.168.59.141:9870
在配置了 ResourceManager 的节点(hadoop142)启动 YARN
#进入目录
cd /opt/hadoop-3.1.3/sbin/
#启动yarn(也是不能root登入)
./start-yarn.sh
3.2.3 集群基本测试
上传文件到集群
#创建文件夹
hadoop fs -mkdir /wcinput
#上传文件到hadoop(前面的wcinput是需要上传的本地文件,后面的wcinput是上传到hadoop的目录)
hadoop fs -put wcinput/word.txt /wcinput
#上传大文件测试
hadoop fs -put /opt/jdk-8u212-linux-x64.tar.gz /
#查看 HDFS 文件存储路径
cd /opt/hadoop-3.1.3/data/dfs/data/current/BP-1936985014-192.168.59.141-1624346811419/current/finalized/subdir0/subdir0
#查看 HDFS 在磁盘存储文件内容
cat blk_1073741825
#拼接
cat blk_1073741826 >> tmp.tar.gz
cat blk_1073741827 >> tmp.tar.gz
#解压
tar -zxf tmp.tar.gz
#发现解压出来的是jdk
执行 wordcount 程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wcinput /wcoutput
3.2.4 配置历史服务器
配置 mapred-site.xml
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop141:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop141:19888</value>
</property>
分发配置
xsync mapred-site.xml
在 hadoop141 启动历史服务器
#进入目录
cd /opt/hadoop-3.1.3/bin/
#启动历史服务器
mapred --daemon start historyserver
3.2.5 配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上。
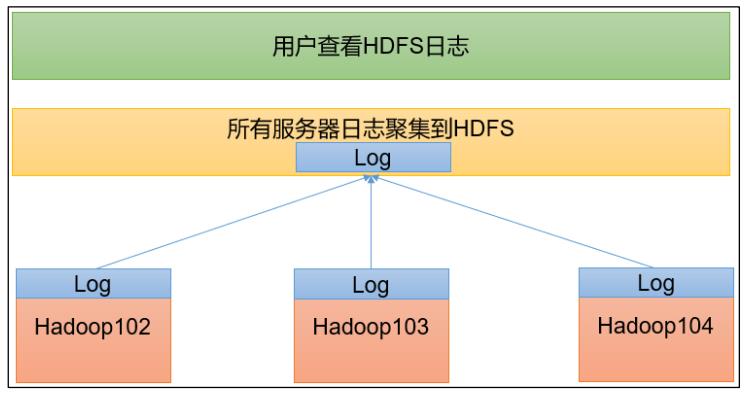
配置 yarn-site.xml
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop141:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
3.2.6 集群启动/停止方式总结
各个模块分开启动/停止(配置 ssh 是前提)常用
#整体启动/停止 HDFS
start-dfs.sh/stop-dfs.sh
#整体启动/停止 YARN
start-yarn.sh/stop-yarn.sh
各个服务组件逐一启动/停止
#分别启动/停止 HDFS 组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
#启动/停止 YARN
yarn --daemon start/stop resourcemanager/nodemanager
3.2.7 编写 Hadoop 集群常用脚本
启动停止集群
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop 集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop141 "/opt/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop142 "/opt/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------" ssh hadoop141 "/opt/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop 集群 ==================="
echo " --------------- 关闭 historyserver ---------------" ssh hadoop141 "/opt/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop142 "/opt/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop141 "/opt/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
查看jps
#!/bin/bash
for host in hadoop141 hadoop142 hadoop143
do
echo =============== $host ===============
ssh $host jps
done
3.2.8 常用端口号说明
| 端口名称 | hadoop2.x | hadoop3.x |
|---|---|---|
| NameNode 内部通信端口 | 8020/9000 | 8020/9000/9820 |
| NameNode HTTP UI | 50070 | 9870 |
| MapReduce 查看执行任务端口 | 8088 | 8088 |
| 历史服务器通信端口 | 19888 | 19888 |
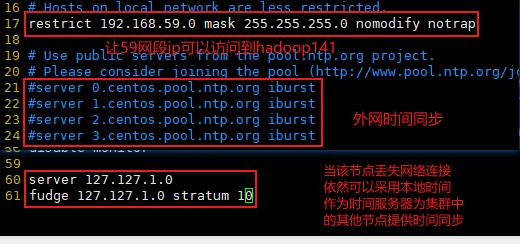
3.2.9 集群时间同步
如果服务器在公网环境(能连接外网),可以不采用集群时间同步,因为服务器会定期 和公网时间进行校准;
如果服务器在内网环境,必须要配置集群时间同步,否则时间久了,会产生时间偏差, 导致集群执行任务时间不同步。
时间服务器配置(必须 root 用户)
sudo systemctl status ntpd
sudo systemctl start ntpd
修改 hadoop141 的 ntp.conf 配置文件
#编辑配置文件
sudo vim /etc/ntp.conf
#追加内容
server 127.127.1.0
fudge 127.127.1.0 stratum 10
#编辑配置文件
vim /etc/sysconfig/ntpd
#追加内容
SYNC_HWCLOCK=yes
#重启ntpd
systemctl restart ntpd
#开启启动
systemctl enable ntpd
其他机器配置(必须 root 用户)
#关闭所有节点上 ntp 服务和自启动
sudo systemctl stop ntpd
sudo systemctl disable ntpd
#在其他机器配置 1 分钟与时间服务器同步一次
sudo crontab -e
#编写定时任务如下:
*/1 * * * * /usr/sbin/ntpdate hadoop102
3.2.10 集群环境搭建小结
-
不能用root账户启动(创建新用户 --> 更改文件归属 chown -R 用户名:用户名 /opt/hadoop-3.1.3/ )
-
如果报错提示没有权限,大部分原因是ssh免密登陆问题,重新搞搞就好了(进去.ssh目录,看看有无认证文件)
-
如果报错提示不能写入log文件,因为log和data是新生成的,普通用户没有权限,重新chown一下
-
hdfs-web报错Couldn’t preview the file.(未设置Windows-hosts文件域名映射)
-
如果造成了数据不一致需要删除所有的data和log然后初始化(hdfs namenode -format)
总结
文章主要内容来自尚硅谷
以上是关于hadoop入门容易吗?的主要内容,如果未能解决你的问题,请参考以下文章