Hadoop入门——配置历史服务器及日志的聚集(图文详解步骤2021)
Posted Leokadia Rothschild
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop入门——配置历史服务器及日志的聚集(图文详解步骤2021)相关的知识,希望对你有一定的参考价值。
Hadoop入门(十二)——配置历史服务器及日志的聚集(图文详解步骤2021)
还记得在Hadoop入门(十)系列中我们点YARN的History但无效吗
这次我们就来配置一下这个历史服务器
系列文章传送门
这个系列文章传送门:
Hadoop入门(一)——CentOS7下载+VM上安装(手动分区)图文步骤详解(2021)
Hadoop入门(二)——VMware虚拟网络设置+Windows10的IP地址配置+CentOS静态IP设置(图文详解步骤2021)
Hadoop入门(三)——XSHELL7远程访问工具+XFTP7文件传输(图文步骤详解2021)
Hadoop入门(四)——模板虚拟机环境准备(图文步骤详解2021)
Hadoop入门(五)——Hadoop集群搭建-克隆三台虚拟机(图文步骤详解2021)
Hadoop入门(六)——JDK安装(图文步骤详解2021)
Hadoop入门(七)——Hadoop安装(图文详解步骤2021)
Hadoop入门(八)——本地运行模式+完全分布模式案例详解,实现WordCount和集群分发脚本xsync快速配置环境变量 (图文详解步骤2021)
Hadoop入门(九)——SSH免密登录 配置
Hadoop入门(十)——集群配置(图文详解步骤2021)
Hadoop入门(十一)——集群崩溃的处理方法(图文详解步骤2021)
Hadoop入门(十二)——配置历史服务器及日志的聚集(图文详解步骤2021)
Hadoop入门(十三)——集群常用知识(面试题)与技巧总结
Hadoop入门(十四)——集群时间同步(图文详解步骤2021)
Hadoop入门(十五)——集群常见错误及解决方案
配置历史服务器
为了查看程序的历史运行情况,需要配置一下历史服务器。具体配置步骤如下:
1 ) 配置 mapred-site.xml
只需在mapred-site.xml配置文件加两个参数:
[leokadia@hadoop102 hadoop]$ vim mapred-site.xml
在该文件里面增加如下配置。
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
</property>
解释下这两个参数
- 将历史服务器mapreduce.jobhistory.address配置在hadoop102:10020内部通讯端口
<name>mapreduce.jobhistory.address</name>
<value>hadoop102:10020</value>
一个服务器内部代码之间的通讯用的是hadoop102:10020
e.g. hadoop102和103之间的通讯
- 历史服务器对外暴露的接口
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop102:19888</value>
用户查看集群里面的历史服务,从web页面查看,这个端口用的hadoop102:19888

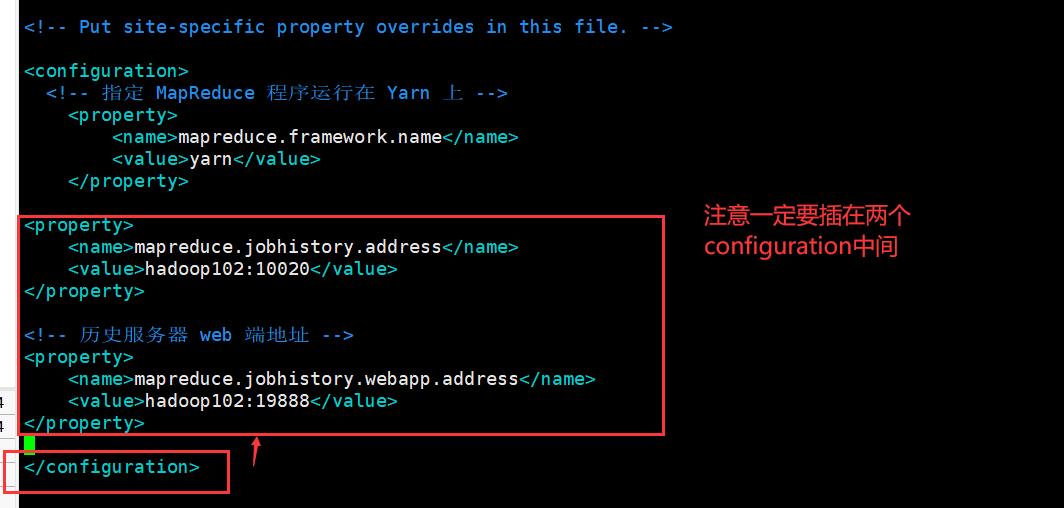
错误示例:
会出现错误
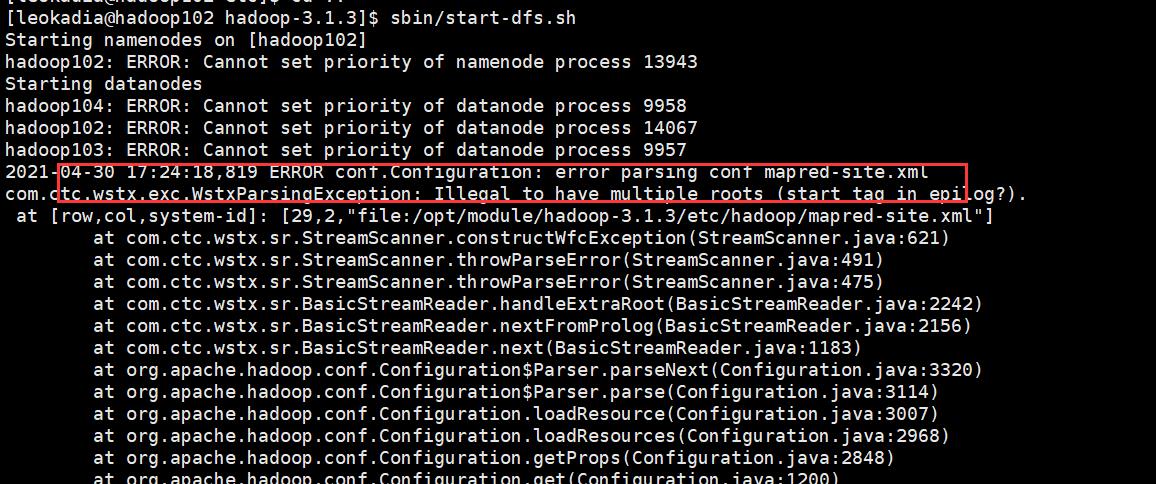
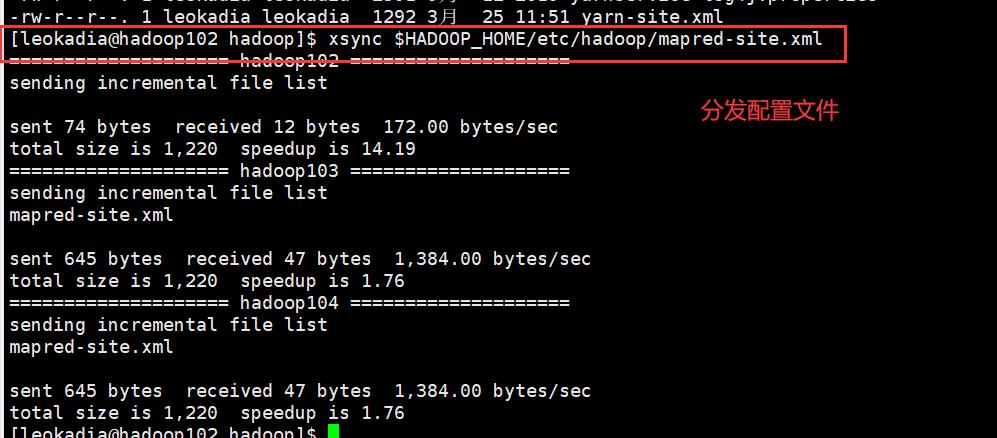
2 ) 分发配置
[leokadia@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/mapred-site.xml
3 ) 在 hadoop102 启动历史服务器
先重新启动一下集群,先stop后start
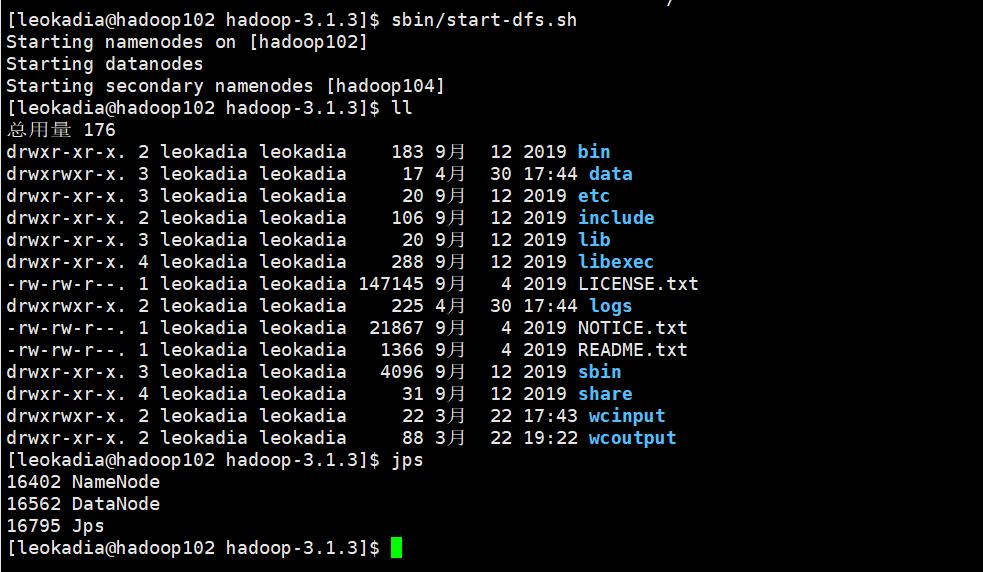

再启用历史服务器
[leokadia@hadoop102 hadoop]$ mapred --daemon start historyserver
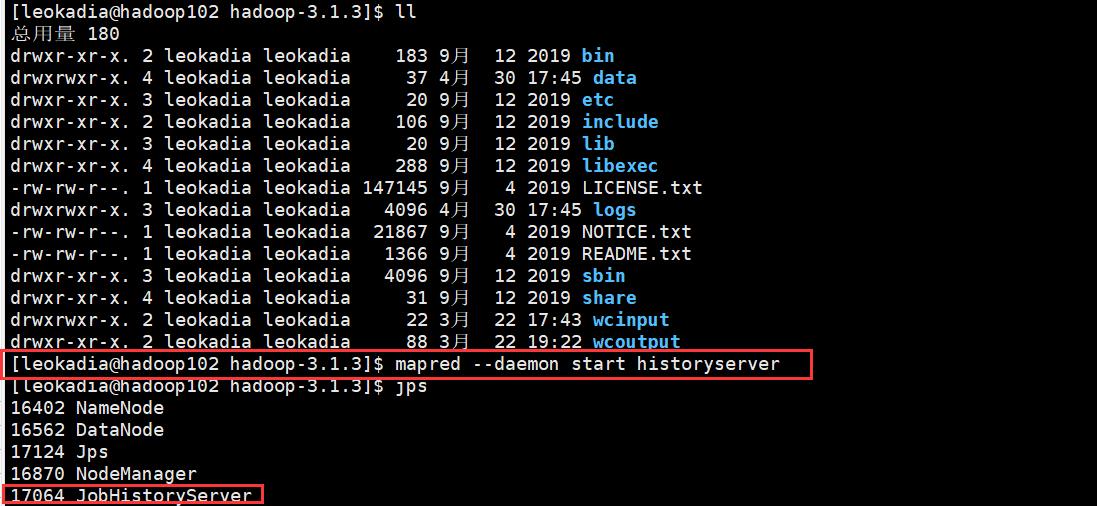
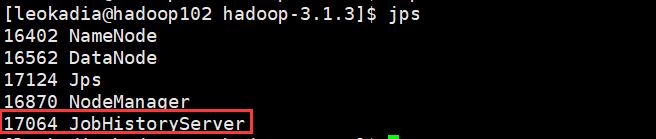
4 ) 查看历史服务器是否启动
[leokadia@hadoop102 hadoop]$ jps
5 ) 测试
先创建一些数据
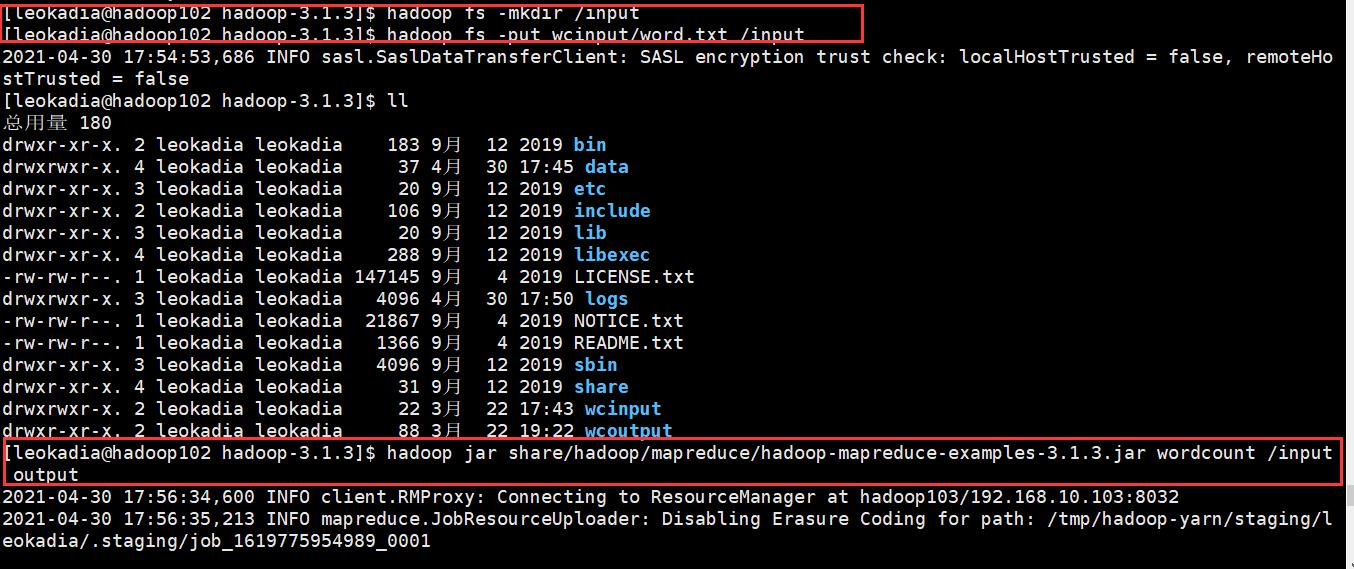
[leokadia@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /input
[leokadia@hadoop102 hadoop-3.1.3]$ hadoop fs -put wcinput/word.txt /input
[leokadia@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input output
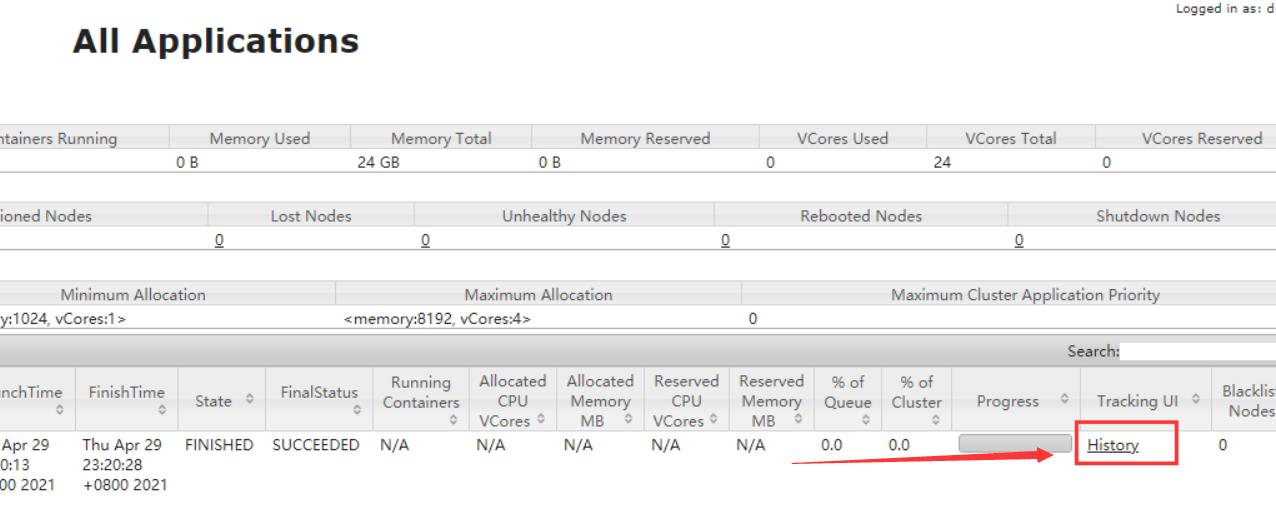
6 ) 查看 JobHistory
点击History
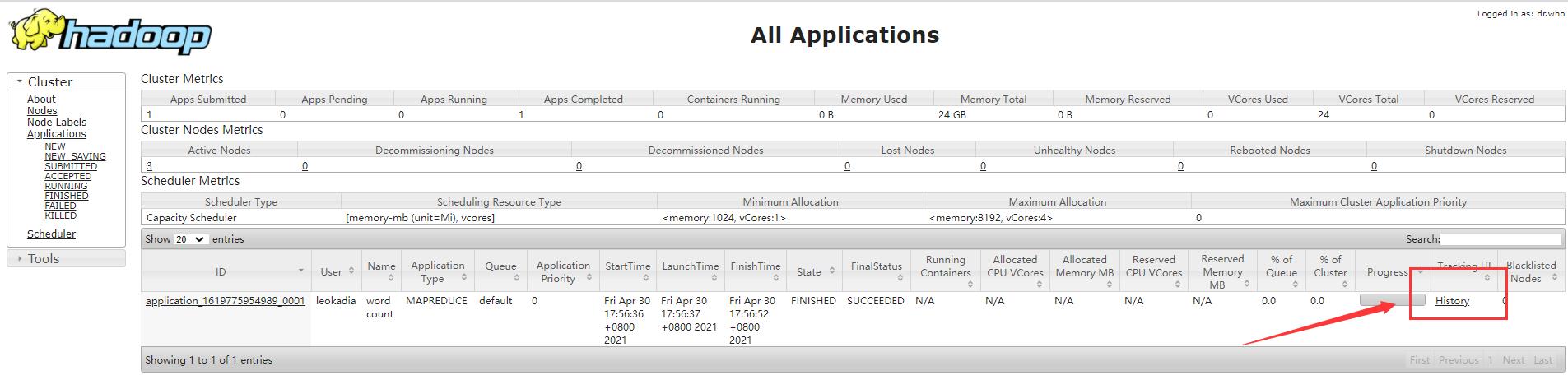
直接跳转到http://hadoop102:19888/jobhistory 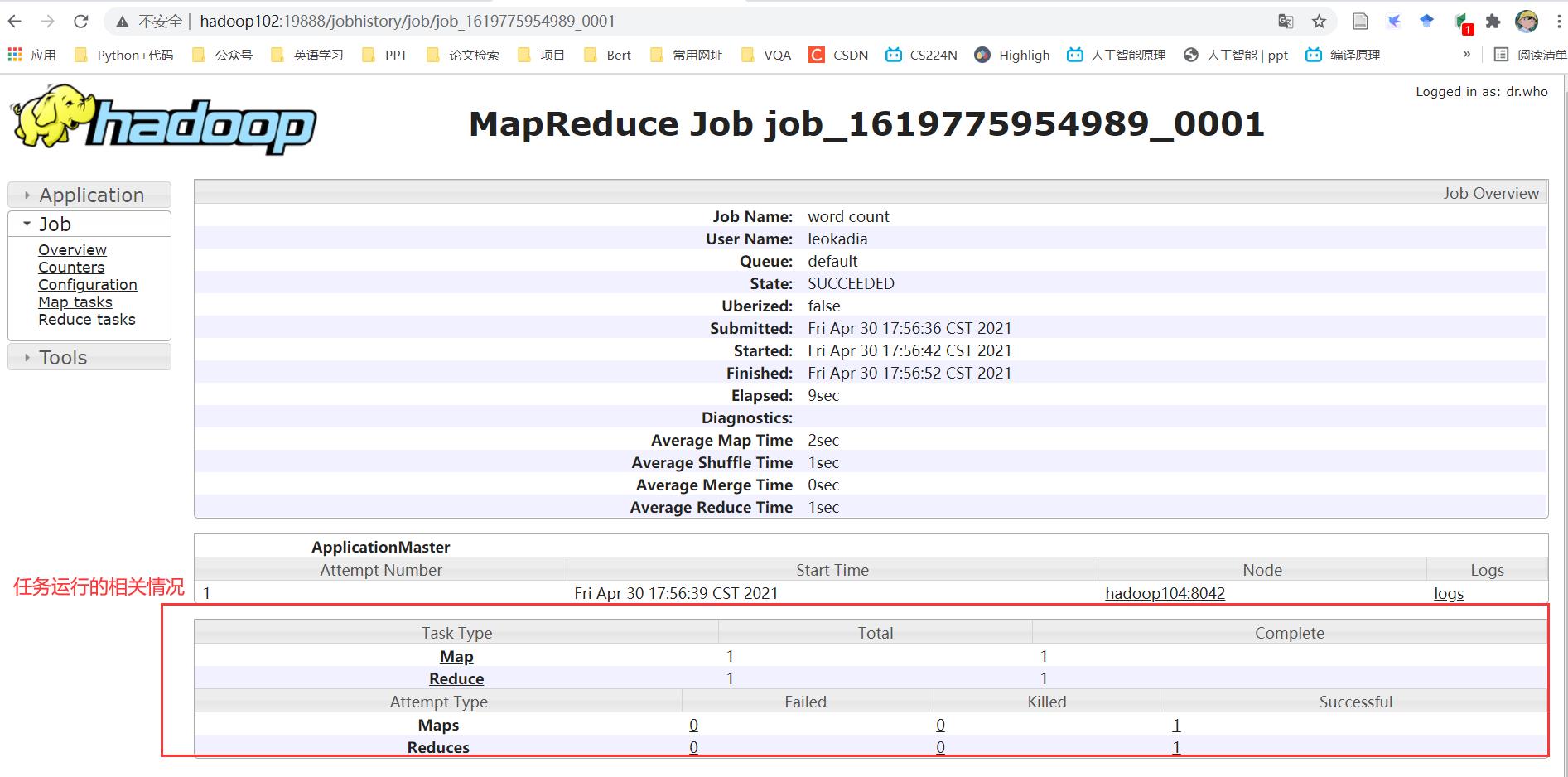

配置日志的聚集
之前在界面上看到有logs的链接(记录程序运行的日志),点进去
点击后无法显示正常的功能
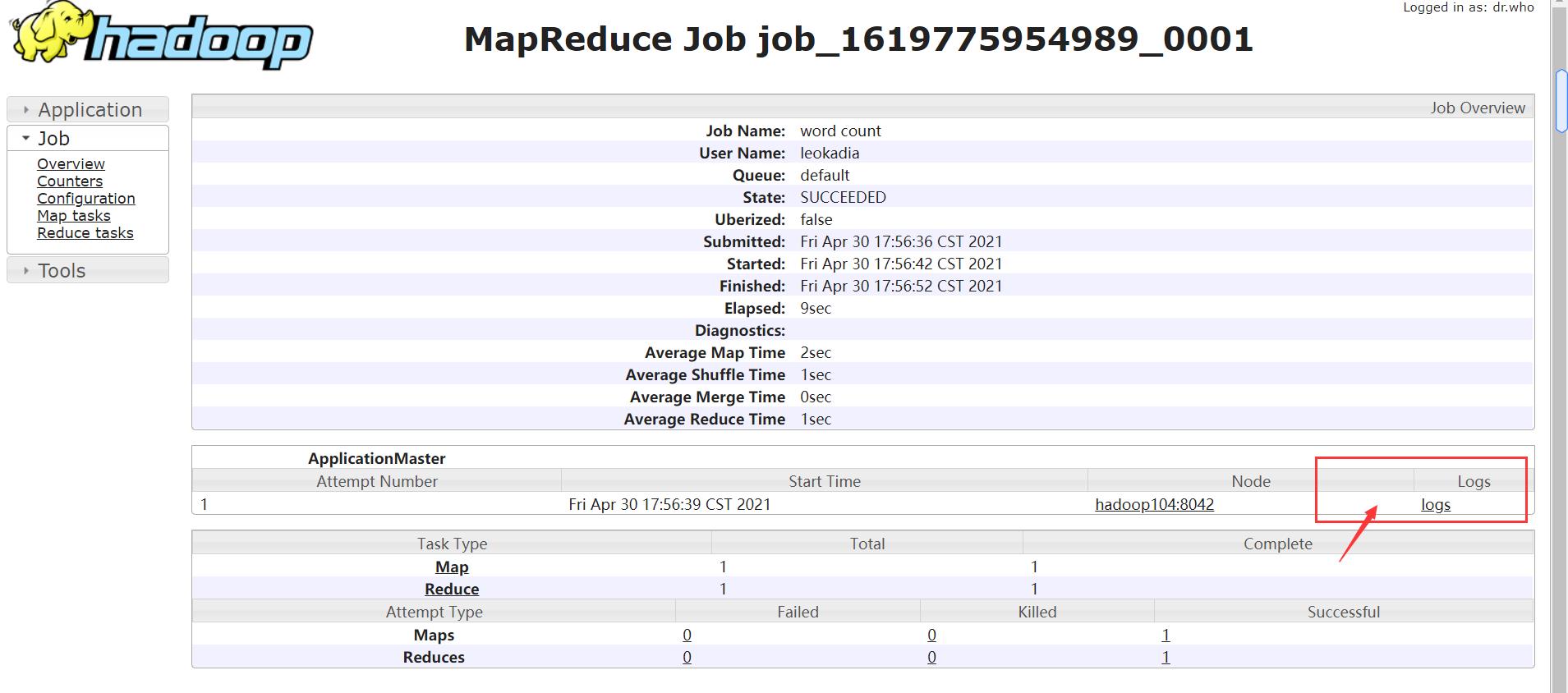
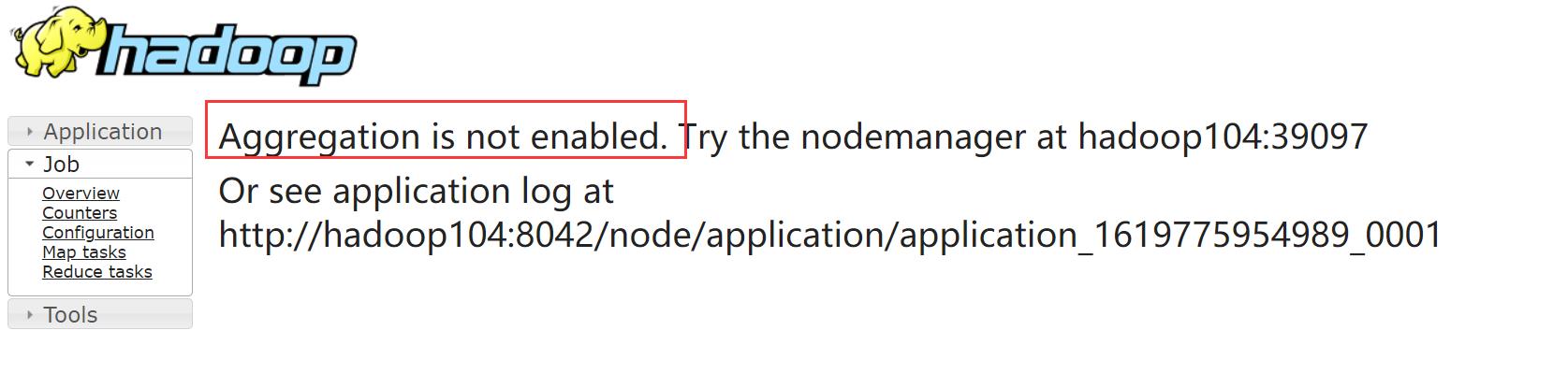
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到 HDFS 系统上。
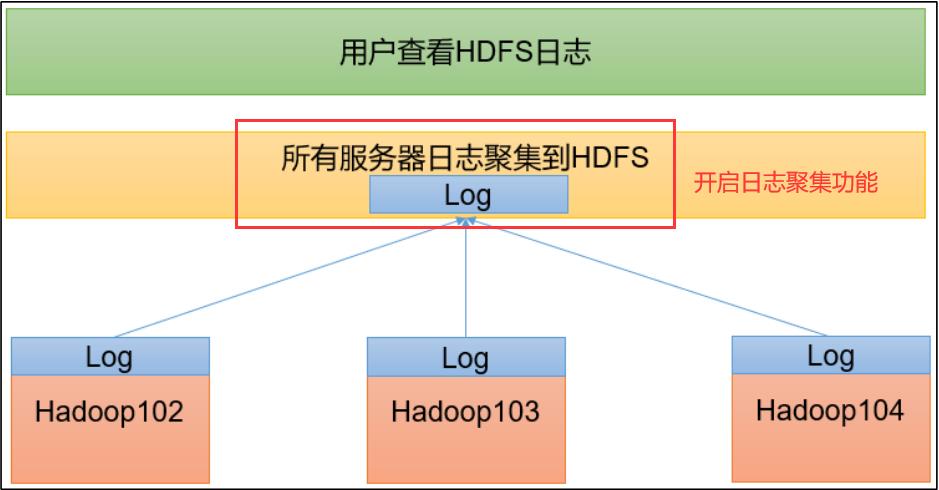
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试。
注意:开启日志聚集功能,需要重新启动 NodeManager 、ResourceManager 和HistoryServer。
开启日志聚集功能具体步骤如下:
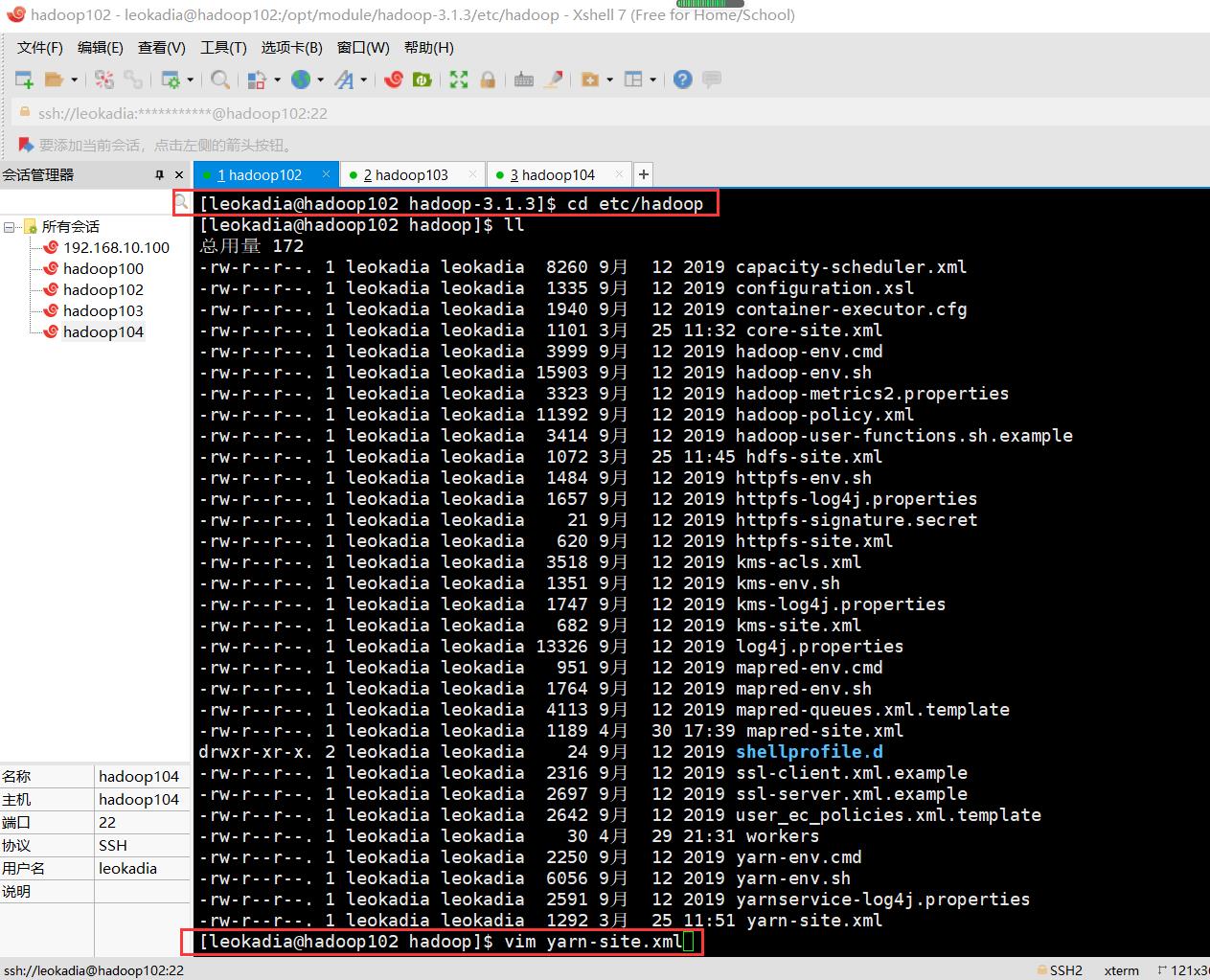
1 ) 配置 yarn-site.xml
[leokadia@hadoop102 hadoop]$ vim yarn-site.xml
在该文件里面增加如下配置。
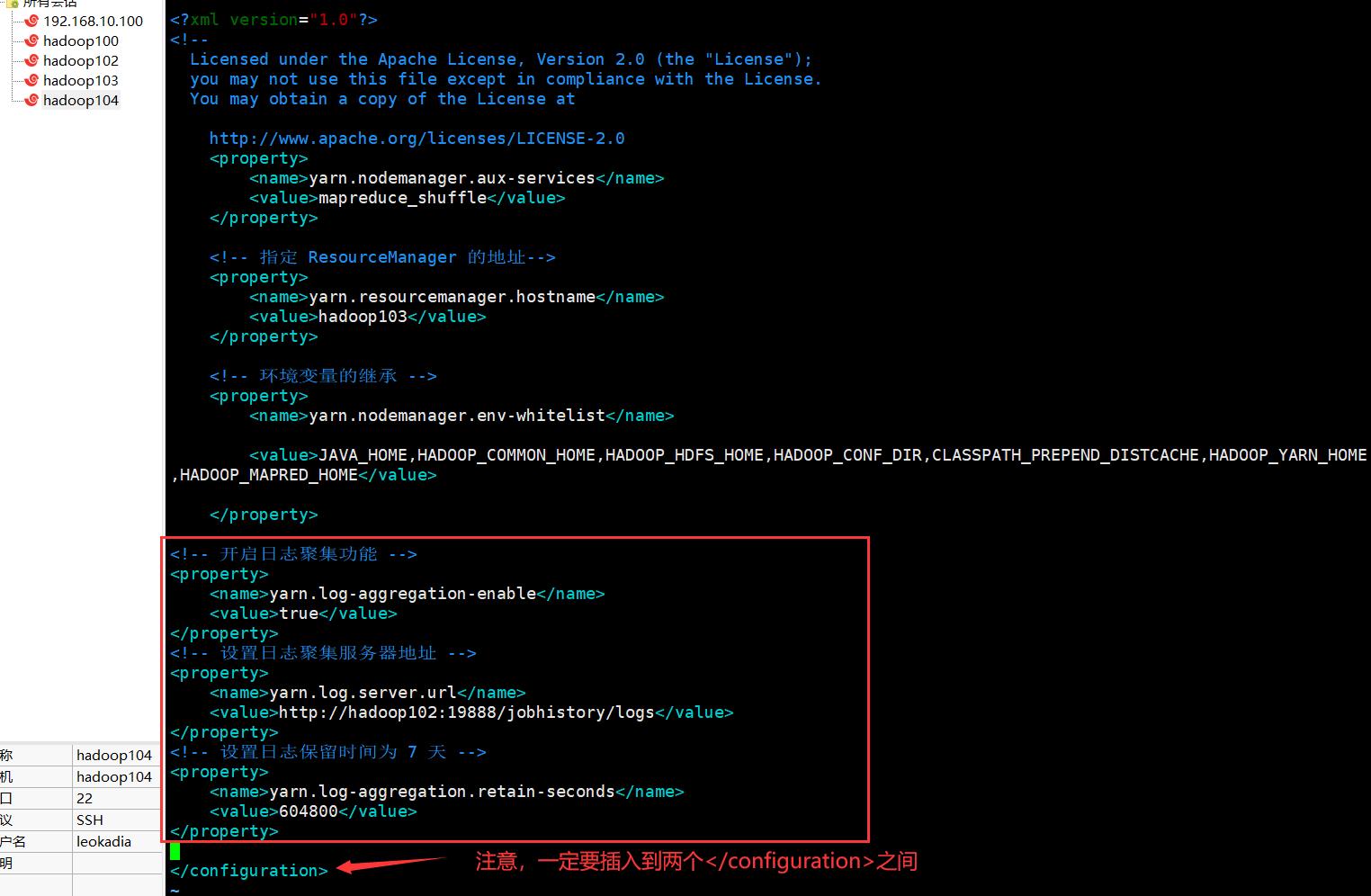
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为 7 天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
2 ) 分发配置
[leokadia@hadoop102 hadoop]$ xsync $HADOOP_HOME/etc/hadoop/yarn-site.xml

注意:分发完毕后一定要重启一下yarn
3 ) 关闭 NodeManager 、ResourceManager 和 HistoryServer
关闭HistoryServer
[leokadia@hadoop103 hadoop-3.1.3]$ mapred --daemon stop historyserver

关闭 NodeManager 、ResourceManager
[leokadia@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh
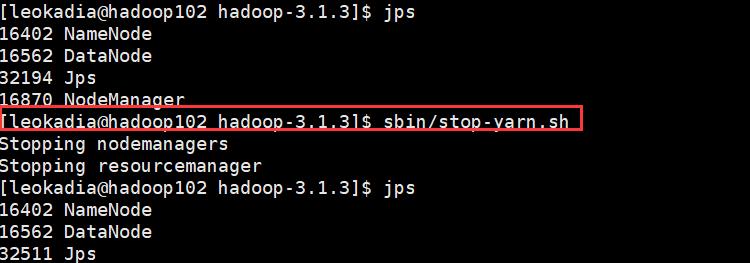
因为更改了yarn的配置,所以需要重启yarn
HDFS配置没有修改,所以不需要重启HDFS
4 ) 启动 NodeManager 、ResourceManage 和 HistoryServer
-
启动 NodeManager 、ResourceManage
[leokadia@hadoop103 ~]$start-yarn.sh -
启动 HistoryServer
[leokadia@hadoop102 ~]$mapred --daemon start historyserver
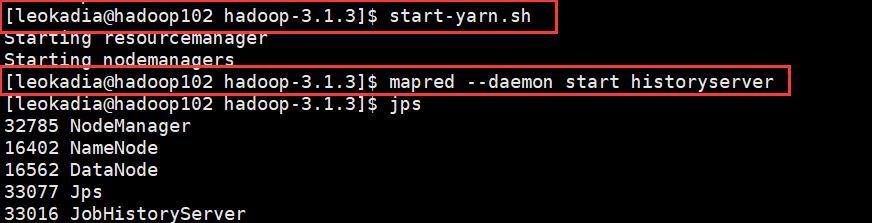
现在查看logs页面
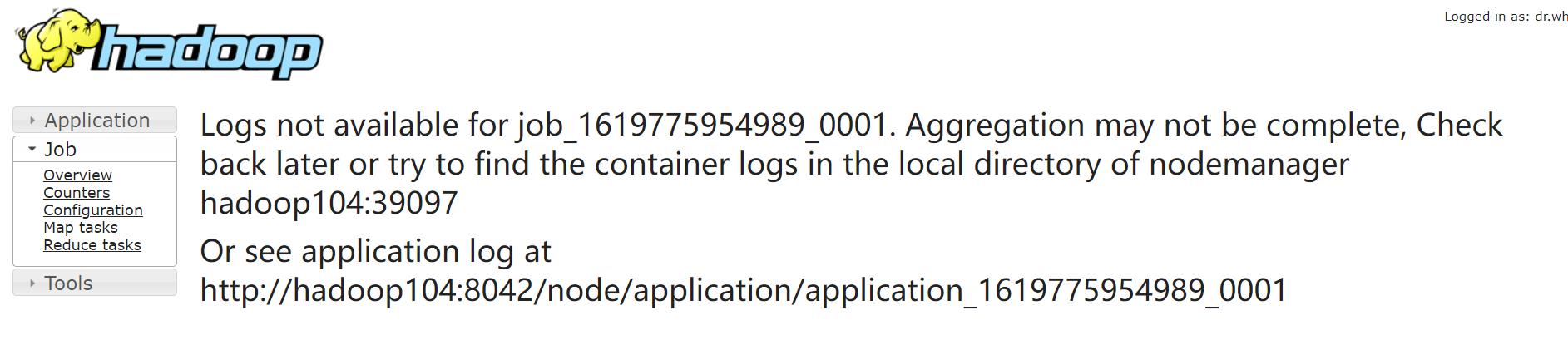
发现还是没有日志,需要再执行一遍任务就会出现日志
5 ) 删除 HDFS 上已经存在的 输出 文件
[leokadia@hadoop102 ~]$ hadoop fs -rm -r /output
6 ) 执行 WordCount 程序
[leokadia@hadoop102 hadoop-3.1.3]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
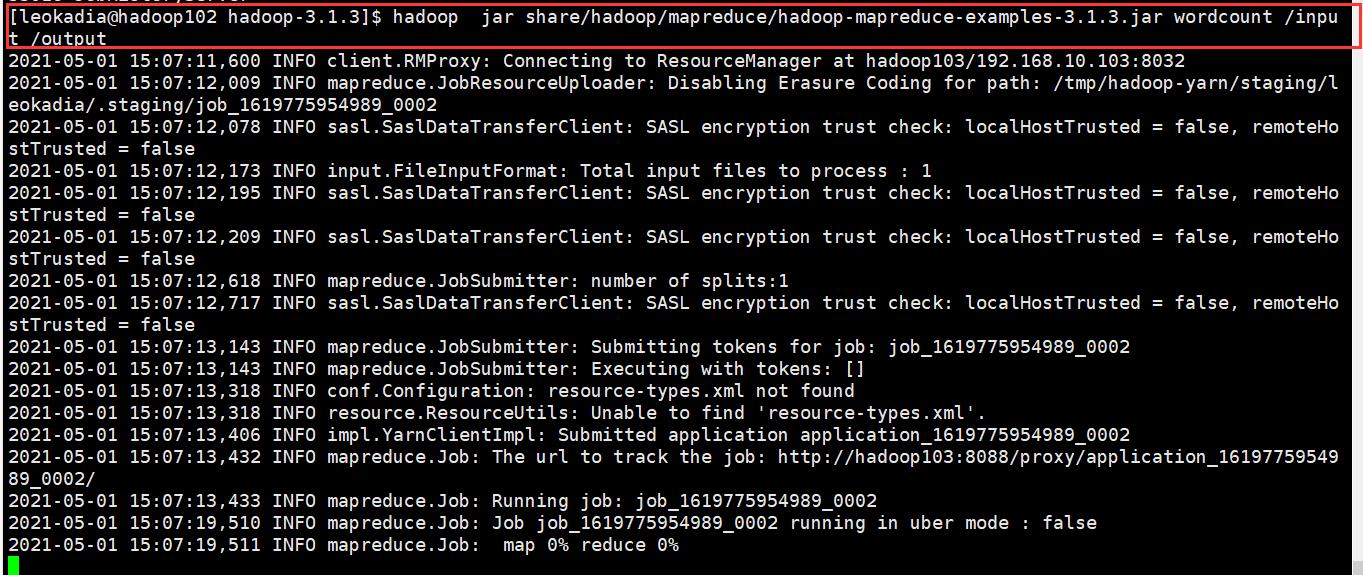
7 ) 查看日志
(1)历史服务器地址
http://hadoop102:19888/jobhistory
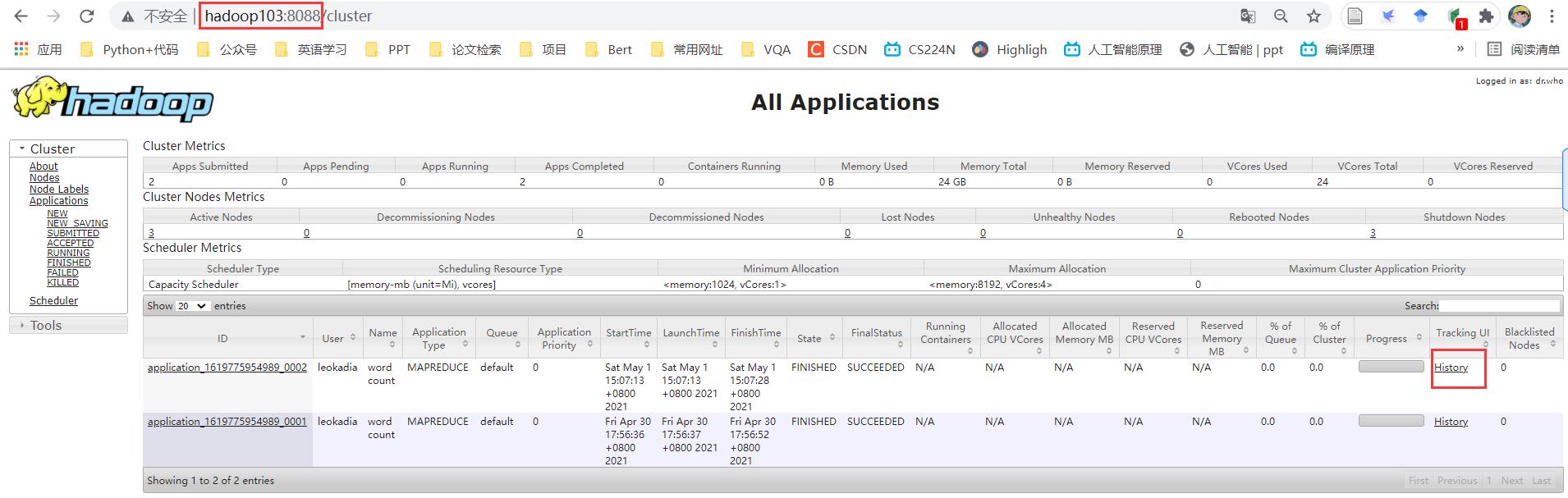
(2)历史任务列表
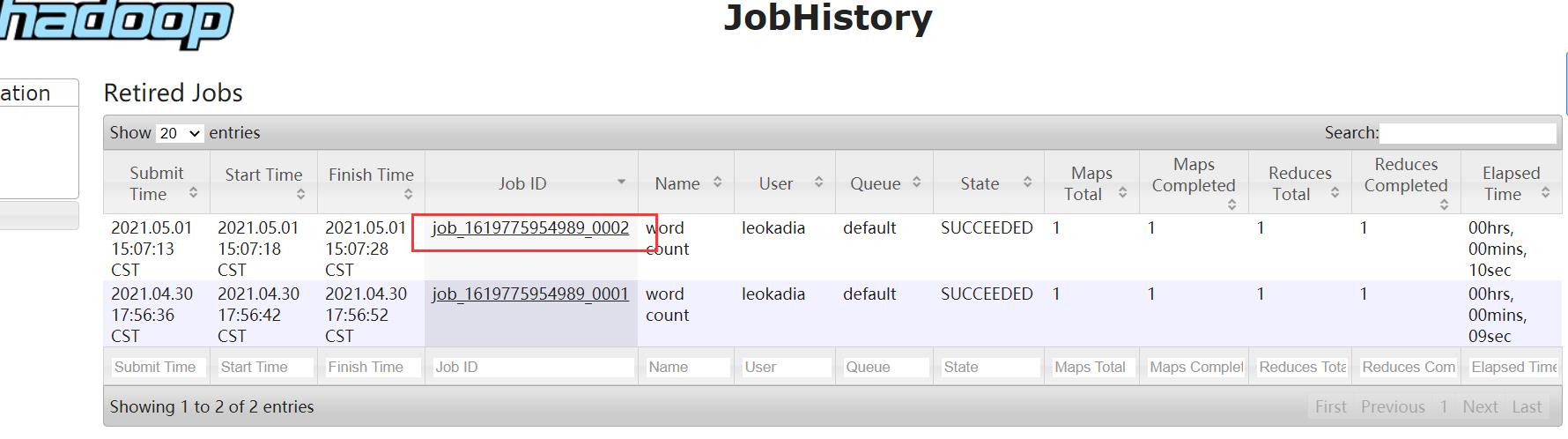
(3)查看任务运行日志
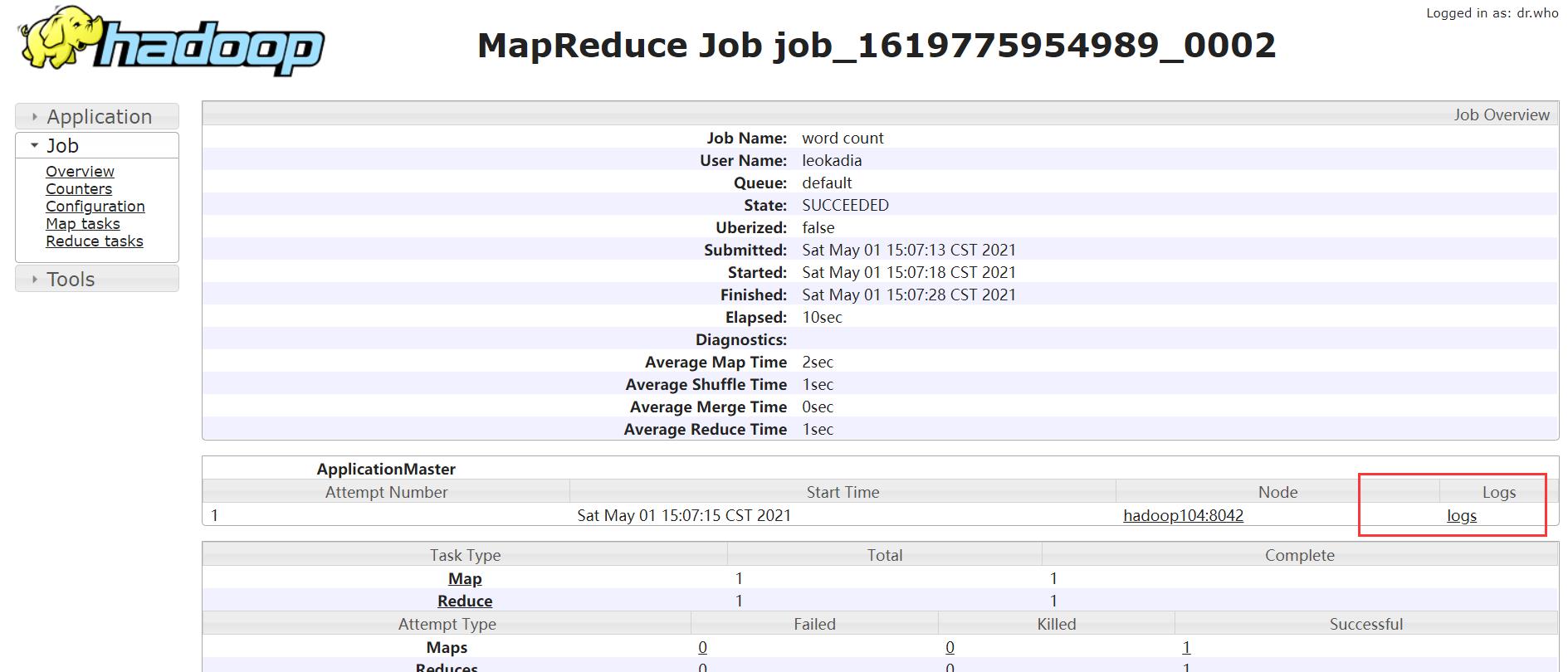
(4)运行日志详情
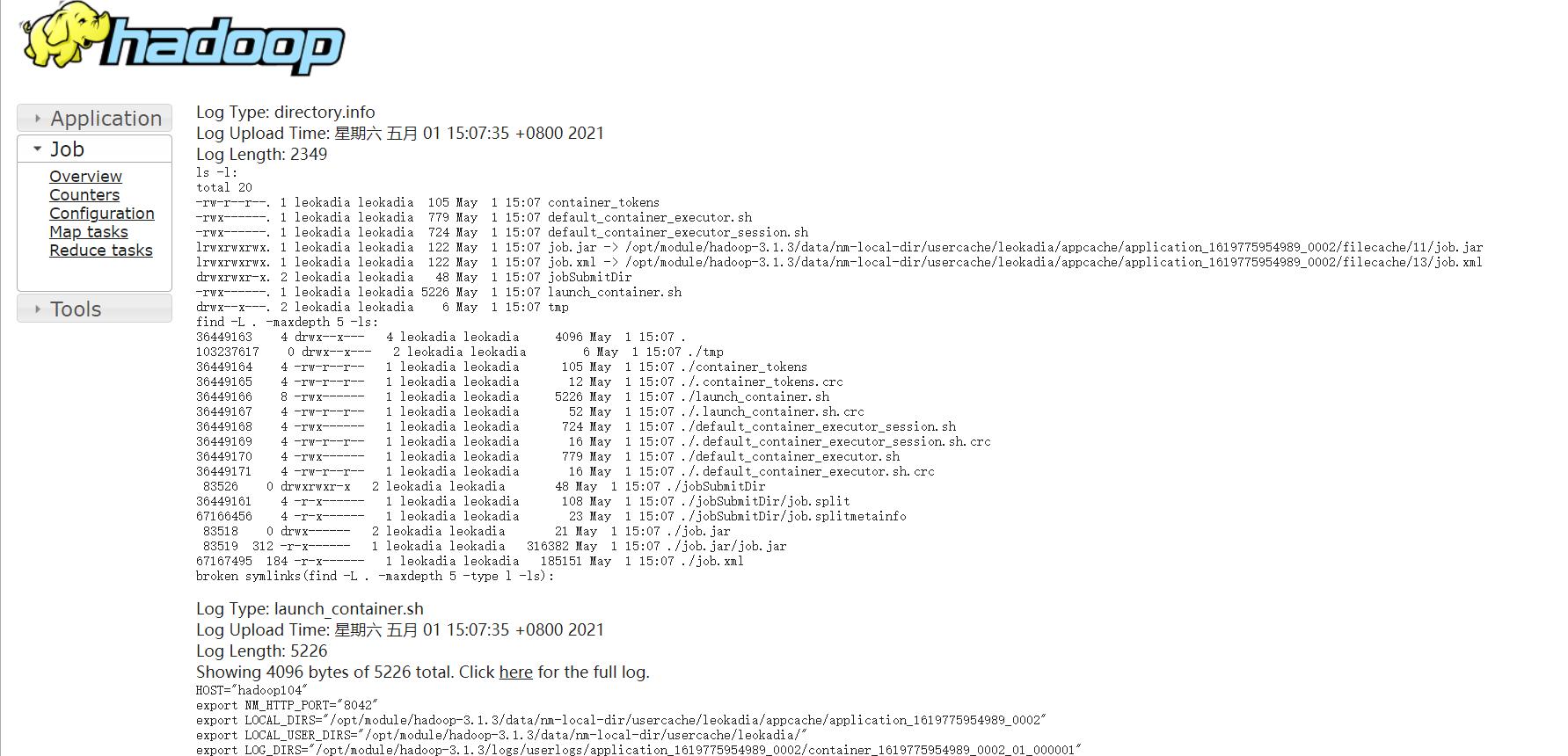
以上是关于Hadoop入门——配置历史服务器及日志的聚集(图文详解步骤2021)的主要内容,如果未能解决你的问题,请参考以下文章