清华&BAAI唐杰团队提出第一个开源的通用大规模预训练文本到视频生成模型CogVideo,含94亿超大参数量!代码即将开源!...
Posted 我爱计算机视觉
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了清华&BAAI唐杰团队提出第一个开源的通用大规模预训练文本到视频生成模型CogVideo,含94亿超大参数量!代码即将开源!...相关的知识,希望对你有一定的参考价值。
关注公众号,发现CV技术之美

我爱计算机视觉
专业计算机视觉技术分享平台,“有价值有深度”,分享开源技术与最新论文解读,传播视觉技术的业内最佳实践。知乎/微博:我爱计算机视觉,官网 www.52cv.net 。KeyWords:深度学习、机器学习、计算机视觉、人工智能。
公众号
本篇分享论文『CogVideo: Large-scale Pretraining for Text-to-Video Generation via Transformers』,油清华&BAAI唐杰团队提出第一个开源的通用大规模预训练文本到视频生成模型CogVideo,含94亿超大参数量!代码即将开源!
详细信息如下:

论文链接:https://arxiv.org/abs/2205.15868
项目链接:https://github.com/THUDM/CogVideo
01
摘要
大规模预训练Transformer在文本(GPT-3)和文本到图像(DALL-E和CogView)生成方面创造了里程碑。它在视频生成中的应用仍然面临着许多挑战:潜在的巨大计算成本使得从头开始的训练难以负担;文本视频数据集的稀缺性和弱相关性阻碍了模型对复杂运动语义的理解。
在这项工作中,作者提出了9B参数Transformer——CogVideo,通过继承预训练文本到图像模型CogView2进行训练。作者还提出了多帧率分层训练策略,以更好地对齐文本和视频片段。作为(可能)第一个开源的大规模预训练文本到视频模型,CogVideo在机器和人工评估方面大大优于所有公开可用的模型。
02
Motivation
自回归Transformer,如DALL-E和CogView,最近彻底改变了文本到图像的生成。研究自回归Transformer在文本到视频生成中的潜力是很自然的。之前的工作遵循这一基本框架,例如VideoGPT,验证了其优于基于GAN的方法,但仍远不能令人满意。
一个常见的挑战是,生成的视频帧往往会逐渐偏离文本提示,使生成的角色难以执行所需的操作。Vanilla自回归模型可能擅长合成具有规则(例如直线移动的汽车)或随机模式(例如,通过随机移动的嘴唇说话)的视频,但在文本提示上失败,例如“狮子正在喝水”。这两种情况之间的主要区别在于,在前一种情况下,第一帧已经为后续的更改提供了足够的信息,而在后一种情况下,模型必须准确理解“喝”的动作,以便正确生成所需的动作——狮子将玻璃杯举到嘴唇,喝下,然后放下玻璃杯。
为什么自回归Transformer很好地理解文本-图像关系,但却很难理解视频中的文本-动作关系?作者认为数据集和利用它们的方式是主要原因。
首先,可以从互联网上收集数十亿对高质量的文本图像,但文本视频数据更为稀缺。最大的带标注文本视频数据集VATEX只有41250个视频。基于检索的文本-视频对(如Howto100M)相关性较弱,大多数只描述场景,没有时间信息。
其次,视频的持续时间变化很大。以前的模型将视频分割为固定帧数的多个片段进行训练,这会破坏文本与其在视频中的时间对应物体之间的对齐。如果将一段“饮酒”视频分为四个单独的片段,分别是“拿着杯子”、“举起”、“饮酒”和“放下”,并使用相同的文本“饮酒”,那么模型将被混淆,无法了解饮酒的准确含义。

在本文中,作者提出了一个大规模的预训练文本到视频生成模型CogVideo,该模型有94亿个参数,在540万个文本-视频对上进行训练。为了继承从文本图像预训练中学习到的知识,作者基于预训练的文本到图像模型CogView2构建了CogVideo。
为了保证视频中文本与其时间对应物之间的对齐,作者提出了多帧率分层训练。文本条件的灵活性使得可以简单地将一段描述帧率的文本前置到原始文本提示中,以建模不同的帧率。为了保持文本视频对齐,作者选择适当的帧率描述,以便在每个训练样本中包含完整的动作。帧率token还控制生成中整个连续帧的更改强度。
具体来说,作者训练了序列生成模型和帧插值模型。前者根据文本生成关键帧,后者通过改变帧率递归填充中间帧,使视频连贯。如上图所示,CogVideo可以生成高分辨率(480×480)视频。人类评估表明,CogVideo在很大程度上优于所有公开可用的模型。本文的主要贡献如下:
提出CogVideo,它是通用领域中最大也是第一个用于文本到视频生成的开源预训练Transformer。
CogVideo优雅而高效地微调了文本到图像生成的预训练用于文本到图像的生成,避免了从头开始昂贵的完全预训练。
提出了多帧率分层训练来更好地对齐文本片段对,这显著提高了生成精度,尤其是对于复杂语义的运动。这种训练策略赋予CogVideo控制生成过程中变化强度的能力。
03
方法
作者首先在3.1节中介绍了多帧率分层训练,以更好地对齐文本和视频语义,然后在3.2节中说明了一种有效的方法,即双通道注意,以继承用于视频生成的预训练文本图像模型中的知识。为了克服大模型和长序列造成的大内存和时间开销,作者参考了Swin注意力,并将其扩展到3.3节中的自回归视频生成。
3.1 Multi-frame-rate Hierarchical Training
作者遵循VQV AE的框架,首先将每个帧token为图像token。每个训练样本由5帧token组成,但本文的训练方法在训练序列的构造和生成过程上有所不同。
Training
关键的设计是在文本和样本帧中添加一个帧率token,以此帧率组成一个固定长度的训练序列。动机有两个方面:
直接将长视频以固定的帧率分割成片段通常会导致语义不匹配。作者仍然使用了全部文本,但截断的片段可能只包含不完整的操作。
相邻帧通常非常相似。与前一帧相比的巨大变化可能会导致巨大的loss。这将导致模型不太倾向于探索长期相关性,因为简单地复制前一帧就像一条捷径。
因此,在每个训练样本中,作者希望文本和帧尽可能匹配。作者预定义了一系列帧速率,并为每个文本视频对选择最低帧率,所以作者在视频中以该帧率至少采样5帧。
尽管上述方法增加了文本和视频的对齐,但在低帧率下的生成可能不连贯。因此,作者训练另一个帧插值模型,将过渡帧插入到序列生成模型的生成样本中。由于CogLM的通用性,这两个模型可以共享相同的结构和训练过程,只需使用不同的注意力mask。
Generation
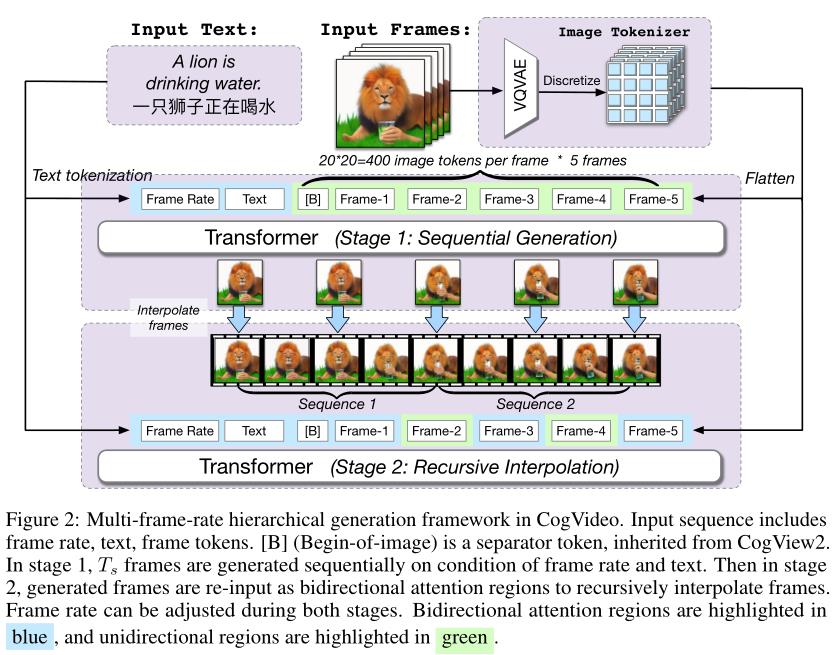
多帧率分层生成是一个递归过程,如上图所示。具体而言,生成管道包括顺序生成阶段和递归插值阶段:
基于低帧率和文本顺序生成个关键帧。输入序列是。在实验中,作者将设置为5,并将最小采样帧速率设置为1 fps。
基于文本、帧率和已知帧进行递归插值帧。输入序列是,其中帧将自动回归生成。通过递归对半,可以进行越来越精细的插值来生成多帧的视频。
The effect of CogLM
诸如帧插值之类的任务严重依赖于双向信息。然而,以前的大多数作品都使用GPT,这是单向的。为了了解双向上下文,作者采用了跨模态通用语言模型(CogLM)中将token划分为单向和双向注意区域的思想,将双向上下文感知mask预测和自回归生成结合起来。
双向区域可以处理所有双向区域,但单向区域可以处理所有双向区域和以前的单向区域。如上图所示,第1阶段中的所有帧以及第2阶段的第2、4帧,和所有其他帧都属于双向区域。这样,在文本和给定帧中充分利用双向注意上下文,而不会干扰自回归帧预测。
3.2 Dual-channel Attention
大规模的预训练通常需要大量的数据集。对于开放域文本到视频生成,理想情况下,需要数据集覆盖足够的文本-视频对,以推断视频和文本之间的空间和时间相关性。然而,收集高质量的文本-视频对通常是困难、昂贵和耗时的。
一个自然的想法是利用图像数据来促进空间语义的学习。Video Diffusion Model和NÜWA模型尝试将文本图像对添加到文本视频训练中,在多个指标上取得了更好的效果。然而,对于仅视频生成模型的训练,添加图像数据将显著增加训练成本,尤其是在大规模预训练场景中。
在本文中,作者提出利用预训练图像生成模型来代替图像数据。预训练的文本到图像模型,例如CogView2,已经很好地掌握了文本图像关系。用于训练这些模型的数据集的覆盖率也比视频的覆盖率大。
本文提出的技术是双通道注意力,只在每个Transformer层的预训练CogView2中添加一个新的时空注意通道。CogView2中的所有参数都在训练中冻结,只有新添加的注意力层中的参数(上图中的attention-plus)是可训练的。
作者发现,直接微调CogView2以生成文本到视频不能很好地继承知识,因为时间注意力遵循不同的注意模式,并在大梯度训练的初始阶段迅速破坏预训练的权重。
具体而言,带Sandwich-LN 的双通道注意力块可计算为:

混合因子α是一个向量,其中d是输入特征的隐藏大小。为了将α的范围限制在(0,1)之内,作者将其重新参数化为,其中是一个可学习的参数。attention plus块的参数形状与正常的多头注意力块attention base相同,但计算过程不同。
在本文的训练中,作者尝试了两种注意力方式,3D局部注意力和3D Swin注意力块。在3D局部注意力中,(t,x,y)(其中(t,x,y)对应于沿时间、高度和宽度的协调)处token的感受野(RF)是一个范围为的3D区块:
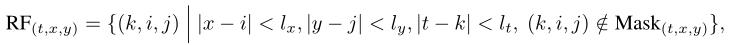
其中,表示token(t,x,y)的注意力mask。在序列生成模型(第1阶段)中,mask确保了自回归顺序;在插值模型(第2阶段)中,mask按照aCogLM的设计,以使所有帧都可以看到已知帧。
值得注意的是,由于FFN是一个包含大量视觉知识的重参数模块,因此两个通道被融合并在每一层中共享相同的FFN。由于图像和视频之间的相似性,将其知识引入时间通道将有助于视频建模。最后,共享FFN可以减少参数,从而加快训练并减少显存开销。
3.3 Shifted Window Attention in Auto-regressive Generatio
为了进一步缓解训练和推理过程中时间通道中的大量时间和内存开销,作者参考了Swin注意力。原来的Swin注意力只适用于非自回归场景,作者通过在移动窗口中应用自回归注意力mask将其扩展到自回归和时间场景。
一个有趣的发现是,Swin注意力为在不同帧的远距离区域进行并行生成提供了机会,这进一步加速了自回归生成。特定token的生成依赖于1)自回归mask。token只能处理前一帧或当前帧中自身之前的token。2)Shifted window。只有在宽度和高度维度的窗口大小距离内的token才能直接注意力。

如上图所示,帧的生成可以并行工作。假设X,Y是每个帧的高度和宽度,是移动窗口的高度和宽度。对于位于和的两个token,
,后者不能直接或间接attend到前者,如果:

这意味着第t帧中的第i个token可以和第t+1帧的第个token并行生成。这样,最多可以并行生成个token,与一次只能生成一个token的标准注意力自回归相比,大大增强了并行性,加快了推理速度。
04
实验

上表展示了UCF-101和Kinetics-600数据集上的生成结果。
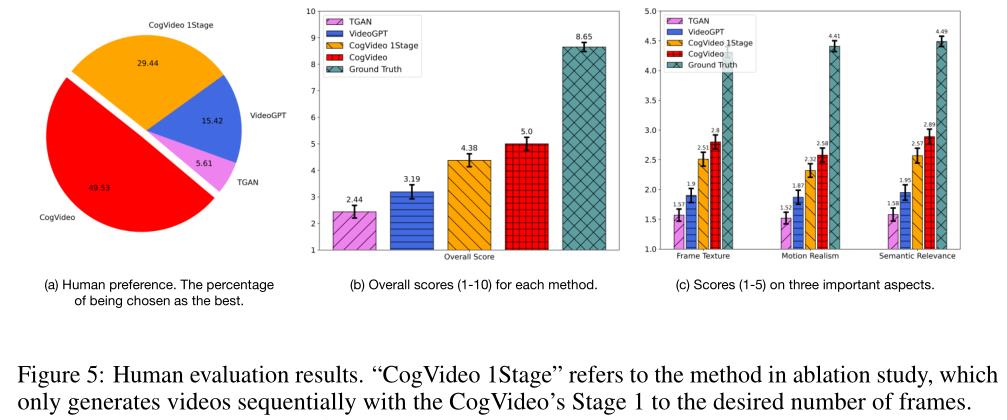
上图中的结果显示,CogVideo在多个重要方面(包括帧纹理、运动真实感和语义相关性)都显著优于baseline,并且在总体质量上取得了最高分。可以看出,49.53%的评估者选择CogVideo作为最佳方法,只有15.42%和5.6%的人分别支持VideoGPT和TGANv2。
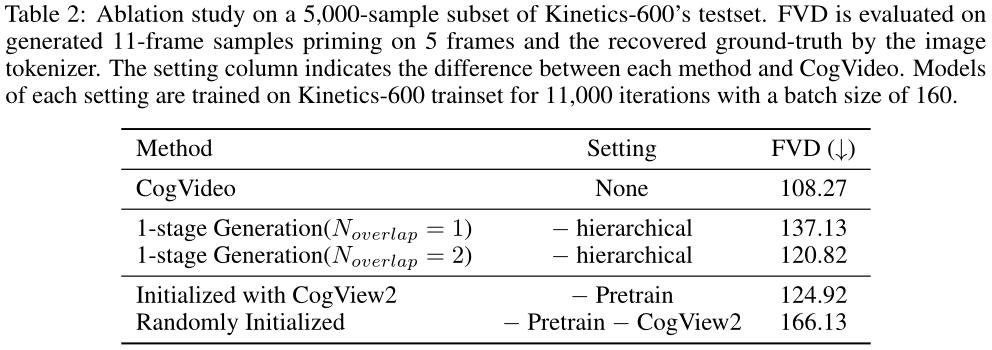
定量结果如上表所示。可以看到,分层方法明显优于具有不同的一阶段生成,并且使用CogView2权重初始化的模型的FVD低于随机初始化的模型。

上图绘制了(1)微调CogVideo的训练损失曲线;(2) 随机初始化训练模型;(3) 使用CogView2初始化训练模型并部分固定。可以看出 CogView2赋予了模型很好的初始化参数。

定性比较如上图所示。虽然从随机初始化训练的模型往往会产生不合理的变形,但包含CogView2的模型能够生成真实的对象,并且层次生成在内容一致性和运动真实性方面表现更好。
05
总结
CogVideo是通用领域中最大、也是第一个用于文本到视频生成的开源预训练Transformer。CogVideo也是第一次尝试在不损害其图像生成能力的情况下,将预训练的文本到图像生成模型有效地利用到文本到视频生成模型。通过提出的多帧率分层训练框架,CogVideo能够更好地理解文本-视频关系,并能够控制生成过程中的变化强度。作者将Swin注意力扩展到CogLM,它可以实现训练和推理的加速。
参考资料
[1]https://arxiv.org/abs/2205.15868
[2]https://github.com/THUDM/CogVideo

END
欢迎加入「计算机视觉」交流群👇备注:CV

清华唐杰团队:一文看懂NLP预训练模型前世今生
博雯 发自 凹非寺
量子位 报道 | 公众号 QbitAI
搞出了全球最大预训练模型的悟道团队,现在来手把手地教你怎么弄懂预训练这一概念了。
刚刚,清华唐杰教授联合悟道团队发布了一篇有关预训练模型的综述:

整篇论文超过40页,从发展历史、最新突破和未来研究三个方向,完整地梳理了大规模预训练模型(PTM)的前世今生。

现在就一起来看看这篇论文的主要内容吧。
预训练的历史
论文首先从预训练的发展过程开始讲起。
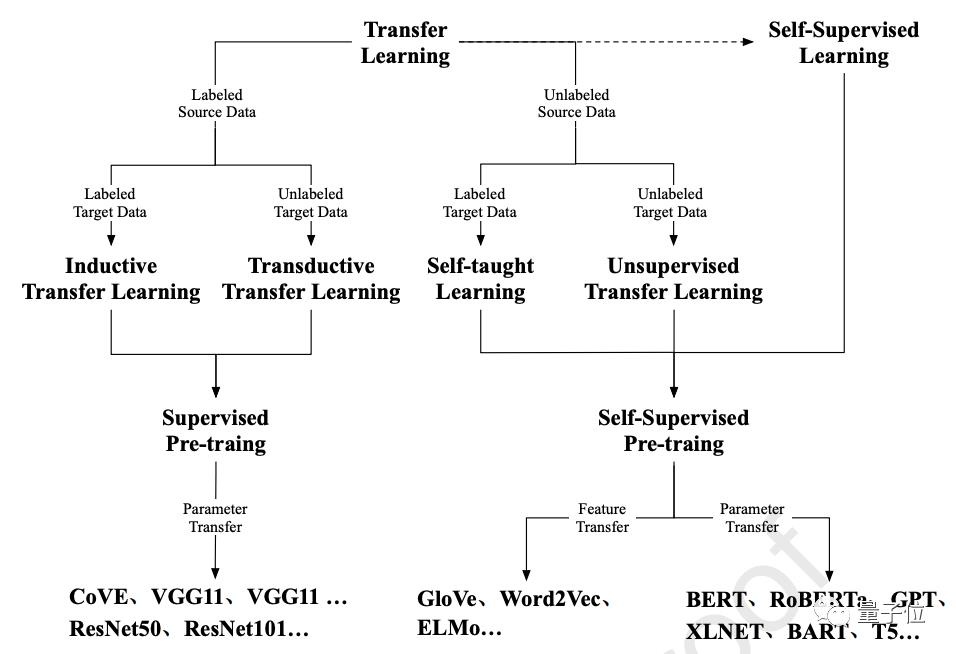
早期预训练的工作主要集中在迁移学习上,其中特征迁移和参数迁移是两种最为广泛的预训练方法。
从早期的有监督预训练到当前的自监督预训练,将基于Transformer的PTM作用于NLP任务已经成为了一种标准流程。
可以说,最近PTM在多种工作上的成功,就得益于自监督预训练和Transformer的结合。
这也就是论文第3节的主要内容:
神经架构Transformer,以及两个基于Transformer的里程碑式的预训练模型:BERT和GPT。
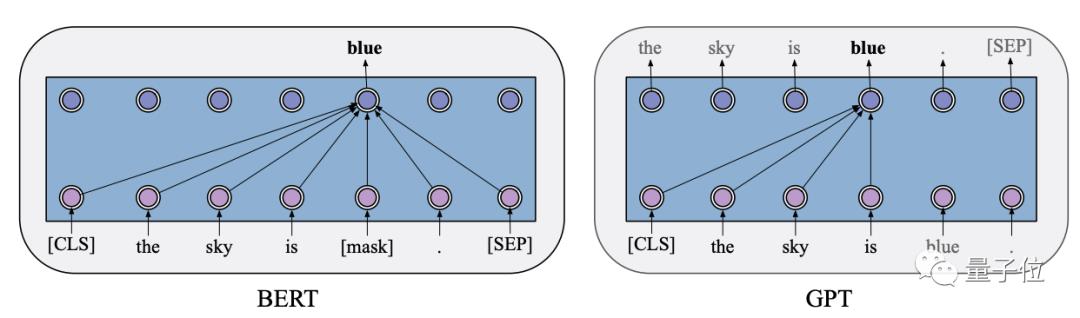
两个模型分别使用自回归语言建模和自编码语言建模作为预训练目标。
后续所有的预训练模型可以说都是这两个模型的变种。
例如论文中展示的这张图,就列出了近年修改了模型架构,并探索了新的预训练任务的诸多PTM:

大规模预训练模型的最新突破
论文的4-7节则全面地回顾了PTM的最新突破。
这些突破主要由激增的算力和越来越多的数据驱动,朝着以下四个方向发展:
设计有效架构
在第4节中,论文深入地探究了BERT家族及其变体PTM,并提到,所有用于语言预训练的基于Transformer的BERT架构都可被归类为两个动机:
统一序列建模
认知启发架构
除此以外,当前大多数研究都专注于优化BERT架构,以提高语言模型在自然语言理解方面的性能。
利用多源数据
很多典型PTM都利用了数据持有方、类型、特征各不相同的多源异构数据。
比如多语言PTM、多模态PTM和知识(Knowledge)增强型PTM。
提高计算效率
第6节从三个方面介绍了如何提升计算效率。
第一种方法是系统级优化,包括单设备优化和多设备优化。
比如说像是ZeRO-Offload,就设计了精细的策略来安排CPU内存和GPU内存之间的交换,以便内存交换和设备计算能够尽可能多地重叠。
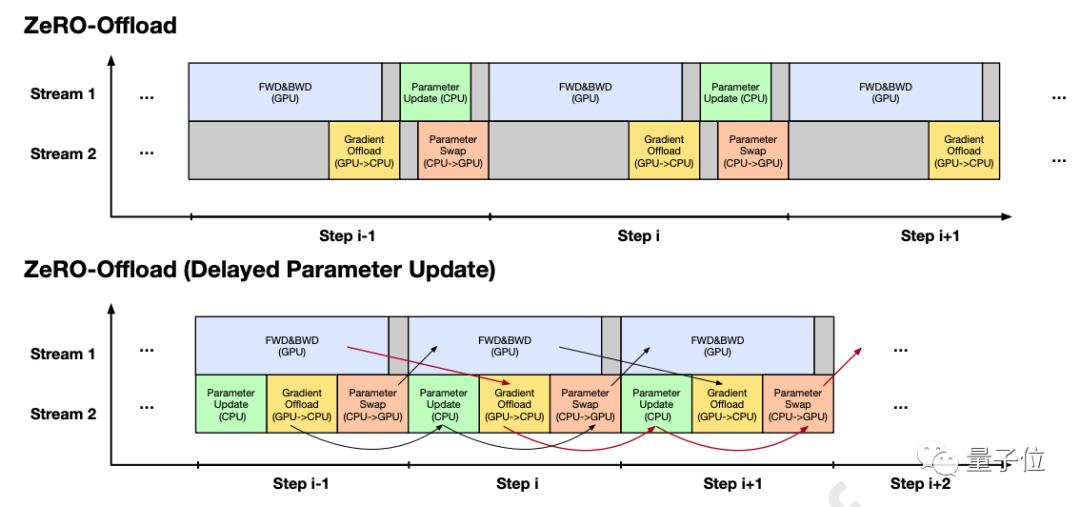
第二种方法是探索更高效的预训练方法和模型架构,以降低方案的成本。
第三种则是模型压缩策略,包括参数共享、模型剪枝、知识蒸馏和模型量化。
解释和理论分析
对于PTM的工作原理和特性,论文在第7节做了详细的解读。
首先是PTM所捕获的两类隐性知识:
一种是语言知识,一般通过表征探测、表示分析、注意力分析、生成分析四种方法进行研究。
另一种是包括常识和事实在内的世界知识。
随后论文也指出,在最近相关工作的对抗性示例中,PTM展现出了严重的鲁棒性问题,即容易被同义词所误导,从而做出错误预测。
最后,论文总结了PTM的结构稀疏性/模块性,以及PTM理论分析方面的开创性工作。
未来的研究方向
到现在,论文已经回顾了PTM的过去与现在,最后一节则基于上文提到的各种工作,指出了PTM未来可以进一步发展的7个方向:
架构和预训练方法
包括新架构、新的预训练任务、Prompt Tuning、可靠性
多语言和多模态训练
包括更多的模态、解释、下游任务,以及迁移学习
计算效率
包括数据迁移、并行策略、大规模训练、封装和插件
理论基础
包括不确定性、泛化和鲁棒性
模识(Modeledge)学习
包括基于知识感知的任务、模识的储存和管理
认知和知识学习
包括知识增强、知识支持、知识监督、认知架构、知识的互相作用
应用
包括自然语言生成、对话系统、特定领域的PTM、领域自适应和任务自适应
论文最后也提到,和以自然语言形式,即离散符号表现的人类知识不同,储存在PTM中的知识是一种对机器友好的,连续的实值向量。
团队将这种知识命名为模识,希望未来能以一种更有效的方式捕捉模识,为特定任务寻找更好的解决方案。
更多细节可点击直达原论文:
http://keg.cs.tsinghua.edu.cn/jietang/publications/AIOPEN21-Han-et-al-Pre-Trained%20Models-%20Past,%20Present%20and%20Future.pdf
参考链接:
https://m.weibo.cn/status/4678571136388064
以上是关于清华&BAAI唐杰团队提出第一个开源的通用大规模预训练文本到视频生成模型CogVideo,含94亿超大参数量!代码即将开源!...的主要内容,如果未能解决你的问题,请参考以下文章
[论文阅读] (22)图神经网络及认知推理总结和普及-清华唐杰老师
克服DIMM近存计算系统的通信瓶颈,清华软件定义芯片团队提出DIMM间广播技术 | ISCA 2021...