深度学习 - 36.TF x Keras TF 常用矩阵计算方法大全
Posted BIT_666
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习 - 36.TF x Keras TF 常用矩阵计算方法大全相关的知识,希望对你有一定的参考价值。
目录
一.引言
开发深度学习任务时经常涉及到矩阵、向量的运算,例如 tf.multiply、tf.matmul、tf.tensordot、K.dot、K.batch_dot 以及 tf.einsum 等等,面对复杂的维度再加上五花八门的 API 时常处于眩晕状态,下面整理下常用矩阵计算方法示例。
二.tf.multiply
该方法用于计算哈达玛乘积,其实就是我们常说的对位相乘,其和 * 在一些场景下计算相同。给定两个向量,如果使用 multiply 就是对位相乘,如果是 dot 就是把对位相乘的结果加起来。其次如果维度的子集与待乘元素维度匹配,依旧可以对位相乘,所以该方法对维度要求较宽松。FM 的二阶项计算和平方与平方和就涉及到矩阵的对位相乘。
1.常规乘法
mat1 = tf.reshape(tf.constant([1] * 12), [3, 4])
mat2 = tf.reshape(tf.constant([2] * 12), [3, 4])
print(mat1 * mat2)
print(tf.multiply(mat1, mat2))可以看到 multiply 与 * 结果相同,因为是对位相乘,所以 MxN * MxN => MxN
tf.Tensor(
[[2 2 2 2]
[2 2 2 2]
[2 2 2 2]], shape=(3, 4), dtype=int32)
tf.Tensor(
[[2 2 2 2]
[2 2 2 2]
[2 2 2 2]], shape=(3, 4), dtype=int32)2.乘以标量
print(tf.multiply(mat1, 100))
标量直接作用与 MxN 的矩阵的每一个元素 Xij
tf.Tensor(
[[100 100 100 100]
[100 100 100 100]
[100 100 100 100]], shape=(3, 4), dtype=int32)3.不规则乘法
mat2 = tf.reshape(tf.constant([2] * 12), [3, 4])
mat3 = tf.constant([2] * 4)
print(mat3)
print(tf.multiply(mat2, mat3))mat2 为 3x4,mat3 为 4,二者相乘的到 3x4。同理,如果前者为 MxNxK,后者为 NxK,multiply 会把 NxK 的部分对位相乘,然后得到 MxNxK。
tf.Tensor([2 2 2 2], shape=(4,), dtype=int32)
tf.Tensor(
[[4 4 4 4]
[4 4 4 4]
[4 4 4 4]], shape=(3, 4), dtype=int32)三.tf.matmul
matmul 矩阵常规计算语法
1.常规矩阵相乘
mat1 = tf.reshape(tf.constant([1] * 12), [3, 4])
mat2 = tf.reshape(tf.constant([2] * 12), [4, 3])
print(tf.matmul(mat1, mat2))matmul MxN NxK => MxK,前者的 dim[-1] 与后者的 dim[0] 匹配即可。
tf.Tensor(
[[8 8 8]
[8 8 8]
[8 8 8]], shape=(3, 3), dtype=int32)2.多维矩阵相乘
mat1 = tf.reshape(tf.constant([1] * 24), [2, 3, 4])
mat2 = tf.reshape(tf.constant([2] * 24), [2, 4, 3])
print(tf.matmul(mat1, mat2))matmul MxNxK MxKxP => MxNxP,二者的首维相同,该方法主要用于两个 Batch 的样本执行矩阵计算,其中 M 看做 None,后面 matmul NxK KxP => NxP。FmFM 的 Fm 部门与 matrix 相乘就用到该方法。
tf.Tensor(
[[[8 8 8]
[8 8 8]
[8 8 8]]
[[8 8 8]
[8 8 8]
[8 8 8]]], shape=(2, 3, 3), dtype=int32)四.tf.tensordot
tf.tensordot 相对于前面的 multiply 或者 matmul 更加平凡或者说更加灵活,其提供 axes 参数,矩阵相乘只需 axes 指定的维度相等即可。
1.axes=1
默认 [-1,0],axes 代表前者的 dim[-1] 与后者的 dim[0] 对应,运算后对应维度消失。
mat1 = tf.ones(shape=[2, 4, 3])
mat2 = tf.ones(shape=[3, 2, 4])
print(tf.tensordot(mat1, mat2, axes=1))M x N x K * K x P x Q => M x N x P x Q,前后的 K 都消失。
tf.Tensor(
[[[[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]]]
[[[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]]]], shape=(2, 4, 2, 4), dtype=float32)2.axes=N
前者的后两维与后者的前两维相同,相乘后对应维度消失。
mat1 = tf.ones(shape=[2, 4, 3])
mat2 = tf.ones(shape=[3, 4, 4])
print(tf.tensordot(mat1, mat2, axes=2))看了 axes=1、2 的示例,这里也可以推广至 axes=N,大家可以自己尝试。
tf.Tensor(
[[12. 12. 12. 12.]
[12. 12. 12. 12.]], shape=(2, 4), dtype=float32)3.axes=Tuple
Tuple(_.1,_.2) axes 为元组时,._1 代表前者维度索引,._2 代表后者维度索引,要求 _.1 = _.2,相乘后对应维度消失。
mat1 = tf.ones(shape=[2, 4, 3])
mat2 = tf.ones(shape=[3, 2, 4])
print(tf.tensordot(mat1, mat2, axes=(1, 2)))2x4x3 的索引1维度为 4,3x2x4的索引2维度为4,二者相乘对应维度消失其余保留得到 2x3x3x2。
tf.Tensor(
[[[[4. 4.]
[4. 4.]
[4. 4.]]
[[4. 4.]
[4. 4.]
[4. 4.]]
[[4. 4.]
[4. 4.]
[4. 4.]]]
[[[4. 4.]
[4. 4.]
[4. 4.]]
[[4. 4.]
[4. 4.]
[4. 4.]]
[[4. 4.]
[4. 4.]
[4. 4.]]]], shape=(2, 3, 3, 2), dtype=float32)4.axes=Array(Tuple())
这个其实和 axes=1 推广至 axes=N 比较类似,这里要求前者的 ._1 * ._1 = ._2 * ._2
mat1 = tf.ones(shape=[2, 4, 3])
mat2 = tf.ones(shape=[3, 2, 4])
print(tf.tensordot(mat1, mat2, axes=((1, 2), (0, 2))))上面说的比较抽象,下面玩点真实的,(1, 2)、(0, 2) 前者维度 4*3 = 12 后者维度 3*4 = 12,对应维度消失,得到 2*2。虽然理解用法了,但是这里维度太多还是不好想象出来真实变换场景。axes 方法在 DCN 构建 CrossLayer 时用到。
tf.Tensor(
[[12. 12.]
[12. 12.]], shape=(2, 2), dtype=float32)五.K.dot
广义矩阵相乘,这里限制较多且无法指定维度,要求前者 dim[-1] 与 后者 dim[-2] 相等,可以看做是 tf.tensordot 的特例,即 tf.tensordot(mat1, mat2, axes=(-1, -2))。通过其定义我们也可以看出其主要用于 TF lookup 得到向量后与参数矩阵相乘使用,第一个维度看做是 None,然后用后面的矩阵相乘。
mat1 = tf.ones(shape=[2, 4, 3])
mat2 = tf.ones(shape=[6, 3, 4])
print(K.dot(mat1, mat2))
print(tf.tensordot(mat1, mat2, axes=(-1, -2)))2x4x3 的最后一维是3,6x3x4 的倒数第二维是3,相乘然后对位维度消失得到 2x4x6x4,大家可以用 tf.tensordot axes=(-1,-2) 验证数据是否一致。
tf.Tensor(
[[[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]]
[[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]]], shape=(2, 4, 6, 4), dtype=float32)六.K.batch_dot
批量广义矩阵相乘,可以通过 axes 指定维度,两个输入的维度相等即可。如果不指定 axes,则类似 K.dot 要求 x_dim - 1 与 y_dim - 2 即前者倒1等于后者倒2。这里同样可以将 y_dim - 2 前面的维度看做 batch_size 的 None 从而实现 emb 与参数矩阵相乘,在 FwFM Fw 加权部分中用到了该方法。
1.不指定 axes
mat1 = tf.ones(shape=[8, 4, 3])
mat2 = tf.ones(shape=[8, 3, 4])
print(K.batch_dot(mat1, mat2))需要注意的是,这里相乘后不再是对位消失其余保留了即 8x4x8x4,而是8保留,4x3 与 3x4 执行矩阵计算,最后得到 8 x 4 x 4。换成符号语言就是 MxNxK 与 MxKxP 相乘的到 M x N x P,对应维度消失,首维度不变。
tf.Tensor(
[[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]], shape=(8, 4, 4), dtype=float32)2.指定 axes 为数字
mat1 = tf.ones(shape=[8, 3, 4])
mat2 = tf.ones(shape=[8, 3, 4])
print(K.batch_dot(mat1, mat2, axes=1))这里要 Dot 的 axes 会消失,即 3 消失 变成 8 x 4 x 4。
tf.Tensor(
[[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]], shape=(8, 4, 4), dtype=float32)3.指定 axes 为列表
mat1 = tf.ones(shape=[8, 4, 3])
mat2 = tf.ones(shape=[8, 3, 4])
print(K.batch_dot(mat1, mat2, axes=[2, 1]))结果以及计算思路与上面不指定 axes 相同。
tf.Tensor(
[[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]
[[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]
[3. 3. 3. 3.]]], shape=(8, 4, 4), dtype=float32)4.二者维度不一致

mat1 = tf.ones(shape=[8, 4, 8])
mat2 = tf.ones(shape=[8, 8])
print(K.batch_dot(mat1, mat2))mat1 看做是 lookup 的批次样本 None x Field x EmdDim 后者为参数矩阵 EmdDim x EmdDim,再次计算时保留 mat1 的 batch_size 即 None,这里会做 sumed 处理,所以最后得到 8 x 4。
tf.Tensor(
[[8. 8. 8. 8.]
[8. 8. 8. 8.]
[8. 8. 8. 8.]
[8. 8. 8. 8.]
[8. 8. 8. 8.]
[8. 8. 8. 8.]
[8. 8. 8. 8.]
[8. 8. 8. 8.]], shape=(8, 4), dtype=float32)这里不好理解的话也可以看下官方给的示例:

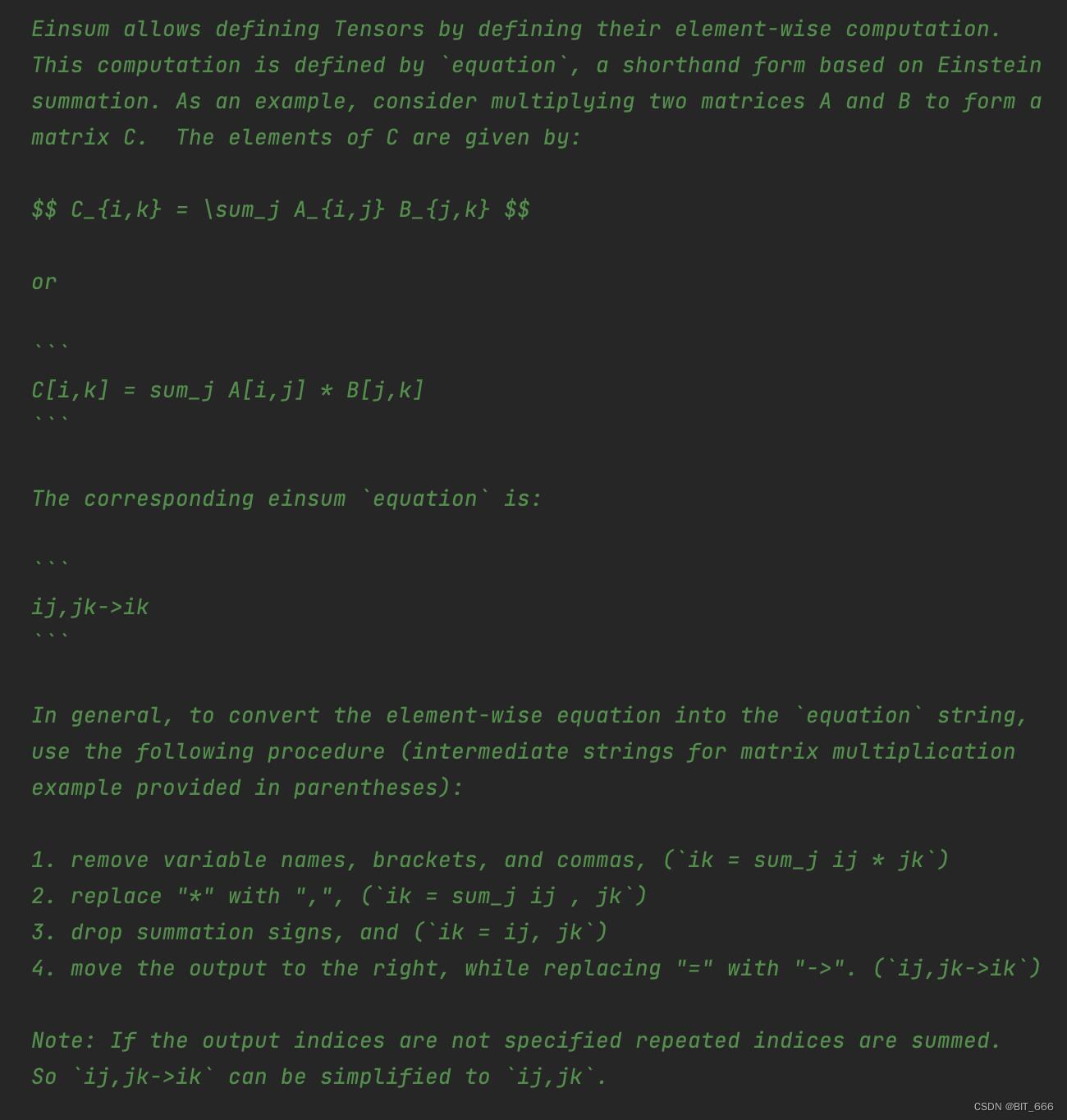
七.tf.einsum
爱因斯坦求和约定,这里使用更加 common 的表达式方式制定维度。
1.求和操作
mat1 = tf.ones(shape=[8, 4, 8])
mat2 = tf.einsum("ijk->ij", mat1)
print(mat2)相当于 reduce_sum,将给定矩阵的第三维累加起来,如果换做数学语言:

即将 K 维的数字累加,如果换做是程序语言:
i, j, k = mat1.shape[0], mat1.shape[1], mat1.shape[2]
mat1 = np.ones(shape=[8, 4, 8])
mat2 = np.zeros(shape=[i, j])
for i_ in range(i):
for j_ in range(j):
for k_ in range(k):
mat2[i_][j_] += mat1[i_][j_][k_]
print(mat2)对哪个 axis 求和,哪个维度消失,所以 8x4x8 对 ijk 的 k 即第三维求和所以剩 ij 即 8x4。
[[8. 8. 8. 8.]
[8. 8. 8. 8.]
[8. 8. 8. 8.]
[8. 8. 8. 8.]
[8. 8. 8. 8.]
[8. 8. 8. 8.]
[8. 8. 8. 8.]
[8. 8. 8. 8.]]2.矩阵乘法
mat1 = tf.ones(shape=[2, 10, 8])
mat2 = tf.ones(shape=[8, 8])
mat3 = tf.einsum("bij,mn->bin", mat1, mat2)
print(mat3)矩阵乘法 None[b] x Filed[i] x EmdDim[j] EmbDim[j] x EmdDim[k] => None x Filed x EmdDim [bik]
相当于 matmul,数学语言:

消失的维度放到求和符号中,剩下的维度保留,最终维度 2 x 10 x 8,程序语言:
b, i, j = mat1.shape[0], mat1.shape[1], mat1.shape[2]
m, n = mat2.shape[0], mat2.shape[1]
mat3 = np.zeros(shape=[b, i, j])
for b_ in range(b):
for i_ in range(i):
for j_ in range(j):
for m_ in range(m):
for n_ in range(n):
mat3[b_][i_][j_] += mat1[b_][i_][j_] * mat2[m_][n_]
print(mat3)tf.Tensor(
[[[64. 64. 64. 64. 64. 64. 64. 64.]
[64. 64. 64. 64. 64. 64. 64. 64.]
[64. 64. 64. 64. 64. 64. 64. 64.]
[64. 64. 64. 64. 64. 64. 64. 64.]
[64. 64. 64. 64. 64. 64. 64. 64.]
[64. 64. 64. 64. 64. 64. 64. 64.]
[64. 64. 64. 64. 64. 64. 64. 64.]
[64. 64. 64. 64. 64. 64. 64. 64.]
[64. 64. 64. 64. 64. 64. 64. 64.]
[64. 64. 64. 64. 64. 64. 64. 64.]]
[[64. 64. 64. 64. 64. 64. 64. 64.]
[64. 64. 64. 64. 64. 64. 64. 64.]
[64. 64. 64. 64. 64. 64. 64. 64.]
[64. 64. 64. 64. 64. 64. 64. 64.]
[64. 64. 64. 64. 64. 64. 64. 64.]
[64. 64. 64. 64. 64. 64. 64. 64.]
[64. 64. 64. 64. 64. 64. 64. 64.]
[64. 64. 64. 64. 64. 64. 64. 64.]
[64. 64. 64. 64. 64. 64. 64. 64.]
[64. 64. 64. 64. 64. 64. 64. 64.]]], shape=(2, 10, 8), dtype=float32)3.向量对位相乘
vec1 = tf.constant([1] * 12)
vec2 = tf.constant([2] * 12)
vec3 = tf.einsum("i,i->i", vec1, vec2)
print(vec3)i,i -> i 实现 mutiply 对位相乘
tf.Tensor([2 2 2 2 2 2 2 2 2 2 2 2], shape=(12,), dtype=int32)
4.向量 dot
vec1 = tf.constant([1] * 12)
vec2 = tf.constant([2] * 12)
vec3 = tf.einsum("i,i->", vec1, vec2)
print(vec3)i,i -> 实现向量内积
tf.Tensor(24, shape=(), dtype=int32)
5.全部求和
mat1 = tf.ones(shape=[2, 10, 8])
sum_ = tf.einsum("ijk->", mat1)
print(sum_)不管多少维,-> 后面均不指定,最终得到求和结果。
tf.Tensor(160.0, shape=(), dtype=float32)
Tips:
上面展示了一些常规的使用方法,具体到实战中可以使用不同语法实现相同功能,更完整的功能介绍与维度变换打击可以直接看官方源码,都有完整的解释与示例:
以上是关于深度学习 - 36.TF x Keras TF 常用矩阵计算方法大全的主要内容,如果未能解决你的问题,请参考以下文章
HCIA-AI_深度学习_TensorFlow2模块tf.keras基本用法
HCIA-AI_深度学习_TensorFlow2模块tf.keras基本用法
HCIA-AI_深度学习_TensorFlow2模块tf.keras基本用法
深度学习笔记:tf.keras.preprocessing.image_dataset_from_directory运行错误