常用服务设计
Posted Tattoo_Welkin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常用服务设计相关的知识,希望对你有一定的参考价值。
文章目录
如何设计一个会议室预定系统?
如何设计一个计数服务?
- mysql 直接存储计数值
- 数据量大之后,分库分表
- 流量更大后,就需要 Redis 来加速,协助处理请求(自然就会引来DB与缓存不一致的情况 解决)
- 如何提升写的能力?批量,异步
- 如何缩减存储成本?冷热分离,改造 Redis 底层数据
如何设计一个高性能短链系统?
哈希算法
- 哈希 MurmurHash 算法, MD5,SHA
- 进制转换
- 长链 和 短链的映射关系存储,以短链为唯一索引,写入时,判断是否成功,如果不成功,就在长链的基础上加上自定义字符串,计算 Hash,存储 MYSQL
- (注:
布隆过滤器是一种非常省内存的数据结构,长度为 10 亿的布隆过滤器,只需要 125 M 的内存空间)用所有生成的短网址构建布隆过滤器,当一个新的长链生成短链后,先将此短链在布隆过滤器中进行查找,如果不存在,说明 db 里不存在此短网址,可以插入!
全局唯一自增序列算法
见下面 如何实现全局唯一ID 即可
如果让你写一个消息队列,该如何进行架构设计?
关键点
(1)首先这个 mq 得支持可伸缩性吧,就是需要的时候快速扩容,就可以增加吞吐量和容量,那怎么搞?设计个分布式的系统呗,参照一下 kafka 的设计理念,broker -> topic -> partition,每个 partition 放一个机器,就存一部分数据。如果现在资源不够了,简单啊,给 topic 增加 partition,然后做数据迁移,增加机器,不就可以存放更多数据,提供更高的吞吐量了?
(2)
其次你得考虑一下这个 mq 的数据要不要落地磁盘吧?那肯定要了,落磁盘才能保证别进程挂了数据就丢了。那落磁盘的时候怎么落啊?顺序写,这样就没有磁盘随机读写的寻址开销,磁盘顺序读写的性能是很高的,这就是 kafka 的思路。
(Kafka 就是充分利用了磁盘的这个特性。它的存储设计非常简单,对于每个分区,它把从 Producer 收到的消息,顺序地写入对应的 log 文件中,一个文件写满了,就开启一个新的文件这样顺序写下去。消费的时候,也是从某个全局的位置开始,也就是某一个 log 文件中的某个位置开始,顺序地把消息读出来)
(3)其次你考虑一下你的 mq 的可用性啊?这个事儿,具体参考之前可用性那个环节讲解的 kafka 的高可用保障机制。多副本 -> leader & follower -> broker 挂了重新选举 leader 即可对外服务
如何幂等性?
在计算机中编程中,一个幂等操作的特点是其
任意多次执行所产生的影响均与一次执行的影响相同
1.使用数据库唯一主键索引实现幂等性
2.乐观锁实现幂等性
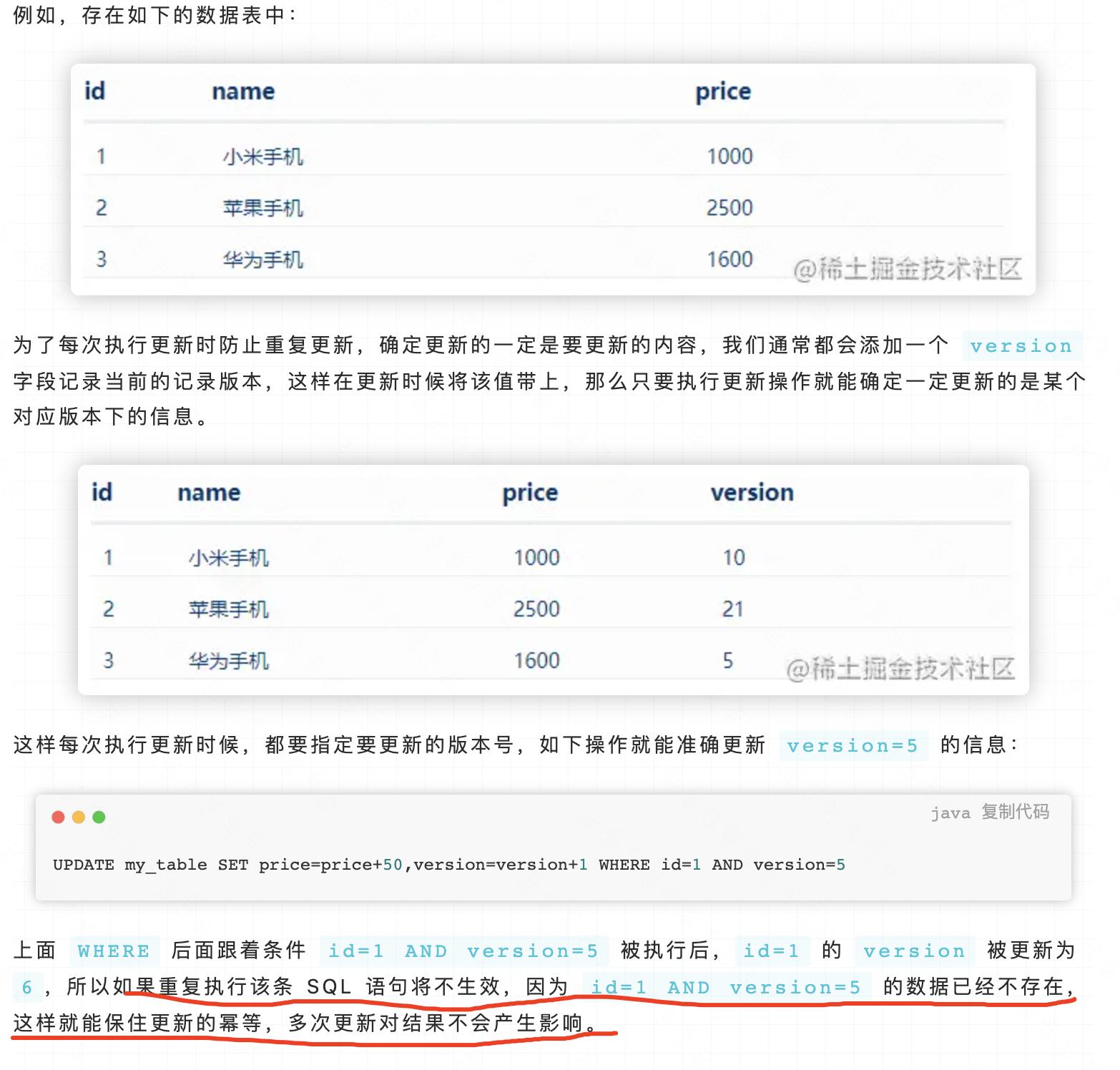
3.Token 令牌如何实现幂等性
所谓的 token 令牌其实就是为了防止用户重复提交一个表单信息,这一点基本上 php 的框架都会带有 token 验证。服务端需要生成一个全局唯一的 id,(例如:snowflake 雪花算法,美团 Leaf 算法,滴滴 TinyID 算法,百度 Uidgenerator 算法,uuid,redis 等)。
- 客户端每次进入表单页面可以优先申请一个唯一令牌存储本地,服务端存储令牌 token 值(redis,文件,memcache 都可)
- 每次发送请求时可以在 Headers 头部中带上当前这个 token 令牌
- 服务端验证 token 是否存在,存在则删除 token,执行后续业务逻辑;不存在则响应客户端重复提交提示语
如何实现全局唯一ID?
数据库自增ID
UUID 的生成
核心思想:结合机器的网卡(基于名字空间/名字的散列值MD5/SHA1)、当地时间(基于时间戳&时钟序列)、一个随记数来生成UUID。
雪花算法(snowflake)
核心思想:把 64-bit 分别划分成多段,分开来标示机器、时间、某一并发序列等,从而使每台机器及同一机器生成的ID都是互不相同
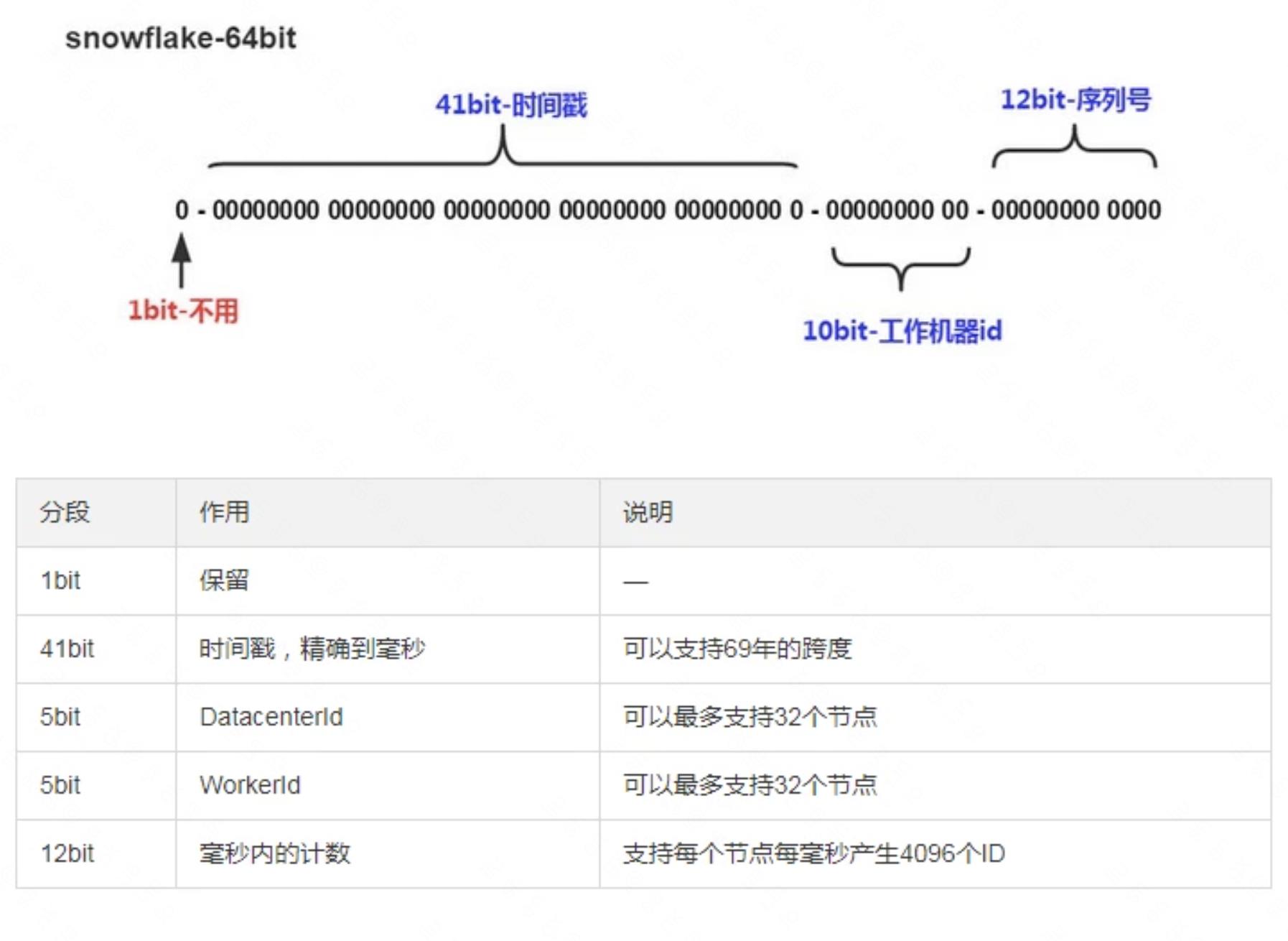
如何解决:时钟回拨(我的想法是添加随机数)
微服务架构下的若干常用设计模式
原文链接:https://www.toutiao.com/a6601430174107959811
在我们选择了用微服务架构来设计、交付数字化应用后,因微服务架构本身所带来的一些共性问题,比如各微服务团队之间的分工合作,数据存储,分布式事务,服务注册与发现等,必须得到很好的解决。幸运的是,我们已经有一些比较成熟的设计模式来解决上述问题。这些模式在我的一些项目中也有所应用。
一. 独立数据库设计模式
问题:
我们按照领域模型拆分了微服务,每个微服务由一个独立的团队负责开发
1. 我们希望这些微服务是松耦合的,能够独立部署,独立扩展
2. 某些情况下,不同的微服务有不同的数据存储要求,有的希望用SQL数据库,有的希望用No-SQL数据库
设计模式:
每一个微服务都拥有自己的数据库,一个微服务希望访问另外一个微服务的数据时,必须通过API访问,而不是通过数据库表的关联查询。
独立数据库设计模式
优点:
1. 微服务之间是松耦合的,某个微服务修改数据库表结构,不会影响其它微服务
2. 每个微服务都可以使用最符合自己需求的数据库
负面影响:
1. 跨数据库的数据查询需在应用程序本身完成,不能通过数据库表的关联查询完成
2. 处理跨多个微服务的事务是一个挑战
二. Saga设计模式
问题:
前面提到,当我们采用微服务模式,并且每个微服务都拥有自己独立的数据库,如何处理跨多个微服务的事务是一个挑战,即如何保证数据在多个微服务之间的一致性?
设计模式:
把一个跨多个微服务的长事务拆分成一个有多个本地事务的序列,即saga。每一个微服务更新本地数据库后发送一个事件到下一个微服务。如果其中一个微服务的事务失败,则触发一系列补偿事务,以取消前序微服务已完成的变更。
该设计模式有两种类型
无中心协调者saga模式:每一个微服务触发事件到下一个微服务,即每一个微服务知道自己要把事件送给哪些微服务
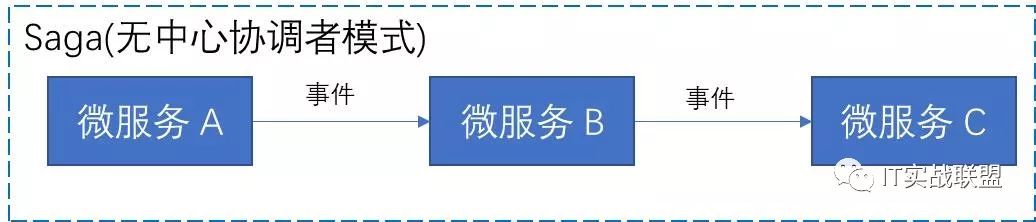
无中心协调者saga模式
有中心协调者saga模式:每一个微服务触发事件到中心协调者,由中心协调者确定发送什么指令到哪一个微服务。
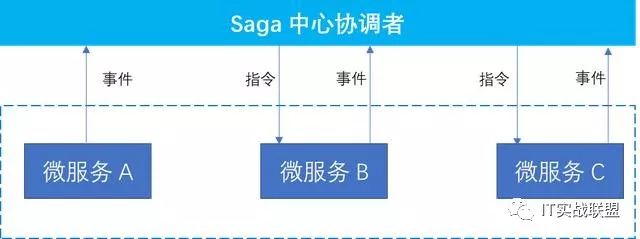
有中心协调者saga模式
优点:
无需使用复杂的分布式事务协议(如2PC,3PC)
负面影响:
编程比较复杂,每个微服务需要实现补偿事务,参与事务的方法还需要实现冥等
为保证本地业务数据更新后可靠的发送事件,需要额外的解决方案
三. 事件溯源Event sourcing设计模式
问题:
前面提到,在采用saga设计模式处理跨多个微服务的长事务时,如何保证本地业务数据更新后可靠的发送事务?目前还没有一个成熟的机制来保证数据库(如MySQL)和消息队列服务(如RabbitMQ)之间的事务一致性。
设计模式:
在业务数据发生变化的时候,把触发改变化的事件记录到Event store事件表中,同时发送事件到事件总线(如RabbitMQ)。微服务定期扫描Event store事件表,对发送失败的事件重发。同时,因为Event store中保存了业务数据变化的所有事件,我们可以通过回放事件获取业务数据在任何时刻的状态。若希望在保存事件的同时,同步更新本地业务数据的最终状态,可以通过数据库的事务来确保两个数据操作的事务一致性。
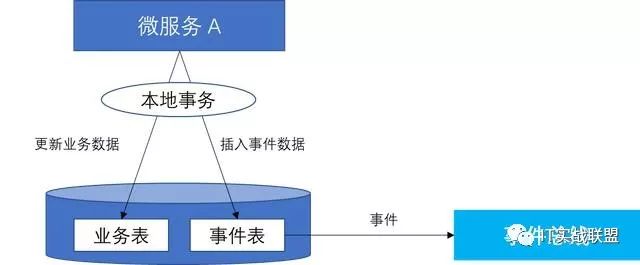
事件溯源Event sourcing设计模式
优点:
解决了在事件驱动架构中可靠发送事件的问题
100%记录业务数据变化事件,可以通过事件回放追溯业务数据在任一时刻点的状态
负面影响:
编程更复杂
查询业务最终状态时,需要回溯业务数据的所有事件,导致查询效率低下,需要通过其他方法解决。
四. CQRS设计模式
问题:
当我们采用微服务架构,每个微服务都有自己独立的数据库,我们无法通过数据库表的关联查询实现跨微服务数据库的多表查询,甚至我们采用事件溯源设计模式,我们只保存了改变业务数据的事件,如何实现数据的高效查询?
设计模式:
把应用分成两部分,命令部分和查询部分。命令部分负责数据的增,删,修改,同时负责在业务数据变化的时候发送事件;查询部分负责数据的查询,同时负责监听业务数据变化事件,更新业务数据最新状态。
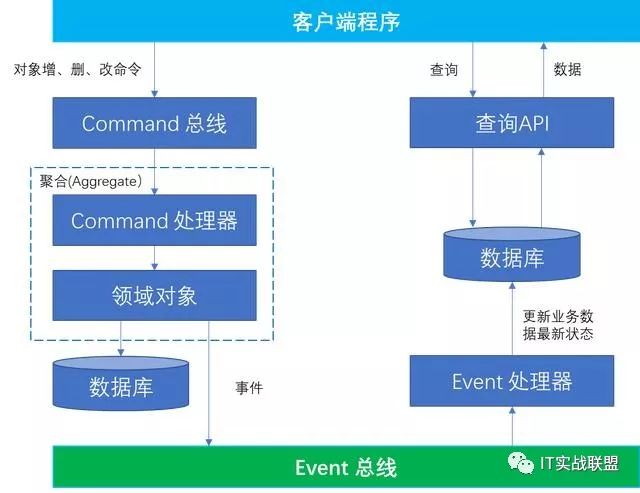
CQRS设计模式
优点:
在采用微服务架构后,提升查询效率
改进业务数据变化的命令模型和业务数据检索时的查询模型
负面影响:
增加了编程的复杂性
可能会有冗余数据和重复代码
复制延迟,最终一致的数据视图
五. API网关设计模式
问题:
当采用微服务架构后,客户端如何访问后台服务,客户端开发人员如何知道后台提供了哪些服务?
设计模式:
客户端通过API 网关访问后台服务
API网关设计模式
优点:
常见的API 网关除了把客户端请求路由到对应的微服务外,还提供安全,限流,监控等功能,同时也支持微服务开发者描述API的能力
负面影响:
增加了额外的网络时延-虽然对于大多数应用来说,这点网络时延对用户体验来说根本感觉不出来。
除了上面描述的5个常用设计模式,在微服务架构下还有以下设计模式也是经常用到的:
日志聚集设计模式: 把所有微服务产生的日志集中到一起,便于查询,比如开源的ELK,商业的Splunk都提供日志聚集解决方案。
分布式追踪设计模式:当客户端调用微服务的时候,生成一个唯一的trace id,用于跟踪客户端每一次后台API调用经历的所有微服务极其日志。每个微服务的日志都记录这个trace id及这次调用的开始结束时间和其它日志。
---------------END----------------
后续的内容同样精彩
长按关注“IT实战联盟”哦
以上是关于常用服务设计的主要内容,如果未能解决你的问题,请参考以下文章