由浅入深的理解Lua的数据结构——table
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了由浅入深的理解Lua的数据结构——table相关的知识,希望对你有一定的参考价值。
参考技术A 思考一下:如果现在定义了一个table a,将table a赋值给table b,此时它们的内存情况是什么样呢?
ab都会指向同一个内存块,如果a设置为nil,b依旧能访问该内存块的元素,直到b设置为nil后,Lua的垃圾回收机制会清理相应的内存。所以当b在更改table内的值后,a再去访问的时候,值也是改变的。
table的for循环写法
先解释一下上面的各个变量
在table中,我们无法对两个table之间进行操作,比如:table a+ table b。为了解决这个问题,就引入了元表的概念,它允许我们 改变table的行为 。
当我们在进行表a+b的时候:
其实逼逼了这么多,我觉得元表和元方法其实就相当于 重载 ,比如_add,我们就是重载了+操作符
也可以将它理解成 事件驱动 ,元表中的键对应着不同的事件名,关联的值是元方法,元方法里就是我们事件对应的操作。
继续接上面的分析
每个Node都是一个键值对 ,里面包含了key和value。tvk是key的值,但是当我们出现hash冲突,此时lua的hash算法比较特殊,一般情况下,我们的hash算法都是根据key算出hash,然后如果有冲突的话,就放在改位置的链表上。而lua不同, 当它出现hash冲突的时候,会在hash表中找到一个空的位置x,来存放key,并且让冲突处的节点的nk.next指向x 。
这意味着什么呢?发生冲突我们无需重新分配空间来存储冲突的key,而是利用hash表上未用过的空白处来存储。刚才我们将key放在了空位置x, 如果此时存在另一个key2,它算出的hash值是空位置x,而我们刚才的key只是因为hash冲突了,占用了其他key的位置,这个时候我们就讲key2放在x上,将key再放到另一个空白处 。
忍不住想总结一波table的实现,和上面我们的Node类型进行对照
lua的table其实由 数组段 和 hash 两部分组成,当你的key值不会过于离散的时候,lua就会将它存储在数组段(也就是下图的array),反正会存储在hash段(也就是下图的node),这个分割线是以数组段的利用率不低于50%为准。hash段采用闭散列的算法,它将有冲突的key存储在空闲槽中,而不额外分配内存。
在我们table结构体中,array和sizearray都是表示数组段。
而lsizenode和node,lastfree是表示hash段。node指向hash表的起始位置,lsizenode是log2(node指向的哈希表的节点数目), lastfree指向node里面最后一个未使用的节点 (因为我们在hash冲突的时候,是从后往前查找未使用的节点,lastfree存储最后一个未使用节点就可以方便查找)
如果此时hash表中已经没有空格了,那么lua就会resize这个hash表(等会再谈lua的动态扩增)
lua创建新表的时候 先为新表分配内存 Table * t = luaM_new(L, Table),然后将表 连接到gc 上并设置标志位luaC_link(L, obj2gco(t), LUA_TTABLE),然后 初始化 一些必要的属性,使用setarrayvector为数组段分配内存,setnodevector为hash部分分配内存,最后返回表指针。
table的查找会根据key进行判断,如果key为空就直接返回空,key为字符串就调用luaH_getstr(t, rawtsvalue(key)),key为数字则根据它是否整数调用luaH_getnum(t, k),否则,计算出key的位置,遍历table的node节点,找到对应键所在的节点返回。
因为key为数字比较特殊,所以研究一把luaH_getnum函数的实现
如果key大于等于1,小于数组的长度,则从数组中取出对应的键值,否则利用hashnum找到key对应的node位置,遍历node链表,返回对应的值
dummynode是带头结点的指针。
往table中插入新值,先检测 key的主位置 (main position)是否为空,主位置就是key的哈希值在node中的位置。
如果主位置为空,就直接插入,主位置不为空,检查占领该位置的key的主位置是不是在这个地方,如果不在,则将该key移动到其他空闲位置,将要插入的key插入到这个位置中。如果在这个地方,则将要插入的key插入到一个 空槽 中。
如果找不到空闲位置放新键值,就 rehash函数 ,扩增hash表的大小,再找出新位置,再调用luaH_set把要插入的key插入到新的哈希表中,直接返回LuaH_set的结果。
如何深入理解Lua数据结构和内存占用?
导语 Lua底层数据结构的内存动态分配,一般情况下不太好估算内存占用。腾讯游戏学院专家Ross在本文剖析lua常见数据结构string和table的底层实现原理,并从中找到一般性的内存占用估算方法。
由于lua是一个跨平台的脚本语言,会根据平台位数(16bitbit)、平台类型(linuxwindows)、语言标准(C89C99)、以及编译参数等开启预编译选项,导致基本数据结构的字长和类型会动态变化,以Tlinux2.2 x86_64 进行编译为基础进行分析介绍, lua版本5.3.4。并根据我们开发过程中一些常见的情景进行分析:

基础数据结构
Lua的基本数据表示方式是type + union的方式,根据不同类型映射到union的不同结构上面, 统一的表示结构lua_TValue:
typedef union Value {GCObject *gc; /* collectable objects */void *p; /* light userdata */int b; /* booleans */lua_CFunction f; /* light C functions */lua_Integer i; /* integer numbers */lua_Number n; /* float numbers */} Value;struct lua_TValue {Value value_;int tt_;} TValue;
但由于lua_Integer和lua_Number在当前平台预处理后,分别定义成long long 和 double类型,所以为方便理解,上述结构经过转义:
typedef union Value {GCObject *gc; /* collectable objects */void *p; /* light userdata */int b; /* booleans */lua_CFunction f; /* light C functions */long long i; /* integer numbers */double n; /* float numbers */} Value;struct lua_TValue {Value value_;int tt_;} TValue;
在lua5.1版本中,统一使用lua_Number来表示整数和浮点数,而double能够表示的整数大小有限,大概2^52的长度,所以用lua_Number表示一些类型为int64_t的全局唯一id长度不够,类似物品id、角色id。在lua5.3中,上述问题不再存在。
lua简单数据类型bool、整型、浮点型都是统一用lua_TValue来表示,消耗内存为sizeof(lua_TValue) = 16字节。因此相对CC++表示整型的charshortintint64_t来说,这种数据结构的表示法虽然比较统一,但比较消耗内存。还有一些复杂的数据结构,统一封装在GCObject中。由于5.1和5.3表示法略有差异,5.1方便理解,如下:
union GCObject {GCheader gch;union TString ts;union Udata u;union Closure cl;struct Table h;struct Proto p;struct UpVal uv;struct lua_State th; /* thread */};


数据结构的内存占用
在开发过程中,最常用的数据结构是sting和table类型,那么现在主要分析这两种数据结构的内存占用。
2.1 string 类型
String又细分为短字符串LUA_TSHRSTR和长字符串LUA_TLNGSTR两种,默认长度小于40的为LUA_TSHRSTR,使用全局stringtable进行管理。即所有短字符串都在stringtable中存放,相同字符串只会有一份实际数据拷贝,每份相同的TString对象只是存放一个hash值,用来索引stringtable。而长字符串则跟普通的GCObject没有差别,相同字符串在内存都是单独一份数据拷贝。在Lua5.1中,没有区分长短字符串,所有的字符串统一在stringtable中存在唯一拷贝。猜想这种改变一是因为长字符串出现相同的情况比较少,二是lua5.1的方式长字符串TString计算Hash是抽取部分字符进行运算,这样的计算方式可能被伪造导致不同字符串的hash值一样,但要是所有字符全用来计算hash又比较耗时。
下面是一个string类型的GCObject的内存表示,根据长短字符串表示方式不一样:
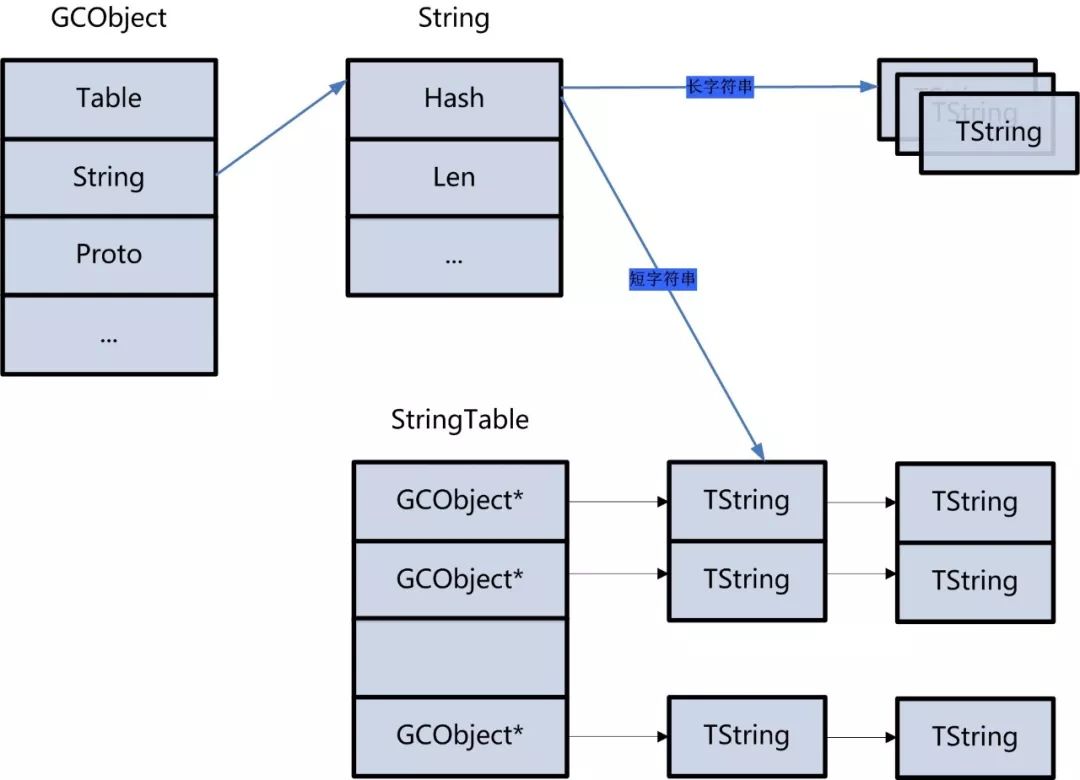
Ø 内存占用分析实践
下面分别对比四种情景来分析内存占用的不同。因为lua在使用 .. 连接字符串时,底层会调用luaV_concat -> luaS_newStr新建字符串,这里对比下在创建短字符串和长字符串后的内存消耗:
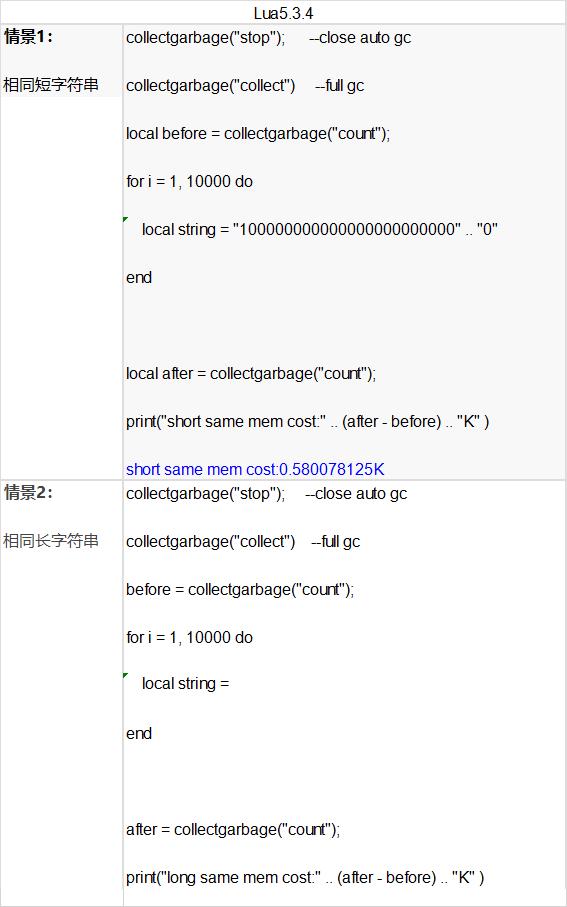
通过对比:在创建相同字符串时,因为短字符串在StringTable只有一份拷贝,而长字符串每次都会产生新的数据拷贝,所以消耗内存差异明显。 0.58K VS 771.48K
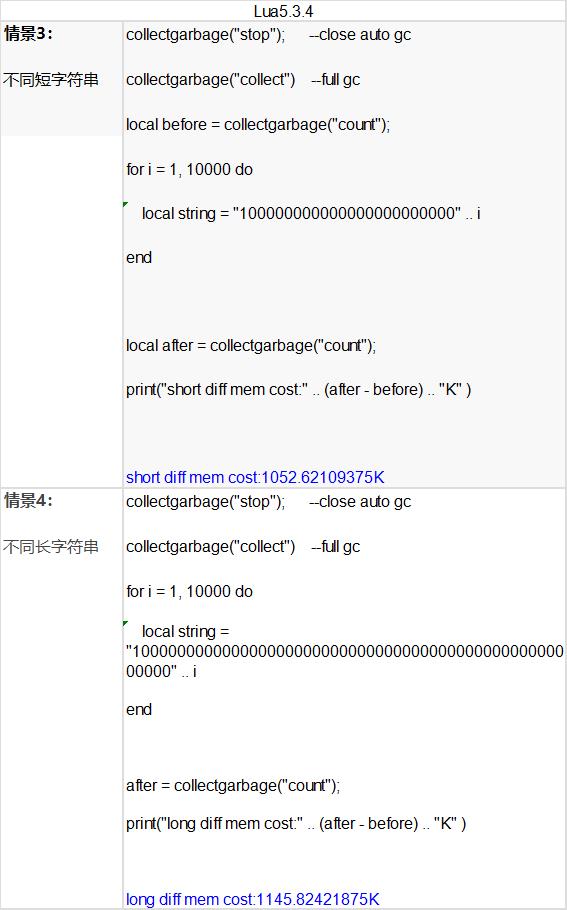
通过对比:在创建不同字符串时,不论长短字符串,都会有一份不同字符串的拷贝,所以都需要消耗大量内存。1052K VS 1145K
问题一:在对比情景2和情景4时,长字符串都是一份拷贝,为什么内存消耗差异较大?(791K vs 1145K)
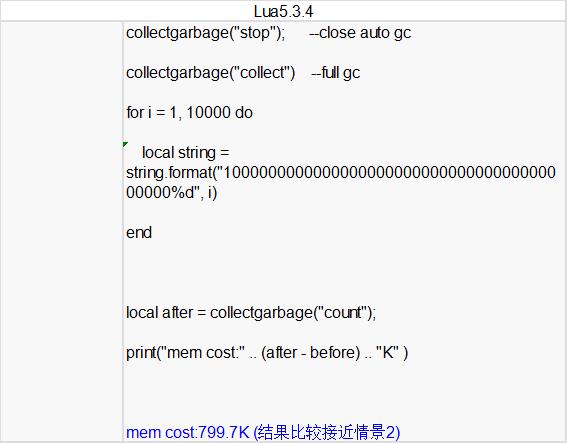
答:这是因为使用连字符 .. 时,情景4里面的变量i转为字符串,相当于生成了10000份不同的短字符串拷贝,导致多消耗了300K左右内存,所以在开发中可以适当避免 .. 产生大量字符串的产生。可以考虑使用string.format来格式化字符串。具体效果如下:
Ø 预估字符串消耗
问题二:以情景2为例,最终内存消耗771.48K,这个可以在开发前估算吗?
答:string实际是GCObject对象,所以有些公共的字段。以”Lua”这个字符串为例,TString的内存结构:
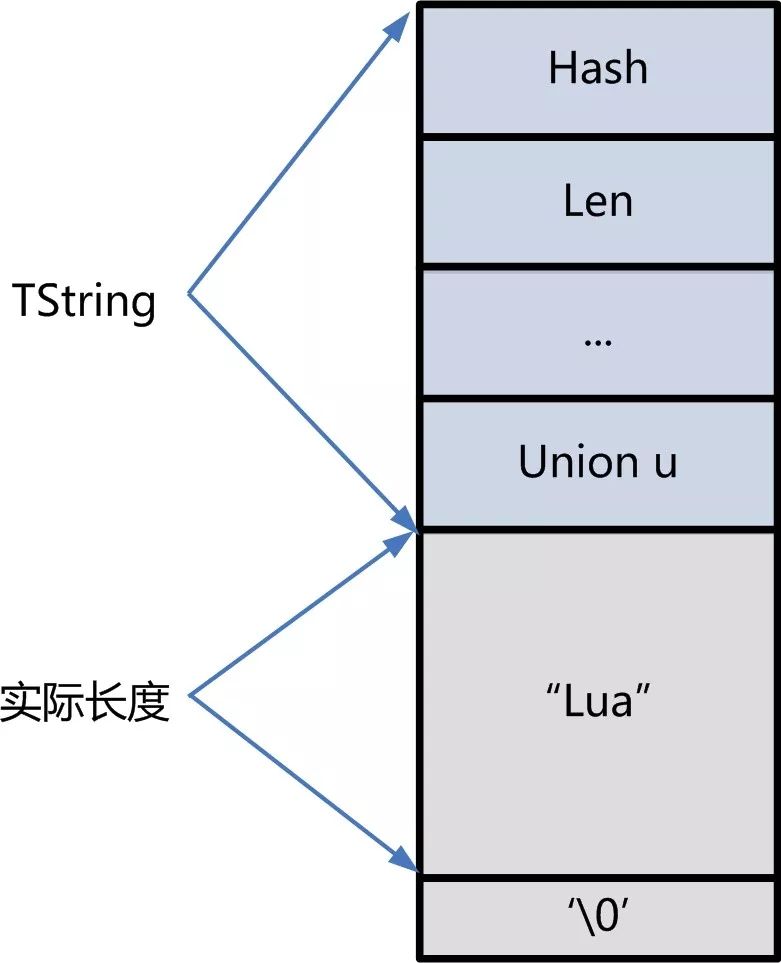
在情景2中,实际字符串长度为54。那么内存占用 = sizeof(TString) + 1 + 实际长度 = 25 + 实际长度 = 25 + 54 = 79。理论内存:10000 * 79/ 1024 = 771.48K, 理论跟实际消耗值几乎一致。
Ø 与lua5.1.4的对比
但由于我们之前也用过lua5.1.4,这个版本所有字符串均引用StringTable一份数据拷贝,理论上不论长短字符串,只要相同的数据只会有一份拷贝。(由于lua5.1.4版本在调用collectgarbage("collect")进行一次完整gc后,luaC_fullgc会调用setthreshold打开自动gc,这里容易踩坑,上述代码运行发现内存消耗明显低于lua5.3版本,非常困惑。所以修改代码在collectgarbage("collect")后,重新调用collectgarbage("stop")关闭自动gc)。修改后在lua5.1.4下面执行对比如下:
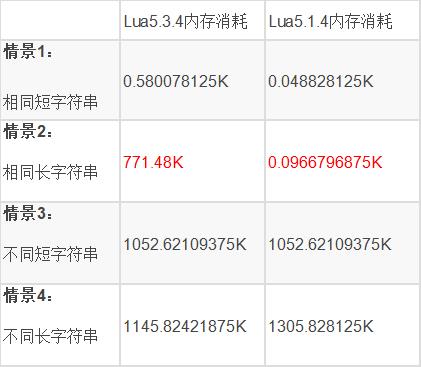
最大差别在于相同长字符串创建的内存消耗,Lua5.1.4由于统一用stringtable保存一份拷贝,所以内存消耗可以忽略不记,但Lua5.3.4由于会产生不同副本拷贝,消耗明显。
Ø table重复字符串key对内存影响?
对于短字符串,只会在stringtable中存在一份拷贝,对内存没有什么影响。对于长字符串,需要分两种场合看:
for i =1, 1000 doTab[i] = {ccccccccccccccccccccccccccccccccccccccc=i}end--或者Tab[1] = {ccccccccccccccccccccccccccccccccccccccc=1}Tab[2] = {ccccccccccccccccccccccccccccccccccccccc=2}Tab[3] = {ccccccccccccccccccccccccccccccccccccccc=3}...Tab[100] = {ccccccccccccccccccccccccccccccccccccccc=100}
对于这两种情况,由于lua程序进行代码文件词法分析时,第一种调用一次luaS_newlstr创建”ccccccccccccccccccccccccccccccccccccccc”, 而第二种会调用100次。正如我们前面的分析,长字符串每次调用都会生成一份新的拷贝,所以第二种情况会有N份的字符串内存消耗。
我们服务器的表资源,转表后都是按第二种形态存在,所以一定要切记key的字符串长度不要超过40,否则产生无谓的内存浪费和大量的GC对象,影响GC效率。
2.2 table类型
在开发过程中,table是最常见的数据结构,每条记录对外都是key-value的方式来读写。他的底层是用array + hashtable的方式管理数据的,但对外是透明的。不论array还是hashtable都是连续的内存分布。在查找时:
1. 如果key是整型, 并且 key > 1 and key < max_array_size, 直接取array[key]数据。
2. 其他情况,默认读取hashtable。Hashtable的管理方有些特别,当不同key hash到同一个node时,用链表来维护这些冲突节点。与stringtable 链表节点动态分配的方法不同,HashTable使用空闲链表来维护冲突节点。
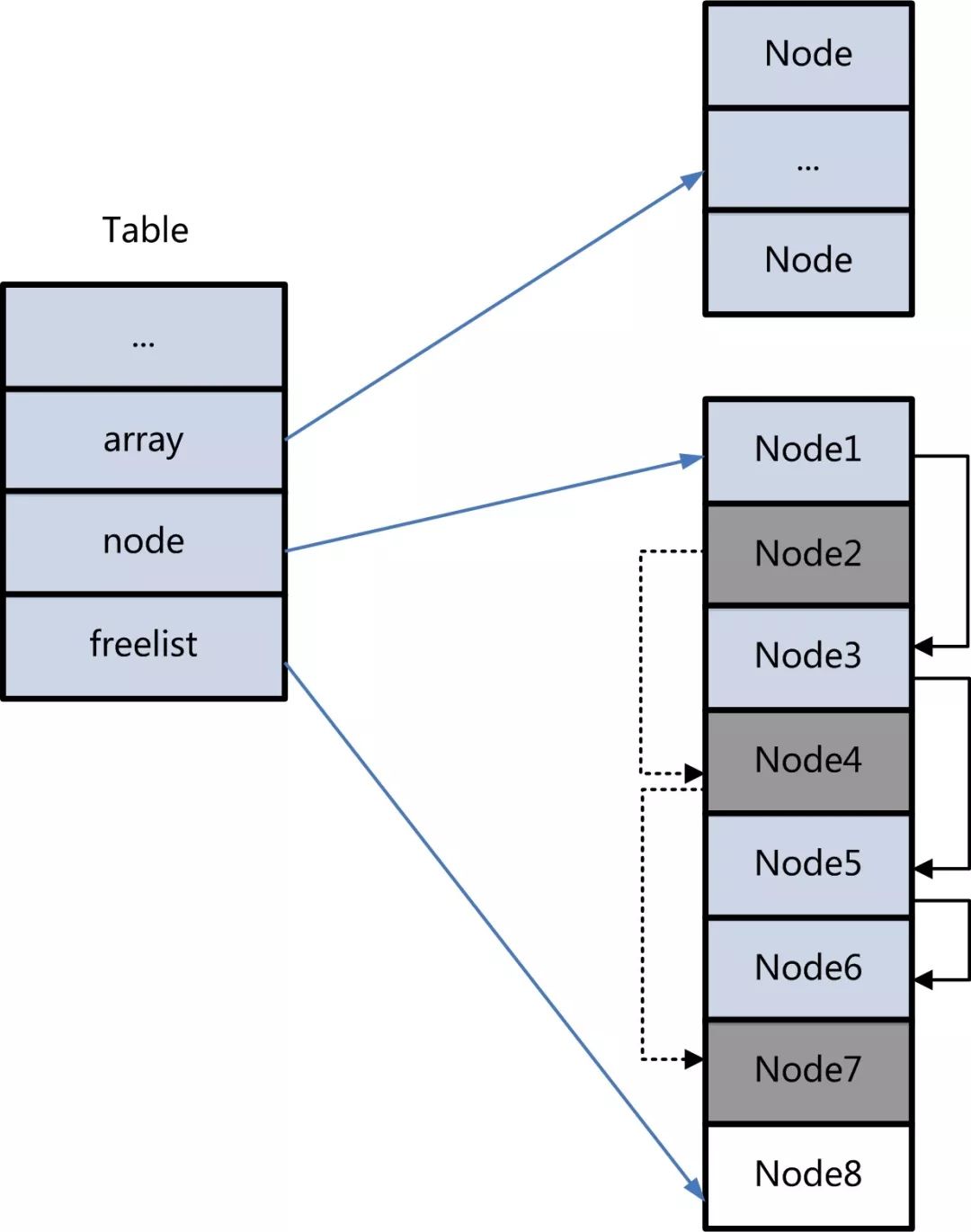
Ø Array or HashTable?
首先说一种典型的情况,调用table.insert 或者table[#table + 1] 按序插入列表的,就是存放在array里面。
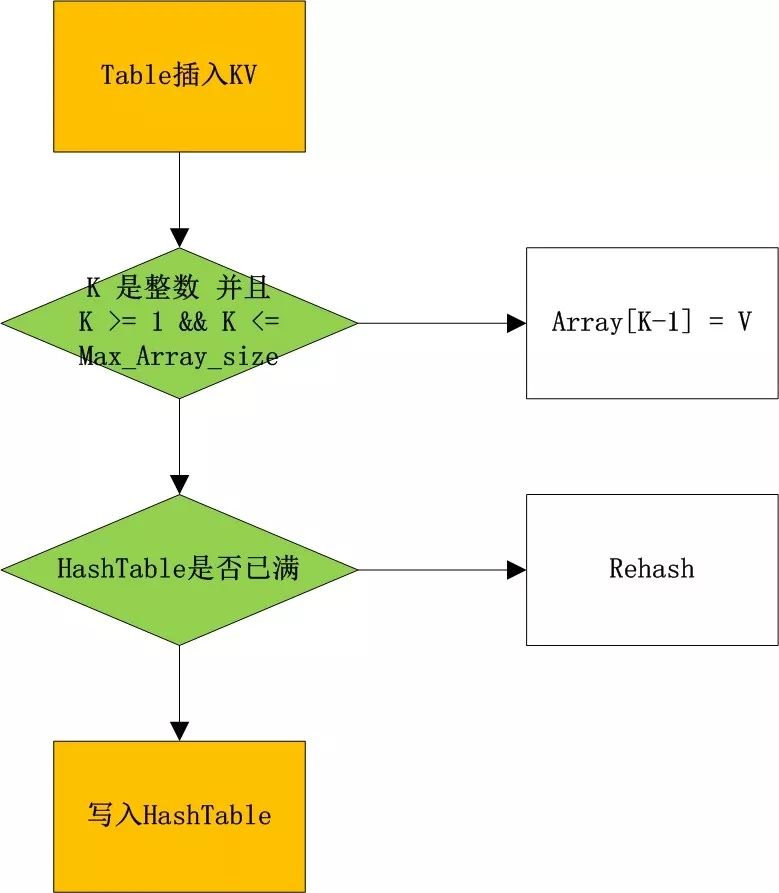
Ø rehash动态扩容原理
在插入新节点时,如果通过freelist找不到可用节点就触发rehash。在新创建table时,node节点数量为0,当插入第1条数据时触发内存分配2^0=1个内存节点。当插入第2条记录时,因为节点都已经使用,所以又触发rehash,分配2^1=2个内存节点。依次类推,在插入第3、5、9时,触发分配一个更大的内存,可以简单理解成重新分配一块oldsize * 2 的内存,把原有的hashTable的数据重新hash插入到新的内存中,再释放掉原有的内存。综上,每次内存的增长都是按2的指数倍来增长。
1)Rehash导致的cpu消耗
使用2的指数倍扩容,针对单个表扩容其实并不频繁,比如100W个节点,最多扩容20次,2^20 > 100W。只是在表的前期会相对频繁,1、2、3、5、9条记录插入会触发扩容,所以要避免小表的频繁创建插入。
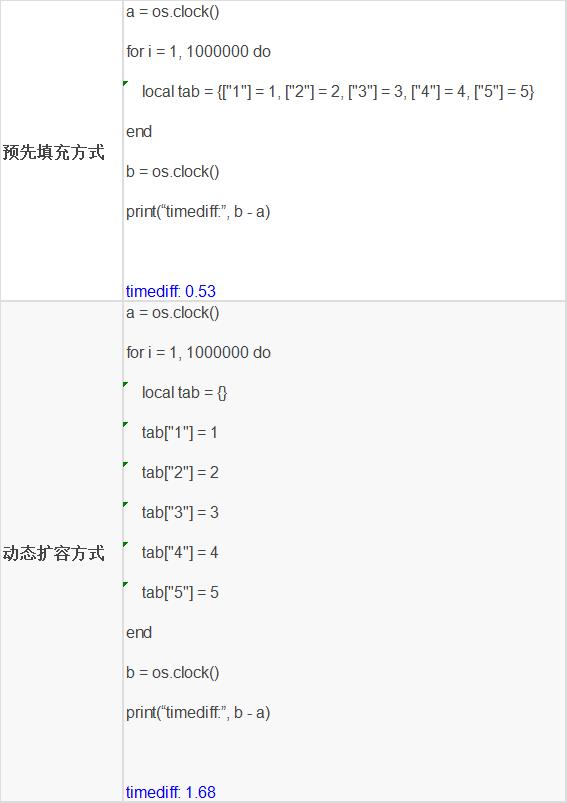
分析:可以看到预填充方式可以避免频繁的表扩容,cpu消耗是动态扩容的1/3。使用预填充的方式,在创建tab时,会直接分配一个8个元素的Node节点的内存,存放数据。而采用动态扩容的方式,第一次分配1个元素,然后随着数据的插入,会扩容到2个元素的内存,把原来数据重新hash到新分配的内存,释放老内存。同理,随着数据的插入,继而扩容到4个元素、扩容到8个元素...
2)rehash导致内存消耗演示
tab = {}text = "diff mem"collectgarbage("stop")before = collectgarbage("count");for i = 1, 100 dotab[10000 + i] = ilocal cur = collectgarbage("count")print(text, cur - before)before = cur ;end
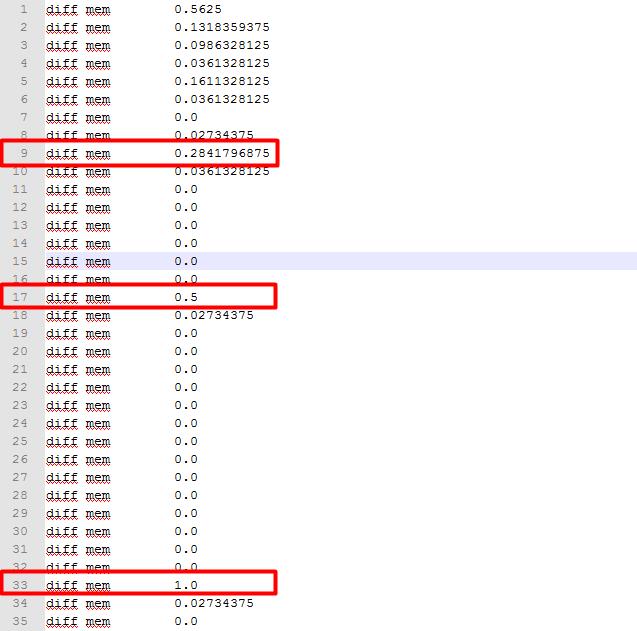
因为hashtable数据分配是0、1、2、4、8、16、32这些内存大小,所以在插入数据时分别在1、2、3、5、9、17、33时内存不够触发扩容,如上红色标记的点。可以看到在红色标记的点上,内存会有大幅扩大,而且基本是上一次大幅扩容的2倍关系。
问题一:在上述截图中,为什么在10、18、34这些地方出现了额外的内存消耗?
以10节点来说明,这是因为在插入第9条数据后,print打印,系统创建了一个”0.2841796875”字符串,导致节点10在统计消耗的时候计算进去了,具体消耗长度为 25 + 实际长度= 25 + 12 = 37字节,与节点10的消耗吻合。同理节点18的消耗为25 + len(“0.5”) = 28
问题二:因为节点10、18、34本身也print打印了字符串,怎么它后面的11、19、35就没有消耗内存?
以11为例,理论上节点10打印的”0.0361328125”会消耗内存,但这个字符串在节点6已经创建过了,由于所有短字符串都在stringtable进行管理,只有一份拷贝,所以不再消耗内存。
问题三:为什第一个节点内存消耗明显偏高?
这是因为for循环里面local cur = collectgarbage("count")调用,触发了Lua_state->stack指向的内存空间的动态扩容,原理有点类似HashTable内存不够的再分配机制。
综上三个问题,可以把代码调整一下再看:
tab = {}text = "diff mem"collectgarbage("stop")before = collectgarbage("count");for i = 1, 100 doif i == 1 then before = collectgarbage("count"); endtab[10000 + i] = ilocal cur = collectgarbage("count")print(text, cur - before)before = collectgarbage("count");end
可以看到,在1、2、3、5、9、17等位置触发内存再分配,对应重新分配的内存是2^0=1、2^1=2、2^2=4、8、16、32大小。NewSize-OldSize差值即新增内存,分别为1-0=1、2-1=1、4-2=2、8-4=4、16-8=8、32-16=16,而单个节点大小为0.03125K,整体每次新增内存与上面截图完全吻合。
Ø 估算table的内存消耗
创建一个最简单的表{}, lua在调用luaH_new初始化时并不会动态分配array和hashtable指向的内存,只是创建一个最简单的table管理结构,所以消耗的内存为sizeof(Table) = 56。
1)估算table中hashtable的内存消耗
每个Node节点消耗sizeof(Node) = 32。所以对于简单数据(整型、浮点、bool)相对比较好估算,sizeof(Table) + sizeof(Node) * NodeNum。 例如上面的代码,100条记录实际分配的Node节点2^7=128,就是56 + 32 * 128 = 4152
collectgarbage("stop");before = collectgarbage("count");tab = {}for i = 1, 128 dotab[10000+i] = iendafter = collectgarbage("count");print("total mem:", (after - before)*1024)total mem: 4152.0
2)估算table中有序数组的内存消耗
对于简单表tab = {}, 一般都是使用tab[#tab + 1] = xxxx 或者 table.insert(tab, xxx) 来插入数据,对于这种典型的场景,table使用的是array的方式存储数据。计算方式,sizeof(Table) + sizeof(TValue) * ArrayNum,其中sizeof(TValue) = 16。同样下面的代码,略作调整,100条记录实际的分配的Array节点也是128, 就是56 + 16 * 128 = 2104.
collectgarbage("stop");before = collectgarbage("count");tab = {}for i = 1, 128 dotab[#tab + 1] = iendafter = collectgarbage("count");print("total mem:", (after - before)*1024)total mem: 2104.0
3)估算table嵌套类型的消耗
上面都是用的简单数据类型进行估算,现在考虑下当value是GCObject对象的情况(字符串、表、闭包)。针对一个Node节点,数据组成:
struct Node {TValue i_val;TKey i_key;Node;
因此,对于简单的数据类型,TValue里面的结构字段足以存储,但对于复杂类型,TValue里面只是存了一个对象指针GCObject*,而对象本身的内存大小还得单独核算。先看一个简单:
collectgarbage("stop");before = collectgarbage("count");tab = {}tab[10000] = {i}after = collectgarbage("count");print("total mem:", (after - before)*1024)total mem: 160.0
A、tab表 sizeof(Table) + sizeof(Node) * 1 = 88
B、{i}使用array来存储,实际消耗 sizeof(Table) + sizeof(TValue) * 1 = 72
C、所以整体消耗: 88 + 72 = 160
4)估算复杂table的数据内存消耗以及与C语言的对比
以一个简单的排行榜列表来进行多维度计算,预计10000条数据,以玩家uid作为key,每条记录存积分和名次。分多个场景进行评估。
场景一:
collectgarbage("stop");before = collectgarbage("count");tab = {}for i = 1, 10000 dotab[100000+i] = {score = 100000+i, rank = i}endafter = collectgarbage("count");print("total mem:", (after - before)*1024)total mem: 1724344.0
A,首先涉及两个字符串”score” “rank” 的消耗。分别是25 + 5 = 30, 25 + 4 = 29 。
B,每个小表{score = 100000+i, rank = i}, sizeof(Table) + sizeof(Node) * 2 = 120。
C, 大表有1W条记录,2^14 = 16384 > 10000。sizeof(Table) + sizeof(Node) * 16384 = 524344
D,最终内存占用:30 + 29 + 120 * 10000 + 524344 = 1724403
理论计算出来的内存占用比实际消耗多了1724403-1724344 = 59字节,似乎两个字符串的消耗没有计算进来。那么这两个字符串”score” ”rank” 是否真正存在于stringTable了? 答案是yes。只是在更早阶段,lua程序对代码文件进行词法分析,生成指令码的过程中,就已经调用luaS_newlstr创建了”score”和”rank”字符串了,因此不在上述代码的统计范围内,有兴趣的可以调试lua程序验证。
场景二:
去掉每条子表记录里面的key,直接按有序列表存储。
collectgarbage("stop");before = collectgarbage("count");tab = {}for i = 1, 10000 dotab[100000+i] = {100000+i, i}endafter = collectgarbage("count");print("total mem:", (after - before)*1024)total mem: 1404344.0
A,每个小表{100000+i, i}, sizeof(Table) + sizeof(TValue) * 2 = 88。
B, 大表有1W条记录,2^14 = 16384 > 10000。sizeof(Table) + sizeof(Node) * 16384 = 524344
C,最终内存占用:88* 10000 + 524344 = 1404344
场景三:
如果列表只有2个变量,可以把两个数值合并,减少一层表的分配,那么就会减少场景二A子表的内存消耗。
collectgarbage("stop");before = collectgarbage("count");tab = {}for i = 1, 10000 dotab[100000+i] = (100000 + i) << 14 + iendafter = collectgarbage("count");print("total mem:", (after - before)*1024)total mem: 524344.0
由于value只是普通的数值,那么Node节点的TValue足够存储,不在单独分配额外内存,所以内存大小:sizeof(Table) + sizeof(Node) * 16384 = 524344
场景四:
如果还要继续压缩内存使用,可以考虑不要存1W条记录,存8192条记录如果也满足要求的话,这样可以减少一次hashtable的预分配。
collectgarbage("stop");before = collectgarbage("count");tab = {}for i = 1, 8192 dotab[100000+i] = (100000 + i) << 14 + iendafter = collectgarbage("count");print("total mem:", (after - before)*1024)total mem: 262200.0
A、大表的hashtable记录数2^13 = 8192, 那么刚好把节点使用完,没有浪费。
B、总体内存:sizeof(Table) + sizeof(Node) * 8192= 262200
所以,如果对lua table的动态内存管理比较清楚,可以在满足需求的情况进行一些优化,能够大幅压缩内存的占用,如上可以看到内存从最早的1724344 优化到262200, 大概只有原来内存占用的1/7。当然了,也不能只考虑内存的占用,也要结合扩展性综合考虑,比如场景四里面由于少了一层表,会导致单条记录没法扩展字段。因此,不论是节省内存还是兼顾扩展性,是综合评估的结果,只有各方面利弊能够准确评估,才能做很好的tradeofff。
场景五:
对比C/C++的实现
struct rankitem{Uint64_t uid;Int score;Short rank_no;};struct ranklist{short num;struct rankitem list[8192];};
在C/C++里面内存比较方便计算:sizeof(struct ranklist) = 114690。可以看到,即使lua的table做了较好的优化,内存优化到早期的1/7, 实际的消耗还是C/C++的2倍。如果记录再增加1条,这个倍数立刻扩大到C/C++内存占用的4倍。所以可以大概认为lua table的一般是C/C++的2 ~ 28(4 * 7) 的范围,当然随着记录条数、table层次不同,这个范围浮动较大,简单可以取个中值算平均数。
正如我们前面分析,lua的table占用内存明显高于C/C++,主要有以下几个因为:
1、lua table支持动态插入,所以为了性能必须要预分配更大内存,减少因为每次的插入而导致重新分配。这样极端情况就会多耗掉一倍的内存。
2、lua table的节点使用的是Node,为了追求通用性,对应kv字段基本都是TValue类型,而这个类型占用16字节,kv消耗加起来就是32,明显高于C/C++里面简单字段类型的消耗。当然lua table引入array可以不需要key字段,内存接近省一半。
3、Lua table本身的管理数据有固定56字节,如果是一个很大的表,这个占用比率并不明显。但如果是很多个小表,例如情景1里面的,占用比例就会很大。
4、在实际开发过程中,一般都会表嵌套表,很多层,由于每层都有内存冗余和浪费,这样嵌套下来消耗就会叠加的更明显。
Ø rehash数据重新分布
上面只是描述节点不够用时触发内存扩容,数据重新进行hash分布。但如果既有Array数据,又有HashTable数据时,会怎么进行rehash呢?
系统会把所有的key为整数的节点进行统计(包含在array和HashTable的),同时数组最大内存Max_Aarry_Size按2的指数倍增长,然后计算满足条件Key <=Max_Aarry_Size的整数节点数量,当数量 > Max_Aarry_Size/2 就认为array内存能充分利用,使用率超过50%,直到系统找到一个最大的符合条件的Max_Aarry_Size为止。剩下的节点数量进入HashTable,HashTable也是按2的指数倍增长,直到能够装下剩余节点数为止。
因此,通过这个也验证上面的例子中,for i=1, 10000 do tab[10000+i] = 10000+i end为什么使用的HashTable存储的原因了。当Max_Aarry_Size = 2^13=8196时,没有Key落在这个[1, 8196]区间。当Max_Aarry_Size= 2^14=16392时,只有6392条数据落入区间[1, 16392], 区间利用率小于50%。当Max_Aarry_Size= 2^15=32784时,只有10000落入区间[1, 32784], 也不满足利用率的要求。
关于腾讯游戏学院专家团
如果你的游戏也富有想法充满创意,如果你的团队现在也遇到了一些开发瓶颈,那么欢迎你来联系我们。腾讯游戏学院聚集了腾讯及行业内策划、美术、程序等领域的游戏专家,我们将为全世界的创意游戏团队提供专业的技术指导和游戏调优建议,解决团队在开发过程中遇到的一系列问题。
项目指导合作请联系微信:18698874612
·END·
以上是关于由浅入深的理解Lua的数据结构——table的主要内容,如果未能解决你的问题,请参考以下文章