异常检测(Anomaly Detection)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了异常检测(Anomaly Detection)相关的知识,希望对你有一定的参考价值。
参考技术A异常检测(Anomaly Detection)是机器学习算法的一个常见应用。它主要用于非监督学习,但又类似一些监督学习问题。
异常检测常用在对网站异常用户的检测;还有在工程上一些零件,设备异常的检查;还有机房异常机器的监控等等
假设有数据集 ,当又有一个新的测试样本 ;
想要知道这个新样本是否是异常的;
首先对x的分布概率建模p(x) ,用来说明这个例子不是异常的概率;
然后定一个阈值 ,当 时说明是异常的。
当出现在高概率分布的区域时,说明该例子时正常的;当出现在低概率的区域时,说明是异常的。
高斯分布又被称之为正态分布,曲线呈钟型,两头低,中间高,左右对称因其曲线呈钟形,因此人们又经常称之为钟形曲线
假设x是一个实数随机变量,如果它的概率分布为高斯分布,定义几个变量:
=平均值
=标准差
=方差
那么x的概率分布可以用公式来表示:
其平均值 决定了其位置,其标准差 决定了分布的幅度
完整的高斯分布的概率公式为:
当参数平均值 和标准差 变化时:
关于平均值和方差的求解:
在一个异常检测的例子中,有m个训练样本,每个样本的特征值数量有n个,那么某个样本的分布概率模型p(x)就可以用样本的每个特征值的概率分布来计算:
上面的式子可以用更简洁的方式来表达
总计一下,异常检测的过程:
如何评估一个异常检测算法,以及如何开发一个关于异常检测的应用:
首先,在获取到的一堆数据中,取一大部分正常的(可能包含少部分异常)的数据用于训练集来训练分布概率公式p(x)。
然后,在交叉验证和测试集中使用包含正常和一定比例异常的数据,来通过查准率和召回率,以及F值公式来评价一个算法。
举个例子
假设有:
下面分割一下训练集,交叉验证集和测试集:
在训练集上训练出概率分布函数p(x)
在交叉验证集上,预测y:
下面通过和真实标签的比较,可以计算出 查准率(Precision)和召回率(Recall),然后通过F值公式来得到一个数值。
总结一下,我们将正常的数据分成60:20:20,分别给训练集,交叉验证集,测试集,然后将异常的数据分成两半,交叉验证集和测试集各一半。
我们可以通过改变不同的阈值 从而得到不同的评价系数来选取一个最佳的阈值。
当得到的评价系数不佳时,也可以通过改变特征值的种类和数量来获取理想的评价系数
在使用异常检测时,对性能影响最大的因素是特征值的选择。
首先要对特征向量使用高斯分布来建模,通常情况下,我们得到的原始数据并没有呈现高斯分布,例如这种:
有几种方法可以实现:
通过上述办法,可以将数据转换成高斯分布的形式。
异常检测有点类似监督学习中的二元分类问题。
我们的目标是使得p(x)对于正常的数据来说是大的,而对于异常的数据来说是很小的,而在异常检测中一个常见的问题是最终我们的到的p(x)对于正常和异常的都很大。
在这种情况下需要观察一下交叉验证集中的异常示例,尝试找出能更好区分数据的新特性。
例子
例如,有一个关于机房机器的样本示例,开始收集的样本示例中包含的特征值有关于cpu负载和网络流量的。
cpu负载和网络流量是呈线性关系的,当网络流量变大时,cpu也会相应增大。
现在有一个异常的示例是网络流量不大,cpu确负载很大。假如在只有这两个特征值的情况下运行异常检测算法得出的p(x),可能就效果不佳。这时可以添加一个特征值,是流量和cpu的比例关系,这样就约束来上述的异常示例,通过这三个特征值得到的异常检测算法可能就会好一点。
异常检测一般用于:
样本中 的数量非常少(0-50个),而 的非常多。这样由于样本数量的过少,达不到良好的训练效果,而在异常检测中确能够表现良好。
还有就是导致 的情况非常多,且有不可预见性。
监督学习一般用于:
样本中 和 的数量都非常多。这样就有足够的样本数量去训练算法。
多元高斯分布是异常检测的一种推广,它可能会检测到更多的异常。
在原始高斯分布中,模型p(x)的搭建是通过分别计算 来完成的,而多元高斯分布则是一步到位,直接计算出模型:
PS: 是一个协方差矩阵。
通过改变 和 可以得到不同的多元高斯分布图:
原始高斯分布模型,它的多个特征值之间的关系是轴对齐的(axis-aligned),两个或多个高斯分布之间没有相关性。
而多元高斯分布能够自动捕获x的不同特征之间的相关性。因此它在图像上会现实椭圆或有斜率的椭圆。
在平常的使用中,一般是使用原始高斯分布模型的,因为它的计算成本比较低。
在多元高斯分布中,因为要计算多个特征值之间的相关性,导致计算会慢很多,而且当特征值很多是,协方差矩阵就会很大,计算它的逆矩阵就会花费很多时间。
要保证样本数量m大于特征值数量n,否则协方差矩阵会不可逆;
根据经验法则,当 时,多元高斯分布会表现良好。
在原始高斯分布模型中可以手动添加相关性高的特征值之间的关系,可以避免了使用多元高斯分布,减小计算成本。
Graph Anomaly Detection with Deep Learning——边检测
边异常检测
论文:A Comprehensive Survey on Graph Anomaly Detection with Deep Learning
论文地址:https://arxiv.org/abs/2106.07178
与针对单个节点的异常节点检测不同,异常边缘检测 (Anomalous edge detection,ANOS ED)旨在识别异常链路,这些链接通常会通知真实对象之间的意外或异常关系。
基于静态图的边属性异常检测
基于深度神经网络的异常检测
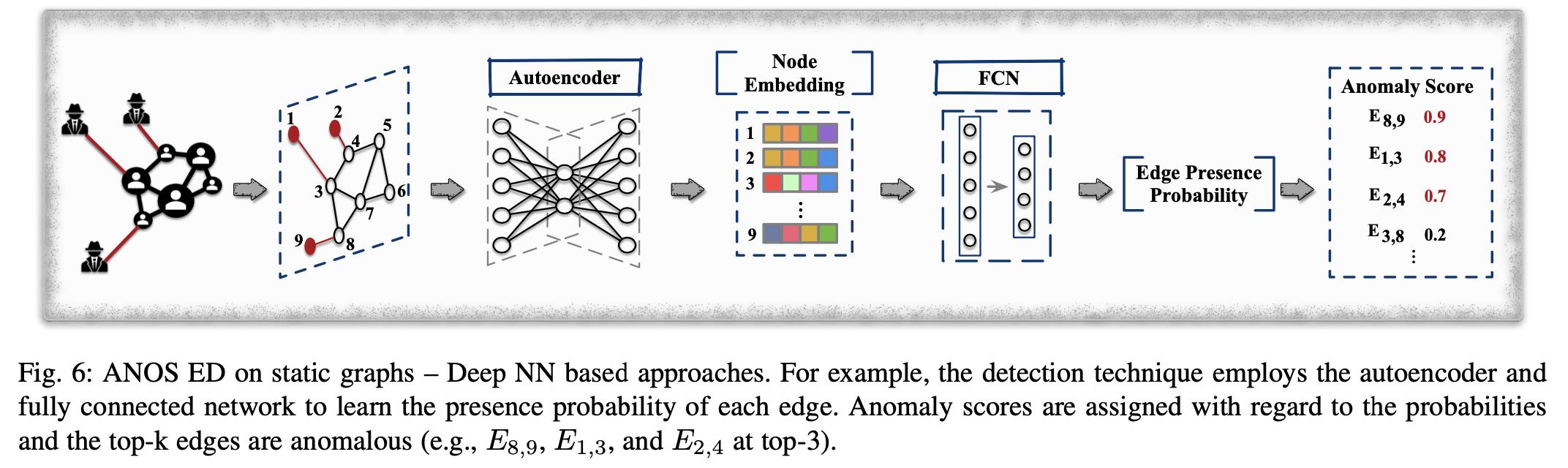
核心思想:使用自动编码器和全连接网络(FCN)进行异常边缘检测
Ouyang 等人[1] 通过深层模型对边分布进行建模,其核心思想是基于构成边的两个节点及其邻居节点属性,估算边出现的概率。具体来说,为了估算边出现的概率他们提出了一个名为 UGED 的方法,首先将每个节点编码为低维向量,并通过自身和邻居向量的平均聚集生成节点的表示,之后输入到另外一个 FCN 中来估算概率。该模型的示意图如下:
基于 GCN 的异常检测
核心思想:对边分布建模,利用 GCN 可以更好地捕获图形结构信息
Duan 等人[2] 提出异常边的存在阻止了基于 GCN 的传统模型捕捉真实边分布,从而导致次优检测性能。他们认为在进行节点 embedding 的时候需要减轻异常边的负面影响。因此,他们提出一种名为 AANE 的方法,在训练期间迭代更新 embedding 和边检测来提高性能。在每个训练迭代中,AANE 通过 GCN 层生成节点 embedding,并学习指示矩阵以发现潜在的异常边缘。其模型的损失函数包含两个部分:异常感知损失:
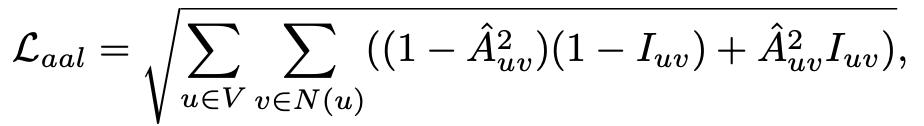 和调整拟合损失:
和调整拟合损失:
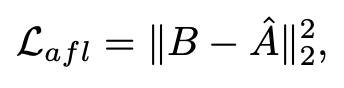
其中,I 为指示矩阵,V是节点集合,N(u) 是u的邻居集合,B 是调整后的邻接矩阵,该矩阵从输入邻接矩阵 A 中移除所有预测异常。
基于网络表示的异常检测
核心思想:直接从图形学习的边表示。
如果边表示能够很好地保留成对节点之间的图形结构和交互内容(例如,在线社交网络中的消息、引文网络中的合著论文),则可以预期增强的检测性能
Xu 等人[3] 在生成边表示方面展现了一部分可能的结果。尽管这个文章不是专门为图异常检测而设计的,但它们指出了一种潜在的 ANOS ED方法。
PS: 当前可能并没有一个代表性的工作可以,因此作者在此处只是简单提及,并未介绍
基于动态图的异常边检测算法
传统的非深度异常检测
核心思想:于利用时间信号(例如,图结构的变化),并应用专门设计的统计度量来检测动态图上的异常边。
Eswaran 等人[4] 将动态图建模为边的变化,并利用图结构以及结构演化模式。他们提出了两种异常边:1、连接图形中断开连接的区域的边;2、突然出现的边。
Chang 等人[5] 提出了一种新的频率分解算法,旨在根据观察到的频率的可能性来发现异常的入射边。具体而言,该方法融合了概率模型和矩阵分解的优点,用于捕获节点的时间和结构变化。
基于网络表示的异常检测
核心思想:将动态图形结构信息编码为边缘表示,并将上述传统异常检测技术应用于不规则边缘的检测
Yu 等人提出的 Netwalk [6] 方法也可以检测动态图中的异常边,使用节点嵌入将边编码到共享的潜在空间中,然后根据它们到潜在空间中最近的边簇中心的距离来识别异常。实际上,Netwalk生成的边表示是源节点和目标节点表示的Hadamard乘积。当新边到达或现有边消失时,节点和边表示将根据每个时间戳的临时图中的随机游动进行更新,然后重新计算边簇中心和边异常分数
基于 GCN 的异常检测
核心思想:基于图结构构建 embedding 向量
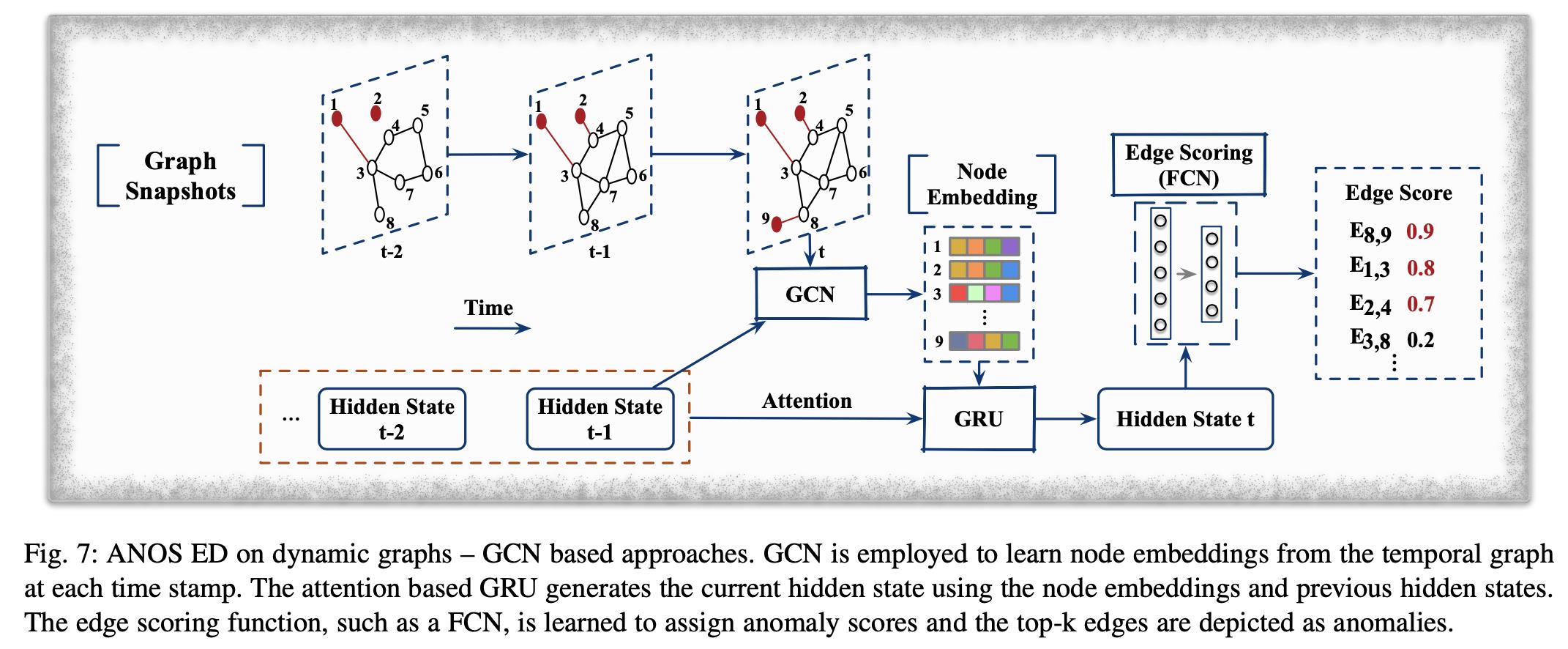
尽管NetWalk能够检测动态图中的异常,但它只更新边表示,而不考虑长/短期节点和图结构的演化模式。Zheng 等人[7] 结合时间、结构和属性信息来度量动态图中边的异常性。他们提出了一个半监督模型 AddGraph,该模型由 GCN 和 GRU 组成,分别从每个时间戳的时态图和它们之间的依赖关系中捕获更具代表性的结构信息。在每个时间戳 t ,GCN 使用上一个时间戳的隐状态生成节点的 embedding,之后 GRU 从节点 embedding 中学习当前隐状态,并关注以前的隐藏状态。在获得所有节点的隐藏状态后,AddGraph 根据与之关联的节点为时态图中的每条边分配一个异常分数。模型示意图如下:
下图是边异常检测的代表算法总结:

参考文献:
[1] L. Ouyang, Y. Zhang, and Y. Wang, “Unified graph embedding-based anomalous edge detection,” in IJCNN, 2020, pp. 1–8.
[2] D. Duan, L. Tong, Y. Li, J. Lu, L. Shi, and C. Zhang, “Aane: Anomaly aware network embedding for anomalous link detection,” in ICDM, 2020, pp. 1002–1007.
[3] L. Xu, X. Wei, J. Cao, and P. S. Yu, “Icane: Interaction content-aware network embedding via co-embedding of nodes and edges,” Int. J. Data Sci. Anal., vol. 9, no. 4, pp. 401–414, 2020.
[4] D. Eswaran and C. Faloutsos, “Sedanspot: Detecting anomalies in edge streams,” in ICDM, 2018, pp. 953–958.
[5] Y.-Y. Chang, P. Li, R. Sosic, M. Afifi, M. Schweighauser, and J. Leskovec, “F-fade: Frequency factorization for anomaly detection in edge streams,” in WSDM, 2021, pp. 589–597.
[6] W. Yu, W. Cheng, C. C. Aggarwal, K. Zhang, H. Chen, and W. Wang, “Netwalk: A flexible deep embedding approach for anomaly detection in dynamic networks,” in KDD, 2018, pp. 2672–2681.
[7] L.Zheng, Z.Li, J.Li, Z.Li, and J.Gao,“Addgraph:Anomalydetection in dynamic graph using attention-based temporal gcn,” in IJCAI, 2019, pp. 4419–4425.
欢迎关注微信公众号:

以上是关于异常检测(Anomaly Detection)的主要内容,如果未能解决你的问题,请参考以下文章
异常检测(Anomaly detection): 异常检测算法(应用高斯分布)
Ng第十五课:异常检测(Anomaly Detection)
Graph Anomaly Detection with Deep Learning——边检测