深度学习笔记:tf.keras.preprocessing.image_dataset_from_directory运行错误
Posted 笨牛慢耕
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习笔记:tf.keras.preprocessing.image_dataset_from_directory运行错误相关的知识,希望对你有一定的参考价值。
目录
2.2 用image_dataset_from_directory加载数据
1. 概要
被tf.keras.preprocessing.image_dataset_from_directory逼疯了。。。
昨天刚写了一个博客,记录学习使用image_dataset_from_directory从目录中加载大型数据集的过程,觉得感觉不错。今天准备正式用用这个做一个深度学习模型训练实验,自信满满地开始,然后。。。遭到了暴击。。。先记录一下这个问题,不知道有没有人碰到过同样的问题。
2. 问题描述
2.1 数据集下载和预处理
实验用数据集:猫狗数据集(cats-vs-dogs)
关于下载参见:深度学习笔记:Tensorflow BatchDataset应用示例
原始数据包存放于cats_vs_dogs目录下,其中包含cats和dogs两个子目录
为了迎合image_dataset_from_directory()的使用,基于以下代码处理从原始数据集中取一部分分别构成train, test和validation set,目录结构如下所示,每个下面都进一步包含cats和dogs两个子目录。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import utils
print(tf.__version__)
def make_subset(subset_name, start_index, end_index):
for category in ("cat", "dog"):
dir = new_base_dir / subset_name / category
src_dir = original_dir / category
print(dir)
os.makedirs(dir)
fnames = [f"i.jpg" for i in range(start_index, end_index)]
for fname in fnames:
shutil.copyfile(src=src_dir / fname, dst=dir / fname)import os, shutil, pathlib
original_dir = pathlib.Path("F:\\DL\\cats-vs-dogs")
new_base_dir = pathlib.Path("F:\\DL\\cats_vs_dogs_small")
print(original_dir, new_base_dir)
if not os.path.exists(new_base_dir):
make_subset("train", start_index=0, end_index=1000)
make_subset("validation", start_index=1000, end_index=1500)
make_subset("test", start_index=1500, end_index=2500)
else:
print('0 already exists, no need to copy the data again!'.format(new_base_dir))运行完后会得到如下目录结构:
2.2 用image_dataset_from_directory加载数据
from tensorflow.keras.preprocessing import image_dataset_from_directory
train_dataset = image_dataset_from_directory(
new_base_dir / "train",
image_size=(180, 180),
batch_size=32)
validation_dataset = image_dataset_from_directory(
new_base_dir / "validation",
image_size=(180, 180),
batch_size=32)
test_dataset = image_dataset_from_directory(
new_base_dir / "test",
image_size=(180, 180),
batch_size=32)
到此为止,一切都在掌握之中。。。
2.3 生成的三个数据集中的batch数不对?
接下来用train_dataset进行模型训练时,运行到中途报告错误退出了,似乎是运行到一个epoch的中途没有数据了。莫名其妙。。。百思不得其解。于是回头来查看以上image_dataset_from_directory()所生成的三个数据集的内容是否正确,我用以下代码来确认以上三个数据集中的batch数是不是正确。
k = 0
for next_batch in test_dataset:
print('k = ', k)
k = k + 1
print(k)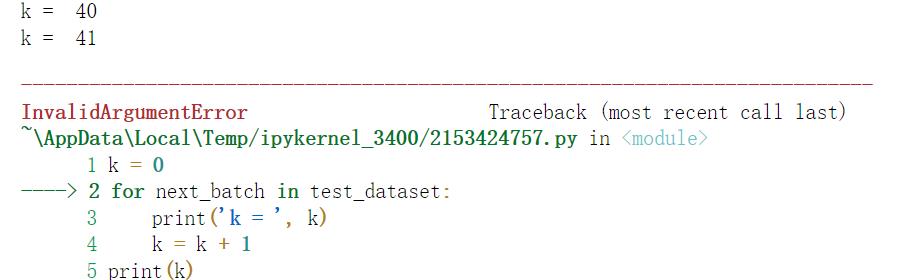
。。。
 我勒个去。。。正常来说,test目录底下由2000张照片,每个batch有32张,应该有ceil(2000/32)=63个batch,可以以上运行到k=41就出错退出了。而且报出的错误是个什么鬼嘛?
我勒个去。。。正常来说,test目录底下由2000张照片,每个batch有32张,应该有ceil(2000/32)=63个batch,可以以上运行到k=41就出错退出了。而且报出的错误是个什么鬼嘛?
接下来看看train_dataset什么情况:
k = 0
for next_batch in train_dataset:
print('k = ', k)
k = k + 1
print(k)运行到k=37时退出,但是报告的错误跟上面的test_dataset还不一样:

然后是validation_dataset什么情况:
k = 0
for next_batch in validation_dataset:
print('k = ', k)
k = k + 1
print(k)这个运行到k=31正常退出,ceil(1000/32) =32符合预期(因为k是从0开始计数的)
三个dataset有两个有问题,两个有问题的数据集所报告的错误信息还不一样。最关键的是,当我重复运行的话,每次出错的情况并不一样(test_dataset和train_dataset出错退出时的k值不一样)。。。
3. 后记
到目前为止,我一直有一个坚定的信仰:不管你碰到什么样的问题,总可以相信一定有人已经碰到过了,并且已经给出解决方案,就在万能的互联网的某个角落。但是这次这个,各种搜索啊,墙内墙外啊,中文英文啊。。。没有找到描述同样或类似问题的博客或者论坛帖子或者任何什么。。。不敢相信居然有这么好的‘运气’。
在做完以上记录后我想到了一种可能性:
我从微软网站上下载的猫狗数据集本身有问题,而恰好validation中的1000张照片是全部好照片,而train/test中则包含有错误的照片,因此每次重复运行(并没有重新创建cats_vs_dog_small目录结构)以上测试代码时,validation_dataset都没有问题,而train/test_dataset由于image_dataset_from_directory的随机性处理使得问题照片出现的batch的顺序号不同。
以上可能性有待进一步验证。
以上是关于深度学习笔记:tf.keras.preprocessing.image_dataset_from_directory运行错误的主要内容,如果未能解决你的问题,请参考以下文章