并发编程系列之并发容器:ConcurrentHashMap
Posted Justin的后端书架
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了并发编程系列之并发容器:ConcurrentHashMap相关的知识,希望对你有一定的参考价值。
前言
之前我们讲了线程,锁以及队列同步器等等一些并发相关底层的东西,当然Java开发者在开发中很少直接去使用之前所讲的,因为Java为了简化开发,为我们提供了一整套并发容器和框架,但是这些容器和框架都是建立在之前所讲的基础之上的,今天就让我们来看第一个并发容器:ConcurrentHashMap,我们主要从原理和使用两个方面介绍,让我们扬帆起航,开始今天的并发之旅吧。

景点一:为什么要使用ConcurrentHashMap
ConcurrentHashMap是一个线程安全并且高效的HashMap,基于下面两点我们还是在并发场景中优先考虑ConcurrentHashMap。
线程不安全的HashMap:在多线程环境下,使用HashMap进行操作会引起死循环,导致CPU100%甚至服务器之间崩溃,读者可以参考下面代码自己试一下,(亲测使用Hash服务器直接卡死,不信U CAN TRY):多线程会导致HashMap的Entry链表形成环形数据结构,一旦形成环,那么Entry的next节点永远不为空,Hash就会陷入死循环获取Entry的场景
public class ConcurrentMapDemo {
public static void main(String[] args) throws InterruptedException {
// final HashMap<String, String> map = new HashMap<String, String>();
final ConcurrentHashMap map = new ConcurrentHashMap<>();
Thread t1 = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 1000; i++) {
map.put(UUID.randomUUID().toString(), "");
}
}
}, "t2").start();
}
}
}, "t1");
t1.start();
}
}效率低下的HashTable:HashTable是使用synchronized来保证线程安全,但是在多线程并发环境下线程竞争激烈,HashTable的效率非常低,也正是因为synchronized导致每次只能有一个线程访问同步块,其他线程处于阻塞或者轮询状态,根本无法对同步块进行任何操作,所以线程竞争越激烈(线程数量越多),效率越低,这明显不满足我们使用多线程的初衷;
ConcurrentHashMap锁分段技术:ConcurrentHashMap内部使用段(segment)来表示这些不同的部分,每个段其实就是一个小的HashTable,他们有自己各自的锁,只要多个修改操作发生在不同的段上,他们之间就可以并发的进行;
景点二:ConcurrentHashMap的结构
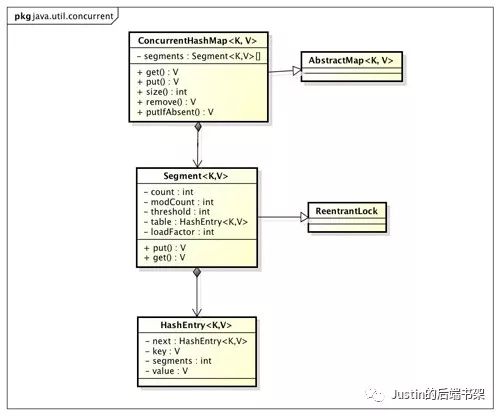
通过上面的结构图,我们来分析下:ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成,Segment是一种可重入锁,在ConcurrentHashMap中充当锁的角色,HashEntry是用来存储键值对数据。这三者的关系如下图:
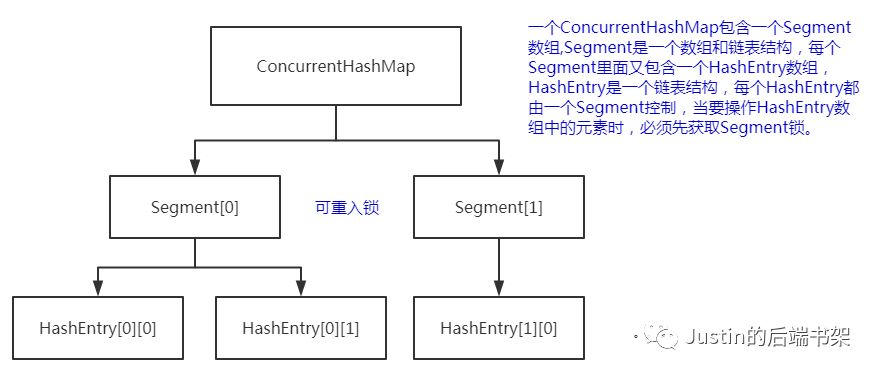
景点三:ConcurrentHashMap的底层实现
ConcurrentHashMap把一个整体分成16个段(segment),也就是说最高支持16个线程的并发修改操作。这也是在多线程场景下减小锁粒度从而降低竞争的一种方案。并且代码中大多共享变量使用volatile关键字,目的是第一时间获取修改的内容,性能非常好。
ConcurrentHashMap的底层主要包括初始化Segment数组、SegmentShift、SegmentMask和每个Segment里面的HashEntry数组以及Segment的定位,下面我们将来一一分析:
初始化Segment数组:
if (concurrencyLevel > MAX_SEGMENTS)
concurrencyLevel = MAX_SEGMENTS;
// segments数组的长度ssize通过concurrencyLevel计算得出。
//为了能通过按位与的哈希算法来定位segments数组的索引,
//必须保证segments数组的长度是2的N次方
// 所以必须计算出一个是大于或等于concurrencyLevel的最小的2的N次方值来作为segments数组的长度
int sshift = 0;
int ssize = 1;
while (ssize < concurrencyLevel) {
++sshift;
ssize <<= 1;
}
this.segmentShift = 32 - sshift;
this.segmentMask = ssize - 1;初始化SegmentShift和SegmentMask:这两个全局变量在定位segment时的哈希散列中使用,sshift等于ssize从1向左移位的次数,在默认情况下concurrencyLevel等于16,1需要向左移位移动4次,所以sshift等于4。segmentShift用于定位参与hash运算的位数,segmentShift等于32减sshift,所以等于28,这里之所以用32是因为ConcurrentHashMap里的hash()方法输出的最大数是32位的。
segmentMask是哈希运算的掩码,等于ssize减1,即15,掩码的二进制各个位的值都是1。因为ssize的最大长度是65536,所以segmentShift最大值是16,segmentMask最大值是65535,对应的二进制是16位,每个位都是1;
初始化每个Segment里面的HashEntry:
// initialCapacity是ConcurrentHashMap的初始化容量
// loadFactor是每个Segment的负载因子
// cap为Segment里面HashEntry数组的长度,它等于initialCapacity/ssize的倍数c,如果c>1则就会取大于等于c的2的N次方值
// 所以cap如果不是1就是2的N次方。
// Segment的容量=(int)cap*loadFactor,默认情况下loadFactor=0.75,initialCapacity=16
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
int c = initialCapacity / ssize;
if (c * ssize < initialCapacity)
++c;
int cap = MIN_SEGMENT_TABLE_CAPACITY;
while (cap < c)
cap <<= 1;
// create segments and segments[0]
Segment<K,V> s0 = new Segment<K,V>(loadFactor, (int)(cap * loadFactor),(HashEntry<K,V>[])new HashEntry[cap]);
Segment<K,V>[] ss = (Segment<K,V>[])new Segment[ssize];定位Segment:ConcurrentHashMap使用分段锁Segment来保护每段数据,那么在插入和获取元素的时候,必须先通过哈希算法定位到Segment,ConcurrentHashMap会对元素的HashCode在进行一次hash散列,进行2次哈希的目的是减少散列冲突,使元素能够均匀地分布在不同的Segment上,提高容器的存取效率。
如果哈希散列最坏的情况是所有元素元素全部散落在一个Segment中,那么分段锁的意义就没有了,而且存取效率也极差,所以为了尽量减少散列冲突ConcurrentHashMap是通过2次哈希来做的,我们可以看具体源码如下:
// segmentShift默认情况下=28
// segmentMask默认情况下=15
private Segment<K,V> segmentForHash(int h) {
// hash值右移28位(让高4位参与到散列中) 再和segmentShift做与运算
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
return (Segment<K,V>) UNSAFE.getObjectVolatile(segments, u);
}
景点四:ConcurrentHashMap的操作
ConcurrentHashMap的的方法有很多如下,我们主要讲三种:get、put和size


put操作:
调用特别简单跟使用HashMap没有任何区别,如下:
ConcurrentHashMap concurrentHashMap = new ConcurrentHashMap<>();
concurrentHashMap.put("Justin","Justin的后端书架");但是,由于ConcurrentHashMap是线程安全的所以put方法需要对共享变量进行写入操作,所以为了线程安全,必须加锁,我们看下put的底层实现:
/**
* put方法首先定位到Segment,然后在Segment里面进行插入操作
* 插入操作需要进行2步:
* 第一步:先判断是否需要对Segment里的HashEntry进行扩容,判断HashEntry是否
* 是否超过容量threshold,如果超过阈值则进行扩容,Segment的扩容比
* Hashmap的扩容更合理,Hash是在插入元素之后再判断是否需要进行扩容,
* 如果插入元素之后,满足扩容条件,但是后续没有元素新增,那就会做了一次无效的扩容
* 拓展:如何扩容?扩容的时候首先会创建一个两倍于原容量的数组,然后将原数组里的元素进行再hash后插入到新的数组里。
* 为了高效ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment进行扩容
* 第二步是定位到添加元素的位置,然后将它放入HashEntry数组里面
*/
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}get操作:
使用很简单:
ConcurrentHashMap concurrentHashMap = new ConcurrentHashMap<>();
concurrentHashMap.put("Justin","Justin的后端书架");
System.out.println(concurrentHashMap.get("Justin"));我们再看下源码实现:
/**
* 三步走:第一步,先对key经过一次再散列
* 第二步:使用这个散列值通过散列运算定位到Segment
* 第三步:再通过散列算法定位到元素
*/
public V get(Object key) {
Segment<K,V> s;
HashEntry<K,V>[] tab;
int h = hash(key);
long u = (((h >>> segmentShift) & segmentMask) << SSHIFT) + SBASE;
if ((s = (Segment<K,V>)UNSAFE.getObjectVolatile(segments, u)) != null &&
(tab = s.table) != null) {
for (HashEntry<K,V> e = (HashEntry<K,V>) UNSAFE.getObjectVolatile
(tab, ((long)(((tab.length - 1) & h)) << TSHIFT) + TBASE);
e != null; e = e.next) {
K k;
if ((k = e.key) == key || (e.hash == h && key.equals(k)))
return e.value;
}
}
return null;
}get操作的高效之处在于整个get过程不需要加锁,除非读到的值是空的才会加锁重读,那么我们看下ConcurrentHashMap是如何做到get不加锁的吧:原因是它的get方法里将要使用的共享变量都定义成volatile,在get操作里只需要读不需要写共享变量,所以可以不用加锁。之所以不会读到过期的值,是因为根据JMM的先行发生原则,对volatile字段的写入操作优先于读操作,即使两个线程同时修改和获取volatile变量,get操作最终也只会拿到最新的值。
size操作:
我们要统计ConcurrentHashMap里元素的大小,就必须统计所有的分区Segment里面元素的总和,但是如果我们在统计每个Segment里面元素总数的过程中,之前已经统计过得Segment又发生了更新,那么之前统计的总数就失效了,所以最安全的做法是在统计每个Segment的时候统计好的Segment就将他的更新操作全部锁住,等待全部Segment统计完毕再释放,但是显然这样是不科学的,效率非常低下。
源码如下:
/**
* 在累加count操作过程中,之前统计过的Segment发生变化的几率比较小,所以 * ConcurrentHashMap的做法是先尝试2次不加锁的方式来统计各个Segment大小,如果统计的过程中,
* 容器的count发生了变化,则再采用加锁的方式来统计所有Segment的大小
*
* ConcurrentHashMap是如何判断在统计的时候容器是否发生了变化呢?
* 使用modCount变量,在put , remove和clean方法里操作元素前都会将变量modCount进行加1, * 那么在统计size前后比较modCount是否发生变化,从而得知容器的大小是否发生变化
*/
public int size() {
final Segment<K,V>[] segments = this.segments;
int size;
boolean overflow; // true if size overflows 32 bits
long sum; // sum of modCounts
long last = 0L; // previous sum
int retries = -1; // first iteration isn't retry
try {
for (;;) {
if (retries++ == RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
ensureSegment(j).lock(); // force creation
}
sum = 0L;
size = 0;
overflow = false;
for (int j = 0; j < segments.length; ++j) {
Segment<K,V> seg = segmentAt(segments, j);
if (seg != null) {
sum += seg.modCount;
int c = seg.count;
if (c < 0 || (size += c) < 0)
overflow = true;
}
}
if (sum == last)
break;
last = sum;
}
} finally {
if (retries > RETRIES_BEFORE_LOCK) {
for (int j = 0; j < segments.length; ++j)
segmentAt(segments, j).unlock();
}
}
return overflow ? Integer.MAX_VALUE : size;
}
景点五:ConcurrentHashMap的缺点
ConcurrentHashMap的缺点就是他最多只能支持16个线程的并发,如果实际场景中,你需要启动的线程的数量比较多,还是同样会发生锁竞争和等待的问题:
以上就是今天所讲的ConcurrentHashMap的五大景点的所有内容,希望能对你有所帮助,通过短短十几分钟的阅读,希望你能有所收获!!!
以上是关于并发编程系列之并发容器:ConcurrentHashMap的主要内容,如果未能解决你的问题,请参考以下文章
Java并发编程:并发容器之ConcurrentHashMap
Java并发编程:并发容器之ConcurrentHashMap(转载)