由浅入深理解Raft协议
Posted MySQL代码研究
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了由浅入深理解Raft协议相关的知识,希望对你有一定的参考价值。
0 - Raft协议和Paxos的因缘
读过Raft论文《In Search of an Understandable Consensus Algorithm》的同学都知道,Raft是因为Paxos而产生的。Paxos协议是出了名的难懂,而且不够详细,紧紧依据Paxos这篇论文开发出可用的系统是非常困难的。Raft的作者也说是被Paxos苦虐了无数个回合后,才设计出了Raft协议。作者的目标是设计一个足够详细并且简单易懂的“Paxos协议”,让开发人员可以在很短的时间内开发出一个可用的系统。
Raft协议在功能上是完全等同于(Multi)-Paxos协议的。Raft也是一个原子广播协议(原子广播协议参见《),它在分布式系统中的功能以及使用方法和Paxos是完全一样的。我们可以用Raft来替代分布式系统中的Paxos协议如下图所示:
1 - Raft的设计理念
严格来说Raft并不属于Paxos的一个变种。Raft协议并不是对Paxos的改进,也没有使用Paxos的基础协议(The Basic Protocol)。Raft协议在设计理念上和Paxos协议是完全相反的。正是由于这个完全不同的理念,使得Raft协议变得简单起来。
Paxos协议中有一个基本的假设前提:可能会同时有多个Leader存在。这里把Paxos协议执行的过程分为以下两个部分:
Leader选举
数据广播
在《》的“Leader的选取”一节中提到过,Paxos协议并没有给出详细的Leader选举机制。Paxos对于Leader的选举没有限制,用户可以自己定义。这是因为Paxos协议设计了一个巧妙的数据广播过程,即Paxos的基本通讯协议(The Basic Protocol)。它有很强的数据一致性保障,即使在多个Leader同时出现时也能够保证广播数据的一致性。
而Raft协议走了完全相反的一个思路:保证不会同时有多个Leader存在。因此Raft协议对Leader的选举做了详细的设计,从而保证不会有多个Leader同时存在。相反,数据广播的过程则变的简单易于理解了。
2 - Raft的日志广播过程
为了保证数据被复制到多数的节点上,Raft的广播过程尽管简单仍然要使用多数派协议,只是这个过程要容易理解的多:
发送日志到所有Followers(Raft中将非Leader节点称为Follower)。
Followers收到日志后,应答收到日志。
当半数以上的Followers应答后,Leader通知Followers日志广播成功。
- 日志和日志队列
Raft将用户数据称作日志(Log),存储在一个日志队列里。每个节点上都有一份。队列里的每个日志都一个序号,这个序号是连续递增的不能有缺。
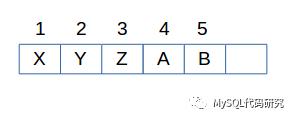
日志队列里有一个重要的位置叫做提交日志的位置(Commit Index)。将日志队列里的日志分为了两个部分:
已提交日志:已经复制到超过半数节点的数据。这些日志是可以发送给应用程序去执行的日志。
未提交日志:还未复制到超过半数节点的数据。
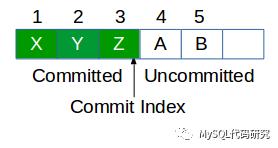
当Followers收到日志后,将日志按顺序存储到队列里。但这时Commit Index不会更新,因此这些日志是未提交的日志,不能发送给应用去执行。当Leader收到超过半数的Followers的应答后,会更新自己的Commit Index,并将Commit Index广播到Followers上。这时Followers更新Commit Index,未提交的日志就变成了已提交的日志,可以发送给应用程序去执行了。
从上面的解释我们可以知道,日志队列中已经提交的日志是不可改变的,而未提交的日志则可以被更新成其他的日志(在Leader发生变化时会发生)。
Raft的日志队列和《》中的“预存储队列+存储队列”功能是一样的,但是巧妙的合并到了一起。这样做解决的问题和《》中“预存储队列+存储队列”解决的问题也是一样的,这里就不再叙述。
3 - Raft的Leader选举
Raft称它的Leader为“Strong Leader”。Strong Leader 有以下特点:
同一时间只有一个Leader
只能从Leader向Followers发送数据,反之不行。
下面我们看一下Raft通过哪些机制来实现Strong Leader。
- 多数派协议
为了保证只有一个Leader被选举出来,选举的过程使用了多数派协议。这样很好理解,当一个Candidate(申请成为Leader的节点)请求成为Leader时,只有半数以上的Followers同意后,才能成为Leader。投票过程如下:
当发现Leader无响应后(一段时间内没有日志或心跳),Candidate发送投票请求。
Followers投票。
如果超过半数的Followers投了票,则Candidate自动变成Leader,开始广播日志。
- 随机超时机制
和《》中提到问题一样,这里也会发生多个Candidate同时发送投票请求,而导致谁都不能够得到多数赞成票的情况,有可能永远也选不出Leader。为了保证Leader选举的效率,Raft在投票选举中使用了随机超时的机制:
在每个Followers上设定的Leader超时时间是在一个范围内随机的。这样可以尽量让Followers不在同一时间发起Leader选举。
每个Candidate发起投票后,如果在一段时间内没有任何Candidate称为Leader则,需要重新发起Leader选举。这段等待的时间,在每个Candidate上也是随机的。从而保证不会有多个Candidate同时重新发起Leader选举。
虽说是随机的超时时间,但是也有个范围,太小或者太大都会影响系统的可用性。太小会导致过多的选举冲突,太大又会影响系统的平滑运行。在Raft的论文中,作者将这个超时时间称为electionTimeout,并给出了合理的范围,公式如下:
broadcastTime ≪ electionTimeout ≪ MTBF
“≪”代表数量级上的差异(10倍以上)。
- Candidate的日志长度要等于或者超过半数节点才能选为Leader
当Leader故障时,Followers上日志的状态很可能是不一致的。有的多有的少,而且Commit Index也不尽相同。
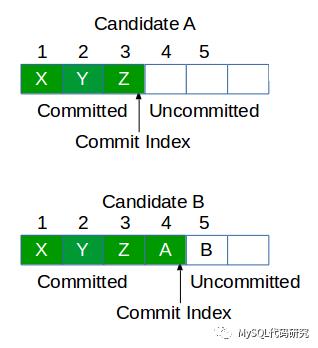
我们知道已经提交的日志是不能够丢弃的,必须要最终复制到所有的节点上才行。假如在选Leader时,图中Candidate A变成了Leader,就必须要首先从Candidate B上将日志4复制过来,然后才能开始处理新的日志。为了减少复杂性,raft就规定,只有包含了所有已提交日志的Candidate才能当选为Leader。
实现也很简单:
当发现Leader无响应后(一段时间内没有数据或心跳),Candidate发送投票请求,请求中包含自己日志队列的长度(或者说最大日志的Index)。
Followers检查Candidate的日志长度,只有Candidate的日志等于或者长于自己才投票。
如果超过半数的Followers投了票,则Candidate自动变成Leader,开始广播数据。
因为已经提交的日志一定被复制到了多数节点上,所以日志长度等于或者长于多数节点的Candidate一定包含了所有已经提交的日志。
为什么不是检查Commit Index?
因为Leader故障时,很有可能只有Leader的Commit Index是最大的。
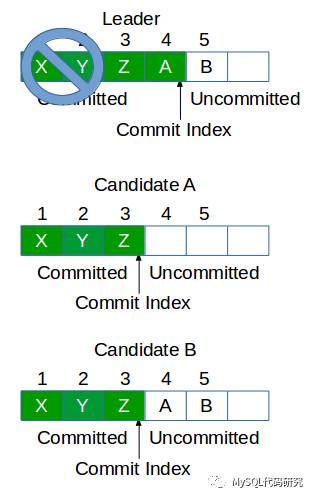
如果图中的Candidate A被选举为Leader,那么日志4就会被丢弃。但是日志4已经在原来的Leader上提交了,因此必须被保留才行。所以只能让日志长度更长的Candidate B选为Leader。这种做法有可能把原来Leader没广播完成的日志(图中的日志5)接着广播完成,这没有什么关系。
- Followers日志补齐
当Leader故障时,Followers上的日志状态是不一样的,有长有短。因此新的Leader选出后,首先要将所有Followers的日志补齐才行。因此Leader要询问Followers的日志长度,从最小的日志位置开始补齐。
- Followers未提交日志的更新
新Leader的日志一定包含所有已经提交的日志。但新Leader的日志不一定是最长的,那些新Leader没有的日志,一定是未提交的日志,因此可以被更新,没有关系的。Leader只需要从自己的当前位置开始插入日志并广播出去就可以了。Followers会用新的日志去更新指定位置上的日志。
4 - 新旧Leader的交替
新的Leader选出后,开始广播日志。这时如果旧的Leader故障恢复了(比如网络临时中断),并且还认为自己是Leader,也会广播日志。这不就导致了同时有两个Leader出现吗?是的,Raft也没办法让旧的Leader不发日志,但是Raft有办法让Followers拒绝旧Leader的日志。
- Term
Raft将时间划分为连续的时间段,称为Term。 Term是指从一次Leader选举开始到下一次Leader选举的一段时间。这段时间内只能有一个Leader被选举成功,并负责管理系统或者没有Leader选出。
Raft论文上的Term图片
每个Term都有一个唯一的数字编号。所有Term的数字编号是从小到大连续排列的。
- 作废旧Leader
Term编号在作废旧Leader的过程中至关重要,但却十分简单。过程如下:
发送日志到所有Followers,Leader的Term编号随日志一起发送。
Followers收到日志后,检查Leader的Term编号。如果Leader的Term编号等于或者大于自己的当前Term(Current Term)编号,则存储日志到队列并且应答收到日志。否则发送失败消息给Leader,消息中包含自己的当前Term编号。
当Leader收到任何Term编号比自己的Term编号大的消息时,则将自己变成Follower。收到的消息包括:Follower给自己的回复消息、新Leader的日志广播消息、Leader的选举消息。
- Raft的实现
论文中作者仅用了两个RPC就实现了Raft的功能,它们分别是:
RequestVote() Candidate发起的投票请求
AppendEntries() 将日志广播到Followers上
AppendEntries()除了广播日志外,作者还巧妙的用它实现了以下的功能:
发送心跳(heartbeat): 没有客户日志时,通过AppendEntries()广播空日志,当做心跳。
发送Commit Index:当Commit Index更新后,可以随着当前的日志通过AppendEntries()广播到Followers上。如果没有客户端日志,则可以随着心跳广播出去。
以上是关于由浅入深理解Raft协议的主要内容,如果未能解决你的问题,请参考以下文章