MySQL入门指南4(查询进阶,外连接)
Posted 爱笑的钮布尼茨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL入门指南4(查询进阶,外连接)相关的知识,希望对你有一定的参考价值。
前期回顾:
目录
一、查询进阶
1.查询增强
前面我们介绍了mysql表的基本查询,这里我们将会在基本查询的基础上进行一些扩展。
代码演示如下:
-- 查找1992.1.1 后入职的员工
-- 这里的hiredate时日期类型,日期类型可以直接比较,但要注意格式
SELECT * FROM emp
WHERE hiredate >'1992-01-01';
-- 查找首字母为S的员工的姓名与工资
-- 在近似查询中 % 代表0到多个字符
SELECT ename,sal FROM emp
WHERE ename LIKE 'S%';
-- 查找第三个字符为大写O的员工的姓名与工资
-- 在近似查询中 _ 表示一个字符
SELECT ename,sal FROM emp
WHERE ename LIKE '__O%'; -- 此处有两个 _
-- 显示没有上级雇员的情况
-- 没有上级即:该记录的mgr为NULL
SELECT * FROM emp
WHERE mgr IS NULL; -- 不可用 = NULL
-- 查询表结构
DESC emp;
-- 按照工资从低到高排序
SELECT * FROM emp
ORDER BY sal;-- 默认升序 ASC
-- 按照部门升序,工资降序排序
-- 多重排序,按照要求一次排序
SELECT * FROM emp
ORDER BY deptno ASC ,sal DESC ;
-- 显示每种岗位的雇员总数,平均工资
SELECT COUNT(*),FORMAT(AVG(sal),2),job
FROM emp
GROUP BY job;
-- 显示雇员总数,以及获得补助的雇员数
-- 未获得补助的员工 comm 值为NULL
-- 在使用 COUNT(列) 时正好不计算在内
SELECT COUNT(*),COUNT(comm)
FROM emp;
-- 统计没有获得补助的雇员数
-- 若为真,则1 ,进而count统计时会统计上
SELECT COUNT(IF(comm IS NULL,1,NULL)) FROM emp;
SELECT COUNT(*)-COUNT(comm) FROM emp;
-- 显示管理员的总人数
SELECT COUNT(job) FROM emp
WHERE job='MANAGER';
-- 统计各部门平均工资,且大于1000,
-- 并降序排列 前两条记录
SELECT FORMAT(AVG(sal),2) AS avg_sal ,deptno
FROM emp -- 从emp表中查询
GROUP BY deptno -- 按照部门分组
ORDER BY avg_sal DESC -- 降序排列
LIMIT 0,2; -- 分页查询前两条记录
-- 总结:如果select语句同时包含 group by,
-- having,limit,order by, 一般按照以下顺序
SELECT column1,column2 FROM `table`
GROUP BY `column`
HAVING `condition`
ORDER BY `column`
LIMIT `start`,`rows`;
除此之外,我们再介绍一下分页查询当我们的数据记录非常多时,我们可能需要分页查询。
分页查询基本语法:
SELECT .....FROM ......
LIMIT start ,rows;
代码演示如下:
-- 按照雇员id排序 每页显示三条记录
SELECT * FROM emp
ORDER BY empno
LIMIT 0,3; -- 从第0+1行开始,得到三条记录
-- 按照雇员id排序 每行显示5条记录
SELECT * FROM emp
ORDER BY empno
LIMIT 3,5; -- 从第3+1行开始,得到五条记录2.多表查询
多表查询是基于两个或者两个以上的表的查询,在实际应用中,查询单个表可能不能满足你的需求,因此这里我们就引出了多表查询。
当我们同时查询多个表时,不同的表之间会形成笛卡尔集。我们需要在笛卡尔集的基础上加上筛选条件来满足我们的要求。
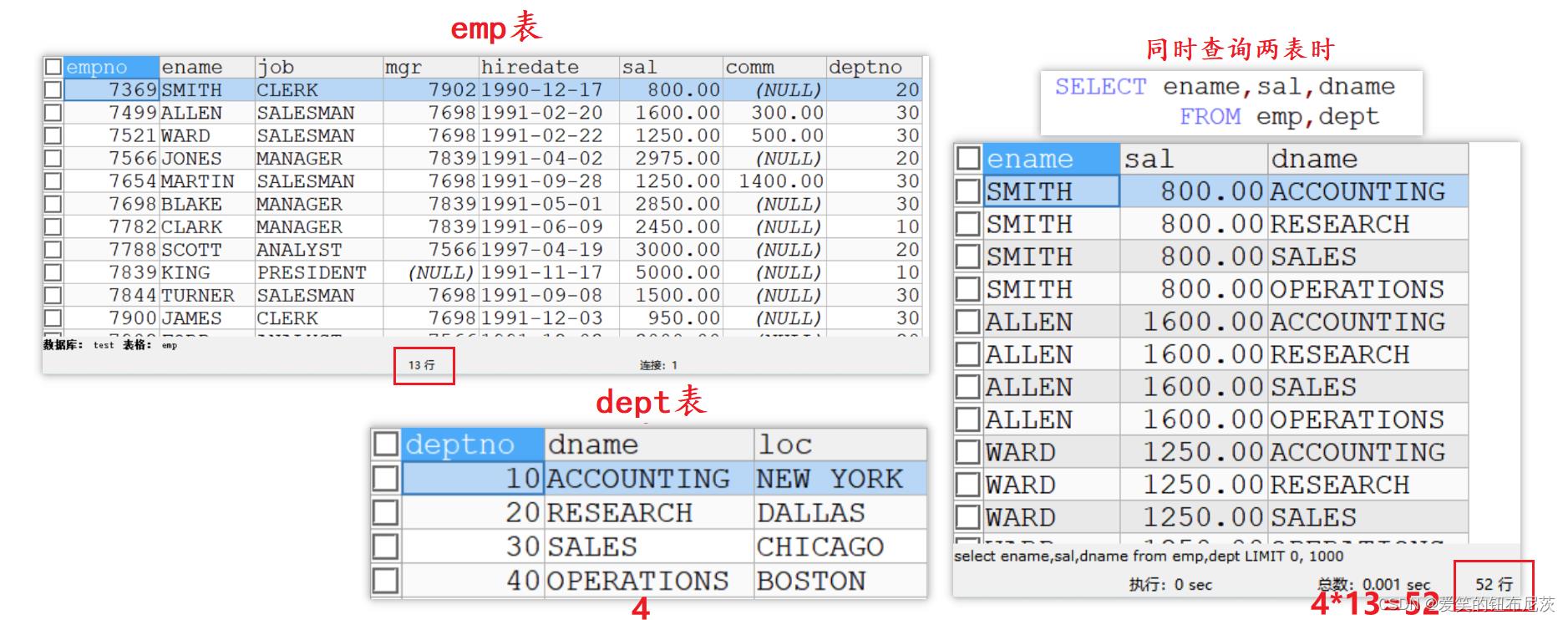
代码演示如下:
-- 多表查询
-- 笛卡尔集
-- 显示雇员名,雇员工资及所在部门的名字
SELECT ename,sal,dname
FROM emp,dept
WHERE emp.deptno=dept.deptno; -- 当满足此条件时,才是我们要的结果
-- 提示:多表查询的条件不能少于表数-1 否则会出现笛卡尔集
-- 显示部门号为10的部门名,员工名,工资
SELECT dname,ename,sal
FROM emp,dept
WHERE emp.deptno=dept.deptno&&emp.deptno=10;
-- 显示各个员工的姓名,工资,以及工资级别
SELECT ename,sal,grade
FROM emp,salgrade
WHERE sal BETWEEN salgrade.losal AND salgrade.hisal;
-- 自连接:在同一张表的连接查询
-- 显示公司员工和他的上级的名字
SELECT emp1.ename AS worker ,emp.ename AS `super`
FROM emp AS emp1,emp -- 由于列名不准确,我们要用AS指定列
WHERE emp1.mgr = emp.empno;3.子查询
子查询是指嵌入在其他SQL语句中的SELECT语句,也叫嵌套查询。按查询结果分为单行子查询,多行子查询,多列子查询。
多行子查询代码演示:
-- 多行子查询
-- 1.0如何显示与SMITH同一个部门的所有员工
-- 1.1 先找到SMITH所在部门
SELECT deptno FROM emp
WHERE ename ='SMITH';
-- 1.2 再找那个部门的员工
SELECT * FROM emp
WHERE deptno = (
SELECT deptno FROM emp
WHERE ename ='SMITH')
-- 2.0查询和部门10的工作相同的雇员的信息,
-- 但不包括部门10自己的雇员
-- 2.1 先找部门10有哪些工作
SELECT DISTINCT job FROM emp -- 由于可能多个员工的从事同一个工作,因此要去重。
WHERE deptno = 10;
-- 2.2 再找从事这些工作的所有雇员
SELECT * FROM emp
WHERE job IN( -- 因为部门10可能不止一种工作
SELECT DISTINCT job FROM emp
WHERE deptno = 10);
-- 2.3 在筛选掉部门号为10的雇员
SELECT * FROM emp
WHERE job IN(
SELECT DISTINCT job FROM emp
WHERE deptno = 10)AND deptno!=10;
子查询当作临时表使用代码演示:
-- 子查询当作临时表使用
-- 显示工资比部门30的所有员工的工资高的员工的姓名、工资、部门号
-- 用MAX
SELECT * FROM emp
WHERE sal>(SELECT MAX(sal) FROM emp WHERE deptno = 30);
-- ALL
SELECT * FROM emp
WHERE sal>ALL(SELECT sal FROM emp WHERE deptno = 30);
-- 显示至少比部门30其中一个高的员工
-- ANY
SELECT * FROM emp
WHERE sal>ANY(SELECT sal FROM emp WHERE deptno = 30);
-- 用MIN
SELECT * FROM emp
WHERE sal>(SELECT MIN(sal) FROM emp WHERE deptno = 30);
-- 将子查询当作临时表使用
SELECT cat_id,MAX(shop_price)
FROM ecs_goods
GROUP BY cat_id;
SELECT goods_id,ecs_goods.cat_id,goods_name,shop_price
FROM ( -- 将子查询结果看成一个临时表再进行相关操作
SELECT cat_id,MAX(shop_price) AS max_price
FROM ecs_goods
GROUP BY cat_id
)temp,ecs_goods
WHERE temp.cat_id = ecs_goods.cat_id
AND temp.max_price=ecs_goods.shop_price;
多列子查询代码演示:
-- 多列子查询
-- 查询与ALLEN同部门,同工作的人,不包括其本人
-- 1.1先找到ALLEN的部门和工作
SELECT deptno,job FROM emp
WHERE ename ='ALLEN';
-- 1.2
SELECT * FROM emp
WHERE(deptno,job) =(
SELECT deptno,job
FROM emp
WHERE ename ='ALLEN'
)AND ename!='ALLEN';
-- 查询与阳阳同学成绩完全一样的同学
SELECT * FROM student
WHERE(chinese,math,english)=(
SELECT chinese,math,english
FROM student
WHERE `name`='阳阳同学'
)AND `name`!='阳阳同学';
-- from子句中使用子查询
-- 查找部门工资高于本部门平均工资的雇员资料
-- 各部门平均工资
SELECT AVG(sal),deptno
FROM emp
GROUP BY deptno;
SELECT ename,sal,avg_sal,emp.deptno
FROM emp,(
SELECT FORMAT(AVG(sal),2) AS avg_sal,deptno
FROM emp
GROUP BY deptno
)temp
WHERE emp.deptno=temp.deptno
AND emp.sal>avg_sal;
-- 查找每个部门工资最高的人的资料
-- 各部门最高工资
SELECT MAX(sal) AS max_sal,deptno
FROM emp
GROUP BY deptno;
SELECT ename,sal,max_sal,emp.deptno
FROM emp,(
SELECT MAX(sal) AS max_sal,deptno
FROM emp
GROUP BY deptno
)temp
WHERE emp.deptno=temp.deptno
AND emp.sal=temp.max_sal
ORDER BY sal;4.合并查询
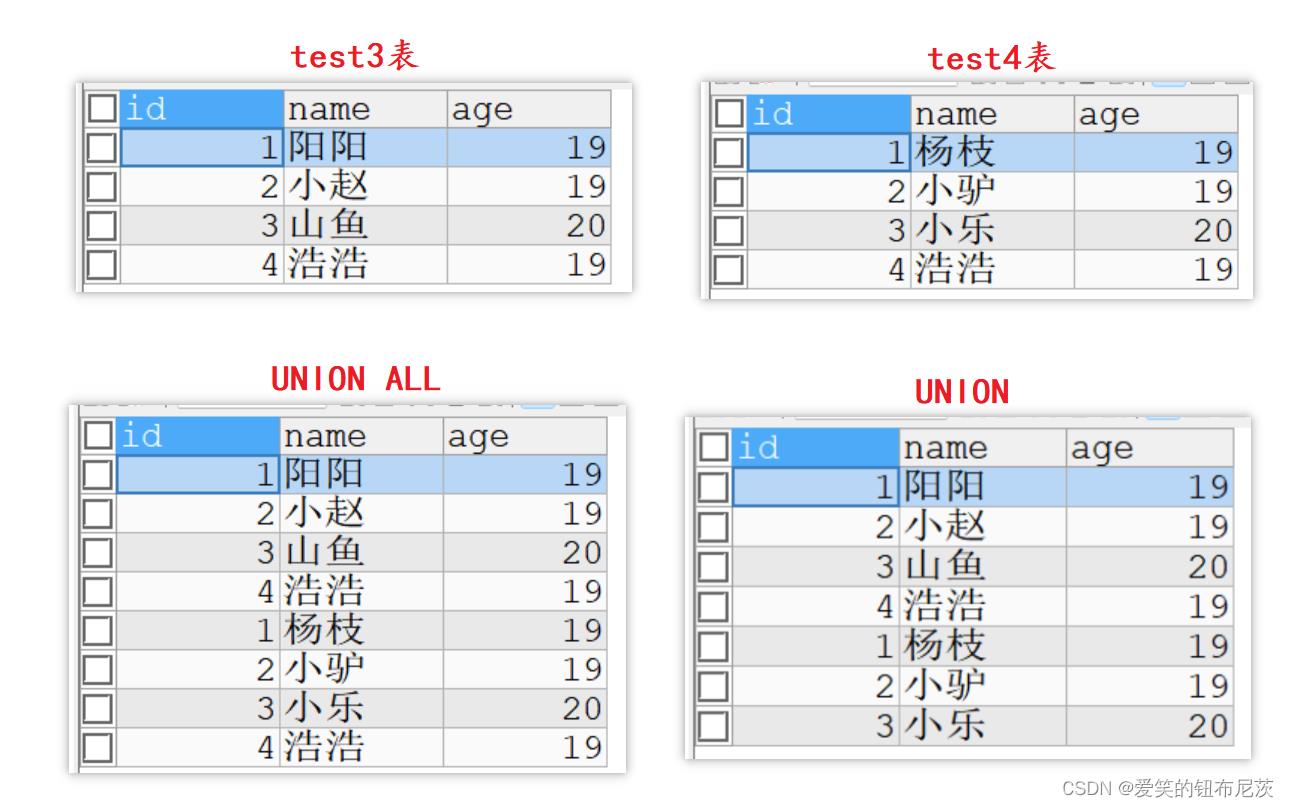
有时再实际应用中,为了合并多个 SELECT 语句的结果,可以使用集合操作符号UNION, UNION ALL. 它们都是用于取得两个结果集的并集。
但 UNION ALL 不会对结果去重,UNION 会自动对结果去重。
代码演示如下:
-- 合并查询
CREATE TABLE test3(
id INT,
`name` VARCHAR(23),
age INT);
INSERT INTO test3
VALUES(1,'阳阳',19),(2,'小赵',19),(3,'山鱼',20),(4,'浩浩',19);
CREATE TABLE test4(
id INT,
`name` VARCHAR(23),
age INT);
INSERT INTO test4
VALUES(1,'杨枝',19),(2,'小驴',19),(3,'小乐',20),(4,'浩浩',19);
SELECT * FROM test3
UNION ALL -- 直接合并不去重
SELECT * FROM test4;
SELECT * FROM test3
UNION ALL -- 去重合并
SELECT * FROM test4;
5.表的复制
-- 表复制
-- 自我复制
CREATE TABLE test(
id INT,
`name` VARCHAR(23),
age INT);
INSERT INTO test
VALUES(1,'阳阳',19),(2,'小赵',19),(3,'山鱼',20),(4,'浩浩',19);
-- 把查询到的本表内容加入到本表完成自我复制
INSERT INTO test
SELECT * FROM test;
DELETE FROM test
-- 去除表中重复记录
-- 1.创建一个新表
CREATE TABLE test2(
id INT,
`name` VARCHAR(23),
age INT);
-- 2.把旧表的数据复制到新表上
INSERT INTO test2(id,`name`,age)
SELECT DISTINCT id,`name`,age FROM test; -- 此处在查找时去重
-- 3.删除旧表
DROP TABLE test;
-- 4.新表改名
RENAME TABLE test2 TO test;二、外连接
前面我们学习的查询,是利用where子句对两张或多张表,形成的笛卡尔集进行筛选,根据关联条件,显示所有匹配的记录,匹配不上的不显示。
不过这样就会造成一个问题,比如当要求:列出部门名称(dept表)和这些部门的员工名称和工作(emp表),同时要求显示那些没有员工的部门。由于我们是在多表形成的笛卡尔集中匹配关联条件进行筛选,因此我们无法显示出没有员工的部门,也无法显示出没有部门的员工。
由此我们引出了外连接。
1.左外连接
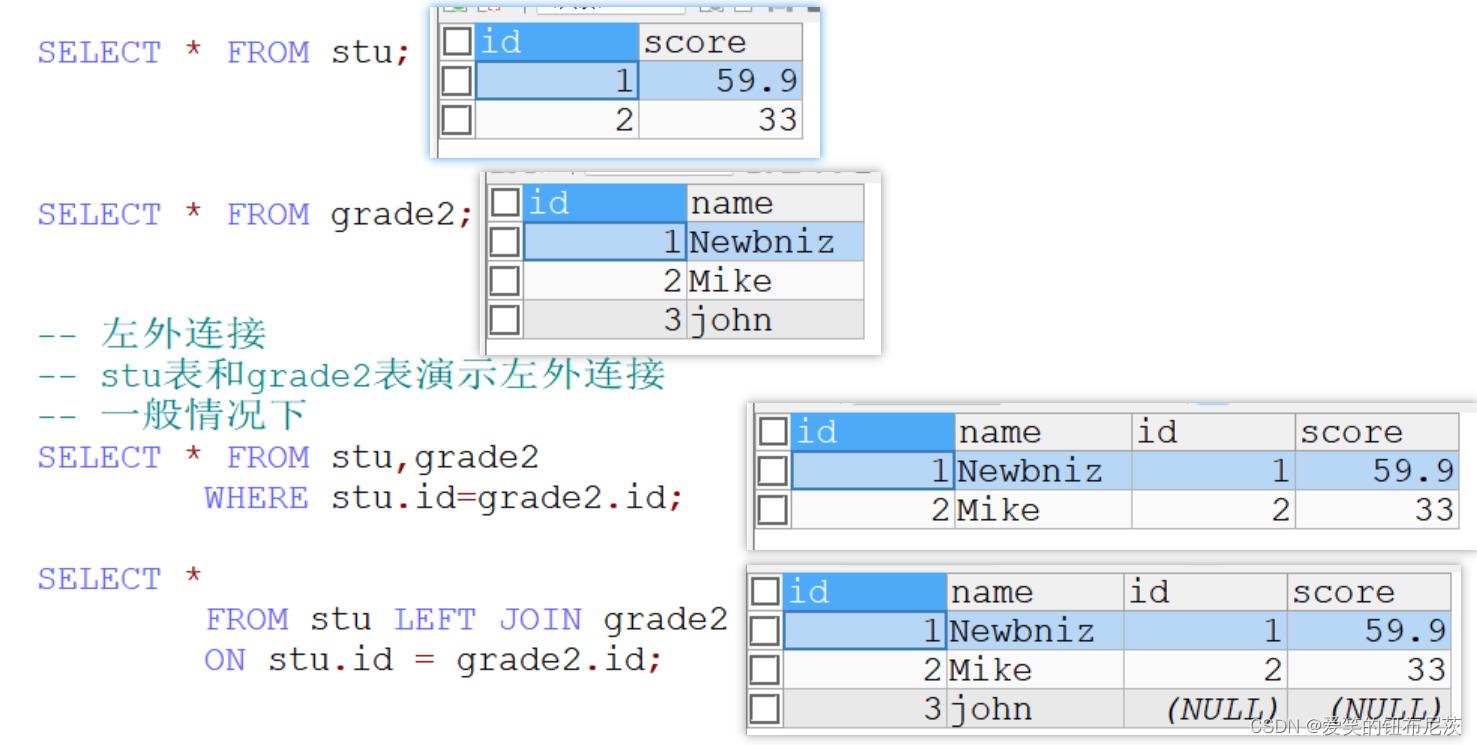
如果左侧的表完全显示我们就说是左外连接。
用法:SELECT ... FROM 表1 LEFT JOIN 表2 ON 条件
代码演示如下:
-- 创建测试表
CREATE TABLE stu(
id INT,
`name` VARCHAR(23));
INSERT INTO stu
VALUES(1,'Newbniz'),(2,'Mike'),(3,'john');
CREATE TABLE grade2(
id INT,
score DOUBLE);
INSERT INTO grade2
VALUES(1,59.9),(2,33);
-- 左外连接
-- 一般情况下
SELECT * FROM stu,grade2
WHERE stu.id=grade2.id;
-- 使用左外连接
SELECT *
FROM stu LEFT JOIN grade2
ON stu.id = grade2.id;
SELECT * FROM stu;
SELECT * FROM grade2;
2.右外连接
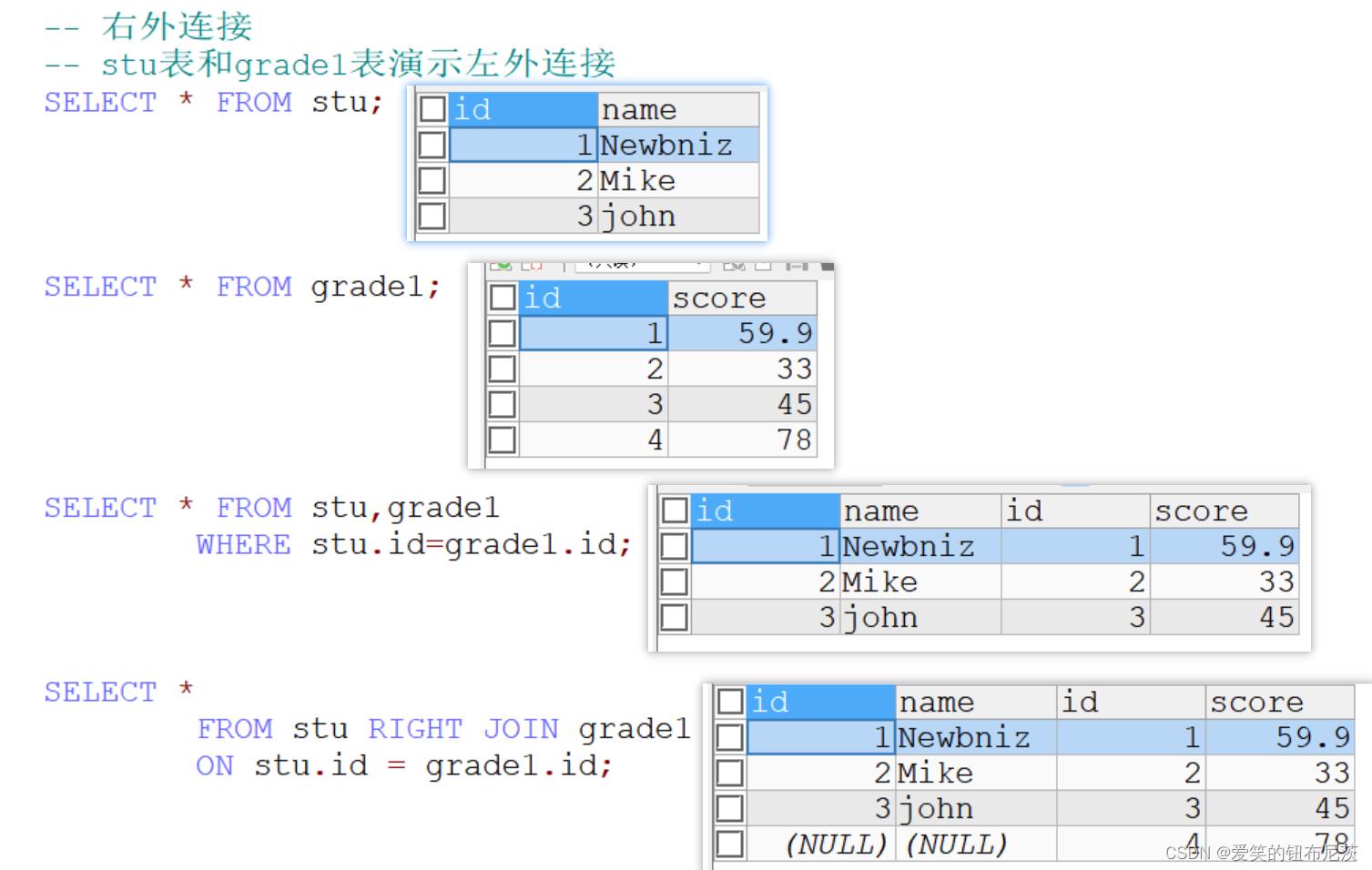
如果右侧的表完全显示我们就说是右外连接。
用法:SELECT ... FROM 表1 RIGHT JOIN 表2 ON 条件
代码演示如下:
-- 创建测试表
CREATE TABLE stu(
id INT,
`name` VARCHAR(23));
INSERT INTO stu
VALUES(1,'Newbniz'),(2,'Mike'),(3,'john');
CREATE TABLE grade1(
id INT,
score DOUBLE);
INSERT INTO grade1
VALUES(1,59.9),(2,33),(3,45),(4,78);
-- 右外连接
-- stu表和grade1表演示左外连接
SELECT * FROM stu;
SELECT * FROM grade1;
-- 一般情况下
SELECT * FROM stu,grade1
WHERE stu.id=grade1.id;
-- 使用右外连接
SELECT *
FROM stu RIGHT JOIN grade1
ON stu.id = grade1.id;
三、最后的话
✨ 原创不易,还希望各位大佬支持一下
👍 点赞,你的认可是我创作的动力!
⭐️ 收藏,你的青睐是我努力的方向!
✏️ 评论,你的意见是我进步的财富!
从入门到自闭之Python--MySQL数据库的多表查询
多表查询
- 连表:
- 内连接:所有不在条件匹配内的数据们都会被剔除连表
- select * from 表名1,表名2 where 条件;
- select * from 表名1 inner join 表名2 on 条件;
- 外连接:
- 左外连接:left join
- select * from 表名1 left join 表名2 on 条件;(显示表名1中的所有数据)
- 右外连接right join
- select * from 表名1 right join 表名2 on 条件;(显示表名2中的所有数据)
- 全外连接 full join
- select * from 表名1 left join 表名2 on 条件 union select * from 表名1 right join 表名2 on 条件;
- 左外连接:left join
- 子查询:建议分开做
- 内连接:所有不在条件匹配内的数据们都会被剔除连表
表的存储引擎:
show engines; 存储引擎
存储引擎:
- 表结构:存放在一个文件中(硬盘)
- 表数据:存放在另一个文件中(内存)
- 索引:为了方便查找设计的一个机制
种类:
innodb:索引+数据 表结构,持久化存储
支持事务begin:一致性,n条语句的执行状态是一致的
begin #开启事务 select ...... update/delete ...... commit; #提交事务,解锁被锁住的数据支持行级锁:只对涉及到修改的行加锁,利用并发的修改,但是对于一次性大量修改效率低下(表级锁:一次性加一把锁就锁住了整张表,不利用并发的修改,但是加锁速度比行锁的效率高)
支持外键约束:被约束表中的数据不能随意的修改,删除,约束字段要根据被约束表来使用数据
myisam:索引,数据,表结构,支持持久化存储
- 支持表级锁
memory:表结构
- 支持断电消失
表的约束
- 非空约束:not null,默认不写的时候自动插入
- unsigned :无符号的数字
- 唯一约束:unique
- 联合唯一约束:unique(需要联合的列)
- 外键约束:foreign key(字段名) references
- 级联更新:on update cascade ,相关的数据会跟随变化
- 设置默认值:default xx
- 主键:primary key
- 第一个被设置了非空+唯一约束的字段会被定义成主键 primary key
- 对某一字段 自增:auto_increment
- (truncate table 表名; 清空表且重置auto_increment),
- (delete from 表名;清空表数据但不能重置auto_increment)
- alter table 表名 auto_increment=数值
表的修改 alter table
- 修改表明:alter table 表名 rename 表名;
- 修改编码:alter table 表名 charset 编码;
- 修改自增:alter table 表名 auto_increment 自增的位置;
- 添加字段约束:alter table 表名 add 约束条件;
- 修改约束:alter table 表名 add 字段名 类型(长度) 约束;
- 修改字段名:alter table 表名 drop 字段名;
- 修改字段名以及类型和约束条件:alter table 表名 change 字段名 新名字 类型(长度)约束
- 修改表中的字段:alter table 表名 modify 字段名 新类型(新长度)约束
- 修改字段名的位置:alter table 表名 add 字段名 类型(长度) 约束 first(备注:移动到第一个)/after 字段名(备注:移动到某个字段名之后)
- 修改原字段的类型:after table 表名 change 字段名1 字段名1 类型(长度) 约束;
表与表之间的关系
一对一:
create table class(id int primary key,cname char(26)); create table student(id int primary key,sname char(16),gid int unique,foreign key(gid) references guest(id));一对多:foreign key
create table class(id int primary key,cname char(16)); create table student(id int primary key,sname char(16),cid int,foreign key(cid) references class(id));多对多:
create table class(id int primary key,cname char(16)); create table teacher(id int primary key,tname char(16)); create table teacher_cls(id int,cid int,tid int,foreign key(cid) references class(id),foreign key(tid) references teacher(id));
索引原理
磁盘预读性原理
- linux 中一个block块大小是4096个字节
树:根节点root,分支节点branch,叶子节点:leaf
- b树:balance 树
- 数据存储在分支节点和叶子节点上
- 导致了树的高度增加,找到一个数据的时间不稳定
- 在查找范围的时候不够便捷
- b+树:mysql中innodb存储引擎的所有的索引树都是b+树,是为了更好的处理范围问题在b树的基础上有所优化
- 数据不再存储在分支节点了,而是存储在叶子节点上(树的高度降低,找到所有数据的时间稳定)
- 在叶子节点与叶子节点之间添加的双向指针提高了再查找范围的效率
- b树:balance 树
索引的两种存储方式:
- 聚集(簇)索引:叶子节点会存储整行数据--innodb的主键中才会有(主键只可以创建一个的原因)
- 非聚集索引(辅助索引):除了主键之外的普通索引都是辅助索引,一个索引没办法查询到整行数据,需要回聚集索引再查一次,俗称回表,数据不直接存储在索引的叶子节点
索引优缺点:
- 优点 :加快查询速度
- 缺点:降低写的效率,占用更多的磁盘空间
索引的创建:create index 索引名 on 表名(字段名);
索引的删除:drop index 索引名 on 表名;
正确的使用索引:
- 只有对创建了索引的列进行条件筛选的时候效率才可以提高
- 索引对应的列做条件不能参与运算,不能使用函数
- 当某一列的区分度非常小(重复率高),不适合创建索引
- 当范围作为条件的时候,查询结果的范围越大越慢,越小越快。
- like关键字:如果使用%/ _ 开头都无法命中索引
- 多个条件:如果只有一部分创建了索引,条件用and相连,那么可以提高查询效率,如果用or相连,不能提高效率
- 联合索引:
- 条件不能用or
- 要服从最左前缀原则
- 不能从使用了范围的条件开始之后的索引都失效
基础概念:
explain :执行计划
- explain
覆盖索引 using index:在查询的过程中不需要回表
以上是关于MySQL入门指南4(查询进阶,外连接)的主要内容,如果未能解决你的问题,请参考以下文章