Linux进程理解与学习(Ⅰ)
Posted 诺诺的包包
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux进程理解与学习(Ⅰ)相关的知识,希望对你有一定的参考价值。
环境:centos7.6,腾讯云服务器
Linux文章都放在了专栏:【 Linux 】欢迎支持订阅 🌹
相关文章推荐:
【Linux】冯.诺依曼体系结构与操作系统
进程概念
什么是进程?
进程是什么?我们打开任务管理器可以看到有很多的程序正在运行状态,并且上面写着进程二字。难道进程就是指这些被运行起来的程序吗?课本上对于进程是这么说的:程序的一个执行实例,正在执行的程序等。
windows下的进程
但是实际上这种说法并不完全准确?(举个例子,一个仅仅进入学校的人,并不能算是这个学校的学生,只有这个人的信息被加载到学校的教务系统,并且被这个学校所管理的人,才称得上学生。这里的学校就是指内存,数据只有加载到内存,并被OS所管理,这才算是一个完整的进程)。
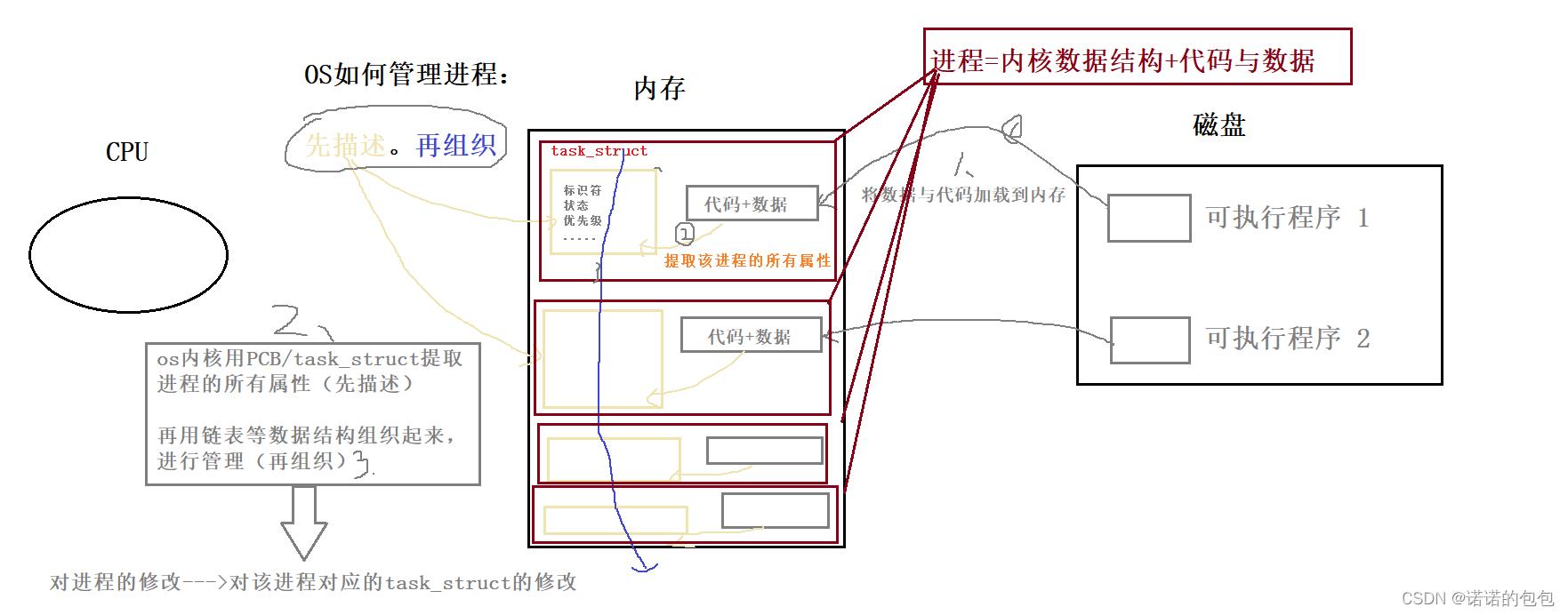
os管理进程
在前文我们知道了cpu一般不会与外设进行直接沟通,而是与内存打交道。所以我们在磁盘上的程序被运行时,要将数据与代码加载到内存中。由操作系统来进行管理。具体怎么来管理呢?先描述,再组织。
所谓的 先描述实际上是指 OS会用一个 特定的结构体( PCB/task_struct)来 提取该进程的各种属性(这里的属性与加载到内存中的数据与代码无关,或者说仅仅只有一点点的关系,即可以通过对应的 task_struct找到该进程的代码和数据)。 组织是指 OS会以链表或者其它的数据结构将各个task_struct组织起来,方便管理。( 对进程的修改--->对链表或者其它数据结构的增删查改, 比如我们结束一个进程,实际上就是删掉数据结构中对应的pcb)
★上面啰嗦一大堆,无非就是说两个事:
结论一:进程=os内核关于该进程的相关数据结构(PCB/task_struct)+当前程序加载到内存的代码与数据。
结论二:OS如何管理进程?先描述(pcb/task_struct),再组织(链表等数据结构)。
PCB — 进程控制块
进程需要被OS管理,管理的本质就是先描述,再组织。而PCB就是用来描述进程的一种特定结构体。在Linux系统下的PCB就是task_struct。
task_struct内容分类
task_struct结构体中主要包含了以下信息,了解一下即可:
标示符: 描述本进程的唯一标示符,用来区别其他进程。
状态: 任务状态,退出代码,退出信号等。
优先级: 相对于其他进程的优先级。
程序计数器: 程序中即将被执行的下一条指令的地址。
内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针
上下文数据: 进程执行时处理器的寄存器中的数据[休学例子,要加图CPU,寄存器]。
I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
其他信息
如何查看进程
第一种方法:通过ps指令
我们输入ps axj就可以查看当前所有进程信息,同时,由于进程信息较多,我们可以利用之前学过的管道,以及grep用来筛选过滤,从而拿到我们想要的进程信息。如下:
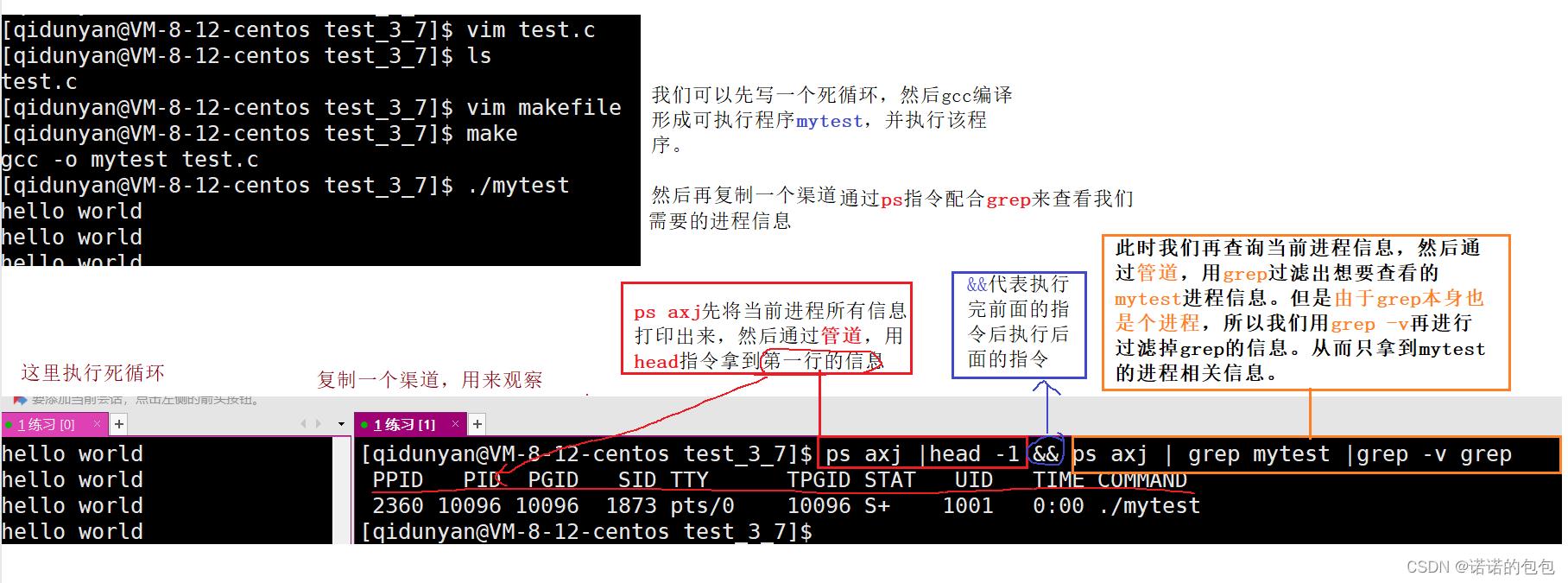
第二种方法:通过函数getpid()
在上面task_struct内容中,有一个是标识符,用来区分其他进程。这里的标识符,实际就是指PID。每一个进程都有自己的pid,并且每一次运行,pid的值都会发生变化(一般都是逐渐递增,当下一次重新登陆时,又是随机值)。
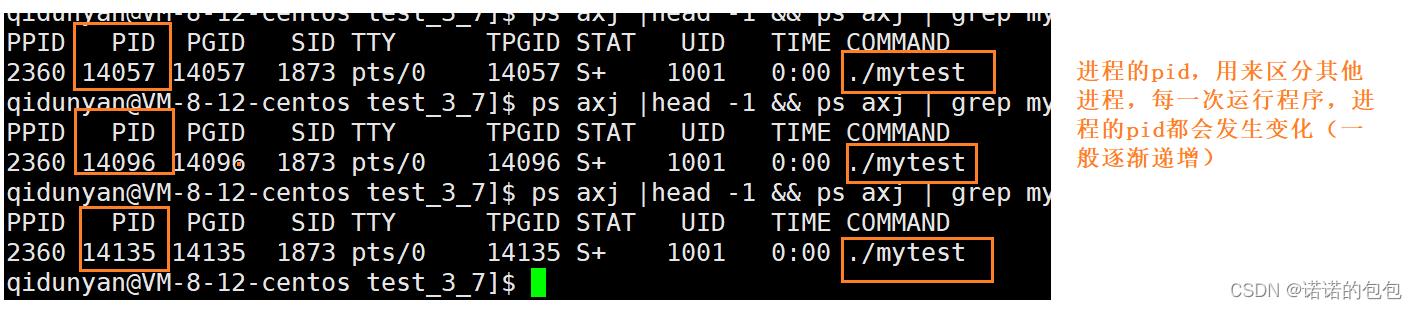
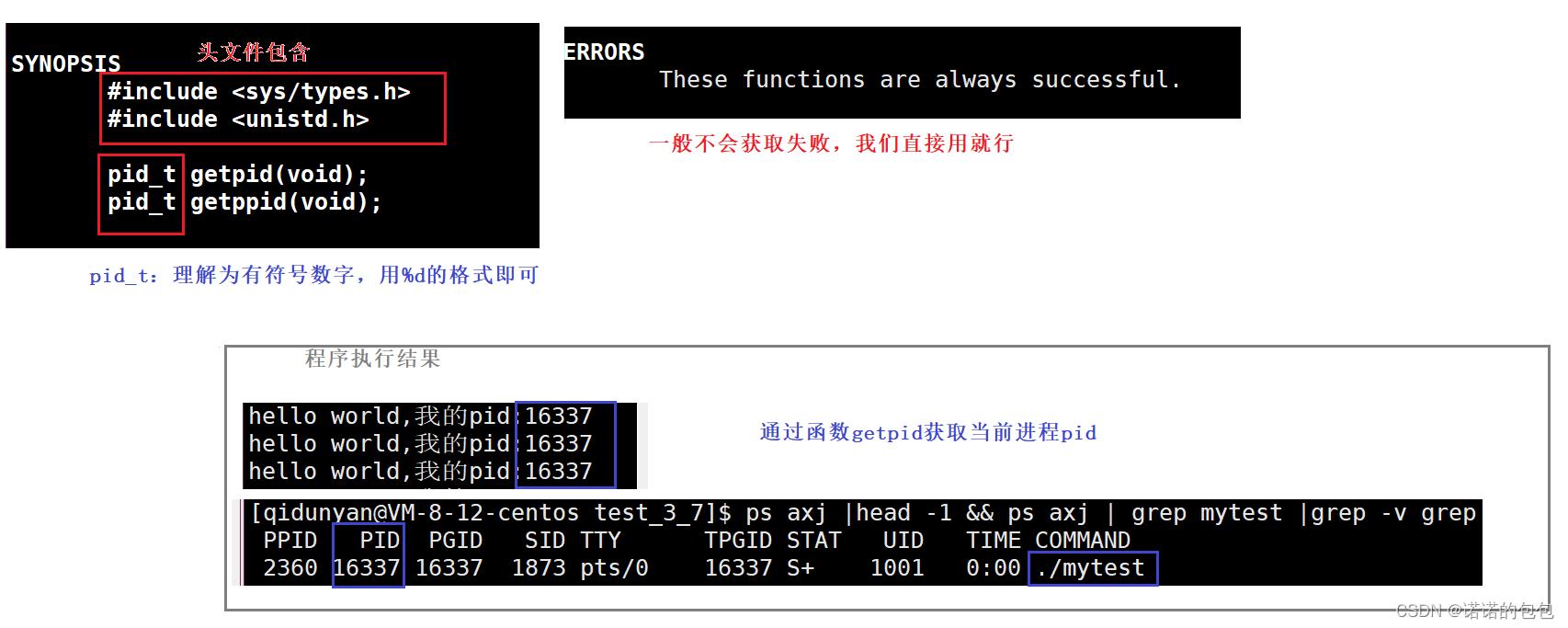
而我们可以通过系统调用函数getpid()来获取当前进程的pid。我们可以用man手册来查询getpid()的使用。我们可以通过如下的简单代码来验证。
#include<stdio.h>
//头文件包含
#include<unistd.h>
#include<sys/types.h>
int main()
while(1)
//获取当前进程pid
printf("hello world,我的pid:%d\\n",getpid());
sleep(1);
return 0;
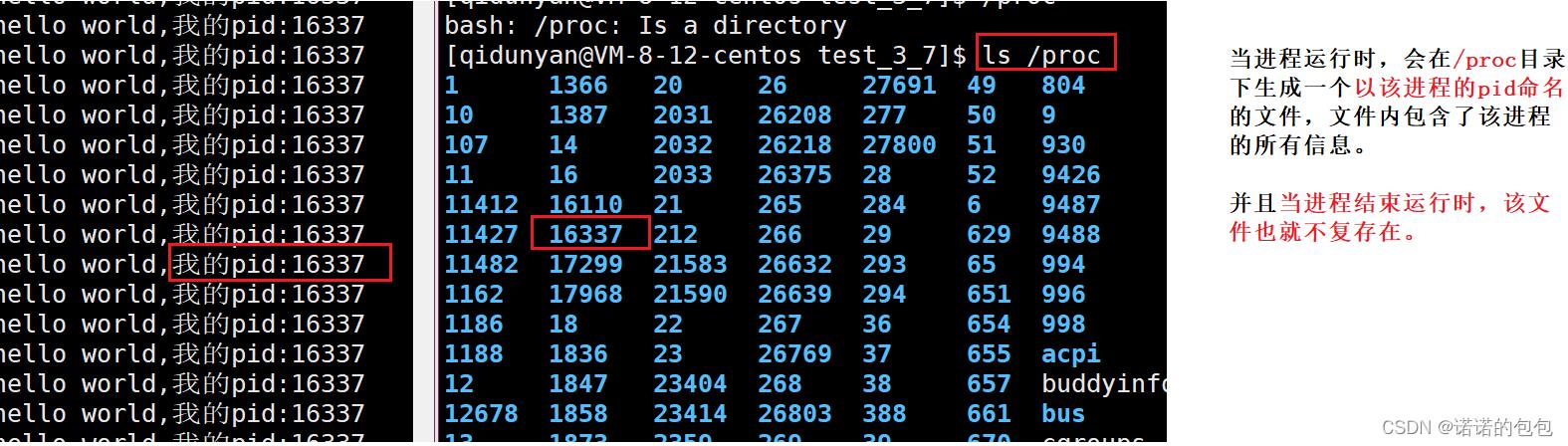
第三种方法:在路径/proc下查看
事实上,我们在执行一个程序时,会在/proc目录下生成一个以当前程序的pid命名的目录文件,该目录文件内包含了当前进程的所有信息。并且还有一个特点:当该程序停止运行时,以pid命名的文件会自动销毁。
如何中止进程
★三种方法:
我们可以通过指令kill -9进程pid来中止进程
通过热键ctrl c来中止当前进程
通过指令killall 进程名称 来中止进程
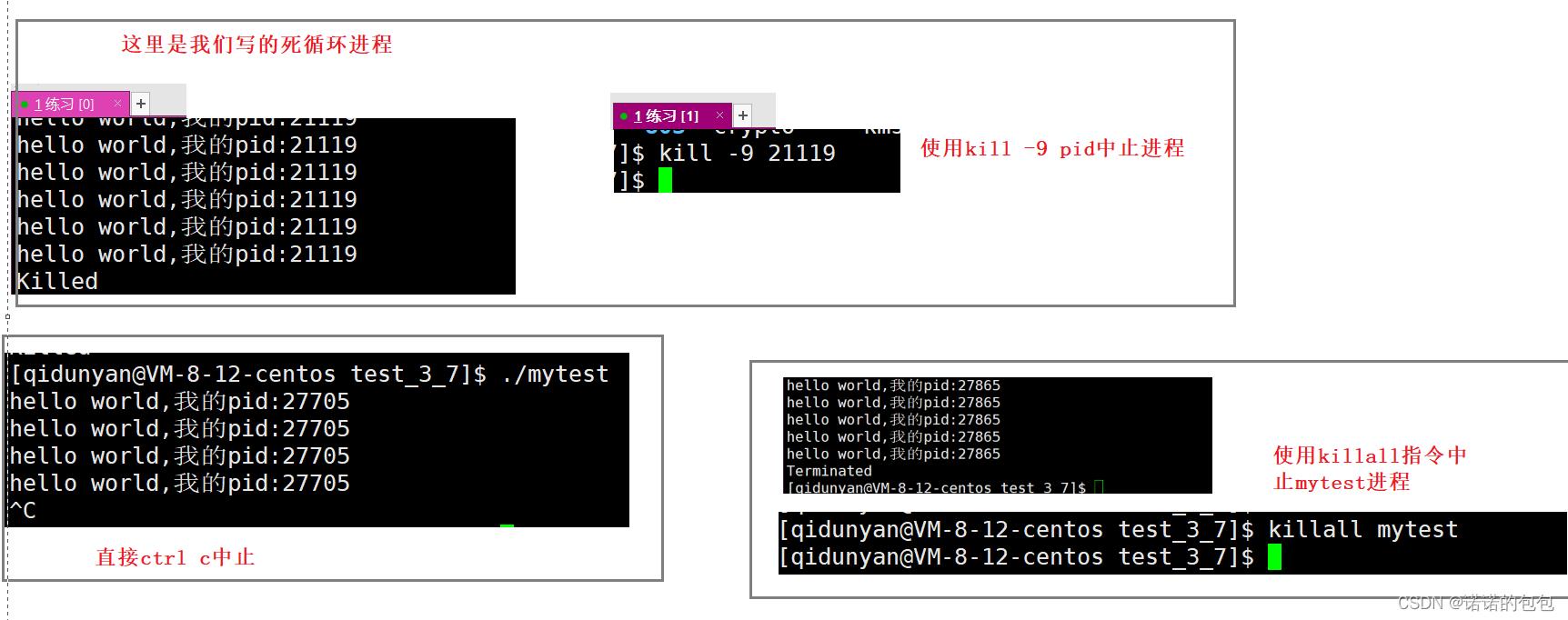
三种方式终止进程
父子进程
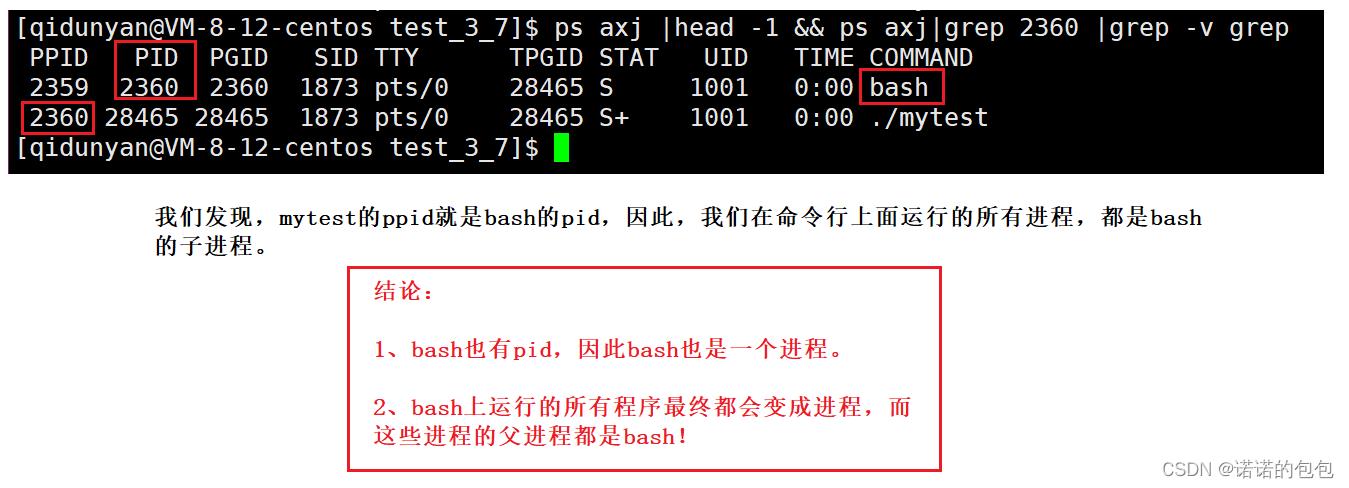
PPID
进程之间存在父子关系,我们知道,bash是命令行解释器,当我们在命令行输入指令执行一个进程时,我们执行的进程就是bash的子进程。究竟是否如我们所说?我们可以验证一下,当然,在此之前我们要先谈一下PPID,PPID就是当前进程的父进程的pid。
fork创建子进程
我们也可以通过系统调用函数fork用来给当前进程创建子进程。我们用man手册查询fork的用法。
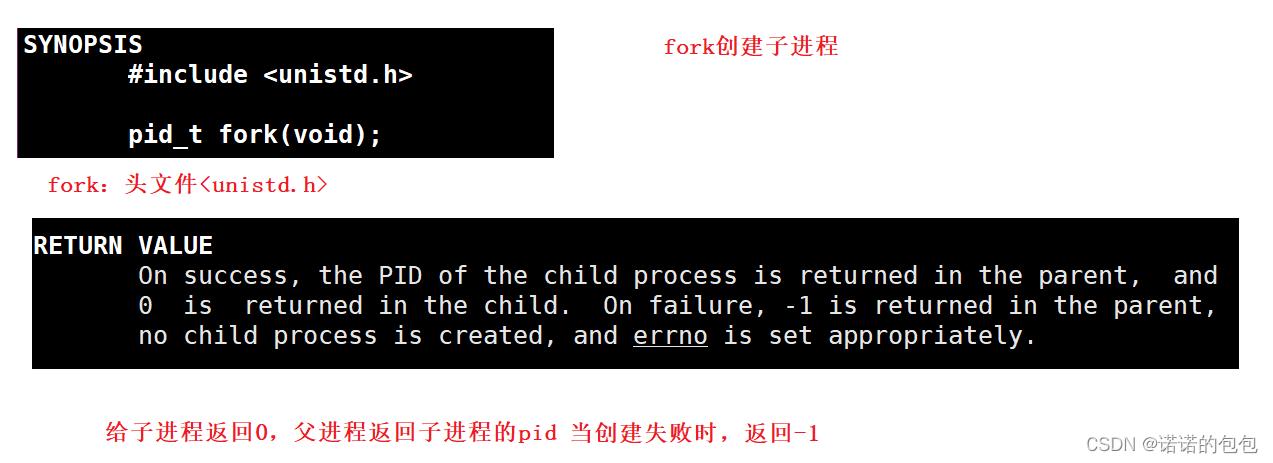
我们可以通过如下代码来进行简单测试:
#include<stdio.h>
#include<assert.h>
#include<unistd.h>
int main()
//我们用ret来接受fork的返回值
pid_t ret=fork();
assert(ret!=-1);//断言一下
//我们通常使用if语句,用来进行执行流分流
if(ret == 0)
while(1)
//此时是子进程,fork给子进程返回0
printf("我是子进程,pid:%d,ppid:%d,ret:%d,&ret:%p\\n",getpid(),getppid(),ret,&ret);
sleep(1);
else if(ret >0)
while(1)
//此时是父进程,fork给父进程返回子进程的pid
printf("我是父进程,pid:%d,ppid:%d,ret:%d,&ret:%p\\n",getpid(),getppid(),ret,&ret);
sleep(1);
return 0;
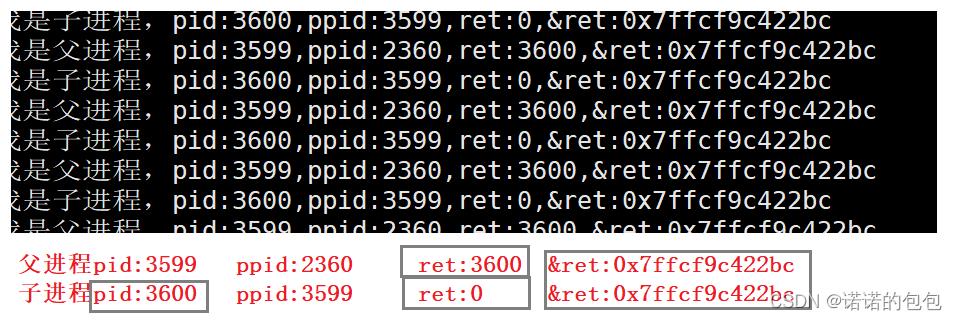
运行结果
我们发现,确实如此,不过这里有一个疑问,为什么ret的地址相同,但是ret的值却不相同呢?我们从未见过这种现象:同一个变量竟然有两个返回值。这是为什么呢?实际上,我们在函数的最后有一个return 0,而fork之后的代码是父子进程共享的,也就是说,return这个语句被执行了两次,并且当return执行时,函数体内部是已经执行完了的。所以会有两个返回值。
为了验证fork之后的代码,被父子进程共享,我们可以写一个简简单单的代码用来测试一下:
#include<stdio.h>
#include<unistd.h>
int main()
int ret = fork();
//这里只有一个printf
printf("hello proc,pid:%d,ppid:%d,ret:%d\\n", getpid(),getppid(),ret);
sleep(1);
return 0;

运行结果
我们发现,确实如此。不仅如此,进程还具有独立性,我们可以定义一个全局变量,父进程对
全局变量进行修改,我们发现不会影响到子进程中的那个全局变量。我们也可以进行验证:
#include<stdio.h>
#include<unistd.h>
//定义全局变量
int a=100;
int main()
pid_t ret=fork();
if(ret == 0)
while(1)
//子进程,不对a做修改
printf("我是子进程,a=%d,&a=:%p\\n",a,&a);
sleep(1);
else
while(1)
//父进程,对全局变量a进行修改
a+=100;
//假如进程不具有独立性,那么父进程的修改也会影响子进程,究竟会不会呢?
printf("我是父进程,a=%d,&a=:%p\\n",a,&a);
sleep(1);
return 0;
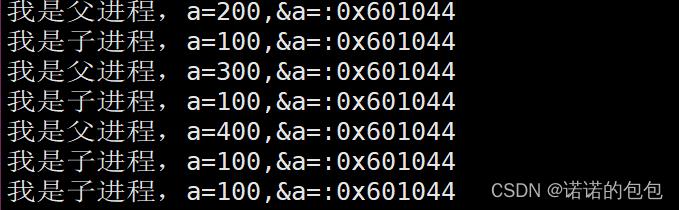
结果
我们发现确实如此,不过为什么同一个地址,对内容进行修改却不会互相影响呢?实际上这里的地址并不是真正的物理地址,并且当进程尝试对数据进行修改时,还会触发写时拷贝。(具体放在后面进程地址空间章节详细讲解)。
总结
★上面写了这么多,总结如下:
命令行启动的程序,都会变成bash的子进程
我们可以通过fork为当前进程创建子进程,fork的返回值给子进程返回0,给父进程返回子进程的pid,创建进程失败时返回-1
fork之后的代码被父子进程共享(但是谁先运行不确定)
进程具有独立性,父子进程也是如此,对其中一个进程的修改不会影响另一个进程
独立性体现在两方面:1、代码方面是可读的
2、数据方面,当一个执行流尝试修改数据时,OS会给我们的进程触发写时拷贝(后面章节详细讲解)。
end.
生活原本沉闷,但跑起来就会有风!🌹
以上是关于Linux进程理解与学习(Ⅰ)的主要内容,如果未能解决你的问题,请参考以下文章