jquery 有3段video视频,当video结束的时候循环动态更换video的src
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了jquery 有3段video视频,当video结束的时候循环动态更换video的src相关的知识,希望对你有一定的参考价值。
jquery 有3段video视频,当video结束的时候循环动态更换video的src,然后每段video上都有文字,在更换src的时候顺便淡入淡出更换盖在上面的文字
参考技术A html5 的video标签有一个属性loop:循环播放
加上去就可以循环播放了
Media.ended; //是否结束
判断之后加上jQuery的fadeIn(淡入)、fadeOut(淡出)切换文字
Video Caption Tutorial
欢迎star fork: video-caption.pytorch或者video-caption.pytorch
任务介绍
和image caption一样,不过是将图片换成了一段视频,根据视频内容给出一句文字描述。可用于后续的视频检索或者摘要生成,帮助智能体或者有视觉障碍的人理解现实情况。

Language model-based approach
语言模型为基础的,预测主谓宾然后补充其他组成一段话
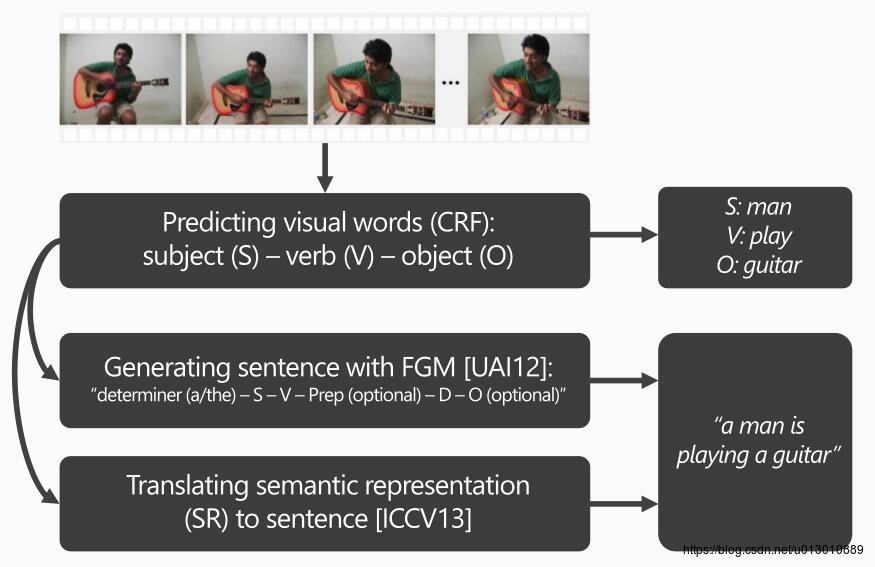
Sequence learning-based approach
Translating Videos to Natural Language Using Deep Recurrent Neural Networks应该是第一篇直接从视频生成文字的文章,它利用cnn将视频中所有帧提取特征(fc7)然后进行mean pool之后送入后面的LSTM decoder进行文字的生成。
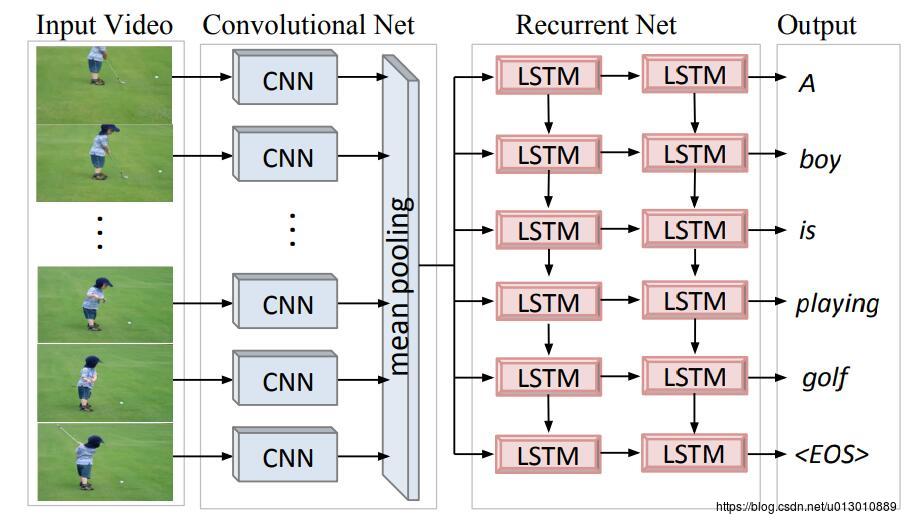
Sequence to Sequence – Video to Text是上一篇文章的作者Subhashini Venugopalan对自己模型的改进,之前直接进行mean pool,忽略了这些特征的顺序和时序关系。所以本文对每帧的特征都送到LSTM encoder中进行,然后再送到decoder中生成文字,这种模型简称成为S2VT
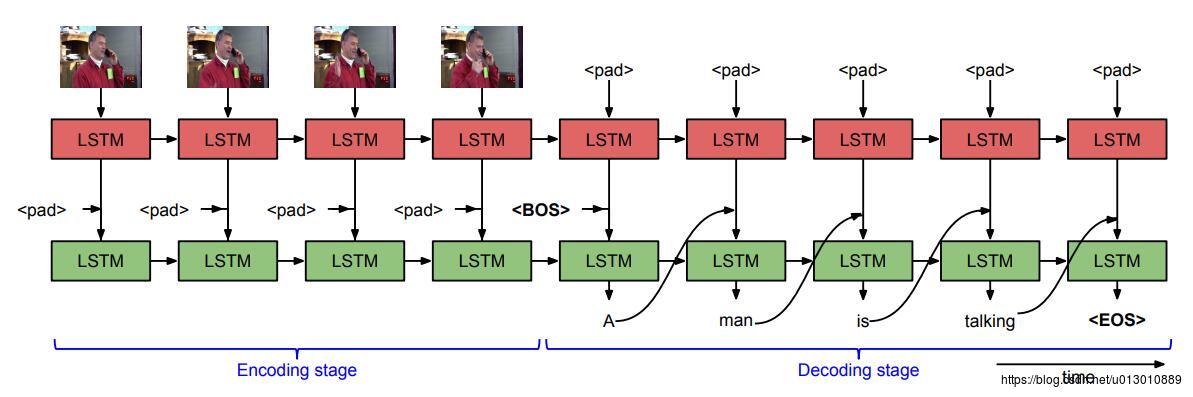
后续又把s2vt进行化简,s2vt中是两路LSTM,后续生成文字时上面的LSTM还要输出到下面的LSTM作为输入,后来的论文中对此进行化简,上面的LSTM encoding完后只把它的输出和隐状态送到后面decoder中,不再跟着decoder再跑一段序列。
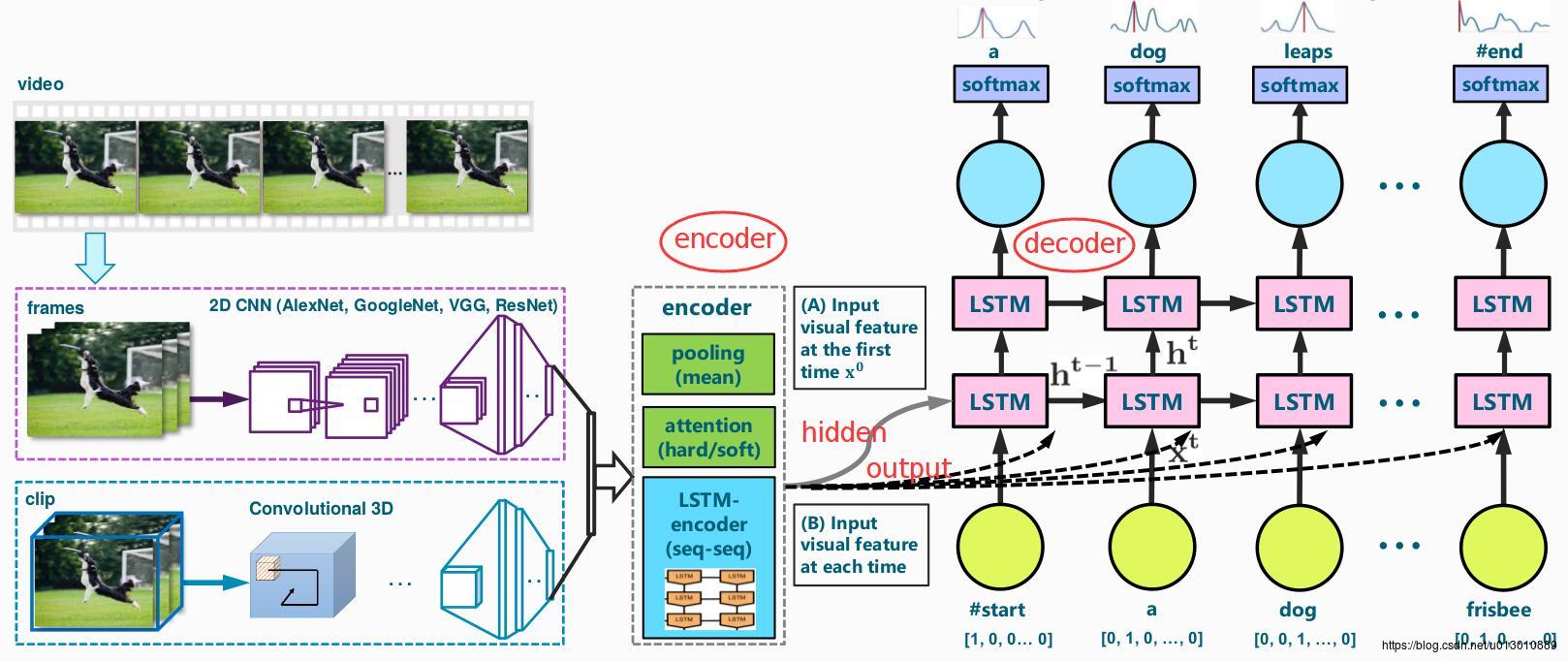
上图有以下几点需要展开讲
1. feature的改进
2. decoder部分的改进,如Attention机制等
3. 其他如增强学习,Reconstruction network等
Video Feature
2d特征的发展主要得益于ImageNet,它是对图片分类。而3d特征主要是对视频分类或者视频中action、event、activity识别,有以下几种结构,本文主要介绍现在比较流行的3D-ConvNet
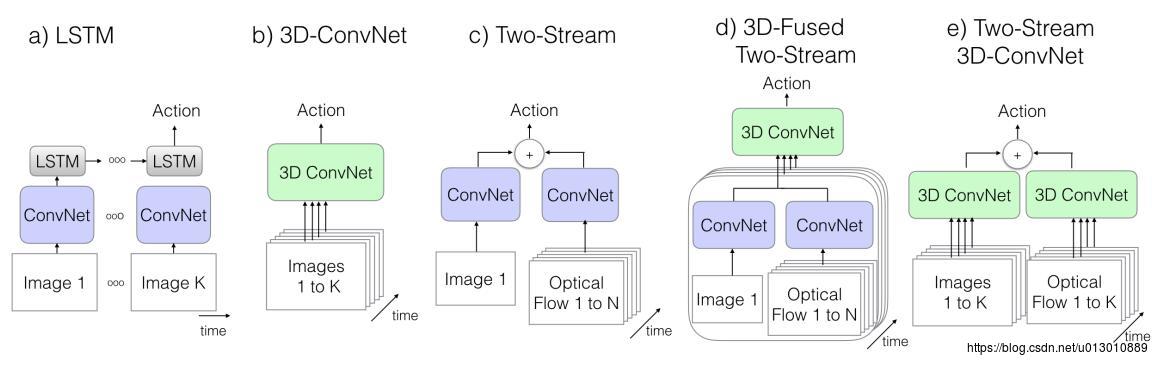
下图中b是将每个帧的图片在channel维度进行cat起来,c是3d卷积,在时间维度上也有一个步长Learning Spatiotemporal Features with 3D Convolutional Networks。

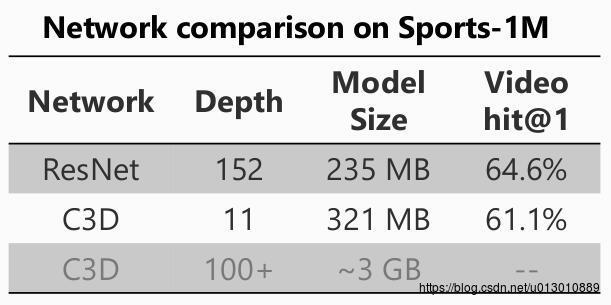
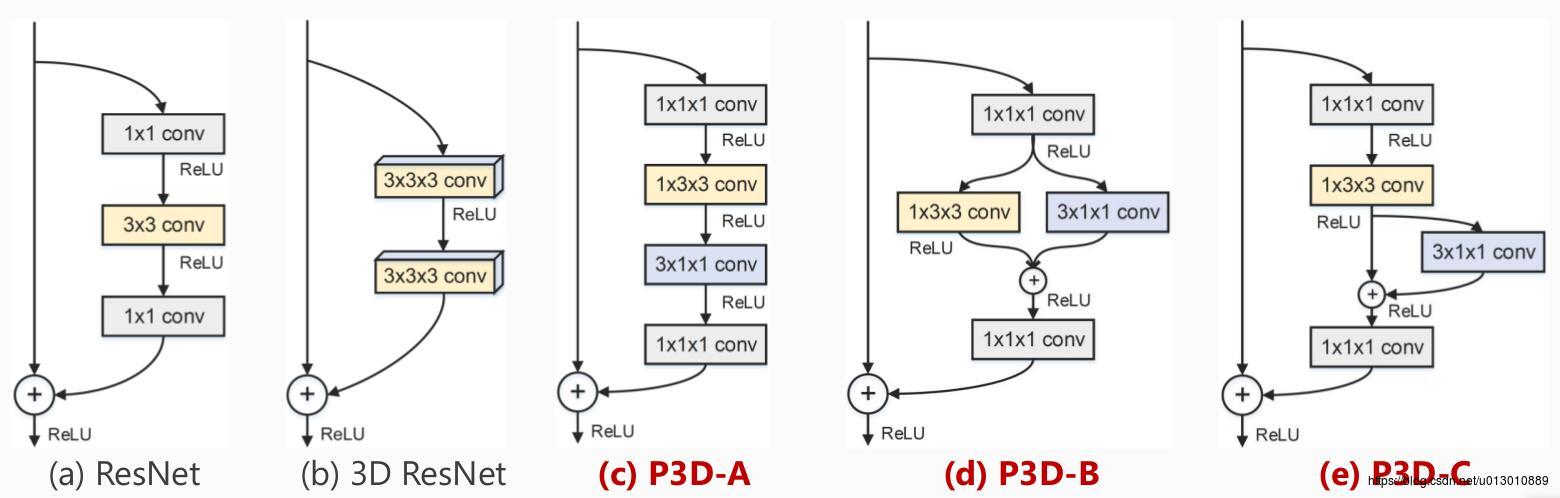
但是c3d的模型参数太多了,它是类似与2d中的VGG,如果对c3d进行加深参数急剧增长。那么能不能把2d中的resnet迁移过来呢,当然可以!但是那个时候数据库还不行(一是有些数据库数量不够,二是sports-1M这种量虽然超级大但是噪声太多它是一整段视频才有一个label,有很多片段都和label action无关),直接把resnet套过去也是不好训练的微软出了个p3d来改,一是进一步减少3d resnet的参数,二是1*3*3的卷积可以利用2d resnet的参数来初始化Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks
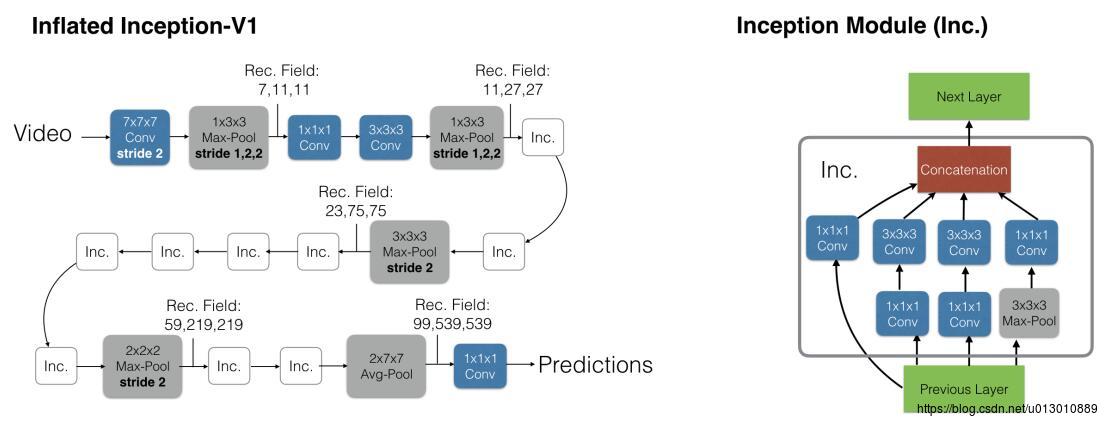
i3d(Inflated 3D ConvNet)Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset,该文提出了i3d的模型,更重要的是提出了一个Kinectics的数据库,数据量是240k段视频 clips,400类动作称为Kinectics-400,最近又推出了Kinectics-600,500K段视频 clips,600类动作称为Kinectics-600。这个数据库很重要的一点是它是只截取该action对应的视频片段(clips),基本不含无关帧,噪声较少。数据库地址
3D-ResNets是在Kinectics数据库推出后,从scratch开始训练完整的ResNets。
ResNet-18在各个视频数据库上训练的曲线图,发现在前3个库上已经overfiting了,但是Kinectics上并没有,所以作者开始加深网络在Kinectics上再次训练。
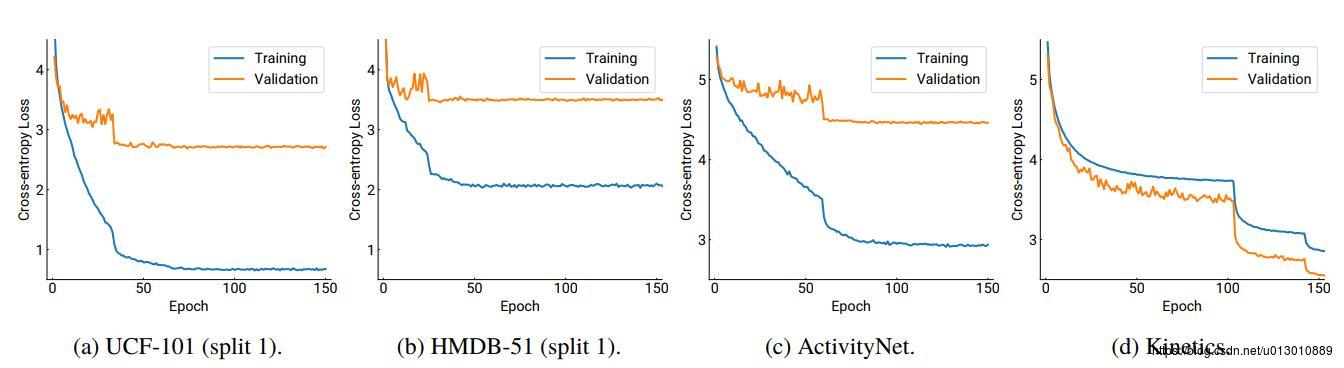
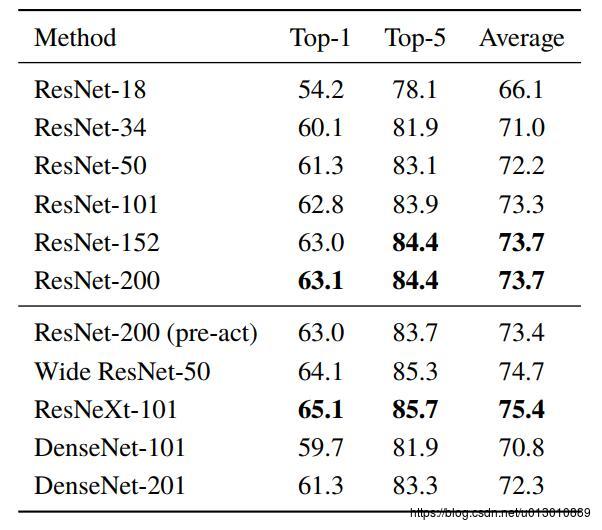
在Kinectics上从scratch开始训练,验证集上的结果,全部可作为pretrained model,且后续也证明了这些预训练模型用到UCf-101和HMDB-51上取得了很好的效果。
Audio Feature
在caption时也可以加入音频特征,不过我对音频方面不是特别了解,暂时就用的google tensorflow提供的Models for AudioSet: A Large Scale Dataset of Audio Events
Attention Mechanism
我在介绍daijifeng老师的 Relation Networks for Object Detection时简单提了一下Attention model。这里也一样,我们把所有视频特征和音频特征encoding后得到一个context,即encoder里每个时刻的输出output。在decoding阶段每个时刻输出单词时需要用不同的context。
下面介绍一种最简单的,decoding时,对于某个时刻的隐状态hidden_state,计算它与encoder_outputs的相似度(encoder_outputs是encoding时所有时刻的输出),然后进行softmax得到权重attn,然后用这个权重取乘以encoder_outputs,得到最终的context(encoder_outputs不同时刻输出的融合)
或者就是用一下其他的加一些全连接参数,或者对hidden_state和encoder_outputs降维后再进行相似度计算
Sundrops/video-caption.pytorch: Attention.py
## directly calculate the similarity of between encoder_outputs and hidden_state ###
# (batch, seq_len, dim) * (batch, dim, 1) -> (batch, seq_len, 1)-> (batch, seq_len)
attn = torch.bmm(encoder_outputs, hidden_state.unsqueeze(2)).squeeze(2)
# (batch, seq_len)-> (batch, 1, seq_len)
attn = F.softmax(attn, dim=1).unsqueeze(1)
# (batch, 1, seq_len) * (batch, seq_len, dim) -> (batch, 1, dim)
context = torch.bmm(attn, encoder_outputs).squeeze(1)
return context其他
强化学习来做caption
由于我们训练时loss是定义在单个词上的交叉熵loss,而测试时是采用BLEU、CIDEr-D等指标,BLEU-4是4-gram看连词的,CIDEr-D采用df-idf不同的词有着不同的权重的,这些我们都无法去定义loss(不好反传,甚至不能反传),需要借助强化学习来弥补这个训练和测试的鸿沟用Reinforcement Learning来做image captioning
- Deep Reinforcement Learning-based Image Captioning with Embedding Reward cvpr 2017 oral
- Reinforced Video Captioning with Entailment Rewards EMNLP 2017
Reconstruction Network
Reconstruction Network for Video Captioning cvpr2018
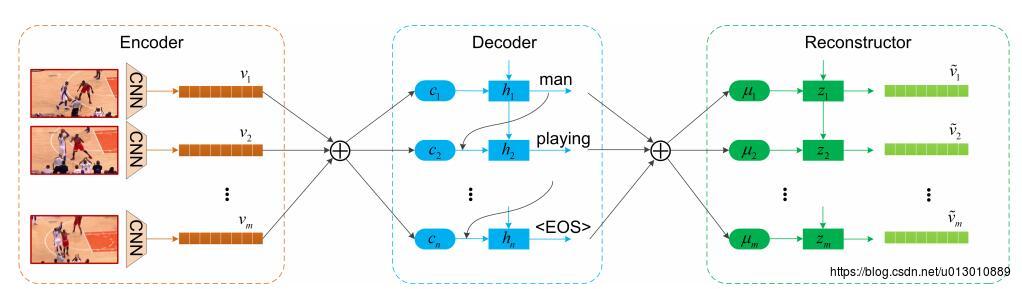
将Decoder产生的输出送入Reconstructor(LSTM/GRU)中重构,得到向量后再和Encoder输出(Decoder输入)做L2 loss。即将video to sentence后再sentence to video, 即dual learning(中-英,英-中),使得中间的特征学习的更好。
Video Caption的比赛
MSR-VTT
| Rank | Team | Organization | BLEU@4 | Meteor | CIDEr-D | ROUGE-L |
|---|---|---|---|---|---|---|
| 1 | RUC+CMU_V2T | RUC & CMU | 0.390 | 0.255 | 0.315 | 0.542 |
| 2 | TJU_Media | TJU | 0.359 | 0.226 | 0.249 | 0.515 |
| 3 | NII | National Institute of Informatics | 0.359 | 0.234 | 0.231 | 0.514 |
| video-caption | model | feature | ||||
| - | s2vt | vgg19 | 0.2864 | 0.2055 | 0.1748 | 0.4774 |
| - | s2vt | resnet101 | 0.3118 | 0.2130 | 0.2002 | 0.4926 |
| - | s2vt | nasnet | 0.3003 | 0.2176 | 0.2213 | 0.4931 |
| - | s2vt | nasnet+c3d_kinectics | 0.3237 | 0.2227 | 0.2299 | 0.5041 |
| - | s2vt | nasnet+c3d_kinectics+beam search | 0.3349 | 0.2244 | 0.2340 | 0.5034 |
| - | s2vt+att | nasnet+c3d_kinectics | 0.3226 | 0.2235 | 0.2399 | 0.5011 |
| - | s2vt+att | nasnet+c3d_kinectics+beam search | 0.3419 | 0.2278 | 0.2503 | 0.5063 |
ActivityNet: Dense Caption
Dense-Captioning Events in Videos
一段视频给出很多句描述,而且描述之间在时间上可能有交叉,这就和之前的不太一样了,之前的每段都是单一事件事先截取好的,这里可能需要现在时间维度上提取proposal,将视频截成很多片段,这些片段可能有交叠。如果不想这样就简单的就是按照不同间隔将视频段进行平分,比如有10帧10帧的也有20帧20帧的,但效果可能不如别人用模型在维度提取proposal,这个比赛确实包含提取proposal这个子任务Temporal Action Proposals。
以上是关于jquery 有3段video视频,当video结束的时候循环动态更换video的src的主要内容,如果未能解决你的问题,请参考以下文章
H5 video JS/Jquery如何设置视频选择性循环播放
Jquery更改HTML5的video标签的属性,实现更换视频的效果。或者提供一个可行的思路