java并发编程要点速览(Java并发容器和框架,原子操作类,并发工具类)
Posted 韩zj
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java并发编程要点速览(Java并发容器和框架,原子操作类,并发工具类)相关的知识,希望对你有一定的参考价值。
ConcurrentHashMap的实现原理与使用
ConcurrentHashMap是线程安全且高效的HashMap。在并发编程中使用HashMap可能导致程序死循环。而使用线程安全的HashTable效率又非常低下,基于以上两个原因,便有了ConcurrentHashMap的登场机会。
在多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。例如,执行以下代码会引起死循环。
final HashMap<String, String> map = new HashMap<String, String>(2);
Thread t = new Thread(new Runnable()
@Override
public void run()
for (int i = 0; i < 10000; i++)
new Thread(new Runnable()
@Override
public void run()
map.put(UUID.randomUUID().toString(), "");
, "ftf" + i).start();
, "ftf");
t.start();
t.join();
HashMap在并发执行put操作时会引起死循环,是因为多线程会导致HashMap的Entry链表形成环形数据结构,一旦形成环形数据结构,Entry的next节点永远不为空,就会产生死循环获取Entry。
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法,其他线程也访问HashTable的同步方法时,会进入阻塞或轮询状态。如线程1使用put进行元素添加,线程2不但不能使用put方法添加元素,也不能使用get方法来获取元素,所以竞争越激烈效率越低。
ConcurrentHashMap所使用的锁分段技术。首先将数据分成一段一段地存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问。
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的角色;HashEntry则用于存储键值对数据。一个ConcurrentHashMap里包含一个Segment数组。Segment的结构和HashMap类似,是一种数组和链表结构。一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得与它对应的Segment锁。
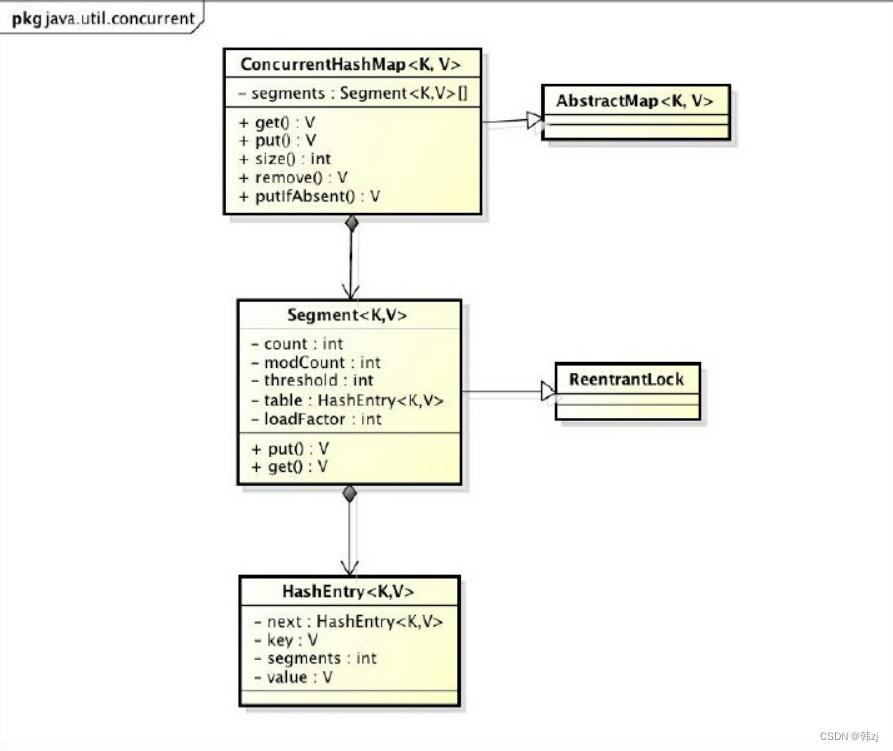
ConcurrentHashMap初始化方法是通过initialCapacity、loadFactor和concurrencyLevel等几个参数来初始化segment数组、段偏移量segmentShift、段掩码segmentMask和每个segment里的HashEntry数组来实现的。
ConcurrentHashMap的操作
1.get操作
Segment的get操作实现非常简单和高效。先经过一次再散列,然后使用这个散列值通过散列运算定位到Segment,再通过散列算法定位到元素,代码如下
public V get(Object key)
int hash = hash(key.hashCode());
return segmentFor(hash).get(key, hash);
get操作的高效之处在于整个get过程不需要加锁,除非读到的值是空才会加锁重读。get方法里将要使用的共享变量都定义成volatile类型,定义成volatile的变量,能够在线程之间保持可见性,能够被多线程同时读,并且保证不会读到过期的值,但是只能被单线程写(有一种情况可以被多线程写,就是写入的值不依赖于原值),在get操作里只需要读不需要写共享变量count和value,所以可以不用加锁。之所以不会读到过期的值,是因为根据Java内存模型的happen before原则,对volatile字段的写入操作先于读操作,即使两个线程同时修改和获取volatile变量,get操作也能拿到最新的值,这是用volatile替换锁的经典应用场景。
2.put操作
由于put方法里需要对共享变量进行写入操作,所以为了线程安全,在操作共享变量时必
须加锁。put方法首先定位到Segment,然后在Segment里进行插入操作。插入操作需要经历两个
步骤,第一步判断是否需要对Segment里的HashEntry数组进行扩容,第二步定位添加元素的位
置,然后将其放在HashEntry数组里。
3.size操作
如果要统计整个ConcurrentHashMap里元素的大小,就必须统计所有Segment里元素的大小后求和。在累加count操作过程中,之前累加过的count发生变化的几率非常小,所以ConcurrentHashMap的做法是先尝试2次通过不锁住Segment的方式来统计各个Segment大小,如果统计的过程中,容器的count发生了变化,则再采用加锁的方式来统计所有Segment的大小。
ConcurrentLinkedQueue
ConcurrentLinkedQueue是一个基于链接节点的无界线程安全队列,它采用先进先出的规则对节点进行排序,当我们添加一个元素的时候,它会添加到队列的尾部;当我们获取一个元素时,它会返回队列头部的元素。它采用了“wait-free”算法(即CAS算法)来实现,该算法在Michael&Scott算法上进行了一些修改。
ConcurrentLinkedQueue由head节点和tail节点组成,每个节点(Node)由节点元素(item)和指向下一个节点(next)的引用组成,节点与节点之间就是通过这个next关联起来,从而组成一张链表结构的队列。默认情况下head节点存储的元素为空,tail节点等于head节点。
入队列:
入队列就是将入队节点添加到队列的尾部。入队主要做两件事情:第一是将入队节点设置成当前队列尾节点的下一个节点;第二是更新tail节点,如果tail节点的next节点不为空,则将入队节点设置成tail节点,如果tail节点的next节点为空,则将入队节点设置成tail的next节点,所以tail节点不总是尾节点
出队列:
出队列的就是从队列里返回一个节点元素,并清空该节点对元素的引用。并不是每次出队时都更新head节点,当head节点里有元素时,直接弹出head节点里的元素,而不会更新head节点。只有当head节点里没有元素时,出队操作才会更新head节点
Java中的阻塞队列
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。这两个附加的操作支持阻塞的插入和移除方法。
1)支持阻塞的插入方法:意思是当队列满时,队列会阻塞插入元素的线程,直到队列不满。
2)支持阻塞的移除方法:意思是在队列为空时,获取元素的线程会等待队列变为非空。
阻塞队列常用于生产者和消费者的场景,生产者是向队列里添加元素的线程,消费者是从队列里取元素的线程。阻塞队列就是生产者用来存放元素、消费者用来获取元素的容器。

JDK 7提供了7个阻塞队列,如下。
·ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列。
·LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列。
·PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列。
·DelayQueue:一个使用优先级队列实现的无界阻塞队列。
·SynchronousQueue:一个不存储元素的阻塞队列。
·LinkedTransferQueue:一个由链表结构组成的无界阻塞队列。
·LinkedBlockingDeque:一个由链表结构组成的双向阻塞队列。
Fork/Join框架
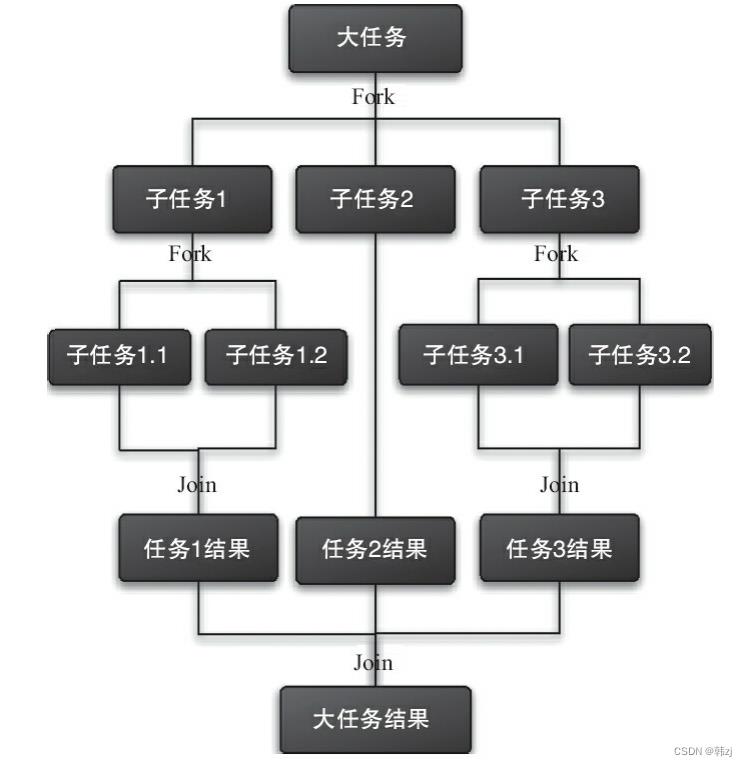
Fork/Join框架是Java 7提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。假如我们需要做一个比较大的任务,可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应。比如A线程负责处理A队列里的任务。但是,有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列
里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取的运行流程:
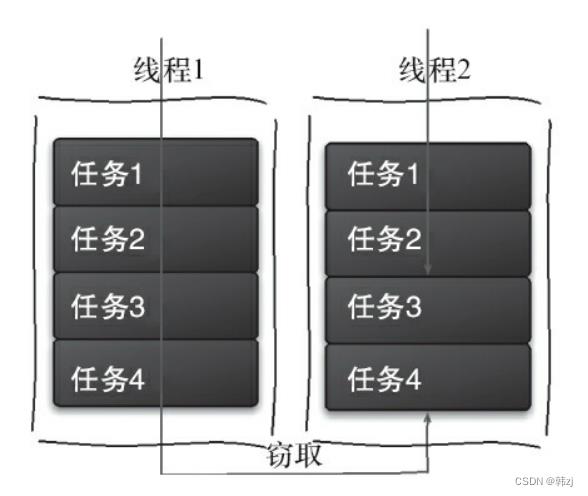
工作窃取算法的优点:充分利用线程进行并行计算,减少了线程间的竞争。
工作窃取算法的缺点:在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且该算法会消耗了更多的系统资源,比如创建多个线程和多个双端队列。
Fork/Join框架的设计:
步骤1 分割任务。首先我们需要有一个fork类来把大任务分割成子任务,有可能子任务还是很大,所以还需要不停地分割,直到分割出的子任务足够小。
步骤2 执行任务并合并结果。分割的子任务分别放在双端队列里,然后几个启动线程分别从双端队列里获取任务执行。子任务执行完的结果都统一放在一个队列里,启动一个线程从队列里拿数据,然后合并这些数据。
Fork/Join使用两个类来完成以上两件事情。
①ForkJoinTask:我们要使用ForkJoin框架,必须首先创建一个ForkJoin任务。它提供在任务中执行fork()和join()操作的机制。通常情况下,我们不需要直接继承ForkJoinTask类,只需要继承它的子类,Fork/Join框架提供了以下两个子类。
·RecursiveAction:用于没有返回结果的任务。
·RecursiveTask:用于有返回结果的任务。
②ForkJoinPool:ForkJoinTask需要通过ForkJoinPool来执行。
任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队列的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
public class CountTask extends RecursiveTask<Integer>
private static final int THRESHOLD = 2; // 阈值
private int start;
private int end;
public CountTask(int start, int end)
this.start = start;
this.end = end;
@Override
protected Integer compute()
int sum = 0;
// 如果任务足够小就计算任务
boolean canCompute = (end - start) <= THRESHOLD;
if (canCompute)
for (int i = start; i <= end; i++)
sum += i;
else
// 如果任务大于阈值,就分裂成两个子任务计算
int middle = (start + end) / 2;
CountTask leftTask = new CountTask(start, middle);
CountTask rightTask = new CountTask(middle + 1, end);
// 执行子任务
leftTask.fork();
rightTask.fork();
// 等待子任务执行完,并得到其结果
int leftResult=leftTask.join();
int rightResult=rightTask.join();
// 合并子任务
sum = leftResult + rightResult;
return sum;
public static void main(String[] args)
ForkJoinPool forkJoinPool = new ForkJoinPool();
// 生成一个计算任务,负责计算1+2+3+4
CountTask task = new CountTask(1, 4);
// 执行一个任务
Future<Integer> result = forkJoinPool.submit(task);
try
System.out.println(result.get());
catch (InterruptedException e)
catch (ExecutionException e)
ForkJoinTask与一般任务的主要区别在于它需要实现compute方法,在这个方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务。如果不足够小,就必须分割成两个子任务,每个子任务在调用fork方法时,又会进入compute方法,看看当前子任务是否需要继续分割成子任务,如果不需要继续分割,则执行当前子任务并返回结果。使用join方法会等待子任务执行完并得到其结果。
Fork/Join框架的实现原理:
ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组组成,ForkJoinTask数组负责将存放程序提交给ForkJoinPool的任务,而ForkJoinWorkerThread数组负责执行这些任务。
Java中的13个原子操作类
Java从JDK 1.5开始提供了java.util.concurrent.atomic包(以下简称Atomic包),这个包中的原子操作类提供了一种用法简单、性能高效、线程安全地更新一个变量的方式。Atomic包里一共提供了13个类,属于4种类型的原子更新方式,分别是原子更新基本类型、原子更新数组、原子更新引用和原子更新属性(字段)。Atomic包里的类基本都是使用Unsafe实现的包装类。
原子更新基本类型类:
·AtomicBoolean:原子更新布尔类型。
·AtomicInteger:原子更新整型。
·AtomicLong:原子更新长整型。
仅以AtomicInteger为例进行讲解,AtomicInteger的常用方法如下。
·int addAndGet(int delta):以原子方式将输入的数值与实例中的值(AtomicInteger里的value)相加,并返回结果。
·boolean compareAndSet(int expect,int update):如果输入的数值等于预期值,则以原子方式将该值设置为输入的值。
·int getAndIncrement():以原子方式将当前值加1,注意,这里返回的是自增前的值。
·void lazySet(int newValue):最终会设置成newValue,使用lazySet设置值后,可能导致其他线程在之后的一小段时间内还是可以读到旧的值
·int getAndSet(int newValue):以原子方式设置为newValue的值,并返回旧值。
getAndIncrement是如何实现原子操作的呢?
public final int getAndIncrement()
for (;;)
int current = get();
int next = current + 1;
if (compareAndSet(current, next))
return current;
public final boolean compareAndSet(int expect, int update)
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
源码中for循环体的第一步先取得AtomicInteger里存储的数值,第二步对AtomicInteger的当前数值进行加1操作,关键的第三步调用compareAndSet方法来进行原子更新操作,该方法先检查当前数值是否等于current,等于意味着AtomicInteger的值没有被其他线程修改过,则将AtomicInteger的当前数值更新成next的值,如果不等compareAndSet方法会返回false,程序会进入for循环重新进行compareAndSet操作。
原子更新数组:
通过原子的方式更新数组里的某个元素,Atomic包提供了以下:
·AtomicIntegerArray:原子更新整型数组里的元素。
·AtomicLongArray:原子更新长整型数组里的元素。
·AtomicReferenceArray:原子更新引用类型数组里的元素
·AtomicIntegerArray类主要是提供原子的方式更新数组里的整型,其常用方法如下。
·int addAndGet(int i,int delta):以原子方式将输入值与数组中索引i的元素相加。
·boolean compareAndSet(int i,int expect,int update):如果当前值等于预期值,则以原子方式将数组位置i的元素设置成update值。
public class AtomicIntegerArrayTest
static int[] value = new int[] 1, 2 ;
static AtomicIntegerArray ai = new AtomicIntegerArray(value);
public static void main(String[] args)
ai.getAndSet(0, 3);
System.out.println(ai.get(0));
System.out.println(value[0]);
输出结果:
3
1
数组value通过构造方法传递进去,然后AtomicIntegerArray会将当前数组复制一份,所以当AtomicIntegerArray对内部的数组元素进行修改时,不会影响传入的数组。
原子更新引用类型
原子更新基本类型的AtomicInteger,只能更新一个变量,如果要原子更新多个变量,就需要使用这个原子更新引用类型提供的类。Atomic包提供了以下3个类。
·AtomicReference:原子更新引用类型。
·AtomicReferenceFieldUpdater:原子更新引用类型里的字段。
·AtomicMarkableReference:原子更新带有标记位的引用类型。可以原子更新一个布尔类型的标记位和引用类型。构造方法是AtomicMarkableReference(V initialRef,boolean initialMark)。
以AtomicReference为例:
public class AtomicReferenceTest
public static AtomicReference<user> atomicUserRef = new AtomicReference<user>();
public static void main(String[] args)
User user = new User("conan", 15);
atomicUserRef.set(user);
User updateUser = new User("Shinichi", 17);
atomicUserRef.compareAndSet(user, updateUser);
System.out.println(atomicUserRef.get().getName());
System.out.println(atomicUserRef.get().getOld());
static class User
private String name;
private int old;
public User(String name, int old)
this.name = name;
this.old = old;
public String getName()
return name;
public int getOld()
return old;
代码中首先构建一个user对象,然后把user对象设置进AtomicReferenc中,最后调用compareAndSet方法进行原子更新操作,实现原理同AtomicInteger里的compareAndSet方法。代码执行后输出结果如下。
Shinichi
17
原子更新字段类
如果需原子地更新某个类里的某个字段时,就需要使用原子更新字段类,Atomic包提供了以下3个类进行原子字段更新。
·AtomicIntegerFieldUpdater:原子更新整型的字段的更新器。
·AtomicLongFieldUpdater:原子更新长整型字段的更新器。
·AtomicStampedReference:原子更新带有版本号的引用类型。该类将整数值与引用关联起来,可用于原子的更新数据和数据的版本号,可以解决使用CAS进行原子更新时可能出现的ABA问题。
要想原子地更新字段类需要两步。第一步,因为原子更新字段类都是抽象类,每次使用的时候必须使用静态方法newUpdater()创建一个更新器,并且需要设置想要更新的类和属性。第二步,更新类的字段(属性)必须使用public volatile修饰符。
public class AtomicIntegerFieldUpdaterTest
// 创建原子更新器,并设置需要更新的对象类和对象的属性
private static AtomicIntegerFieldUpdater<User> a = AtomicIntegerFieldUpdater. newUpdater(User.class, "old");
public static void main(String[] args)
// 设置柯南的年龄是10岁
User conan = new User("conan", 10);
// 柯南长了一岁,但是仍然会输出旧的年龄
System.out.println(a.getAndIncrement(conan));
// 输出柯南现在的年龄
System.out.println(a.get(conan));
public static class User
private String name;
public volatile int old;
public User(String name, int old)
this.name = name;
this.old = old;
public String getName()
return name;
public int getOld()
return old;
输出结果:
10
11
Java中的并发工具类
CountDownLatch、CyclicBarrier和Semaphore工具类提供了一种并发流程控制的手段,Exchanger工具类则提供了在线程间交换数据的一种手段。
等待多线程完成的CountDownLatch
CountDownLatch允许一个或多个线程等待其他线程完成操作。假如有这样一个需求:我们需要解析一个Excel里多个sheet的数据,此时可以考虑使用多线程,每个线程解析一个sheet里的数据,等到所有的sheet都解析完之后,程序需要提示解析完成。在这个需求中,要实现主线程等待所有线程完成sheet的解析操作,最简单的做法是使用join()方法,如代码清单所示。
public class JoinCountDownLatchTest
public static void main(String[] args) throws InterruptedException
Thread parser1 = new Thread(new Runnable()
@Override
public void run()
);
Thread parser2 = new Thread(new Runnable()
@Override
public void run()
System.out.println("parser2 finish");
);
parser1.start();
parser2.start();
parser1.join();
parser2.join();
System.out.println("all parser finish");
join用于让当前执行线程等待join线程执行结束。其实现原理是不停检查join线程是否存活,如果join线程存活则让当前线程永远等待。直到join线程中止后,线程的this.notifyAll()方法会被调用。
CountDownLatch也可以实现join的功能,并且比join的功能更多:
public class CountDownLatchTest
staticCountDownLatch c = new CountDownLatch(2);
public static void main(String[] args) throws InterruptedException
new Thread(new Runnable()
@Override
public void run()
System.out.println(1);
c.countDown();
System.out.println(2);
c.countDown();
).start();
c.await();
System.out.println("3");
CountDownLatch的构造函数接收一个int类型的参数作为计数器,如果你想等待N个点完成,这里就传入N。
当我们调用CountDownLatch的countDown方法时,N就会减1,CountDownLatch的await方法会阻塞当前线程,直到N变成零。由于countDown方法可以用在任何地方,所以这里说的N个点,可以是N个线程,也可以是1个线程里的N个执行步骤。用在多个线程时,只需要把这个CountDownLatch的引用传递到线程里即可。
同步屏障CyclicBarrier
CyclicBarrier的字面意思是可循环使用(Cyclic)的屏障(Barrier)。它要做的事情是,让一组线程到达一个屏障(也可以叫同步点)时被阻塞,直到最后一个线程到达屏障时,屏障才会开门,所有被屏障拦截的线程才会继续运行。
默认的构造方法是CyclicBarrier(int parties),其参数表示屏障拦截的线程数量,每个线程调用await方法告诉CyclicBarrier我已经到达了屏障,然后当前线程被阻塞。
public class CyclicBarrierTest
staticCyclicBarrier c = new CyclicBarrier(2);
public static void main(String[] args)
new Thread(new Runnable()
@Override
public void run()
try
c.await();
catch (Exception e)
System.out.println(1);
).start();
try
c.await();
catch (Exception e)
System.out.println(2);
因为主线程和子线程的调度是由CPU决定的,两个线程都有可能先执行,所以会产生两种输出,1 2或者2 1。如果把new CyclicBarrier(2)修改成new CyclicBarrier(3),则主线程和子线程会永远等待,因为没有第三
JAVA并发编程的艺术 Java并发容器和框架
ConcurrentHashMap
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。
一个ConcurrentHashMap里包含一个Segment数组,Segment的结构和HashMap类似,是一种数组和链表结构, 一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素, 每个Segment守护者一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得它对应的Segment锁。
以上是关于java并发编程要点速览(Java并发容器和框架,原子操作类,并发工具类)的主要内容,如果未能解决你的问题,请参考以下文章