业内视频超分辨率新标杆,快手&大连理工研究登上CVPR 2022
Posted QbitAl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了业内视频超分辨率新标杆,快手&大连理工研究登上CVPR 2022相关的知识,希望对你有一定的参考价值。
转载整理自 快手音视频技术
量子位 | 公众号 QbitAI
现在,视频超分辨率算法又迎来新突破。
一篇最新登上CVPR 2022的论文,从一种新的视角,统一了视频超分辨率中的低分辨率和高分辨率的时序建模思路。
论文提出一种新的视频超分辨率框架,以较小的计算代价,充分利用了低分辩和高分辨率下的时序互补信息,以此带来更多细节和纹理的超分辨率结果。

研究在多个公开数据集上达到了SOTA效果,也为后续的视频超分辨率研究提供了新的灵感。

文章地址:https://arxiv.org/abs/2204.07114
代码地址:https://github.com/junpan19/VSR_ETDM
视频超分辨率难在哪?
超分辨率是计算机视觉领域的经典技术,利用图像的自然结构信息实现图像从低分辩率到高分辨率的映射。随着深度学习的发展,卷积神经网络通过强大的拟合能力,在图像超分辨率场景取得了叹为观止的效果。
于是人们开始将目光转向更难的视频超分辨率任务,并在视频领域得到大规模的落地实践,如在快手App的服务端、移动端等业务都已广泛应用。视频超分辨率的难点在于时序信息的利用,即如何利用多帧图像序列间的互补信息来产生超分辨率所需的纹理细节。
现有的时序建模方法大致分为两个方向。
一个是基于光流[1,2,3]、可变形卷积[4,5]、3D卷积[6,7]的方法。这类方法会在低分辨率层面显性或者隐性地建模前后帧的时序信息,然后经过融合网络得到重建的高分辨率结果。由于这些建模的结构大多基于神经网络,并且较为复杂,有时难以直接插入到任意的视频框架中。
另一个时序建模的思路是基于递归隐状态累积的方法[8,9,10,11,12],通过不断在隐层累积历史特征来建模整段视频序列的互补信息。
这种方案最早采用了单向的循环卷积网络,即只利用当前帧与前一帧和历史累积的结果作为网络的输入,融合得到超分辨率结果。该方式的好处是在一定的信息累积后,仅用较小的网络结构和运算成本便可取得可观的收益。但它的问题是前几帧的信息累积不充分,导致初始几帧的超分辨率效果都会受到损失。在实际场景中需要“预热”一段时间后才可以被使用。
双向循环卷积网络是缓解信息分配不平衡的一个解决方案,它将视频的全部信息分别进行正向和反向的传播,最终结合正向和反向的信息生成超分辨率结果。本文深入分析了这种方法,并发现双向的传播策略也面临两个问题。
(1)信息利用的灵活性。由于双向的传播策略通常是利用前一个和后一个的时序特征,所以当这些时刻发生遮挡或者视差变换时,误差也会累积到隐层特征中,对当前时刻的超分产生错误结果。
一个直观的解决方案是直接将多个时刻的信息传播到当前时刻,但较大的运动差异反而会影响融合的效果。近期有一些方法,采取对预测结果进行运动补偿来弥补,但无论是光流还是可变形卷积都会引入庞大的计算开销。
(2)实时性。由于双向循环卷积网络的每次运算都要导入所有图像序列的处理,导致难以在实况直播这种因果系统中应用。
此外,无论是在相邻帧的融合方式,还是在特征传播上,现有的视频超分辨率框架仍没有统一的处理方案,往往需要应对各自的时序建模的对象来单独设计策略,这也引发了本文的思考,是否存在一种统一的策略,来对低分辨率图像和高分辨率结果进行时序建模?
面对上述问题,本文提出用相邻帧的时间残差图来统一低分辨率和高分辨率的时序建模视角。
在低分辨率空间下,输入帧的时间残差图可以用来区分这两帧间中的低变化和高变化区域,不同的区域所包含的互补信息应当在重建中被区分对待。在高分辨率空间下,时序残差图可以将不同时刻的预测结果以较小的运算代价传播到任意过去和未来的时刻。
值得一提的是,所提出的视频超分辨率框架(ETDM)虽然是单向循环网络的传播结构,但在时间残差图的帮助下,当前时刻的初步超分辨率结果可以被多个过去和未来的结果进一步增强。
图1展示了ETDM在学术公开集Vid4上的处理效果,超过了众多已经发表的视频超分辨率方案,同时也展示了一张图片从320×180超分到1280×720所需的速度。ETDM方法以单向的循环卷积网络结构超过了大部分单向、双向、多帧融合的方法,达到了更好的效果与速度的平衡。

△图1 ETDM方法与其他SOTA方法在效果和速度上的对比
具体如何实现?
如图2所示,本文提出的视频超分辨率结构(ETDM)是一个基于单向结构的循环卷积网络,即隐层特征只采用正向的传播方式。对于每个时刻,网络的输入分为两个层面:一个是低分辨率空间下的图像序列(前一帧It-1、当前帧It和后一帧It+1);另一个是高分辨率空间下的预测结果。
ETDM的核心是提出用相邻帧的差分图来统一这两个层面下的时序建模方式。这里定义当前帧为参考帧,时间差分图为参考帧与相邻帧的差,它既可以表示为前后帧图像的像素变化差异,也可以被认为是参考帧到邻近帧的转换“桥梁”。接下来将从这两方面具体介绍时间差分图的应用方式。

△图2 所提出的ETDM网络结构
在低分辨率空间下的显性时序建模
由于视频帧在获取时具有连续性,存在冗余和非冗余的时序信息,因此相邻帧有着不同程度的互补信息。为了验证这一点,采用图3描绘了参考帧相对邻近帧在不同区域的像素变化程度,不同的颜色表示不同的强度。

△图3 相邻两帧每个像素点的差异程度
可以发现,相邻帧中存在像素点运动差异变化程度较小和较大的区域。这种差异程度具有一定启发性,是否能用时间残差图将邻近帧拆分为低变化(LV)和高变化(HV)的区域。
直觉上,LV区域的表征变化细微,那么相邻帧的互补信息可能来源于微小的细节;而HV区域的整体差异较大,可以从不同方面提供更粗尺度的互补信息。
但是,时间差分图是非常稀疏的。为了得到完整的划分区域,我们先对它用3×3进行滤波和图形化方法处理,然后将其变为二值化的时序差分图并作用到原图上,得到LV和HV区域,如下所示:

由于自然图像的平滑性,LV可能对应帧间小运动的区域,而HV可能对应大运动的区域。
因此在融合方式上,本文选择用参数共享但感受野不同的融合网络。具体来讲,为HV分支的前几层网络分配了更大的空洞率,从而捕捉更大的运动信息。
在高分辨率空间下的显性时序建模
残差图的另一层含义是参考帧到邻近帧的转换“桥梁”。于是,除了重建当前时刻的超分辨率结果外,我们还会重建当前时刻到过去和未来的高分辨率时序残差图。
如上图2所示,我们在特征提取网络后增加了3个Residual Head (Spatial-Residual Head, Past-Residual Head 和 Future-Residual Head)。它们分别预测当前时刻的超分辨率结果,当前到过去的时序残差图的超分辨率结果,以及当前到未来的时序残差图的超分辨率结果。
通过利用所预测的时序残差图,当前、未来或者过去时刻所预测的超分辨率结果便可以传播到当前时刻,并为当前时刻提供更多互补信息。
于是,我们提出了时序往返优化机制。对于当前时刻而言,过去时刻和未来时刻的结果可以按照下面的方式传播到当前时刻:

传播过来的结果带来了不同时刻下的互补信息,因此可以帮助当前时刻的超分辨率结果获得进一步优化。
我们进一步发现,时间残差图具备累积转移特性,即当前时刻到任意时刻的时间转移都可以用这段时间内每个相邻帧的时序残差图来累积得到。于是,自然地将传播过程进阶扩展到任意的时间顺序上。下式展示了将第t-l个时刻的结果传递到当前时刻:
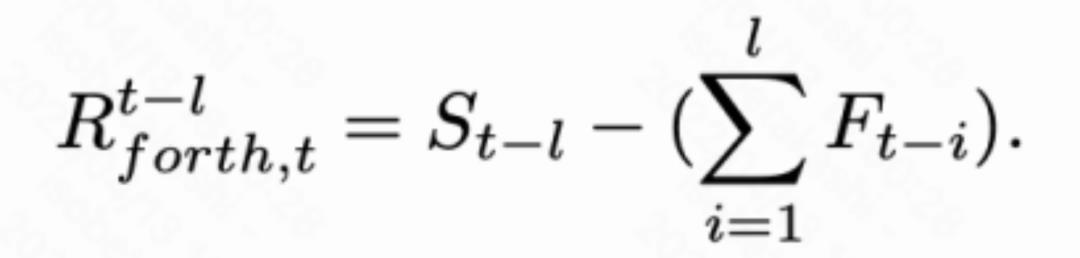
同理,也可以将t+l个时刻的结果传递到当前时刻:

为了充分利用不同时刻下的互补信息,我们维护了长度为N的存储器,来存储N个过去和未来时刻的超分辨率结果,即 和
和 。
。
下图表示了存储器的更新过程。

△图4 存储器的更新过程
这里以第t帧处理后,开始重建第t+1时刻的帧为例。此时,网络不仅需要更新隐层的特征,还需要更新存储器中的特征,采用下方公式来更新:

效果如何?
一些现有的方法采用不同的数据集来训练网络,这些数据集中的纹理分布不同,对性能也具有一定影响,不利于公平地比较。本文采用了公开的数据集Vimeo-90K来训练网络,并在该数据下复现了部分已有的方法。具体性能比较如图5所示。

△图5 定量的性能对比
图5 展示了不同方法在公开数据集Vid4,SPMCS,UDM10,REDS4的对比结果。ETDM方法在客观评价指标PSNR和SSIM上超过了大部分视频超分辨率方法。图5表中也记录了不同方法4倍超分辨率一张320x180图像的所需时间。
可以发现,ETDM方法超过了大部分基于时间滑动窗的多帧融合算法,如TGA、RBPN和EDVR,也超过了部分基于双向循环卷积网络的方法。值得一提的是,虽然ETDM的主干网络为单向的隐层传递,但它也超过了BasicVSR、GOVSR这类基于双向卷积网络的方法。
在使用上,ETDM支持灵活设置所要传播的未来和过去的结果个数,而并不需要使用整段视频的所有帧作为输入,因此具备比双向网络结构更灵活的应用能力。

△图6 定性的性能对比
图6 展示了在公开数据集上的定性对比结果,ETDM方法可以产生更丰富的细节和准确的结构。
下面是一些视频的对比结果(上:输入,下:超分辨率后的结果):
总结
视频超分辨率的一个重点是时序互补信息的利用方式,业内多采用基于多帧运动补偿和基于递归隐状态累积的方式分别对低分辨率和高分辨率进行时序建模。
本文重新思考了这个问题,并从新的角度提出了用时序差分来统一低分辨率和高分辨率下的时序建模方法。
时序差分的第一层含义是描述前后帧图像的像素变化差异,因此在低分辨率下可以用来区分输入序列的高变化和低变化的区域;第二层含义是相邻两帧的转换“桥梁”,因此在高分辨率下可以用于传播不同时刻的预测结果。进一步,本文将高分辨率下的单时刻转移扩展为任意时刻的转移,并存储了多个时刻的结果来优化当前时刻。
本文是快手与大连理工大学贾旭副教授合作的,包括TGA,RSDN,RRN系列视频超分辨率工作的后续工作。所提出的ETDM在多个公开数据集上取得了不错的结果,以单向循环卷积的结构超过了SOTA的EDVR,GOVSR,BasicVSR等方法。
快手音视频技术团队介绍
快手音视频技术团队由业界资深的行业专家组成,涵盖了算法、工程、产品等多个领域。自2016年成立以来,团队建立了业界领先的短视频和直播技术体系,保障快手海内外数亿用户体验,驱动平台多元业务的发展。
基于丰富多样的视频应用场景,快手音视频技术团队构建了包括点播云、直播云、RTC等产品体系。通过算法优化和工程建设,团队以用户体验为导向,采用数据驱动、质量评测及产品化等手段,实现了从视频制作、云端处理到视频消费的全链路技术创新,打造更为极致的音视频体验。
以上是关于业内视频超分辨率新标杆,快手&大连理工研究登上CVPR 2022的主要内容,如果未能解决你的问题,请参考以下文章
快手磁力聚星520CP心动季揽获9.3亿曝光,打造节点创新营销新标杆
高糊视频秒变4K,速度比TecoGAN快了9倍!东南大学提出新的视频超分辨率系统
双非长沙理工排名飙升176反超吉大,湖大连续2年超哈工大 | US News 2023