Javascript常见性能优化
Posted togoog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Javascript常见性能优化相关的知识,希望对你有一定的参考价值。
俗话说,时间就是生命,时间就是金钱,时间就是一切,人人都不想把时间白白浪费,一个网站,最重要的就是体验,而网站好不好最直观的感受就是这个网站打开速度快不快,卡不卡.
当打开一个购物网站卡出翔,慢的要死,是不是如同心塞一样的感受,蓝瘦香菇,想买个心爱的宝贝都不能买,心里想这尼玛什么玩意.

那么如何让我们的网站给用户最佳的体验呢?大环境我们不说,什么网络啊,浏览器性能啊,这些我们无法改变,我们能改变的就是我们码农能创造的,那就是代码的性能.代码精简,执行速度快,嵌套层数少等等都是我们可以着手优化注意的地方.
恰巧最近刚看完**《高性能javascript》收获颇丰,今天就以点带面从追求高性能JavaScript的目的书写的代码来感受一下速度提升带来的体验,从编程实践,代码优化的角度总结一下自己平时遇到、书中以及其他地方看到有关提高JavaScript性能的例子,其他关于加载和执行,数据存取,浏览器中的DOM,算法和流程控制,字符串和正则表达式,快速响应的用户界面,Ajax**这些大范围的方向这里就不多加阐述.我们从代码本身出发,用数据说话,挖掘那些细思极恐的效率.有的提升可能微不足道,但是所有的微不足道聚集在一起就是一个从量到质变.

比较宽泛的阐释高性能JavaScript,从大体上了解提高JavaScript性能的有几个大方面,可以阅读这两篇文章作详细了解:
本文只从代码和数据上阐述具体说明如何一步步提高JavaScript的性能.
Javascript是一门非常灵活的语言,我们可以随心所欲的书写各种风格的代码,不同风格的代码也必然也会导致执行效率的差异,作用域链、闭包、原型继承、eval等特性,在提供各种神奇功能的同时也带来了各种效率问题,用之不慎就会导致执行效率低下,开发过程中零零散散地接触到许多提高代码性能的方法,整理一下平时比较常见并且容易规避的问题。
算法和流程控制的优化
循坏
你一天(一周)内写了多少个循环了?
我们先以最简单的循环入手作为切入点,这里我们只考虑单层循环以及比较不同循环种类和不同流程控制的效率.
测试数据:[1,2,3,...,10000000]
测试依据:数组[1,2,3,\'\'\',10000000]的累加所需要的时间
测试环境:node版本v6.9.4环境的v8引擎
为什么不在浏览器控制台测试?
首先不同浏览器的不同版本性能可能就不一样,这里为了统一,我选择了node环境,为什么不选择浏览器而选择了node环境测试,这是因为浏览器的一部分原因.
因为用控制台是测不出性能的,因为控制台本质上是个套了一大堆安全机制的eval,它的沙盒化程度很高。这里我们就一个简单的例子来对比一下,浏览器和node环境同样的代码的执行效率.
测试的数组代码:
var n = 10000000;
// 准备待测数组
var arr = [];
for(var count=0;count<n;count++){
arr[count] = 1;
}
// for 测试
console.time(\'for\');
for(var i=0;i<arr.length;i++){
arr[i];
}
console.timeEnd(\'for\');
就想简单测试一下这段生成待测数组所消耗时间的对比:
这是最新谷歌浏览器控制台的执行结果:
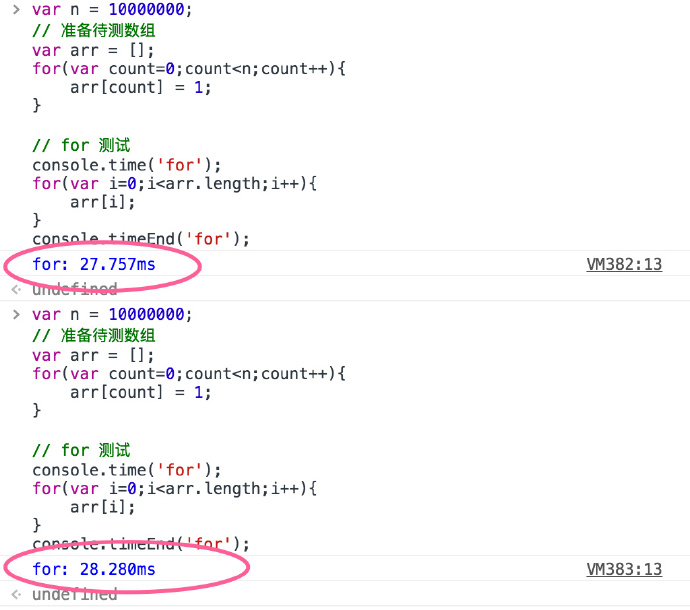
时间大约在28ms左右.
我们再来在node环境下测试一下所需要的时间:
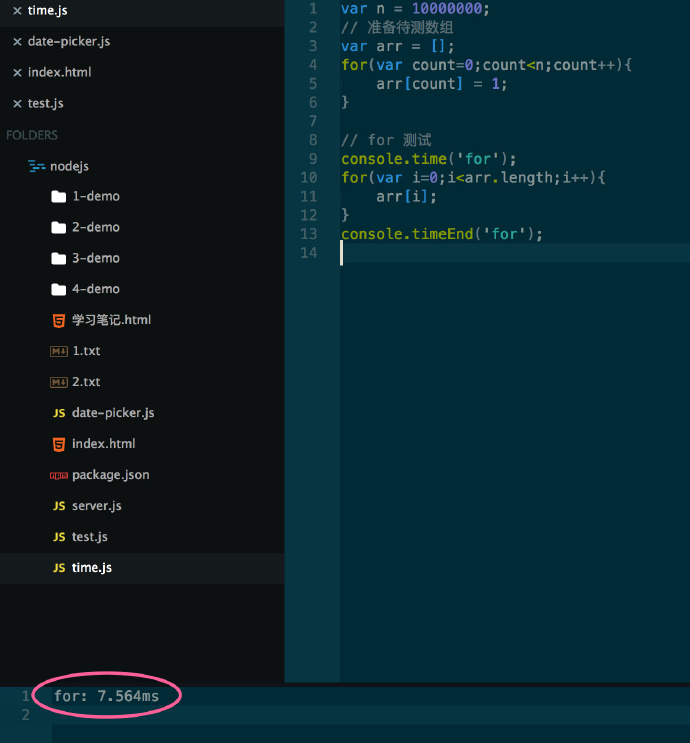
时间稳定在7ms左右,大约3倍的差距,同样都是v8引擎,浏览器就存在很明显的差距,这是由于浏览器的机制有关,浏览器要处理的事情远远比单纯在node环境下执行代码处理的事情多,所以用浏览器测试性能没有在单纯地node环境下靠谱.
具体细节和讨论可以参看知乎上的这篇RednaxelaFX的回答:
为何浏览器控制台的JavaScript引擎性能这么差?
各个循环实现的测试代码,每个方法都会单独执行,一起执行会有所偏差.
// for 测试(for和while其实差不多,这里我们只测试for循环)
console.time(\'for\');
for (var i = 0; i < arr.length; i++) {
arr[i];
}
console.timeEnd(\'for\');
// for loop测试
console.time(\'for\');
var sum = 0;
for (var i = 0; i < arr.length; i++) {
sum += arr[i];
}
console.timeEnd(\'for\');
// for loop缓存测试
console.time(\'for cache\');
var sum = 0;
var len = arr.length;
for (var i = 0; i < len; i++) {
sum += arr[i];
}
console.timeEnd(\'for cache\');
// for loop倒序测试
console.time(\'for reverse\');
var sum = 0;
var len = arr.length;
for (i = len-1;i>0; i--) {
sum += arr[i];
}
console.timeEnd(\'for reverse\');
//forEach测试
console.time(\'forEach\');
var sum = 0;
arr.forEach(function(ele) {
sum += ele;
})
//这段代码看起来更加简洁,但这种方法也有一个小缺陷:你不能使用break语句中断循环,也不能使用return语句返回
到外层函数。
console.timeEnd(\'forEach\');
//ES6的for of测试
console.time(\'for of\');
var sum = 0;
for (let i of arr) {
sum += i;
}
console.timeEnd(\'for of\');
//这是最简洁、最直接的遍历数组元素的语法
//这个方法避开了for-in循环的所有缺陷
//与forEach()不同的是,它可以正确响应break、continue和return语句
// for in 测试
console.time(\'for in\');
var sum=0;
for(var i in arr){
sum+=arr[i];
}
console.timeEnd(\'for in\');
最后在node环境下各自所花费的不同时间:
| 循环类型 | 耗费时间(ms) |
|---|---|
| for | 约11.998 |
| for cache | 约10.866 |
| for 倒序 | 约11.230 |
| forEach | 约400.245 |
| for in | 约2930.118 |
| for of | 约320.921 |
从上面的表格统计比较可以看出,前三种原始的for循坏一个档次,然后forEach和for of也基本属于一个档次,for of的执行速度稍微高于forEach,最后最慢的就是for in循环了,差的不是几十倍的关系了.
看起来好像是那么回事哦!
同样是循坏为什么会有如此大的悬殊呢?我们来稍微分析一下其中的个别缘由导致这样的差异.
for in 一般是用在对象属性名的遍历上的,由于每次迭代操作会同时搜索实例本身的属性以及原型链上的属性,所以效率肯定低下.
for...in实际上效率是最低的。这是因为 for...in有一些特殊的要求,具体包括:
1. 遍历所有属性,不仅是 ownproperties 也包括原型链上的所有属性。
2. 忽略 enumerable 为 false 的属性。
3. 必须按特定顺序遍历,先遍历所有数字键,然后按照创建属性的顺序遍历剩下的。
这里既然扯到对象的遍历属性,就顺便扯一扯几种对象遍历属性不同区别,为什么for...in性能这么差,算是一个延伸吧,反正我发现写一篇博客可以延伸很多东西,自己也可以学到很多,还可以巩固自己之前学过但是遗忘的一些东西,算是温故而知新.
遍历数组属性目前我知道的有:for-in循环、Object.keys()和Object.getOwnPropertyNames(),那么三种到底有啥区别呢?
for-in循环:会遍历对象自身的属性,以及原型属性,包括enumerable 为 false(不可枚举属性);
Object.keys():可以得到自身可枚举的属性,但得不到原型链上的属性;
Object.getOwnPropertyNames():可以得到自身所有的属性(包括不可枚举),但得不到原型链上的属性,Symbols属性
也得不到.
Object.defineProperty顾名思义,就是用来定义对象属性的,vue.js的双向数据绑定主要在getter和setter函数里面插入一些处理方法,当对象被读写的时候处理方法就会被执行了。 关于这些方法和属性的更具体解释,可以看MDN上的解释(戳我);
简单看一个小demo例子加深理解,对于Object.defineProperty属性不太明白,可以看看上面介绍的文档学习补充一下.
\'use strict\';
class A {
constructor() {
this.name = \'jawil\';
}
getName() {}
}
class B extends A {
constructor() {
super();
this.age = 22;
}
//getAge不可枚举
getAge() {}
[Symbol(\'fullName\')]() {
}
}
B.prototype.get = function() {
}
var b = new B();
//设置b对象的info属性的enumerable: false,让其不能枚举.
Object.defineProperty(b, \'info\', {
value: 7,
writable: true,
configurable: true,
enumerable: false
});
//Object可以得到自身可枚举的属性,但得不到原型链上的属性
console.log(Object.keys(b)); //[ \'name\', \'age\' ]
//Object可A以得到自身所有的属性(包括不可枚举),但得不到原型链上的属性,Symbols属性也得不到
console.log(Object.getOwnPropertyNames(b)); //[ \'name\', \'age\', \'info\' ]
for (var attr in b) {
console.log(attr);//name,age,get
}
//in会遍历对象自身的属性,以及原型属性
console.log(\'getName\' in b); //true
从这里也可以看出为什么for...in性能这么慢,因为它要遍历自身的属性和原型链上的属性,这无疑就增加了所有不必要的额外开销.
目前绝大部分开源软件都会在for loop中缓存数组长度,因为普通观点认为某些浏览器Array.length每次都会重新计算数组长度,因此通常用临时变量来事先存储数组长度,以此来提高性能.
而forEach是基于函数的迭代(需要特别注意的是所有版本的ie都不支持,如果需要可以用JQuery等库),对每个数组项调用外部方法所带来的开销是速度慢的主要原因.
总结:
1.能用for缓存的方法循环就用for循坏,性能最高,写起来繁杂;
2.不追求极致性能的情况下,建议使用forEach方法,干净,简单,易读,短,没有中间变量,没有成堆的分号,简单非常
优雅;
3.想尝鲜使用ES6语法的话,不考虑兼容性情况下,推荐使用for of方法,这是最简洁、最直接的遍历数组元素的语法,该方
法避开了for-in;循环的所有缺陷与forEach()不同的是,它可以正确响应break、continue和return语句.
4.能避免for in循环尽量避免,太消费性能,太费时间,数组循环不推荐使用.
条件语句
常见的条件语句有if-else和switch-case,那么什么时候用if-else,什么时候用switch-case语句呢?
我们先来看个简单的if-else语句的代码:
if (value == 0){
return result0;
} else if (value == 1){
return result1;
} else if (value == 2){
return result2;
} else if (value == 3){
return result3;
} else if (value == 4){
return result4;
} else if (value == 5){
return result5;
} else if (value == 6){
return result6;
} else if (value == 7){
return result7;
} else if (value == 8){
return result8;
} else if (value == 9){
return result9;
} else {
return result10;
}
最坏的情况下(value=10)我们可能要做10次判断才能返回正确的结果,那么我们怎么优化这段代码呢?一个显而易见的优化策略是将最可能的取值提前判断,比如value最可能等于5或者10,那么将这两条判断提前。但是通常情况下我们并不知道(最可能的选择),这时我们可以采取二叉树查找策略进行性能优化。
if (value < 6){
if (value < 3){
if (value == 0){
return result0;
} else if (value == 1){
return result1;
} else {
return result2;
}
} else {
if (value == 3){
return result3;
} else if (value == 4){
return result4;
} else {
return result5;
}
}
} else {
if (value < 8){
if (value == 6){
return result6;
} else {
return result7;
}
} else {
if (value == 8){
return result8;
} else if (value == 9){
return result9;
} else {
return result10;
}
}
}
这样优化后我们最多进行4次判断即可,大大提高了代码的性能。这样的优化思想有点类似二分查找,和二分查找相似的是,只有value值是连续的数字时才能进行这样的优化。但是代码这样写的话不利于维护,如果要增加一个条件,或者多个条件,就要重写很多代码,这时switch-case语句就有了用武之地。
将以上代码用switch-case语句重写:
switch(value){
case 0:
return result0;
case 1:
return result1;
case 2:
return result2;
case 3:
return result3;
case 4:
return result4;
case 5:
return result5;
case 6:
return result6;
case 7:
return result7;
case 8:
return result8;
case 9:
return result9;
default:
return result10;
}
swtich-case语句让代码显得可读性更强,而且swtich-case语句还有一个好处是如果多个value值返回同一个结果,就不用重写return那部分的代码。一般来说,当case数达到一定数量时,swtich-case语句的效率是比if-else高的,因为switch-case采用了branch table(分支表)索引来进行优化,当然各浏览器的优化程度也不一样。
相对来说,下面几种情况更适合使用switch结构:
枚举表达式的值。这种枚举是可以期望的、平行逻辑关系的。
表达式的值具有离散性,不具有线性的非连续的区间值。
表达式的值是固定的,不是动态变化的。
表达式的值是有限的,而不是无限的,一般情况下表达式应该比较少。
表达式的值一般为整数、字符串等类型的数据。
而if结构则更适合下面的一些情况:
具有复杂的逻辑关系。
表达式的值具有线性特征,如对连续的区间值进行判断。
表达式的值是动态的。
测试任意类型的数据。
除了if-else和swtich-case外,我们还可以采用查找表。
var results = [result0, result1, result2, result3, result4, result5, result6, result7,
result8, result9, result10];
//return the correct result
return results[value];
当数据量很大的时候,查找表的效率通常要比if-else语句和swtich-case语句高,查找表能用数字和字符串作为索引,而如果是字符串的情况下,最好用对象来代替数组。当然查找表的使用是有局限性的,每个case对应的结果只能是一个取值而不能是一系列的操作。
从根源上分析if else 和 switch的效率,之前只知道if else 和switch算法实现不同,但具体怎么样就不清楚了,为了刨根问底,翻阅了很多资料,但无奈找到了原因我还是不太懂,只知道就是这么回事,不懂汇编,懂底层汇编的大神还望多加指点.
想要深入从汇编的角度了解可以看看这篇文章:switch...case和if...else效率比较
学前端的我想问你汇编是啥?能吃吗?

在选择分支较多时,选用switch...case结构会提高程序的效率,但switch不足的地方在于只能处理字符或者数字类型的变量,if...else结构更加灵活一些,if...else结构可以用于判断表达式是否成立,比如if(a+b>c),if...else的应用范围更广,switch...case结构在某些情况下可以替代if...else结构。
小结:
1. 当只有两个case或者case的value取值是一段连续的数字的时候,我们可以选择if-else语句;
2. 当有3~10个case数并且case的value取值非线性的时候,我们可以选择switch-case语句;
3. 当case数达到10个以上并且每次的结果只是一个取值而不是额外的JavaScript语句的时候,我们可以选择查找表.
事件委托减少循环绑定的事件
什么是事件委托:通俗的讲,事件就是onclick,onmouseover,onmouseout,等就是事件,委托呢,就是让别人来做,这个事件本来是加在某些元素上的,然而你却加到别人身上来做,完成这个事件。
也就是:利用冒泡的原理,把事件加到父级上,触发执行效果。
好处呢:
1.提高性能。
2.新添加的元素还会有之前的事件。
试想一下,一个页面上ul的每一个li标签添加一个事件,我们会不会给每一个标签都添加一个onclick呢。 当页面中存在大量元素都需要绑定同一个事件处理的时候,这种情况可能会影响性能,不仅消耗了内存,还多循环时间。每绑定一个事件都加重了页面或者是运行期间的负担。对于一个富前端的应用,交互重的页面上,过多的绑定会占用过多内存。 一个简单优雅的方式就是事件委托。它是基于事件的工作流:逐层捕获,到达目标,逐层冒泡。既然事件存在冒泡机制,那么我们可以通过给外层绑定事件,来处理所有的子元素出发的事件。
一个事件委托的简单实现:
document.getElementById(\'ulId\').onclick = function(e) {
var e = e || window.event;
var target = e.target || e.srcElement; //兼容旧版本IE和现代浏览器
if (target.nodeName.toLowerCase() !== \'ul\') {
return;
}
console.log(target.innerhtml);
}
我们可以看一个例子:需要触发每个li来改变他们的背景颜色。
<ul id="ul">
<li>1</li>
<li>2</li>
<li>3</li>
</ul>
首先想到最直接的实现:
window.onload = () => {
let oUl = document.querySelector("#ul");
let aLi = oUl.querySelectorAll("li");
Array.from(aLi).forEach(ele => {
ele.onmouseover = function() {
this.style.background = "red";
}
ele.onmouseout = function() {
this.style.background = "";
}
})
}
这样我们就可以做到li上面添加鼠标事件。
但是如果说我们可能有很多个li用for循环的话就比较影响性能。
下面我们可以用事件委托的方式来实现这样的效果。html不变
window.onload = () => {
let oUl = document.querySelector("#ul");
/*
这里要用到事件源:event 对象,事件源,不管在哪个事件中,只要你操作的那个元素就是事件源。
ie:window.event.srcElement
标准下:event.target
nodeName:找到元素的标签名
*/
//虽然习惯用ES6语法写代码,这里事件还是兼容一下IE吧
oUl.onmouseover = ev => {
ev = ev || window.event;
let target = ev.target || ev.srcElement;
//console.log(target.innerHTML);
if (target.nodeName.toLowerCase() === "li") {
target.style.background = "red";
}
}
oUl.onmouseout = ev=> {
ev = ev || window.event;
let target = ev.target || ev.srcElement;
//console.log(target.innerHTML);
if (target.nodeName.toLowerCase() == "li") {
target.style.background = "";
}
}
}
好处2,新添加的元素还会有之前的事件。
我们还拿这个例子看,但是我们要做动态的添加li。点击button动态添加li
<input type="button" id="btn" />
<ul id="ul">
<li>1</li>
<li>2</li>
<li>3</li>
</ul>
不用事件委托我们会这样做:
window.onload = () => {
let oUl = document.querySelector("#ul");
let aLi = oUl.querySelectorAll("li");
let oBtn = document.querySelector("#btn");
let iNow = 4;
//刚才用forEach实现,现在就用性能最高的for实现,把刚才学的温习一下
for (let i = 0, len = aLi.length; i < len; i++) {
aLi[i].onmouseover = function() {
this.style.background = "red";
}
aLi[i].onmouseout = function() {
this.style.background = "";
}
}
oBtn.onclick = function() {
iNow++;
let oLi = document.createElement("li");
oLi.innerHTML = 1* iNow;
oUl.appendChild(oLi);
}
}
这样做我们可以看到点击按钮新加的li上面没有鼠标移入事件来改变他们的背景颜色。
因为点击添加的时候for循环已经执行完毕。
那么我们用事件委托的方式来做。就是html不变
window.onload = () => {
let oUl = document.querySelector("#ul");
let oBtn = document.querySelector("#btn");
let iNow = 4;
oUl.onmouseover = ev => {
ev = ev || window.event;
let target = ev.target || ev.srcElement;
if (target.nodeName.toLowerCase() === "li") {
target.style.background = "red";
}
}
oUl.onmouseout = ev => {
ev = ev || window.event;
let target = ev.target || ev.srcElement;
if (target.nodeName.toLowerCase() == "li") {
target.style.background = "";
}
}
oBtn.onclick = function() {
iNow++;
let oLi = document.createElement("li");
oLi.innerHTML = 1111 * iNow;
oUl.appendChild(oLi);
}
}
更快速的数据访问
对于浏览器来说,一个标识符所处的位置越深,去读写他的速度也就越慢(对于这点,原型链亦是如此)。这个应该不难理解,简单比喻就是:杂货店离你家越远,你去打酱油所花的时间就越长... 熊孩子,打个酱油那么久,菜早烧焦了 -.-~
我们在编码过程中多多少少会使用到一些全局变量(window,document,自定义全局变量等等),了解javascript作用域链的人都知道,在局部作用域中访问全局变量需要一层一层遍历整个作用域链直至顶级作用域,而局部变量的访问效率则会更快更高,因此在局部作用域中高频率使用一些全局对象时可以将其导入到局部作用域中,例如:
对比看看:
//修改前
function showLi(){
var i = 0;
for(;i<document.getElementsByTagName("li").length;i++){ //一次访问document
console.log(i,document.getElementsByTagName("li")[i]); //三次访问document
};
};
//修改后
function showLi(){
var li_s = document.getElementsByTagName("li"); //一次访问document
var i = 0;
for(;i<li_s.length;i++){
console.log(i,li_s[i]); //三次访问局部变量li_s
};
};
再来看看两个简单的例子;
//1、作为参数传入模块
(function(window,$){
var xxx = window.xxx;
$("#xxx1").xxx();
$("#xxx2").xxx();
})(window,jQuery);
//2、暂存到局部变量
function(){
var doc = document;
var global = window.global;
}
eval以及类eval问题
我们都知道eval可以将一段字符串当做js代码来执行处理,据说使用eval执行的代码比不使用eval的代码慢100倍以上(具体效率我没有测试,有兴趣同学可以测试一下),前面的浏览器控制台效率低下也提到eval这个问题.
JavaScript 代码在执行前会进行类似“预编译”的操作:首先会创建一个当前执行环境下的活动对象,并将那些用 var
申明的变量设置为活动对象的属性,但是此时这些变量的赋值都是 undefined,并将那些以 function 定义的函数也
添加为活动对象的属性,而且它们的值正是函数的定义。但是,如果你使用了“eval”,则“eval”中的代码(实际上为字
符串)无法预先识别其上下文,无法被提前解析和优化,即无法进行预编译的操作。所以,其性能也会大幅度降低
对上面js的预编译,活动对象等一些列不太明白的童鞋.看完这篇文章恶补一下,我想你会收获很多:前端基础进阶(三):变量对象详解
其实现在大家一般都很少会用eval了,这里我想说的是两个类eval的场景(new Function{},setTimeout,
setInterver)
setTimtout("alert(1)",1000);
setInterver("alert(1)",1000);
(new Function("alert(1)"))();
上述几种类型代码执行效率都会比较低,因此建议直接传入匿名方法、或者方法的引用给setTimeout方法.
DOM操作的优化
众所周知的,DOM操作远比javascript的执行耗性能,虽然我们避免不了对DOM进行操作,但我们可以尽量去减少该操作对性能的消耗。
为什么操作DOM这么耗费性能呢?
浏览器通常会把js和DOM分开来分别独立实现。
举个栗子冷知识,在IE中,js的实现名为JScript,位于jscript.dll文件中;DOM的实现则存在另一个库中,名为mshtml.dll(Trident)。
Chrome中的DOM实现为webkit中的webCore,但js引擎是Google自己研发的V8。
Firefox中的js引擎是SpiderMonkey,渲染引擎(DOM)则是Gecko。
DOM,天生就慢
前面的小知识中说过,浏览器把实现页面渲染的部分和解析js的部分分开来实现,既然是分开的,一旦两者需要产生连接,就要付出代价。
两个例子:
- 小明和小红是两个不同学校的学生,两个人家里经济条件都不太好,买不起手机(好尴尬的设定Orz...),所以只能通过写信来互相交流,这样的过程肯定比他俩面对面交谈时所需要花费的代价大(额外的事件、写信的成本等)。
- 官方例子:把DOM和js(ECMAScript)各自想象为一座岛屿,它们之间用收费桥进行连接。ECMAScript每次访问DOM,都要途径这座桥,并交纳“过桥费”。访问DOM的次数越多,费用也就越高。
因此,推荐的做法是:尽可能的减少过桥的次数,努力待在ECMAScript岛上。
让我们通过一个最简单的代码解释这个问题:
function innerLi_s(){
var i = 0;
for(;i<20;i++){
document.getElementById("Num").innerHTML="A";
//进行了20次循环,每次又有2次DOM元素访问:一次读取innerHTML的值,一次写入值
};
};
针对以上方法进行一次改写:
function innerLi_s(){
var content ="";
var i = 0;
for(;i<20;i++){
content += "A"; //这里只对js的变量循环了20次
};
document.getElementById("Num").innerHTML += content;
//这里值进行了一次DOM操作,又分2次DOM访问:一次读取innerHTML的值,一次写入值
};
减少页面的重排(Reflows)和重绘(Repaints)
简单说下什么是重排和重绘:
浏览器下载完HTMl,CSS,JS后会生成两棵树:DOM树和渲染树。 当Dom的几何属性发生变化时,比如Dom的宽高,或者颜色,position,浏览器需要重新计算元素的几何属性,并且重新构建渲染树,这个过程称之为重绘重排。
元素布局的改变或内容的增删改或者浏览器窗口尺寸改变都将会导致重排,而字体颜色或者背景色的修改则将导致重绘。
对于类似以下代码的操作,据说现代浏览器大多进行了优化(将其优化成1次重排版):
//修改前
var el = document.getElementById("div");
el.style.borderLeft = "1px"; //1次重排版
el.style.borderRight = "2px"; //又1次重排版
el.style.padding = "5px"; //还有1次重排版
//修改后
var el = document.getElementById("div");
el.style.cssText = "border-left:1px;border-right:2px;padding:5px"; //1次重排版
针对多重操作,以下三种方法也可以减少重排版和重绘的次数:
- Dom先隐藏,操作后再显示 2次重排 (临时的display:none);
- document.createDocumentFragment() 创建文档片段处理,操作后追加到页面 1次重排;
- var newDOM = oldDOM.cloneNode(true)创建Dom副本,修改副本后oldDOM.parentNode.replaceChild
(newDOM,oldDOM)覆盖原DOM 2次重排 - 如果是动画元素的话,最好使用绝对定位以让它不在文档流中,这样的话改变它的位置不会引起页面其它元素重排
更多DOM优化的细节以及关于浏览器页面的**重排(Reflows)和重绘(Repaints)**的概念和优化请参考:天生就慢的DOM如何优化?,花10+分钟阅读,你会受益匪浅.
尽量少去改变作用域链
- 使用with
- try catch
我了解到的JavaScript中改变作用域链的方式只有两种1)使用with表达式 2)通过捕获异常try catch来实现
但是with是大家都深恶痛绝的影响性能的表达式,因为我们完全可以通过使用一个局部变量的方式来取代它(因为with的原理是它的改变作用域链的同时需要保存很多信息以保证完成当前操作后恢复之前的作用域链,这些就明显的影响到了性能)
try catch中的catch子句同样可以改变作用域链。当try块发生错误时,程序自动转入catch块并将异常对象推入作用域链前端的一个可变对象中,也就是说在catch块中,函数所有的局部变量已经被放在第二个作用域链对象中,但是catch子句执行完成之后,作用域链就会返回到原来的状态。应该最小化catch子句来保证代码性能,如果知道错误的概念很高,我们应该尽量修正错误而不是使用try catch.
最后
虽说现代浏览器都已经做的很好了,但是本兽觉得这是自己对代码质量的一个追求。并且可能一个点或者两个点不注意是不会产生多大性能影响,但是从多个点进行优化后,可能产生的就会质的飞跃了
JavaScript 总结的这几个提高性能知识点,希望大家牢牢掌握。
参考文章:
高性能JavaScript循环语句和流程控制
if else 和 switch的效率
switch...case和if...else效率比较
JavaScript提高性能知识点汇总
JavaScript执行效率小结
天生就慢的DOM如何优化?
编写高性能的JavaScript代码
以上是关于Javascript常见性能优化的主要内容,如果未能解决你的问题,请参考以下文章