Alluxio架构场景与部分配置参数详解
Posted 气运联盟
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Alluxio架构场景与部分配置参数详解相关的知识,希望对你有一定的参考价值。
Alluxio架构、场景与部分配置参数
1 架构
1.1 概述
Alluxio作为大数据和机器学习生态系统中的一个新的数据访问层,配置在任何持久性存储系统(如Amazon S3、Microsoft Azure对象存储、Apache HDFS或OpenStack Swift)和计算框架(如Apache Spark、Presto或Hadoop MapReduce)之间。**请注意,Alluxio不是一个持久化存储系统。**使用Alluxio作为数据访问层有如下好处:
1.对于用户应用程序和计算框架,Alluxio提供了快速存储,促进了作业之间的数据共享和局部性,而不管使用的是哪种计算引擎。因此,当数据位于本地时,Alluxio可以以内存速度提供数据;当数据位于Alluxio时,Alluxio可以以计算集群网络的速度提供数据。第一次访问数据时,只从存储系统上读取一次数据。为了得到更好的性能,Alluxio推荐部署在计算集群上。
2.对于存储系统,Alluxio弥补了大数据应用与传统存储系统之间的差距,扩大了可用的数据工作负载集。当同时挂载多个数据源时,Alluxio可以作为任意数量的不同数据源的统一层。
Alluxio可以被分为三个部分:**masters、workers以及clients。**一个典型的设置由一个主服务器、多个备用服务器和多个worker组成。客户端用于通过Spark或MapReduce作业、Alluxio命令行或FUSE层等应用程序与Alluxio服务器通信。
Alluxio使用了单Master和多Worker的架构,Master和Worker一起组成了Alluxio的服务端,它们是系统管理员维护和管理的组件,Client通常是应用程序,如Spark或MapReduce作业,或者Alluxio的命令行用户。Alluxio用户一般只与Alluxio的Client组件进行交互。
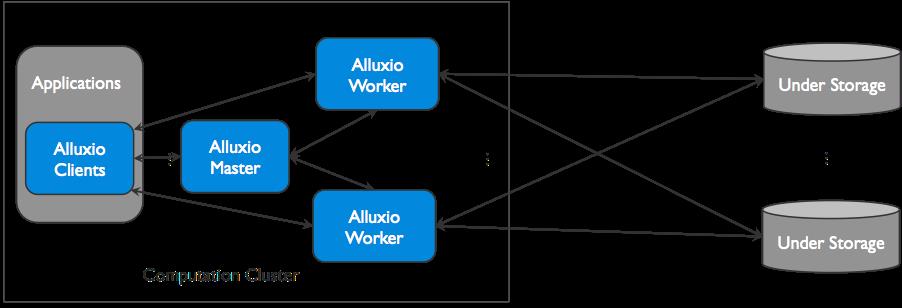
1.1.1Master
Alluxio主服务可以部署为一个主master和几个备用master,以实现容错。当主master奔溃时,备用master可以被选为新的主master。
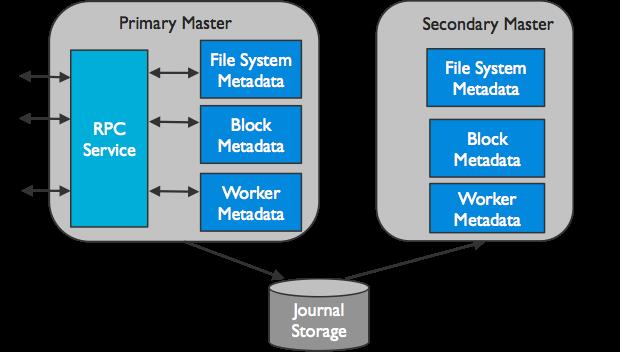
Master: 负责管理整个集群的全局元数据并响应Client对文件系统的请求。在Alluxio文件系统内部,每一个文件被划分为一个或多个数据块(block),并以数据块为单位存储在Worker中。Master节点负责管理文件系统的元数据(如文件系统的inode树、文件到数据块的映射)、数据块的元数据(如block到Worker的位置映射),以及Worker元数据(如集群当中每个Worker的状态)。所有Worker定期向Master发送心跳消息汇报自己状态,以维持参与服务的资格。Master通常不主动与其他组件通信,只通过RPC服务被动响应请求,同时Master还负责实时记录文件系统的日志(Journal),以保证集群重启之后可以准确恢复文件系统的状态。Master分为Primary Master和Secondary Master,Secondary Master需要将文件系统日志写入持久化存储,从而实现在多Master(HA模式下)间共享日志,实现Master主从切换时可以恢复Master的状态信息。Alluxio集群中可以有多个Secondary Master,每个Secondary Master定期压缩文件系统日志并生成Checkpoint以便快速恢复,并在切换成Primary Master时读取之前Primary Master写入的日志。Secondary Master不处理任何Alluxio组件的任何请求。
(1)主master
Alluxio中只有一个master进程为主master。主master用于管理全局的元数据。这里面包含文件系统元数据(文件系统节点树)、数据块元数据(数据块位置)、以及worker的容量元数据(空闲或已占用空间)。Alluxio clients与主master通信用来读取或修改元数据。所有的worker都会定期的向主master发送心跳。主master会在一个分布式的持久化系统上记录所有的文件系统事务,这样可以恢复主master的信息。这组日志被称为journal。---------------导致的问题,Master内存爆了,client与master的通信过于频繁!!!
(2)备用master
备用master读取主master写入的journal日志,以保持与主master的状态同步。它们会对journal日志写入检查点,用于快速恢复。它们不处理来自Alluxio组件的任何请求。
1.1.2Worker
Worker: Alluxio Master只负责响应Client对文件系统元数据的操作,而具体文件数据传输的任务由Worker负责,如图,每个Worker负责管理分配给Alluxio的本地存储资源(如RAM,SSD,HDD),记录所有被管理的数据块的元数据,并根据Client对数据块的读写请求做出响应。Worker会把新的数据存储在本地存储,并响应未来的Client读请求,Client未命中本地资源时也可能从底层持久化存储系统中读数据并缓存至Worker本地。
Worker代替Client在持久化存储上操作数据有两个好处:1.底层读取的数据可直接存储在Worker中,可立即供其他Client使用 2.Alluxio Worker的存在让Client不依赖底层存储的连接器,更加轻量化。
Alluxio采取可配置的缓存策略,Worker空间满了的时候添加新数据块需要替换已有数据块,缓存策略来决定保留哪些数据块。
Alluxio的worker用于管理用户为Alluxio定义的本地资源(内存、SSD、HDD)。Alluxio的worker将数据存储为块,并通过在其本地资源上读或者创建新的数据块来响应client请求。Workers只用于管理数据块;文件到数据块的映射存储在master中。Workers在其底层存储上进行数据操作。这带来两个重要的优势:
1.从底层存储系统读取的数据能被存储在worker中,这样别的client可以立即使用。
2.client可以是轻量级的,不依赖于底层存储的连接器。
因为RAM的容量有限,所以当空间满了的时候block会被清理。Workers使用清理策略决定什么数据留在Alluxio中。
1.1.3 Client
Client: 允许分析和AI/ML应用程序与Alluxio连接和交互,它发起与Master的通信,执行元数据操作,并从Worker读取和写入存储在Alluxio中的数据。它提供了Java的本机文件系统API,支持多种客户端语言包括REST,Go,Python等,而且还兼容HDFS和Amazon S3的API。
可以把Client理解为一个库,它实现了文件系统的接口,根据用户请求调用Alluxio服务,客户端被编译为alluxio-2.0.1-client.jar文件,它应当位于JVM类路径上,才能正常运行。
当Client和Worker在同一节点时,客户端对本地缓存数据的读写请求可以绕过RPC接口,使本地文件系统可以直接访问Worker所管理的数据,这种情况被称为短路写,速度比较快,如果该节点没有Worker在运行,则Client的读写需要通过网络访问其他节点上的Worker,速度受网络宽带的限制。
2 Alluxio场景与数据流
Alluxio的应用场景
Alluxio 的落地非常依赖场景,否则优化效果并不明显(无法发挥内存读取的优势)
- 计算应用需要反复访问远程云端或机房的数据(存储计算分离)
- 混合云,计算与存储分离,异构的数据存储带来的系统耦合(Alluxio提供统一命名空间,统一访问接口)
- 多个独立的大数据应用(比如不同的Spark Job)需要高速有效的共享数据(数据并发访问)
- 计算框架所在机器内存占用较高,GC频繁,或者任务失败率较高,Alluxio通过数据的OffHeap来减少GC开销
- 有明显热表/热数据,相同数据被单应用多次访问
- 需要加速人工智能云上分析(如TensorFlow本地训练,可通过FUSE挂载Alluxio FS到本地)
提示:如果HDFS本身已经和Spark和Hive共置了,那么这个场景并不算Alluxio的目标场景。计算和存储分离的情况下才会有明显效果,否则通常是HDFS已经成为瓶颈时才会有帮助。“
还有,如果HDFS部署在计算框架本地,作业的输入数据可能会存在于系统的高速缓存区,则Alluxio对数据加速也并不明显。
以下:描述了Alluxio读或写的场景,基于以下的配置:Alluxio与计算集群部署在一起,持久化存储系统可以为远程存储系统或云存储。
2.1 读
在底层存储和计算集群间,Alluxio是作为一个缓存层存在的。这小节描述了不同的缓存场景以及其对性能的影响。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hvACuKUT-1647520294115)(C:\\Users\\anonymous\\AppData\\Roaming\\Typora\\typora-user-images\\image-20220316162013845.png)]
2.1.1 本地缓存命中
本地缓存命中发生在请求数据位于本地Alluxio worker。举例说明,如果一个应用通过Alluxio client请求数据,client向Alluxio master请求数据所在的worker。如果数据在本地可用,Alluxio client使用“短路”读取来绕过Alluxio worker,并直接通过本地文件系统读取文件。短路读取避免通过TCP套接字传输数据,并提供数据的直接访问。---------------
【过程:
- 应用通过Allxuio Client与Alluxio Master通信,获得数据的位置信息(数据的元数据信息);
- 根据数据所在位置,如果数据已经被缓存到本地(内存、SSD、HDD等),可以直接访问本地缓存的数据
- 如果数据没有被缓存到本地,需要通过Alluxio worker来读取数据(数据不一定是在Alluxio的其他worker节点,还是在远程的云上-----其他worker节点,优于远程云端)!
问题:Client与Master的频繁通信,占据大量内存 】
还要注意,Alluxio除了内存之外还可以管理其他存储介质(例如SSD、HDD),因此本地数据访问速度可能会因本地存储介质的不同而有所不同。
2.1.2 远程缓存命中
当请求的数据存储在Alluxio中,而不是存储在client的本地worker上时,client将对具有数据的worker进行远程读取。client完成读取后,会要求本地的worker(如果存在)创建一个copy,这样以后读取的时候可以在本地读取相同的数据。远程缓存击中提供了网络级别速度的数据读取。Alluxio优先从远程worker读取数据,而不是从底层存储,因为Alluxio worker间的速度一般会快过Alluxio workers和底层存储的速度。
2.1.3 缓存Miss
如果数据在Alluxio中找不到,则会发生缓存丢失,应用将不得不从底层存储读取数据。Alluxio client会将数据读取请求委托给worker(本地worker优先)。这个worker会从底层存储读取数据并缓存。缓存丢失通常会导致最大的延迟,因为数据必须从底层存储获取。
当client只读取块的一部分或不按照顺序读取块时,client将指示worker异步缓存整个块。异步缓存不会阻塞client,但是如果Alluxio和底层存储系统之间的网络带宽是瓶颈,那么异步缓存仍然可能影响性能。
【异步缓存: worker从底层存储(远程云)中读取数据,返回给client;同时会将数据缓存到本地(内存、SSD、HDD等),等待下次的快速访问。
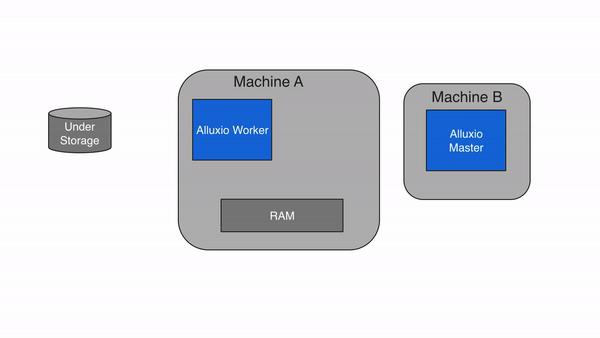
2.2 写
用户可以通过选择不同的写类型来配置应该如何写数据。写类型可以通过Alluxio API设置,也可以通过在客户机中配置属性Alluxio .user.file.writetype.default来设置。本节描述不同写类型的行为以及对应用程序的性能影响。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Pc8V5PSU-1647520294121)(C:\\Users\\anonymous\\AppData\\Roaming\\Typora\\typora-user-images\\image-20220316162038360.png)]
2.2.1 只写入到Alluxio(MAST_CACHE)
当写类型设置为MUST_CACHE,Alluxio client将数据写入本地Alluxio worker,而不会写入到底层存储。如果“短路”写可用,Alluxio client直接写入到本地RAM的文件,绕过Alluxio worker,避免网络传输。由于数据没有持久存储在under storage中,因此如果机器崩溃或需要释放数据以进行更新的写操作,数据可能会丢失。当可以容忍数据丢失时,MUST_CACHE设置对于写临时数据非常有用。
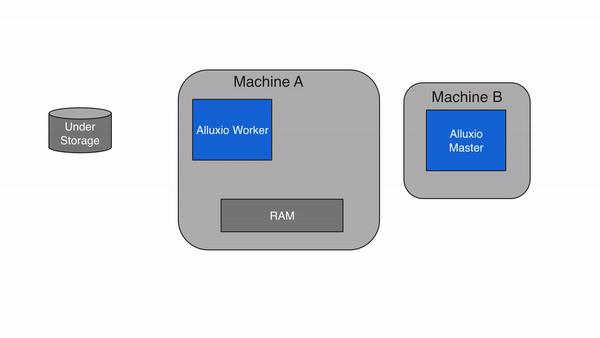
2.2.2 写到UFS(CACHE_THROUGH)
使用CACHE_THROUGH写类型,数据被同步地写到一个Alluxio worker和下一个底层存储。Alluxio client将写操作委托给本地worker,而worker同时将对本地内存和底层存储进行写操作。由于底层存储的写入速度通常比本地存储慢,所以client的**写入速度将与底层存储的速度相匹配。**当需要数据持久化时,建议使用CACHE_THROUGH写类型。在本地还存了一份副本,以便可以直接从本地内存中读取数据。
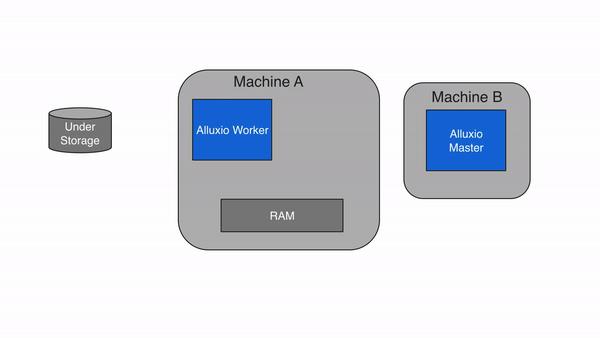
2.2.3 写回UFS(ASYNC_THROUGH)
Alluxio提供了一个叫做ASYNC_THROUGH的写类型。数据被同步地写入到一个Alluxio worker,并异步地写入到底层存储。ASYNC_THROUGH可以在持久化数据的同时以内存速度提供数据写入。
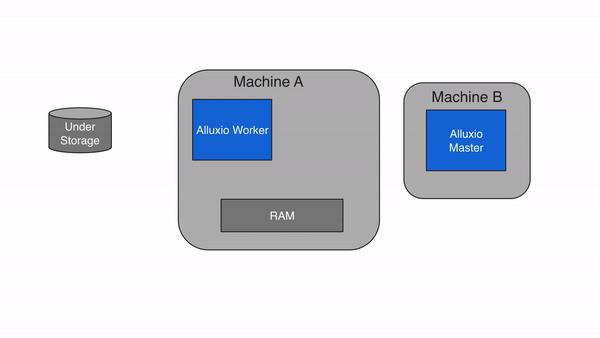
3.Alluxio的重要配置参数
3.1 Alluxio的读写配置参数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8nlf7puJ-1647520294128)(C:\\Users\\anonymous\\AppData\\Roaming\\Typora\\typora-user-images\\image-20220316162245501.png)]
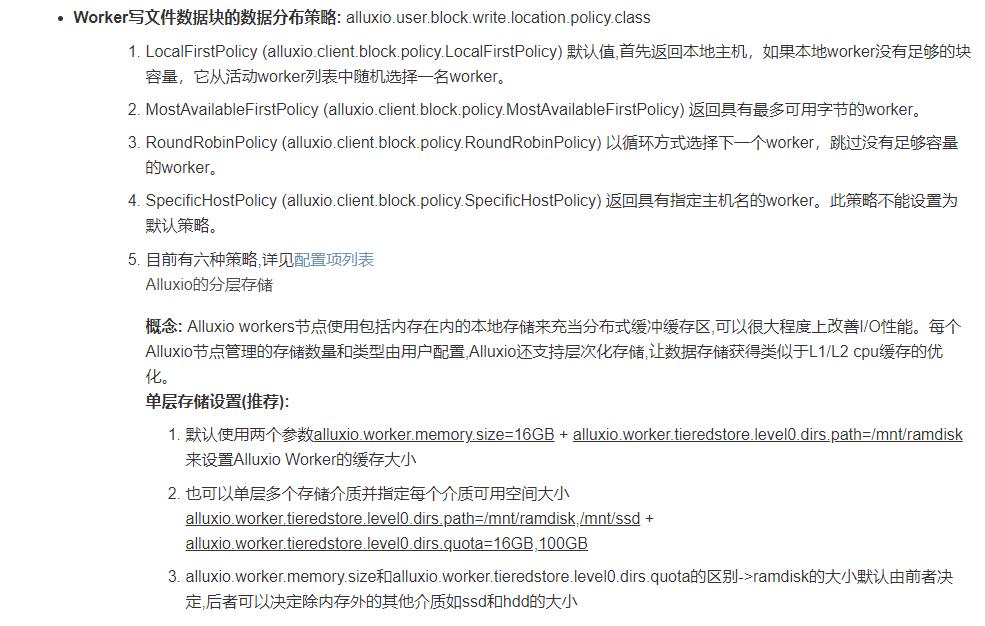
3.2 多级存储策略
多层存储的配置-使用两层存储MEM和HDD
alluxio.worker.tieredstore.levels=2 # 最大存储级数 在Alluxio中配置了两级存储
alluxio.worker.tieredstore.level0.alias=MEM # alluxio.worker.tieredstore.level0.alias=MEM 配置了首层(顶层)是内存存储层
alluxio.worker.tieredstore.level0.dirs.path=/mnt/ramdisk # 设置了ramdisk的配额是100GB
alluxio.worker.tieredstore.level0.dirs.quota=100GB
alluxio.worker.tieredstore.level0.watermark.high.ratio=0.9 # 回收策略的高水位
alluxio.worker.tieredstore.level0.watermark.low.ratio=0.7
alluxio.worker.tieredstore.level1.alias=HDD # 配置了第二层是硬盘层
alluxio.worker.tieredstore.level1.dirs.path=/mnt/hdd1,/mnt/hdd2,/mnt/hdd3 # 定义了第二层3个文件路径各自的配额
alluxio.worker.tieredstore.level1.dirs.quota=2TB,5TB,500GB
alluxio.worker.tieredstore.level1.watermark.high.ratio=0.9
alluxio.worker.tieredstore.level1.watermark.low.ratio=0.7
写数据默认写入顶层存储,也可以指定写数据的默认层级 alluxio.user.file.write.tier.default 默认0最顶层,1表示第二层,-1倒数第一层
Alluxio收到写请求,直接把数据写入有足够缓存的层,如果缓存全满,则置换掉底层的一个Block.
3.3 缓存回收策略
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rBsZ5w1f-1647520294129)(C:/Users/anonymous/AppData/Roaming/Typora/typora-user-images/image-20220316162719403.png)]
3.4 Alluxio的异步缓存策略
(base) [mca@clu08 bin]$ alluxio version
2.7.0-SNAPSHOT
# 当前集群使用的版本2.7.0

3.5 Alluxio元数据存储管理
在Alluxio新的2.x版本中,对元数据存储做了优化,使其能应对数以亿级的元数据存储。
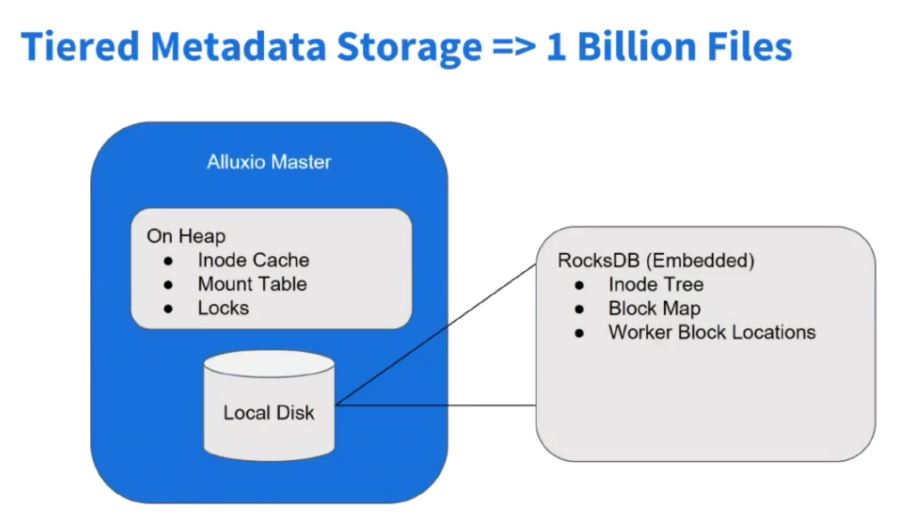
首先,文件系统是INode-Tree组成的,即文件目录树,Alluxio Master管理多个底层存储系统的元数据,每个文件目录都是INode-Tree的节点,在Java对象中,可能一个目录信息本身占用空间不大,但映射在JavaHeap内存中,算上附加信息,每个文件大概要有1KB左右的元数据,如果有十亿个文件和路径,则要有约1TB的堆内存来存储元数据,完全是不现实的。
所以,为了方便管理元数据,减小因为元数据过多对Master性能造成的影响,Alluxio的元数据通过RocksDB键值数据库来管理元数据,Master会Cache常用数据的元数据,而大部分元数据则存在RocksDB中,这样大大减小了Master Heap的压力,降低OOM可能性,使Alluxio可以同时管理多个存储系统的元数据。
通过RocksDB的行锁,也可以方便高并发的操作Alluxio元数据。
高可用过程中,INode-Tree是进程中的资源,不共享,如果ActiveMaster挂掉,StandByMaster节点可以从Journal持久日志(位于持久化存储中如HDFS)恢复状态。
这样会依赖持久存储(如HDFS)的健康状况,如果持久存储服务宕机,Journal日志也不能写,Alluxio高可用服务就会受到影响。
所以,Alluxio通过Raft算法保证元数据的完整性,即使宕机,也不会丢失已经提交的元数据。
详细演变可参考:
3.6 元数据的一致性
-
Alluxio读取磁层存储系统的元数据,包括文件名,文件大小,创建者,组别,目录结构等
-
如果绕过Alluxio修改底层存储系统的目录结构,Alluxio会同步更新
alluxio.user.file.metadata.sync.interval=-1 Alluxio不主动同步底层存储元数据
alluxio.user.file.metadata.sync.interval=正整数 正整数指定了时间窗口,该时间窗口内不触发元数据同步
alluxio.user.file.metadata.sync.interval=0 时间窗口为0,每次读取都触发元数据同步
时间窗口越大,同步元数据频率越低,Alluxio Master性能受影响越小
-
Alluxio不加载具体数据,只加载元数据,若要加载文件数据,可以通过load命令或FileStream API
-
在Alluxio中创建文件或文件夹时可以指定是否持久化
alluxio fs -Dalluxio.user.file.writetype.default=CACHE_THROUGH mkdir /xxx
alluxio fs -Dalluxio.user.file.writetype.default=CACHE_THROUGH touch /xxx/xx
3.7 Alluxio的Metrics
度量指标信息可以让用户深入了解集群上运行的任务,是监控和调试的宝贵资源。
Alluxio的度量指标信息被分配到各种相关Alluxio组件的实例中。每个实例中,用户可以配置一组度量指标槽,来决定报告哪些度量指标信息。现支持Master进程,Worker进程和Client进程的度量指标 。
- 度量指标的sink
参数为alluxio.metrics.sink.xxx
ConsoleSink: 输出控制台的度量值。
CsvSink: 每隔一段时间将度量指标信息导出到CSV文件中。
JmxSink: 查看JMX控制台中注册的度量信息。
GraphiteSink: 给Graphite服务器发送度量信息。
MetricsServlet: 添加Web UI中的servlet,作为JSON数据来为度量指标数据服务。
- 可选度量的配置
-
Master的Metrics 配置方法 master.* 例如:master.CapacityTotal
常规信息CapacityTotal: 文件系统总容量(以字节为单位)。
CapacityUsed: 文件系统中已使用的容量(以字节为单位)。
CapacityFree: 文件系统中未使用的容量(以字节为单位)。
PathsTotal: 文件系统中文件和目录的数目。
UnderFsCapacityTotal: 底层文件系统总容量(以字节为单位)。
UnderFsCapacityUsed: 底层文件系统中已使用的容量(以字节为单位)。
UnderFsCapacityFree: 底层文件系统中未使用的容量(以字节为单位)。
Workers: Worker的数目。
逻辑操作
DirectoriesCreated: 创建的目录数目。
FileBlockInfosGot: 被检索的文件块数目。
FileInfosGot: 被检索的文件数目。
FilesCompleted: 完成的文件数目。
FilesCreated: 创建的文件数目。
FilesFreed: 释放掉的文件数目。
FilesPersisted: 持久化的文件数目。
FilesPinned: 被固定的文件数目。
NewBlocksGot: 获得的新数据块数目。
PathsDeleted: 删除的文件和目录数目。
PathsMounted: 挂载的路径数目。
PathsRenamed: 重命名的文件和目录数目。
PathsUnmounted: 未被挂载的路径数目。
RPC调用
CompleteFileOps: CompleteFile操作的数目。
CreateDirectoryOps: CreateDirectory操作的数目。
CreateFileOps: CreateFile操作的数目。
DeletePathOps: DeletePath操作的数目。
FreeFileOps: FreeFile操作的数目。
GetFileBlockInfoOps: GetFileBlockInfo操作的数目。
GetFileInfoOps: GetFileInfo操作的数目。
GetNewBlockOps: GetNewBlock操作的数目。
MountOps: Mount操作的数目。
RenamePathOps: RenamePath操作的数目。
SetStateOps: SetState操作的数目。
UnmountOps: Unmount操作的数目。 -
Worker的Metrics 配置方法 192_168_1_1.* 例如:192_168_1_1.CapacityTotal
常规信息
CapacityTotal: 该Worker的总容量(以字节为单位)。
CapacityUsed: 该Worker已使用的容量(以字节为单位)。
CapacityFree: 该Worker未使用的容量(以字节为单位)。
逻辑操作
BlocksAccessed: 访问的数据块数目。
BlocksCached: 被缓存的数据块数目。
BlocksCanceled: 被取消的数据块数目。
BlocksDeleted: 被删除的数据块数目。
BlocksEvicted: 被替换的数据块数目。
BlocksPromoted: 被提升到内存的数据块数目。
BytesReadAlluxio: 通过该worker从Alluxio存储读取的数据量,单位为byte。其中不包括UFS读。
BytesWrittenAlluxio: 通过该worker写到Alluxio存储的数据量,单位为byte。其中不包括UTF写。
BytesReadUfs-UFS: U F S : 通 过 该 w o r k e r 从 指 定 U F S 读 取 的 数 据 量 , 单 位 为 b y t e 。 B y t e s W r i t t e n U f s − U F S : UFS: 通过该worker从指定UFS读取的数据量,单位为byte。 BytesWrittenUfs-UFS: UFS:通过该worker从指定UFS读取的数据量,单位为byte。BytesWrittenUfs−UFS:UFS: 通过该worker写到指定UFS的数据量,单位为byte。 -
Client的Metrics 配置方法 client.* 例如:clien.BytesReadRemote
常规信息
NettyConnectionOpen: 当前Netty网络连接的数目。
逻辑操作
BytesReadRemote: 远程读取的字节数目。
BytesWrittenRemote: 远程写入的字节数目。
BytesReadUfs: 从ufs中读取的字节数目。
BytesWrittenUfs: 写入ufs的字节数目。
配置示例
vim metrics.properties
# List of available sinks and their properties.
alluxio.metrics.sink.ConsoleSink
alluxio.metrics.sink.CsvSink
alluxio.metrics.sink.JmxSink
alluxio.metrics.sink.MetricsServlet
alluxio.metrics.sink.PrometheusMetricsServlet
alluxio.metrics.sink.GraphiteSink
master.GetFileBlockInfoOps
master.GetNewBlockOps
master.FreeFileOps
192_168_1_101.BytesReadAlluxio
192_168_1_101.BytesWrittenAlluxio
192_168_1_101.BlocksAccessed
192_168_1_101.BlocksCached
192_168_1_101.BlocksCanceled
192_168_1_101.BlocksDeleted
192_168_1_101.BlocksEvicted
192_168_1_101.BlocksPromoted
192_168_1_102.BytesReadAlluxio
192_168_1_102.BytesWrittenAlluxio
192_168_1_102.BlocksAccessed
192_168_1_102.BlocksCached
192_168_1_102.BlocksCanceled
192_168_1_102.BlocksDeleted
192_168_1_102.BlocksEvicted
192_168_1_102.BlocksPromoted
192_168_1_103.BytesReadAlluxio
192_168_1_103.BytesWrittenAlluxio
192_168_1_103.BlocksAccessed
192_168_1_103.BlocksCached
192_168_1_103.BlocksCanceled
192_168_1_103.BlocksDeleted
192_168_1_103.BlocksEvicted
192_168_1_103.BlocksPromoted
然后访问 http://192.168.1.101:19999/metrics/json/ 可得到监控信息
3.8 Alluxio审计日志
Alluxio提供审计日志来方便管理员可以追踪用户对元数据的访问操作。
开启审计日志: 讲JVM参数alluxio.master.audit.logging.enabled设为true
审计日志包含如下条目:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-nX6nBaku-1647520294131)(C:/Users/anonymous/AppData/Roaming/Typora/typora-user-images/image-20220316163810322.png)]
4.配置资源
Alluxio属性可以在多个资源中配置。在这种情况下,它的最终值由列表中最早的资源配置决定:
- JVM系统参数 (i.e.,
-Dproperty=key) - 环境变量
- 参数配置文件. 当Alluxio集群启动时, 每一个Alluxio服务端进程(包括master和worke) 在目录
$HOME/.alluxio/,/etc/alluxio/and$ALLUXIO_HOME/conf下顺序读取alluxio-site.properties, 当alluxio-site.properties文件被找到,将跳过剩余路径的查找. - 集群默认值. Alluxio客户端可以根据master节点提供的集群范围的默认配置初始化其配置。
如果没有为属性找到上面用户指定的配置,那么会回到它的默认参数值。
要检查特定配置属性的值及其值的来源,用户可以使用以下命令行:
$ ./bin/alluxio getConf alluxio.worker.rpc.port
29998
$ ./bin/alluxio getConf --source alluxio.worker.rpc.port
DEFAULT
列出所有配置属性的来源:
$ ./bin/alluxio getConf --source
alluxio.conf.dir=/Users/bob/alluxio/conf (SYSTEM_PROPERTY)
alluxio.debug=false (DEFAULT)
...
用户还可以指定--master选项来通过master节点列出所有的集群默认配置属性 。注意,使用--master选项 getConf将查询master,因此需要主节点运行;没有--master 选项,此命令只检查本地配置。
$ ./bin/alluxio getConf --master --source
alluxio.conf.dir=/Users/bob/alluxio/conf (SYSTEM_PROPERTY)
alluxio.debug=false (DEFAULT)
...
腾讯大咖分享 | 腾讯Alluxio(DOP)在金融场景的落地与优化实践
目录
Alluxio导读
近期,腾讯 Alluxio 团队与 CDG 金融数据团队、TEG supersql 团队、konajdk 团队进行通力协作,解决了金融场景落地腾讯 Alluxio(DOP=Data Orchestration Platform 数据编排平台) 过程中遇到的各种问题,最终达到了性能和稳定性都大幅提升的效果。

背景
在腾讯金融场景中,我们的数据分析主要有两大入口,一个是基于sql的分析平台产品idex,另一个是图形化的分析平台产品"全民BI"。全民BI是一款类似tableau一样的可以通过拖拉拽进行数据探索分析的工具,因为不需要编写sql,所以面向人群更广,不仅包括了数据分析人员,还有产品和运营,对耗时的敏感度也更高,而这里主要介绍的是针对全民BI应用场景的落地优化。
为支持日益增加的各类分析场景,今年腾讯金融业务数据团队进行了较大的架构升级,引入了 Presto + 腾讯 Alluxio(DOP),以满足用户海量金融数据的自由探索需求。
大数据olap分析面临的挑战
| 挑战一:从可用到更快,在快速增长的数据中交互式探索数据的需求。

虽然这些年SSD不管是性能还是成本都获得了长足的进步,但是在可见的未来5年,HDD还是会以其成本的优势,成为企业中央存储层的首选硬件,以应对未来还会继续快速增长的数据。
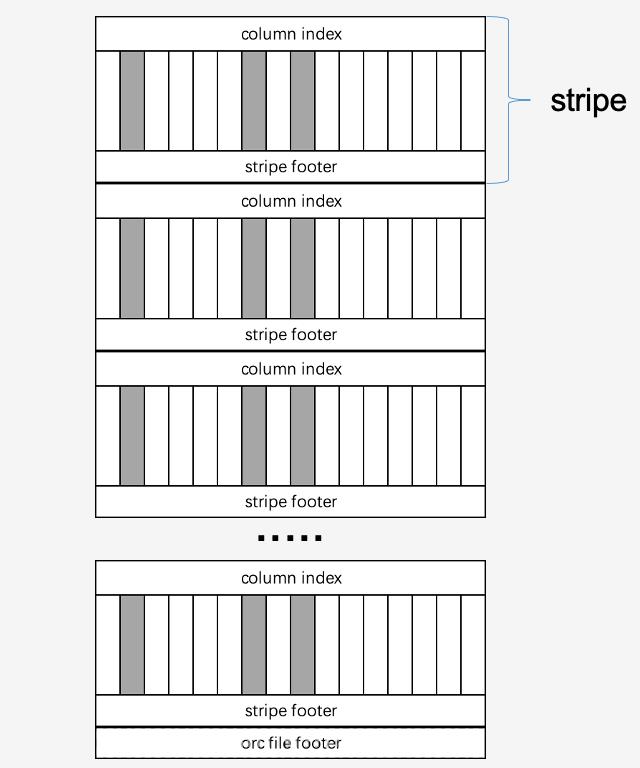
但是对于olap分析的特点,磁盘的IO是近乎随机碎片化的,SSD显然才是更合适的选择。
下图展示的是olap分析中presto对一个ORC文件读取的视图,其中灰色竖条表示具体的分析需要读取的三列数数据在整个文件中可能的位置分布:
| 挑战二:在多种计算任务负载,olap分析的性能如何在IO瓶颈中突围
企业大数据计算常见的两种负载:
✓ ETL:数据的抽取(extract)、转换(transform)、加载(load),主要是在数据仓库、用户画像、推荐特征构建上,特点是涉及大部分的数据列。
✓ OLAP:在线联机分析处理,主要用在对数据的多维度分析上,特点是仅涉及少量的数据列,但可能涉及较大的数据范围。
虽然ETL的峰值会在凌晨,但其实整个白天都会有各种任务在不断的执行,两种类型任务的IO负载的影响看起来不可避免,再加上中央存储层HDD硬盘的IO性能约束,IO很容易会成为数据探索的瓶颈。
| 一种流行的解决方案
面对这些挑战,目前很多企业会选择下面的这种架构:
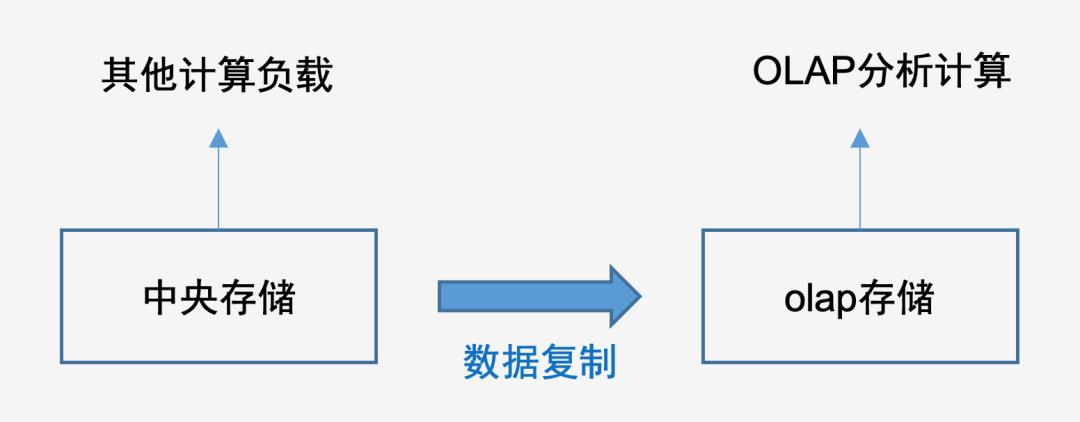
将olap分析需要的热数据(比如近一年)复制到一个olap专用的存储中,这样不仅可以解决IO竞争的问题,还可以选用SSD硬盘,进一步加速olap。
但是这样的架构却又引入了新的问题:
✓ 数据的边界:因为数据需要提前复制,如果需要临时分析超出约定范围的数据(比如同比去年),就会导致只能降级到中央存储上的引擎去执行,这里不仅涉及到存储的切换,也涉及到计算引擎的切换。
✓ 数据的一致性和安全:数据复制需要面对数据一致性的拷问,另外就是这部分数据的权限和安全问题能否跟中央存储进行关联,否则就要独立管控数据的权限和数据安全,这无疑又是不小的成本,这一点在注重监管的金融行业尤其如此。
Alluxio:一种可能更优的方案
重新思考我们的olap引擎的存储需求其实是:
1)有一份独享的数据副本,最好采用SSD的存储,满足更高的性能要求
2)不需要额外的数据管理成本:数据生命周期、权限和安全
所以我们首先想到的其实是在HDFS层面解决,Hadoop在2.6.0版本的时候引入了异构存储,支持对指定的目录采取某种存储策略,但是这个特性并不能解决我们的几个问题:
✓ 不同计算负载的IO隔离:因为这部分对于olap引擎(比如presto)和etl引擎(比如spark)是透明的,无法实现让olap引擎访问某一个指定的副本(比如ONE_SSD策略的SSD副本)
✓ 数据生命周期的管理成本高:如果要根据冷热做动态策略管理还有大量的工作要做
数据副本其实可以分成物理和逻辑层面来考虑:
1)物理两套,逻辑两套:需要面对两份数据管理的问题
2)物理一套,逻辑一套:难以解决IO隔离的问题
在上面两种不可行的情况下,我们自然地想到了另一个思路:
✓ 物理两套,逻辑一套?
而Alluxio恰好在这个思路上给了我们一种可能性:
Alluxio的元数据可以实现跟HDFS的同步,有比较完善的一致性保障,所以可以理解为在Alluxio中的数据跟HDFS是一份逻辑数据。而基于数据冷热驱逐的自动化机制给更灵活的数据生命周期的管理提供了一条通路。
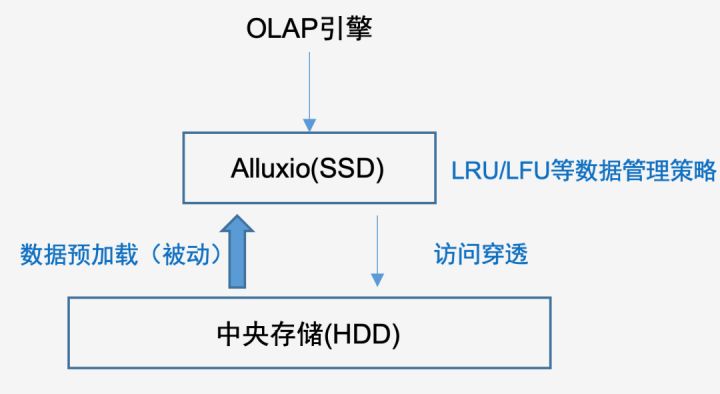
这样,结合数据的预加载,结合Alluxio的缓存特性,不仅做到了无边界的访问中央存储的数据,同时也实现了热数据的IO隔离和SSD加速。
但区别于更流行的缓存加速的用法,我们使用Alluxio的方式更倾向于IO隔离

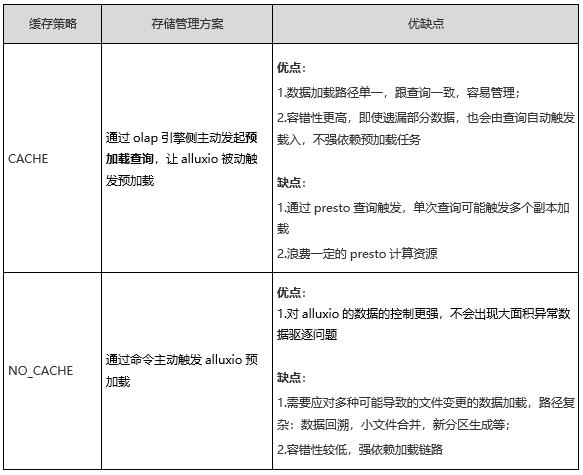
| Alluxio的缓存策略选择
Alluxio的两种主要缓存策略
✓ CACHE : 通过Alluxio访问后,如果不在Alluxio中,则会进行缓存,单位为block
✓ NO_CACHE:通过Alluxio访问后,如果不在Alluxio中,不进行缓存
两种策略对应两种不同的存储管理方案:
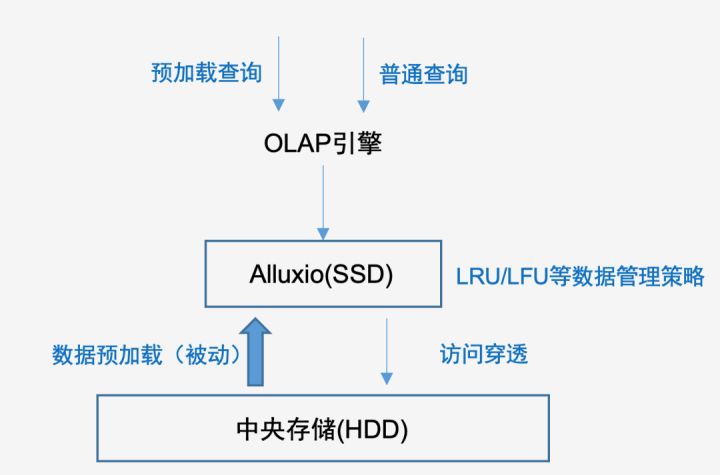
【名词解释】
预加载查询:是通过olap应用系统登记注册的分析主题(对应库表),然后构造的简单聚合查询:select count(*) ,来触发Alluxio的数据加载。
最后考虑到长期的管理和运维复杂度,我们选择了路径单一容错性更高的CACHE方案
新的挑战
思路清晰了,但是还是有三个挑战:
1)如何让Alluxio只应用于olap引擎,而避免修改公共hive元数据中的数据location
2)如何避免一个随意的大范围查询导致其他数据被大面积驱逐?
3)异构存储机型下,我们的缓存请求分配策略怎么选择?
| 挑战一:如何让Alluxio只应用olap引擎,而无需修改hive元数据?
因为alluixo的访问schema是:Alluxio:// ,所以正常情况下使用Alluxio需要在hive中将对应表格的地址修改为Alluxio://,但如果那样做的话,其他引擎(比如spark)也会同样访问到Alluxio,这是我们不希望的。
得益于TEG 天穹presto团队的前期工作,我们采取的做法是通过在presto中增加一个Alluxio库表白名单模块解决。也就是根据用户访问的库表,我们将拿到元数据的地址前缀hdfs://hdfs_domain/user-path替换成了alluxio://allluxio_domain:port/hdfs_domain/user-path, 这样后续的list目录和获取文件操作都会走alluxio client,以此解决alluxio的独享问题。
另外对于商业版本的alluxio,还有一个Transparent URI 的特性可以解决同样的问题。
| 挑战二:如何避免随意的大范围查询导致其他数据被大面积驱逐
利用库表白名单,我们实现了对Alluxio存储的数据的横向限制,但是依然存在一个很大的风险就是用户可能突然提交一个很大范围的查询,进而导致很多其他库表的数据被evict。
因为只要采用的是CACHE策略,只要数据不在Alluxio,就会触发Alluxio的数据加载,这时候就会导致其他数据根据evict策略(比如LRU) 被清理掉。
为了解决这个问题我们采取了下面的两个关键的策略:
✓ 基于时间范围的库表白名单策略:
在库表白名单的横向限制基础上,增加纵向的基于分区时间的限制机制,所以就有了我们后面迭代的基于时间范围的库表白名单策略,我们不仅限制了库表,还限制了一定的数据范围(一般用最近N天表示)的分区数据,然后再结合用户高频使用数据的范围,就可以确定一个库表比较合理范围。
下面是一个样例片段参考:
"dal_base.*",
"dal_base.*.$yyyyMMddHH:(-720h,0)",
"dal_base.*.$yyyyMMdd:(-217d,0)",
"dal_base.*.$yyyyMM:(-36m,0)"✓ 降低Alluxio worker异步缓存加载的最大线程数:
Alluxio.worker.network.async.cache.manager.threads.max 默认是2倍cpu核数,我们基本上是调整成了1/2甚至是1/4 cpu核数,这样因为查询突然增加的load cache请求就会被reject掉,降低了对存量数据的影响。
这样我们实际上就是构建了一个Alluxio的保护墙,让Alluxio在一个更合理的数据范围内(而不是全局)进行数据管理,提升了数据的有效性。
而且采用这样的策略,部分直接走HDFS的流量不管是耗时,还是对Alluxio的内存压力都会有所降低。
| 挑战三: 异构存储机型下,我们的缓存请求分配策略怎么选择?
这个也是将Alluxio当作一个存储层,可以独立扩展必须要面对的,新的机型不一定跟原来的一致。面对异构 Worker 存储的需求,Alluxio已有的块位置选取策略,都会造成热点或者不均衡的问题,不能有效利用不同worker上的存储资源。比如:
✓ RoundRobinPolicy、DeterministicHashPolicy:平均策略,将请求平均分配给所有Worker,会导致小容量的worker上的数据淘汰率更高;
✓ MostAvailableFirstPolicy:可能会导致大容量worker容易成为数据加载热点;而且因为所有worker存储最终都会达到100%,所以满了之后这个策略也就是失去意义了。
因此 我们积极参与腾讯 Alluxio 开源社区,设计并贡献了“基于容量的随机块位置选取策略 CapacityBaseRandomPolicy”。
该策略的基本思想是:在随机策略的基础上,基于不同worker的容量给予不同节点不同的分发概率。这样容量更大的worker就会接收更多的请求,配合不同worker上的参数调整,实现了均衡的数据负载。
如下图所示,是上线初期的容量情况,第一列是存储容量,第二列是使用容量,可以看到基本是按比例在增长。

除了上面的三个挑战,我们还对方案中的一个问题"presto触发查询会导致多副本问题"做了优化。因为presto的查询会将一个文件拆成以split为单位(默认64MB)进行并行处理,会在不同Worker上触发缓存,实际上会对数据产生多个副本。本来我们使用DeterministicHashPolicy来限制副本数量,但是由于切换到了CapacityBaseRandomPolicy,我们再一次对副本数失去了控制。因此我们做了如下两个优化:
✓ 预加载查询设置大split(max_initial_split_size,max_split_size):使用跟alluxio block size一致的split,比如256MB,这样避免一个文件被拆成多个split
✓ 对CapacityBaseRandomPolicy增加了缓存机制:避免了同一个worker多次请求发送到多个worker上,触发多个副本加载问题
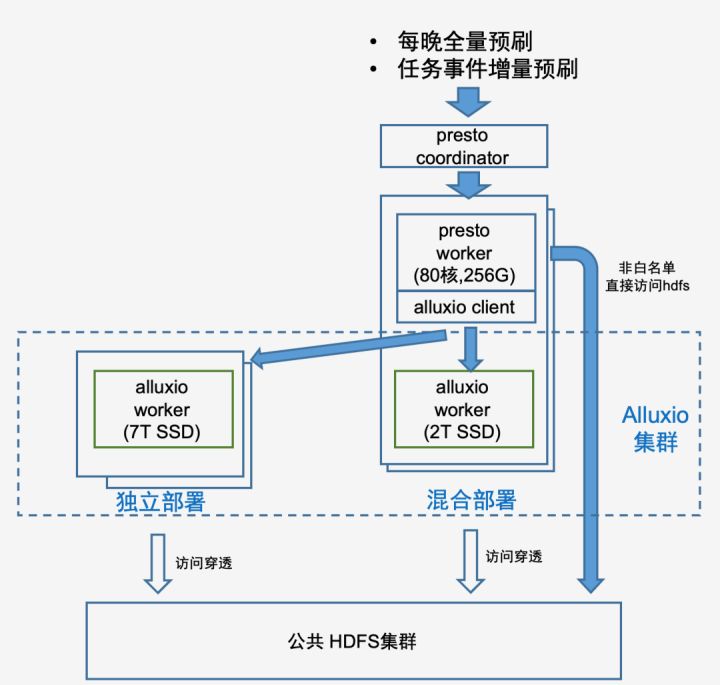
最终架构
在落地过程中,为了满足实际存储需求,额外申请了SSD存储机型扩容了Alluxio worker,最终采用了 Presto + 腾讯 Alluxio(DOP) 混合部署以及独立部署 Alluxio Worker 的架构,即有的服务器同时部署了Presto worker和Alluxio worker,有的服务器仅部署Alluxio worker,该架构具有计算和存储各自独立扩展的能力。
线上运行效果
我们基于某一工作日随机抽取了一批历史查询,5个并发,由于完全是随机的,所以查询涉及的范围可能包含了部分一定不走Alluxio的数据(不在预设的白名单时间范围,或者没有命中),但是能更真实反映我们实际使用的效果。
测试我们选取了两个时间段:
1) 周末下午:500个查询,大部分ETL任务已经完成,HDFS大集群负载低,这时候主要看SSD加速效果。
2)工作日早上:300个查询,这个时间点还会有很多ETL,画像标签、推荐特征等任务运行,HDFS集群繁忙程度较高,这个主要看IO隔离性。
测试结果如下:
闲时:
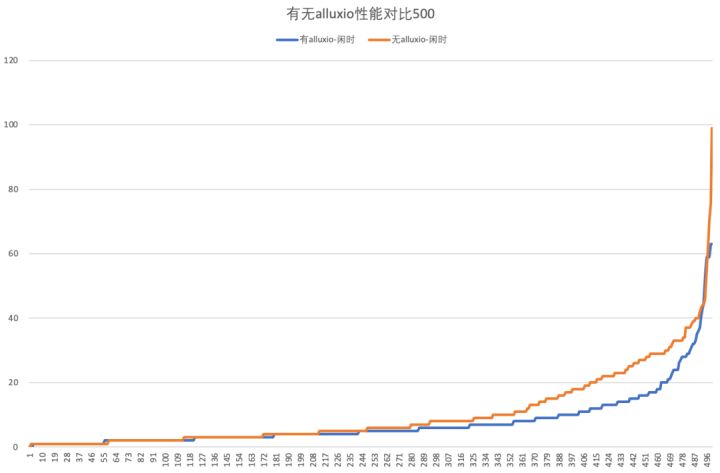
图中的横坐标是按耗时从低到高排序后的500个查询(剔除了最大值213秒),纵坐标是耗时(单位秒),其中90分位的耗时有Alluxio和无Alluxio分别是16s和27s,90分位的查询性能提升为68.75%,这里主要是SSD带来性能提升。
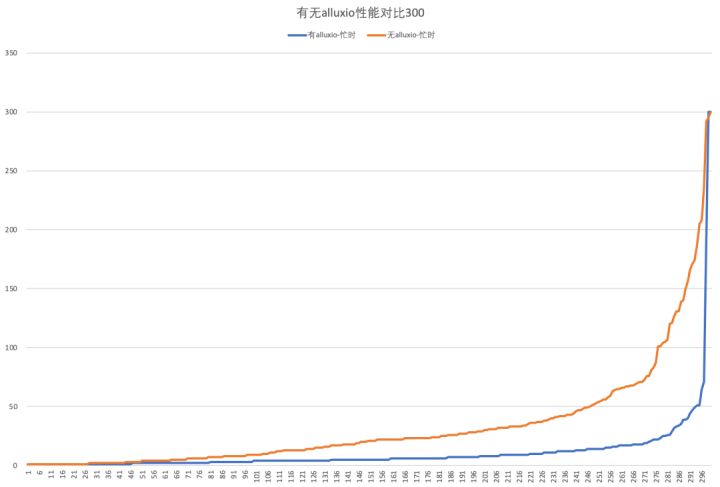
忙时:
图中的横纵坐标如上一个图一致,横坐标是300个按耗时排序后的查询,注意:因为查询覆盖的数据范围可能超过Alluxio的数据范围,所以会出现极端值。
效果总结:
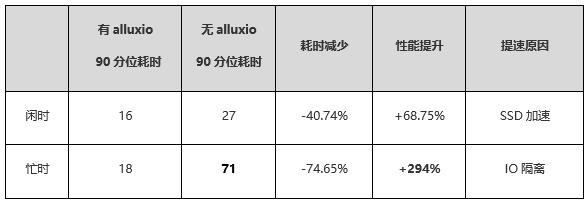
从测试结果可以看到:
✓ SSD提速:即使在闲时对50%以上的查询都有一定幅度的提升效果,在90分位达到了68%的性能提升。
✓ IO隔离优势:可以看到HDFS忙时,无Alluxio的90分位查询会明显上升,但是有Alluxio的查询非常平稳,在90分位到达了+294%的性能提升。
优化调优实践
| 采用腾讯 Konajdk + G1GC
腾讯 Alluxio(DOP) 采用 KonaJDK 和 G1GC 作为底层 JVM 和 垃圾回收器。KonaJDK 对于 G1GC 进行了持续的优化,相较于社区版本,针对腾讯内部应用特点进行了深度的优化,减少了GC暂停时间和内存使用。
| 利用腾讯 Kona-profiler 定位高并发访问 Alluxio Master FGC 问题
当出现业务海量并发查询请求场景,Alluxio Master 出现了频繁 FGC 的情况,并且内存无法大幅回收,导致 Alluxio Master 无法正常提供服务,影响业务使用。
我们获取了 JVM heap dump 文件,使用 kona-profiler 进行分析。
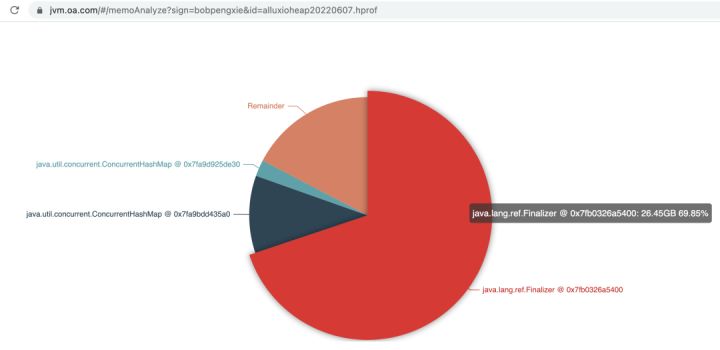
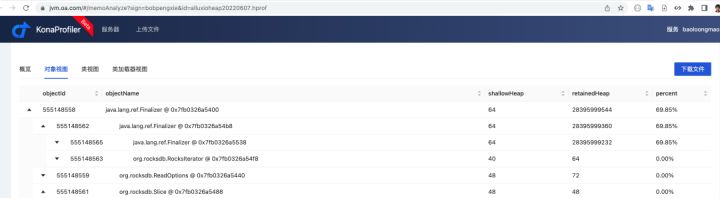
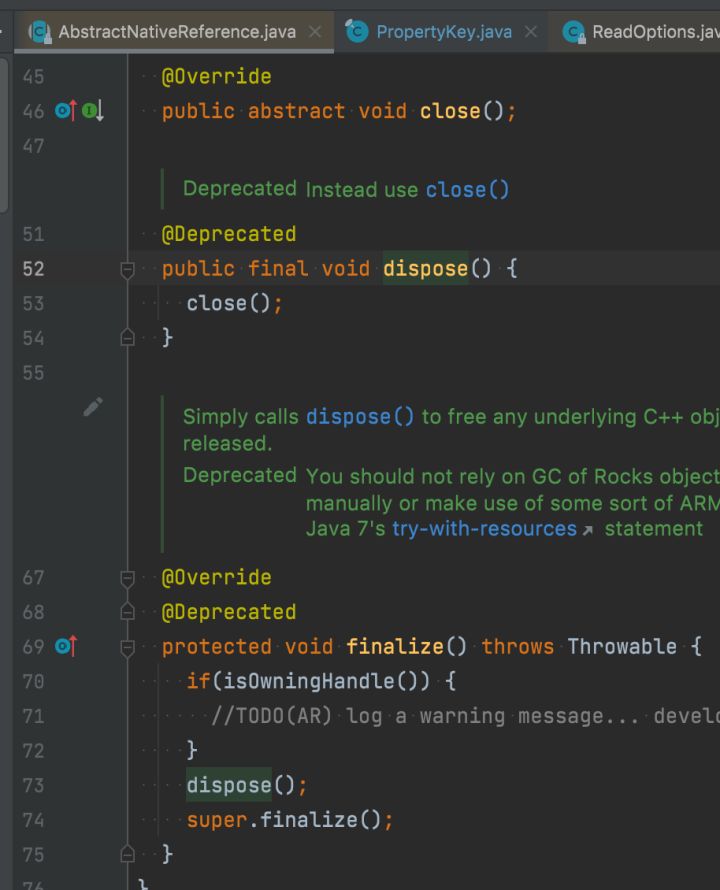
使用 kona-profiler 快速发现问题的瓶颈在于:短时间内出现了大量未被释放的 Rocksdb 的 ReadOptions 对象,这些对象被Finalizer引用,说明ReadOptions对象可以被回收了,但是在排队做 finalizer 的函数调用,进一步定位发现,ReadOptions 对象的祖先类 AbstractNativeReference 实现了 finalizer 函数,其中的逻辑又过于复杂,因此回收较慢,这在7.x 版本的 rocksdb 已经修复。
但由于版本升级跨度过大,我们采用另一种办法解决该问题。配置腾讯 Alluxio 的alluxio.master.metastore.block=ROCKS_BLOCK_META_ONLY,支持把 blockLocation 独立放置于内存管理,而 block 信息使用 rocksdb 管理,这样从根本上避免了原本海量获取 block 位置操作,构造海量 rocksdb 的 ReadOptions 对象的问题。
升级改造后。
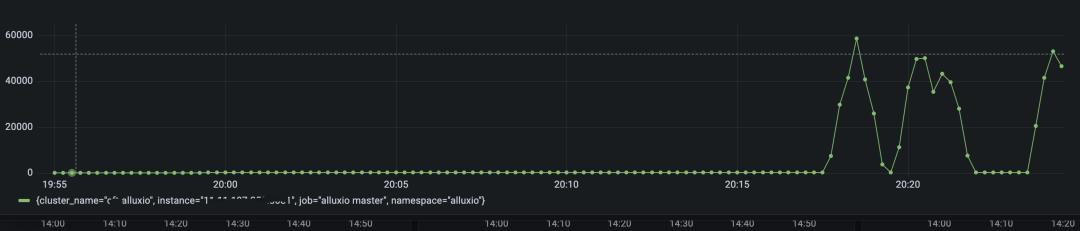
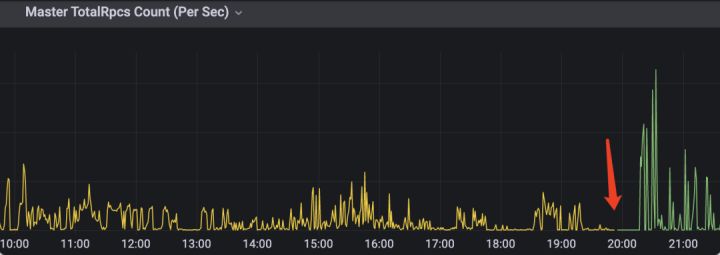
Alluxio 侧,在压测的情况下,999分位从原来的 10ms 减少到了 0.5ms,qps 从 2.5w 提升到了6.5w;
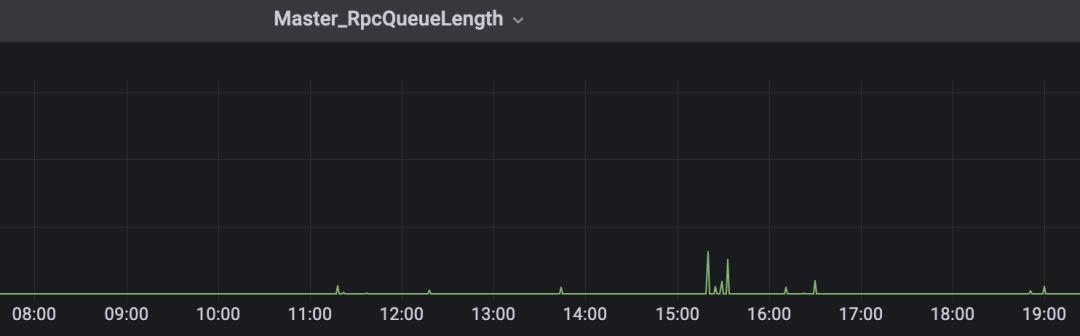
正常负载下升级前rpc排队情况:
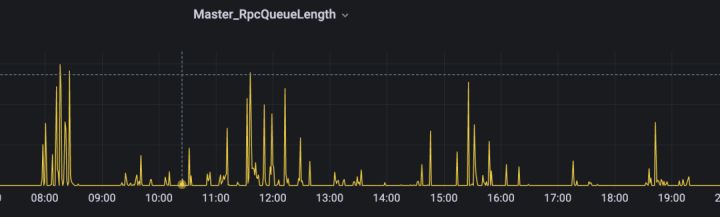
正常负载下升级后 rpc 排队情况:
Presto 侧:对于涉及分区很多的查询场景,比如大范围的点击流漏斗分析,在一个基准测试里,从 120 秒减少到了 28 秒,提升了4 倍。
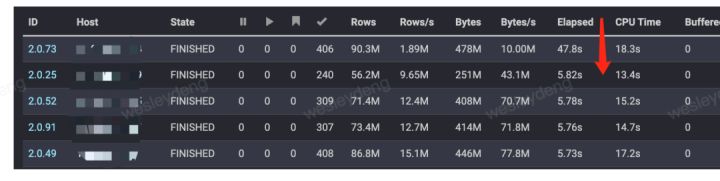
| 周期性出现50秒慢查询问题参数优化
一个查询多次执行耗时差很多。大部分在7秒左右,但是会偶尔突然增加到50秒,就是某个数据读取很慢,测试的时候集群的负载还是比较低的。
下图是慢查询时 Presto 的调用栈
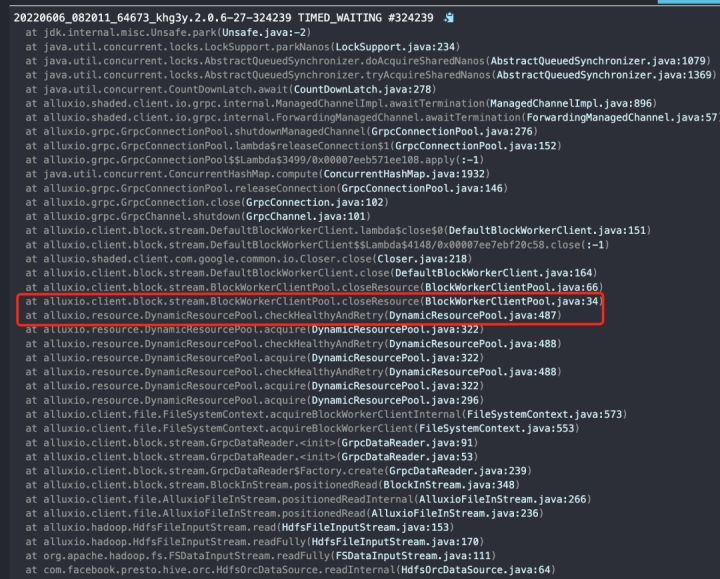
结合源码,可以看出此时 Alluxio 客户端认为拿到的 BlockWorker 客户端是不健康的。
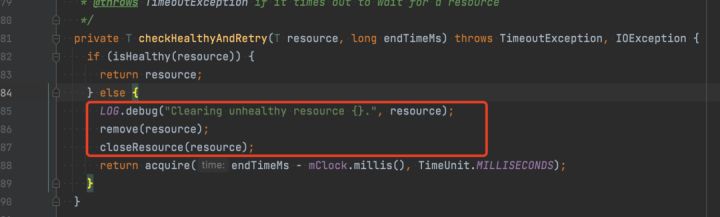
判断健康的判定标准为:不是 shutdown 状态,且两个通信 channel 都是健康的。
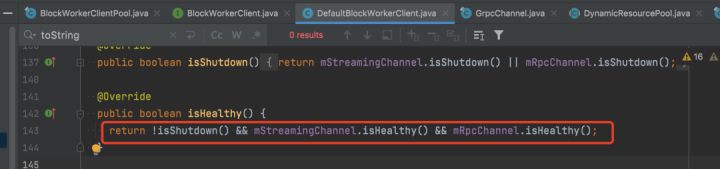
根据上下文,可以判断,目前不是 shutdown 的,那么只能是两个通信 channel 不健康了。
进一步结合源码,定位在 closeResource 过程中,会关闭并释放 grpcConnection,这个过程中会先优雅关闭,等待超时如果未能优雅关闭则转为强制关闭。
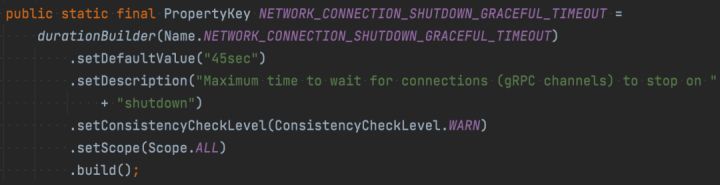
因此,规避该问题,只需要修改调小配置项 alluxio.network.connection.shutdown.graceful.timeout 即可。
| Master data 页面卡住的问题优化
Alluxio Master 的 data 页面,在有较多 in Alluxio 文件的时候,会出现卡住的问题。这是因为,打开这个页面时,Alluxio Master 需要扫描所有文件的所有块。
为了避免卡住的问题,采用限制 in Alluxio 文件个数的解决办法。可以配置最多展示的 in Alluxio 文件数量。
总结展望
✓ 腾讯 Alluxio(DOP) 支持 BlockStore 层次化,前端为缓存层,后端为持久层,同时,blockLocation 这种不需要持久化的数据,不需要实时写入后端持久层,只需要在前端缓存层失效的时候才需要溢出到后端,该功能正在内部评测。
✓ 腾讯 Alluxio(DOP) 作为一个中间组件,在大数据查询场景,遇到的性能问题,在业务侧,需要业务团队不仅对自身业务非常了解,对 Alluxio 也需要有一定的了解。在底层 JVM 侧,需要 JVM 专业的团队采用专业的技术进行协作解决,从而最大限度的优化,使得整体方案发挥最优的性能。
✓ 这是一次非常成功的跨 BG,跨团队协作,快速有效的解决腾讯 Alluxio(DOP) 落地过程中的问题,使得腾讯 Alluxio(DOP) 在金融业务场景顺利落地。
往期阅读
【遇见Alluxio专家】将数据编排技术用于AI模型训练
【Alluxio实现高可用】看Alluxio如何在存储文件系统状态时实现高可用和容错
 暑期编程PK赛
暑期编程PK赛
 得CSDN机械键盘等精美礼品!
得CSDN机械键盘等精美礼品!
以上是关于Alluxio架构场景与部分配置参数详解的主要内容,如果未能解决你的问题,请参考以下文章
腾讯大咖分享 | 腾讯Alluxio(DOP)在金融场景的落地与优化实践
Presto on Alluxio By Alluxio SDS 单节点搭建