Java集合中List和 Map区别?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java集合中List和 Map区别?相关的知识,希望对你有一定的参考价值。
一个是存储单列数据的集合,,另外一个是存储键和值
这样的双列数的集合,List中存储的数据是有顺序的,并且允许重复。。。Map中存储的数据是没有顺序的,其键是不能重复的,它的值是可以有重复的。。。
List继承
Collection接口
,,Map不继承Collection接口。 参考技术A set集合中的数据没有顺序,且如果add两个一样的对象或基本类型的数据,set集合里也是只有一个,即set集合中的数据都是独一无二的;不能使用加强的for循环;
list中的数据是有顺序的,可以加入多个一样的对象和基本类型的数据,可使用加强的for循环;
map集合是键值对的形式进行存储,一个key,一个value。 参考技术B
List:是存储单列数据的集合,存储的数据是有序并且是可以重复的
Map:存储双列数据的集合,通过键值对存储数据,存储 的数据是无序的,Key值不能重复,value值可以重复 key和value是一一对应的
关系
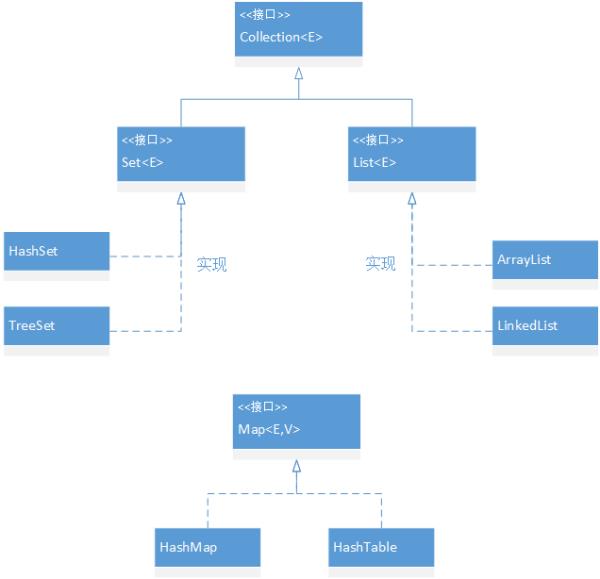
这张图简单揭示了Set、List与Map之间的相对关系。
Collection接口
Collection是Java中最基本的集合接口。它描述了一组有关集合操作的方法。
int Size(); //集合大小
boolean isEmpty(); //是否为空
boolean contains(Object o); //是否包含某个对象
Iterator<E> iterator(); //返回一个迭代对象,用来遍历集合中的元素
Object[] toArray(); //将集合中的元素以数组形式然后返回
<T> T[] toArray(T[] a); //上一个方法的泛型形式
boolean add(E e); //将对象e添加进集合,添加成功则返回true
boolean remove(Object o); //移除某个元素
boolean containsAll(Collection<?> c); //传入一个集合c,如果c中的元素都存在,则返回true
boolean addAll(Collection<? extends E> c); //将集合c中的元素全部添加进本集合
boolean removeAll(Collection<?> c); //本集合减去c集合中的元素
boolean retainAll(Collection<?> c); //取本集合和c集合的交集
void clear(); //清空集合
boolean equals(Object o); //判断相等
int hashCode(); //获取集合当前的hash值
Set接口
Set接口直接继承自Collection接口,并且方法接口上也一模一样。Set对添加的元素有一些要求,其不允许出现重复的元素,并且元素之间没有次序。这相当于一个不允许重复的离散的集合。因此,添加进Set的元素类型需要定义equals方法。若是使用自定义的类,则应该重写equals方法来确保实现自己需要的功能。
Set接口主要实现了两个类:HashSet,TreeSet。
HashSet是按照哈希来存取元素的,因此速度较快。HashSet继承自抽象类AbstractSet,然后实现了Set、Cloneable、Serializable接口。
TreeSet也是继承自AbstractSet,不过不同的是其实现的是NavigableSet接口。而NavigableSet继承自SortedSet。SortedSet是一个有序的集合。其添加的元素必须实现了Comparable接口,因为其在添加一个元素的时候需要进行排序。NavigableSet则提供了更多的有关元素次序的方法。
LinkedHashSet也是Set的一个实现。和HashSet类似,只不过内部用链表来维护,按照元素插入次序来保存。
List接口
List接口也是继承自Collection。与Set不同的是,List可以存储重复的元素。主要有两种实现:ArrayList和LinkedList。
ArrayList没有什么好说的,就像传统的数组一样,有着很快的随机存取速度,但是插入删除的速度就很慢。
LinkedList则与ArrayList恰恰相反,因为用链表来保存数据,所以插入删除元素的速度很快,但是访问数据的速度就不如ArrayList了。
Map接口
Map(映射)是一个存储键值对的容器接口。每一个元素包含一个key对象和value对象,且元素不允许重复。
Map接口的实现有以下几个:
HashMap是最常用的一个实现。HashMap使用hash映射来存取数据,这个速度是相当快,是O(1)的速度。其容量capacity,和负载因子load factor可以在一开始设定。当元素个数达到capacity*load factor的时候,就会进行扩容。
LinkedHashMap和HashMap类似,只不过内部用链表来维护次序。因此遍历时候的顺序是其插入顺序。
TreeMap是基于红黑树的Map,插入的数据被有次序保存,并且有很高的效率。因此在遍历输出的时候可以得到排序的数据。但是这要求插入的数据实现了comparable接口。
总结
Collection、Set、List和Map都是接口,不能被实例化。
Set和List都继承自Collection,而Map则和Collection没什么关系。
Set和List的区别在于Set不能重复,而List可以重复。
Map和Set与List的区别在于,Map是存取键值对,而另外两个则是保存一个元素。
希望对您有所帮助!~
java中 List 与Set 有啥区别?
Java的集合类都位于java.util包中,Java集合中存放的是对象的引用,而非对象本身。Java集合主要分为三种类型:
a.Set(集):集合中的对象不按特定方式排序,并且没有重复对象。它的有些实现类能对集合中的对象按特定方式排序。
b.List(列表):集合中的对象按索引位置排序,可以有重复对象,允许按照对象在集合中的索引位置检索对象。
c.Map(映射):集合中的每一个元素包含一对键对象和值对象,集合中没有重复的键对象,值对象可以重复。它的有些实现类能对集合中的键对象进行排序。
Set、List和Map统称为Java集合。
1.Set(集)
Set集合中的对象不按特定方式排序,并且没有重复对象。Set接口主要有两个实现类HashSet和TreeSet。HashSet类按照哈希算法来存取集合中的对象,存取速度比较快。HashSet类还有一个子类LinkedHashSet类,它不仅实现了哈希算法,而且实现了链表数据结构。TreeSet类实现了SortedSet接口,具有排序功能。
Set的add()方法判断对象是否已经存在于集合中的判断流程:
boolean isExists = false;
Iterator it = set.iterator();
while(it.hasNext())
Object object = it.next();
if(newObject.equals(oldObject))
isExists = true;
break;
2.HashSet类
当HashSet向集合中加入一个对象时,会调用对象的hashCode()方法获得哈希码,然后根据这个哈希码进一步计算出对象在集合中的存放位置。
当Object1变量和object2变量实际上引用了同一个对象,那么object1和object2的哈希码肯定相同。
为了保证HashSet能正常工作,要求当两个对象用equals()方法比较的结果为相等时,它们的哈希码也相等。即:
customer1.hashCode() == customer2.hashCode();
如:对应于Customer类的以下重写后的equals()方法:
public boolean equals(Object o)
if(this==o) return true;
if(!o instanceof Customer) return false;
final Customer other = (Customer)o;
if(this.name.equals(other.getName())&&this.age==other.getAge())
return true;
else
return false;
为了保证HashSet正常工作,如果Customer类覆盖了equals()方法,也应该覆盖hashCode()方法,并且保证两个相等的Customer对象的哈希码也一样。
public int hashCode()
int result;
result = (name==null?0:name.hashCode());
result = 29*result+(age==null?0:age.hashCode());
return result;
3.TreeSet类
TreeSet类实现了SortedSet接口,能够对集合中的对象进行排序。TreeSet支持两种排序方式:自然排序和客户化排序,在默认情况下TreeSet采用自然排序方式。
a.自然排序
在JDK中,有一部分类实现了Comparable接口,如Integer、Double和String等。Comparable接口有一个compareTo(Object o)方法,它返回整数类型。对于表达式x.compareTo(y),如果返回值为0,表示x和y相等,如果返回值大于0,表示x大于y,如果返回值小于0,表示x小于y。
TreeSet调用对象的compareTo()方法比较集合中对象的大小,然后进行升序排列,这种排序方式称为自然排序。
以下列出了JDK中实现了Comparable接口的一些类的排序方式
类 排序
BigDecimal\BigInteger\Byte\Double\Float\Integer\Long\Short 按数字大小排序
Character 按字符的Unicode值的数字大小排序
String 按字符串中字符的Unicode值排序
使用自然排序时,只能向TreeSet集合中加入同类型的对象,并且这些对象的类必须实现了Comparable接口,否则会在第二次调用TreeSet的add()方法时,会抛出ClassCastException异常。
例如:
以下是Customer类的compareTo()方法的一种实现方式:
public int compareTo(Object o)
Customer other = (Customer)o;
//先按照name属性排序
if(this.name.compareTo(other.getName())>0) return 1;
if(this.name.compareTo(other.getName())<0) return -1;
//再按照age属性排序
if(this.age>other.getAge()) return 1;
if(this.age<other.getAge()) return -1;
return 0;
为了保证TreeSet能正确地排序,要求Customer类的compareTo()方法与equals()方法按相同的规则比较两个Customer对象是否相等。
因此在Customer类的equals()方法中应该采用相同的比较规则:
public boolean equals(Object o)
if(this==o) return true;
if(!(o instanceof Customer)) return false;
final Customer other = (Customer)o;
if(this.name.equals(other.getName())&&this.age==other.getAge())
return true;
else
return false;
值得注意的是,对于TreeSet中已经存在的Customer对象,如果修改了它们的属性,TreeSet不会对集合进行重新排序。在实际域模型中,实体类的属性可以被更新,因此不适合通过TreeSet来排序。最适合于排序的是不可变类。
b.客户化排序
除了自然排序,TreeSet还支持客户化排序。java.util.Comparator接口用于指定具体的排序方式,它有个compare(Object object1,Object object2)方法,用于比较两个对象的大小。当表达式compare(x,y)的值大于0,表示x大于y;当compare(x,y)的值小于0,表示x小于y;当compare(x,y)的值等于0,表示x等于y。
例如:如果希望TreeSet仅按照Customer对象的name属性进行降序排列,可以创建一个实现Comparator接口的类CustomerComparator:
public class CustomerComparator implements Comparator
public int compare(Object o1,Object o2)
Customer c1= (Customer)o1;
Customer c2 = (Customer)o2;
if(c1.getName().compareTo(c2.getName())>0) return -1;
if(c2.getName().compareTo(c2.getName())<0) return 1;
return 0;
接下来在构造TreeSet的实例时,调用它的TreeSet(Comparator comparator)构造方法:
Set set = new TreeSet(new CustomerComparator());
4.向Set中加入持久化类的对象
例如两个Session实例从数据库加载相同的Order对象,然后往HashSet集合里存放,在默认情况下,Order类的equals()方法比较两个Orer对象的内存地址是否相同,因此order1.equals(order2)==false,所以order1和order2游离对象都加入到HashSet集合中,但实际上order1和order2对应的是ORDERS表中的同一条记录。对于这一问题,有两种解决方案:
(1)在应用程序中,谨慎地把来自于不同Session缓存的游离对象加入到Set集合中,如:
Set orders = new HashSet();
orders.add(order1);
if(!order2.getOrderNumber().equals(order1.getOrderNumber()))
order.add(order2);
(2)在Order类中重新实现equals()和hashCode()方法,按照业务主键比较两个Order对象是否相等。
提示:为了保证HashSet正常工作,要求当一个对象加入到HashSet集合中后,它的哈希码不会发生变化。
5.List(列表)
List的主要特征是其对象以线性方式存储,集合中允许存放重复对象。List接口主要的实现类有LinkedList和ArrayList。LinkedList采用链表数据结构,而ArrayList代表大小可变的数组。List接口还有一个实现类Vector,它的功能和ArrayList比较相似,两者的区别在于Vector类的实现采用了同步机制,而ArrayList没有使用同步机制。
List只能对集合中的对象按索引位置排序,如果希望对List中的对象按其他特定方式排序,可以借助Comparator和Collections类。Collections类是集合API中的辅助类,它提供了操纵集合的各种静态方法,其中sort()方法用于对List中的对象进行排序:
a.sort(List list):对List中的对象进行自然排序。
b.sort(List list,Comparator comparator):对List中的对象进行客户化排序,comparator参数指定排序方式。
如Collections.sort(list);
6.Map(映射)
Map(映射)是一种把键对象和值对象进行映射的集合,它的每一个元素都包含一对键对象和值对象,而值对象仍可以是Map类型,依次类推,这样就形成了多级映射。
Map有两种比较常用的实现:HashMap和TreeMap。HashMap按照哈希算法来存取键对象,有很好的存取性能,为了保证HashMap能正常工作,和HashSet一样,要求当两个键对象通过equals()方法比较为true时,这两个对象的hashCode()方法返回的哈希码也一样。
TreeMap实现了SortedMap接口,能对键对象进行排序。和TreeSet一样,TreeMap也支持自然排序和客户化排序两种方式。
例:创建一个缓存类EntityCache,它能粗略地模仿Session的缓存功能,保证缓存中不会出现两个OID相同的Customer对象或两个OID相同的Order对象,这种惟一性是由键对象的惟一性来保证的。
Key.java:
package mypack;
public class Key
private Class classType;
private Long id;
public Key(Class classType,Long id)
this.classType = classType;
this.id = id;
public Class getClassType()
return this.classType;
public Long getId()
return this.id;
public boolean equals(Object o)
if(this==o) return true;
if(!(o instanceof Key)) return false;
final Key other = (Key)o;
if(classType.equals(other.getClassType())&&id.equals(other.getId()))
return true;
return false;
public int hashCode()
int result;
result = classType.hashCode();
result = 29 * result + id.hashCode();
return result;
EntityCache.java:
package mypack;
import java.util.*;
public class EntityCache
private Map entitiesByKey;
public EntityCache()
entitiesByKey=new HashMap();
public void put(BusinessObject entity)
Key key=new Key(entity.getClass(),entity.getId());
entitiesByKey.put(key,entity);
public Object get(Class classType,Long id)
Key key=new Key(classType,id);
return entitiesByKey.get(key);
public Collection getAllEntities()
return entitiesByKey.values();
public boolean contains(Class classType,Long id)
Key key=new Key(classType,id);
return entitiesByKey.containsKey(key);
参考技术A 集合类型主要有3种:set(集)、bailist(列表)和map(映射)。
1、List(有序、可重复)
List里存放的对象是有序的,同时也是可以重复的,List关注的是索引,拥有一系列和索引相关的方法,查询速度快。因为往list集合里插入或删除数据时,会伴随着后面数据的移动,所有插入删除数据速度慢。
2、Set(无序、不能重复)
Set里存放的对象是无序,不能重复的,集合中的对象不按特定的方式排序,只是简单地把对象加入集合中。
3、Map(键值对、键唯一、值不唯一)
Map集合中存储的是键值对,键不能重复,值可以重复。根据键得到值,对map集合遍历时先得到键的set集合,对set集合进行遍历,得到相应的值。
以上是关于Java集合中List和 Map区别?的主要内容,如果未能解决你的问题,请参考以下文章