Pytorch反向传播实现——up主:刘二大人《PyTorch深度学习实践》
Posted 不吃水果的太空人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch反向传播实现——up主:刘二大人《PyTorch深度学习实践》相关的知识,希望对你有一定的参考价值。
教程: https://www.bilibili.com/video/BV1Y7411d7Ys?p=2&vd_source=715b347a0d6cb8aa3822e5a102f366fe
数据集:
x
d
a
t
a
=
[
1.0
,
2.0
,
3.0
]
y
d
a
t
a
=
[
2.0
,
4.0
,
6.0
]
x_data = [1.0, 2.0, 3.0] \\\\y_data = [2.0, 4.0, 6.0]
xdata=[1.0,2.0,3.0]ydata=[2.0,4.0,6.0]
参数初始值:
w
1
=
1.0
w
2
=
1.0
b
=
1.0
w_1=1.0\\\\w_2=1.0\\\\b=1.0
w1=1.0w2=1.0b=1.0
模型:
y
=
w
1
∗
x
2
+
w
2
∗
x
+
b
y = w_1*x^2+w_2*x+b
y=w1∗x2+w2∗x+b
import torch
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w1 = torch.Tensor([1.0])
w1.requires_grad = True
w2 = torch.Tensor([1.0])
w2.requires_grad = True
b = torch.Tensor([1.0])
b.requires_grad = True
epoch_p = []
loss_p = []
def forward(x):
return w1 * x ** 2 + w2 * x + b
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y)
l.backward()
print('\\tgrad:', x, y, w1.grad.item(), w2.grad.item(), b.grad.item())
w1.data = w1.data - 0.01 * w1.grad.data
w2.data = w2.data - 0.01 * w2.grad.data
b.data = b.data - 0.01 * b.grad.data
w1.grad.data.zero_()
w2.grad.data.zero_()
b.grad.data.zero_()
loss_p.append(l.item())
epoch_p.append(epoch)
print('Epoch:', epoch, l.item())
print("predict(aftertraining)",4,forward(4).item())
plt.figure()
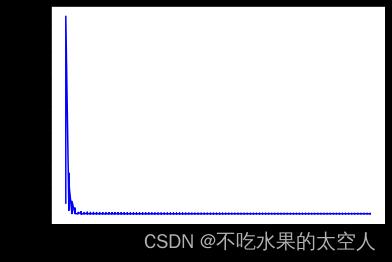
plt.plot(epoch_p, loss_p, c = 'b')
plt.xlabel('Epoch')
plt.ylabel('loss')
plt.show()
刘二第八讲,加载数据集
具体内容参考Pytorch深度学习——加载数据集(b站刘二大人)P8讲 加载数据集_努力学习的朱朱的博客-CSDN博客_diabetes.csv.gz【Pytorch深度学习实践】B站up刘二大人之Dataset&DataLoader-代码理解与实现(7/9)_nemo_0410的博客-CSDN博客
import numpy as np
import matplotlib.pyplot as plt
import torch
from torch.utils.data import Dataset, DataLoader
"""
Dataset是不能实例化的抽象类,所以只能被继承
DataLoader用来加载数据,不是抽象类,可实例化
"""
# epo_list = []
# loss_list = []
class DiabetesDataset(Dataset):
"""
DiabetesDataset类继承Dataset类
实现了几个魔术方法
重写__init__方法:
文件读取,传给xy
去xy的shape[0],即取数据的数量,也即有多少行
通过torch模块中的from_numpy函数进行数据的读取操作
返回的 x_data y_data 都是张量
重写__getitem__方法:
返回x_data的索引 和 y_data的索引
重写__len__方法:
返回数据第一位的数值
"""
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0]
#通过拿到xy矩阵每行的第一个从而得知数据样本的个数
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
# 通过索引将数据拿出
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
"""
读取文件diabetes文件;返回dataset
通过DataLoader函数,传入参数:数据集,单词训练的样本数量;是否打乱数据集,多线程工作
"""
dataset = DiabetesDataset('diabetes.csv')
train_loader = DataLoader(dataset=dataset,
batch_size=32,
shuffle=True,
num_workers=2)
class Model(torch.nn.Module):
"""
继承Module类,
搭建不同层数中权值参数维度的变化。
搭建一个sigmoid函数
都是用torch库中封装好的函数
"""
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
"""
:param x: 特征
:return: 预测数据
"""
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
"""
模型实例化--model
调用BCELoss损失函数
选择SGD优化器,其中初始化模型参数,学习率设置为0.01
"""
model = Model()
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
if __name__ == '__main__':
for epoch in range(100):
for i, data in enumerate(train_loader, 0):
"""
enumerate(train_loader, 0),其中是对train_loader迭代,而后面的0则是索引,表示从
从train_loader拿到一个xy元组赋值给data
i:第几次循环;
data:【张量每个数据集,张量每个数据对应的标签】
张量每个数据集:一个列表,batch个元素;每个元素是由一条数据中的特征所构成的列表。
张量每个数据对应的标签:一个列表,batch个元素,每个元素是由数据中的标签构成的列表。
[tensor([[], [], []]), tensor([[], [], []])]
"""
# print("i", i)
# print("data", data)..
inputs, labels = data
# print(inputs.shape(0))
"""
元组的赋值方式
传出列表中的两个元素,都是张量
inputs:tensor([[], [], []])
labels:tensor([[], [], []])
"""
# print("inputs", inputs)
# print("labels", labels)
"""
将数据集传入模型,得到预测值的张量形式
通过criterion函数返回损失值--loss-张量
输出:第几次循环所有数据集,当前循环下,训练的第几组(一个batch长度为一组)的数据集,和相应的损失值的高精度格式
梯度值清零
反向传播
利用优化器进行参数更新
"""
y_pred = model(inputs)
loss = criterion(y_pred, labels)
# loss_list.append(loss.item())
# epo_list.append(epoch+i)
print(epoch, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
# print('loss_list=',loss_list,'epo_list=',epo_list)
# plt.plot(epo_list,loss_list)
# plt.show()以上是关于Pytorch反向传播实现——up主:刘二大人《PyTorch深度学习实践》的主要内容,如果未能解决你的问题,请参考以下文章
PyTorch学习2B站刘二大人《PyTorch深度学习实践》——梯度下降算法(Gradient Descent)
PyTorch学习2B站刘二大人《PyTorch深度学习实践》——梯度下降算法(Gradient Descent)
PyTorch学习1B站刘二大人《PyTorch深度学习实践》——线性模型(Linear Model)