TPS Motion(CVPR2022)视频生成论文解读
Posted ‘Atlas’
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TPS Motion(CVPR2022)视频生成论文解读相关的知识,希望对你有一定的参考价值。
文章目录
论文: 《Thin-Plate Spline Motion Model for Image Animation》
github: https://github.com/yoyo-nb/Thin-Plate-Spline-Motion-Model
解决问题
问题:
尽管当前有些工作使用无监督方法进可行任意目标姿态迁移,但是当源图与目标图差异大时,对当前无监督方案来说仍然具有挑战。
方法:
本文提出无监督TPS Motion,
1、提出thin-plate spline(TPS)运动估计,以生成更灵活光流,将源图特征迁移至目标图特征;
2、为了补全缺失区域,使用多分辨率遮挡mask进行有效特征融合。
3、额外辅助损失函数用于确保网络各模块分工,使得生成高质量图片;
算法
TPS Motion算法整体流程图如图2所示,
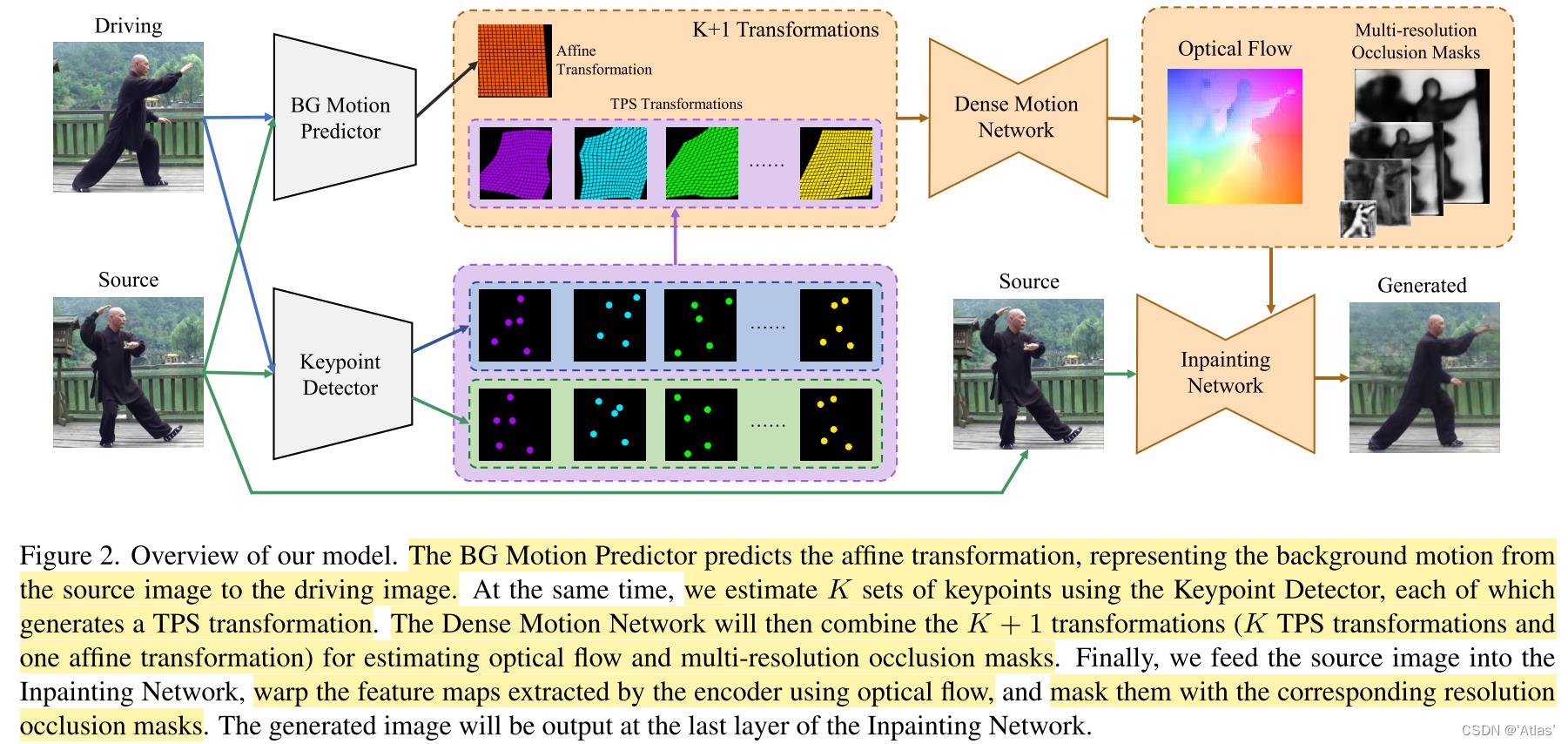
TPS Motion主要包括以下模块:
1、关键点检测模块
E
k
p
E_kp
Ekp:生成
K
∗
N
K*N
K∗N对关键点用于生成K个TPS变换;
2、背景运动预测
E
b
g
E_bg
Ebg:估计背景变换参数;
3、稠密运动网络(Dense Motion Network):这是一个hourglass网络,使用
E
b
g
E_bg
Ebg背景变换及
E
k
p
E_kp
Ekp的K的K个TPS变换进行光流估计、多分辨率遮挡mask预测,用于指导缺失区域;
4、修复网络(Inpainting Network):同为hourglass网络,使用预测光流扭曲原图特征图,修复每个尺度下特征图缺失区域;
TPS运动估计
1、通过TPS可通过最小扭曲,将原图变换到目标图,如式1,
P
i
X
表示图
X
上第
i
个关键点
P^X_i表示图X上第i个关键点
PiX表示图X上第i个关键点;

E
k
p
E_kp
Ekp使用
K
∗
N
K*N
K∗N个关键点,计算k个tps变换,每个使用N个关键点(N=5),TPS计算如式2,
p
为坐标,
A
与
w
为式
1
求解到的系数,
U
为偏置项
p为坐标,A与w为式1求解到的系数,U为偏置项
p为坐标,A与w为式1求解到的系数,U为偏置项,
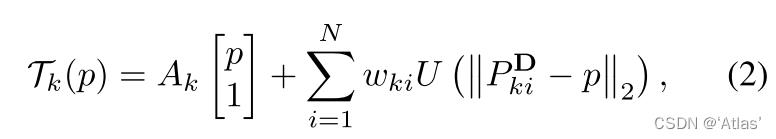
2、背景变换矩阵如式4,其中
A
b
g
A_bg
Abg由背景运动预测器
E
b
g
E_bg
Ebg生成;
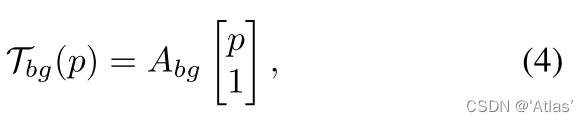
3、通过Dense Motion Network将K+1个变换预测contribution map
M
~
∈
R
(
K
+
1
)
×
H
×
W
\\tilde M \\in R^(K+1)\\times H \\times W
M~∈R(K+1)×H×W,经过softmax得到
M
M
M,如式5,

将其与K+1个变换结合计算光流,如式6,
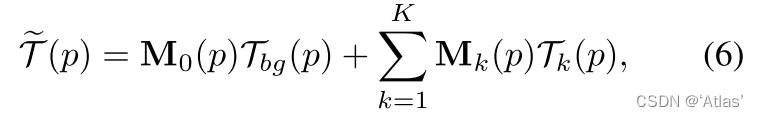
由于训练初期仅有部分TPS变换起作用,由此导致contribution map有的地方为0,因此训练时容易陷入局部最优;
作者使用dropout使得某些contribution map为0,将式5改为式7,
b
i
服从伯努利分布,概率为
1
−
P
b_i服从伯努利分布,概率为1-P
bi服从伯努利分布,概率为1−P,使得网络不会过度依赖某些TPS变换,训练几个epoch后,作者将其去除;
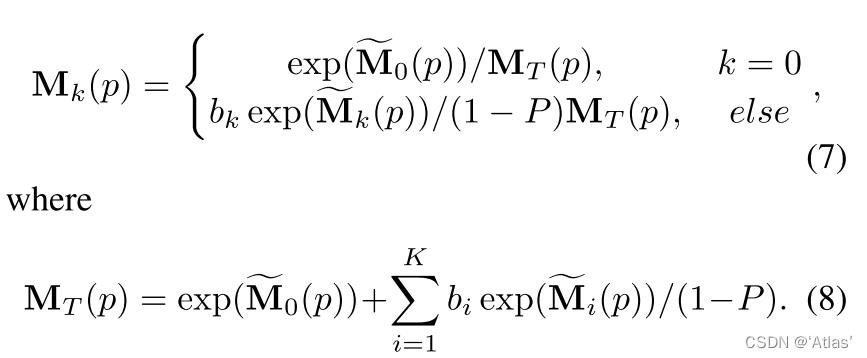
4、修复网络(Inpainting Network)的编码器提取原图特征进行变换,解码器进行重构目标图;
多分辨率遮挡Mask
一些论文证明,不同尺度特征图关注区域有区别,低分辨率关注抽象形态,高分辨率关注细节纹理;因此作者在每层进行预测遮挡mask;
Dense Motion Network除了预测光流还预测多分辨率遮挡mask,通过在每层编码器添加一个额外的卷积层实现;

Inpaintting Network融合多尺度特征生成高质量图像,细节如图3所示;
1、将原图S送入编码器,光流
T
~
\\tilde T
T~用于变换每层特征图;
2、使用预测的遮挡mask进行遮挡变换后的特征图;
3、使用skip connection与浅层解码器输出concat;
4、通过两个残差网络及上采样层,生成最终图像;
训练损失函数
重构损失:使用VGG-19计算重构损失,如式9;
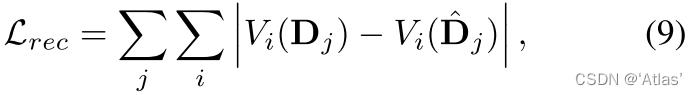
同变损失:用于约束关键点检测模块,如式10;
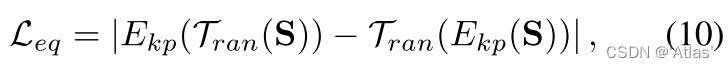
背景损失:用于约束背景Motion预测器,确保预测更加准确,
A
b
g
A_bg
Abg表示从S到D的背景仿射变换矩阵;
A
b
g
′
A'_bg
Abg′表示D到S的背景仿射变换矩阵,防止预测输出矩阵为0,loss未使用式11,而是式12;

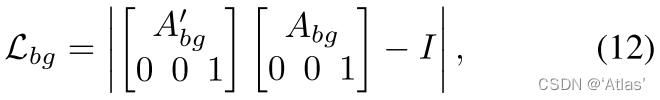
扭曲损失:用于约束Inpainting Network,使得估计光流更加可靠,如式13,Ei表示网络第i层编码器;
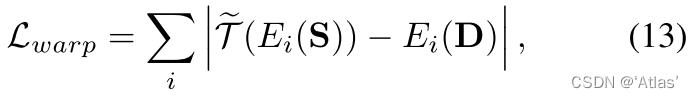
整体损失函数如式14
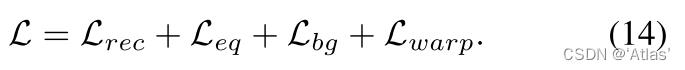
测试阶段
FOMM有两种模式:标准、相关;
前者使用驱动视频
D
t
D_t
Dt每一帧及S,依据式6估计motion,但当S与D差异大时(比如S与D中人体身材差异大),表现不佳;
后者用于估计
D
1
D_1
D1至
D
t
D_t
Dt的motion,将其应用于S,这要求
D
1
D_1
D1与S的pose接近;
MRAA提出一种新模式,通过解耦进行动画,额外训练网络进行预测motion,应用于S,本文使用相同模式;训练shape及pose编码器,shape编码器学习关键点S的shape,pose编码器学习关键点
D
t
D_t
Dt的pose,解码器重构关键点保留S的shape及
D
t
D_t
Dt的pose,训练过程中使用同一视频两帧,其中一帧关键点进行随机变换仿真另一个体的pose;
对于图像动画而言,将S及
D
t
D_t
Dt的关键点送入shape及pose编码器,经过解码器获取重构的关键点,根据式6估计motion。
实验
评估指标
L1表示驱动图与生成图像素L1距离;
Average keypoint distance (AKD)表示生成图与驱动图关键点距离;
Missing keypoint rate (MKR)表示驱动图中存在但是生成图中不存在的关键点比率;
Average Euclidean distance (AED)表示使用reid模型提取生成图与驱动图特征,比较两者之间L2损失;
视频重构结果如表1;
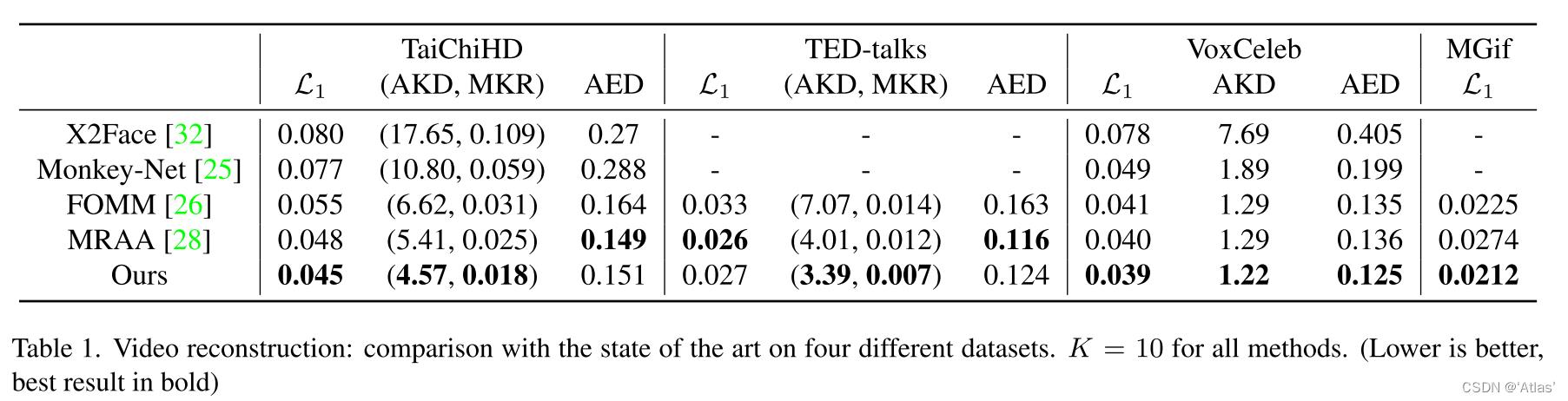
图6展示图像动画结果,在4个数据集上与MRAA比较,

表2展示真实用户在连续性及真实性上评价;

表4展示消融实验结果;

表3比较不同K对结果影响,FOMM、MRAA使用K=5,10,20;本文方式用2,4,8;

结论
作者提出的方无监督图像动画方法:
1、通过TPS估计光流,训练初期使用dropout,防止陷入局部最优;
2、多分辨率遮挡mask用于更有效特征融合;
3、设计额外辅助损失;
本文方法取得SOTA,但是当源图与驱动图人物身份极度不匹配时,效果不理想;
阿里云视频云人脸生成领域最新研究成果入选CVPR2022
CVPR(IEEE Conference on Computer Vision and Pattern Recognition)作为计算机视觉和模式识别领域的顶级会议,在全球具有极高的权威性。目前在中国计算机学会推荐国际学术会议的排名中,CVPR为人工智能领域的A类会议 。
凭借在人脸生成领域的扎实积累和前沿创新,阿里云视频云与香港科技大学合作的最新研究成果《基于生成对抗网络的深度感知人脸重演算法》(Depth-Aware Generative Adversarial Network for Talking Head Video Generation)被CVPR2022接收。
而最新一届CVPR 2022也将于2022年6月19日-24日在美国路易斯安那州新奥尔良举行。

近年来,人脸重演(face reenactment/talking head)受到了越来越广泛的关注,现有的人脸重演方法严重依赖于从输入图像中学习到的2D表征,而很少引入3D几何信息进行指导和约束 ,导致生成人脸的结构、姿态和表情不够准确,泛化性较差,难以大规模应用于实际场景中 。
阿里云视频云技术团队与香港科技大学联合提出一种具有深度感知的人脸重演算法。该算法的出现,是人脸重演领域的重大创新,其学术和应用价值是值得期待的。尤其是在视频云领域,该算法的应用有望使得音视频编解码的效率有着极大的突破。
算法使用一种自监督的深度估计模型,无需任何3D标注,即可从视频中获得像素级深度图,进而指导人脸关键点的检测和运动场的合成。在人脸生成阶段,利用该深度图可以学习得到跨模态注意力图,以捕捉更多动作细节并修正人脸结构。
因此,该项技术为在特定场景下的视频编解码提供了新的解决方案。例如在视频会议场景中,我们的模型学习使用一张包含目标人物外观的源图像和一段驱动视频来合成人物头部说话的视频。我们的运动是基于一种新的关键点表标注进行编码的,我们紧凑的关键点标注使视频会议系统能够实现与商业 H.264 标准相同的视觉质量,同时仅使用十分之一的带宽。即大幅度降低带宽要求时,仍可实现较高画质和低延迟。
除此之外,该项技术可广泛应用于会议、直播场景或者元宇宙、虚拟人等互动娱乐场景中,可满足各场景中图片视频化的需求。即按照预想动作,驱动各类风格的人脸图片获得对应的视频。可见,利用该技术路径的突破,灵活地应用到热点行业的业务路径中,将收获一股不可估量的助力。
「视频云技术」你最值得关注的音视频技术公众号,每周推送来自阿里云一线的实践技术文章,在这里与音视频领域一流工程师交流切磋。公众号后台回复【技术】可加入阿里云视频云产品技术交流群,和业内大咖一起探讨音视频技术,获取更多行业最新信息。
以上是关于TPS Motion(CVPR2022)视频生成论文解读的主要内容,如果未能解决你的问题,请参考以下文章
CVPR2022 前沿研究成果解读:基于生成对抗网络的深度感知人脸重演算法