高能技巧!60 行 NumPy 代码 从头实现一个 GPT
Posted CSDN资讯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高能技巧!60 行 NumPy 代码 从头实现一个 GPT相关的知识,希望对你有一定的参考价值。

【CSDN 编者按】近日,一名工程师 Jay Mody 在一篇文章汇总将用 60 行 NumPy 代码从头实现一个 GPT。并把 GPT-2 模型权重加载到实现中,从而生成文本。
原文链接:https://jaykmody.com/blog/gpt-from-scratch/
未经授权,禁止转载!
作者 | Jay Mody 译者 | 禾木木
出品 | CSDN(ID:CSDNnews)
在本篇文章中,作者将用 60 行 NumPy 代码从头实现一个 GPT。并把 GPT-2 模型权重加载到实现中,从而生成文本。
注:
这篇文章假设你已熟悉 Python、NumPy 和一些训练神经网络的基本经验。
这个实现缺少大量的功能,目的是在保持完整的同时尽可能的简单。我们的目标是为 GPT 作为一种教育工具提供一个简单而完整的技术介绍。
了解 GPT 架构只是 LLM 难题中至关重要的一小部分。

什么是 GPT?
GPT 是 Generative Pre-trained Transformer 的缩写。这是一种基于 Transformer 的神经网络架构。
Generative:GPT 生成文本。
Pre-trained:GPT 根据大量的书籍、互联网等文本上训练出来。
Transformer:GPT 是一个仅有解码器的变换器神经网络。
像 GPT-3、LaMDA 和 Command XLarge 这类的大型语言模型(LLMs)都只是底层的 GPT。它们的特殊之处在于:1)非常大(数十亿的参数);2)在大量的数据上进行训练(数百GB的文本)。
从根本上说,GPT 生成的是有提示的文本,即使有了这个非常简单的 API(input=text,output=text),一个训练有素的 GPT 可以做一些非常棒的事情,例如写一封电子邮件、总结一本书、给 Instagram 起一些标题、向一个 5 岁的孩子解释黑洞,用 SQL 编码,甚至写遗嘱。
这就是对 GPT 及其能力的高级概述。接下来让我们深入了解更多细节。
Input / Output
GPT 的函数签名大致如下所示:
def gpt(inputs: list[int]) -> list[list[float]]:
# inputs has shape [n_seq]
# output has shape [n_seq, n_vocab]
output = # beep boop neural network magic
return outputInput
Input 是一个整数序列,表示某些文本的标记:
# integers represent tokens in our text, for example:
# text = "not all heroes wear capes":
# tokens = "not" "all" "heroes" "wear" "capes"
inputs = [1, 0, 2, 4, 6]我们基于标记器的词汇量来确定一个指令的整数值:
# the index of a token in the vocab represents the integer id for that token
# i.e. the integer id for "heroes" would be 2, since vocab[2] = "heroes"
vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
# a pretend tokenizer that tokenizes on whitespace
tokenizer = WhitespaceTokenizer(vocab)
# the encode() method converts a str -> list[int]
ids = tokenizer.encode("not all heroes wear") # ids = [1, 0, 2, 4]
# we can see what the actual tokens are via our vocab mapping
tokens = [tokenizer.vocab[i] for i in ids] # tokens = ["not", "all", "heroes", "wear"]
# the decode() method converts back a list[int] -> str
text = tokenizer.decode(ids) # text = "not all heroes wear"简而言之:
我们有一个字符串
我们使用一个标记器将其分解成更小的部分,称为指令(tokens)
我们使用词汇表将这些标记映射成整数。
在实践中,我们使用更先进的标记化方法,而不是简单地通过空白分割,例如 Byte-Pair Encoding 或 WordPiece,但原理是一样的:
有一个词汇表,将字符串标记映射为整数索引
有一个编码方法可以将str->list[int]转换。
有一个解码方法可以将list[int] -> str转换。
Output
Output 是一个二维数组,其中 output[i][j] 是模型的预测概率,即 vocab[j] 的令牌是下一个指令 inputs[i+1]。例如:
vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
inputs = [1, 0, 2, 4] # "not" "all" "heroes" "wear"
output = gpt(inputs)
# ["all", "not", "heroes", "the", "wear", ".", "capes"]
# output[0] = [0.75 0.1 0.0 0.15 0.0 0.0 0.0 ]
# given just "not", the model predicts the word "all" with the highest probability
# ["all", "not", "heroes", "the", "wear", ".", "capes"]
# output[1] = [0.0 0.0 0.8 0.1 0.0 0.0 0.1 ]
# given the sequence ["not", "all"], the model predicts the word "heroes" with the highest probability
# ["all", "not", "heroes", "the", "wear", ".", "capes"]
# output[-1] = [0.0 0.0 0.0 0.1 0.0 0.05 0.85 ]
# given the whole sequence ["not", "all", "heroes", "wear"], the model predicts the word "capes" with the highest probability为了获得整个序列的下一个指令预测,我们只需取 output[-1] 中概率最高的一个指令 :
vocab = ["all", "not", "heroes", "the", "wear", ".", "capes"]
inputs = [1, 0, 2, 4] # "not" "all" "heroes" "wear"
output = gpt(inputs)
next_token_id = np.argmax(output[-1]) # next_token_id = 6
next_token = vocab[next_token_id] # next_token = "capes"将概率最高的指令作为我们的最终预测,通常被称为 greedy decoding 或 greedy sampling。
预测一个序列中的下一个逻辑词的任务被称为语言建模。因此,我们可以把 GPT 称为语言模型。
生成一个词是很酷,但整个句子、段落等呢...?
生成文本
自回归
我们可以通过反复询问模型预测下一个指令来生成完整的句子。在每次迭代时,我们将预测的指令追加到输入中:
def generate(inputs, n_tokens_to_generate):
for _ in range(n_tokens_to_generate): # auto-regressive decode loop
output = gpt(inputs) # model forward pass
next_id = np.argmax(output[-1]) # greedy sampling
inputs = np.append(out, [next_id]) # append prediction to input
return list(inputs[len(inputs) - n_tokens_to_generate :]) # only return generated ids
input_ids = [1, 0] # "not" "all"
output_ids = generate(input_ids, 3) # output_ids = [2, 4, 6]
output_tokens = [vocab[i] for i in output_ids] # "heroes" "wear" "capes"这个预测未来值(回归),并将其加回输入(自动)的过程就是为什么你可能看到 GPT 被描述为自回归的原因。
采样
我们可以通过从概率分布中抽样而不是贪婪地样,为我们的生成引入一些随机性(随机性):
inputs = [1, 0, 2, 4] # "not" "all" "heroes" "wear"
output = gpt(inputs)
np.random.choice(np.arange(vocab_size), p=output[-1]) # capes
np.random.choice(np.arange(vocab_size), p=output[-1]) # hats
np.random.choice(np.arange(vocab_size), p=output[-1]) # capes
np.random.choice(np.arange(vocab_size), p=output[-1]) # capes
np.random.choice(np.arange(vocab_size), p=output[-1]) # pants它不仅允许我们为相同的输入生成不同的句子,而且与 greedy decoding 相比,它还提高了输出的质量。
在抽样之前,使用 top-k、top-p 和温度等技术来修改概率分布也是很常见的。这进一步提高了生成的质量,并引入了超参数,我们可以通过这些参数来获得不同的生成行为(例如,增加温度使我们的模型承担更多的风险,从而更有 "创造性")。
训练
我们像其他神经网络一样训练 GPT,使用梯度下降法来训练一些损失函数。在 GPT 的情况下,我们将交叉熵损失用于语言建模任务:
def lm_loss(inputs: list[int], params) -> float:
# the labels y are just the input shifted 1 to the left
#
# inputs = [not, all, heros, wear, capes]
# x = [not, all, heroes, wear]
# y = [all, heroes, wear, capes]
#
# of course, we don't have a label for inputs[-1], so we exclude it from x
#
# as such, for N inputs, we have N - 1 langauge modeling example pairs
x, y = inputs[:-1], inputs[1:]
# forward pass
# all the predicted next token probability distributions at each position
output = gpt(x, params)
# cross entropy loss
# we take the average over all N-1 examples
loss = np.mean(-np.log(output[y]))
return loss
def train(texts: list[list[str]], params) -> float:
for text in texts:
inputs = tokenizer.encode(text)
loss = lm_loss(inputs, params)
gradients = compute_gradients_via_backpropagation(loss, params)
params = gradient_descent_update_step(gradients, params)
return params为了清楚起见,我们在 GPT 的输入中添加了 params 参数。在训练循环的每一次迭代中,我们执行梯度下降步骤来更新模型参数,使我们的模型在看到每一段新的文本时都能更好地进行语言建模。这是一个非常简化的训练设置。
请注意,我们没有使用明确标记的数据。相反,我们能够从原始文本本身产生输入/标签对。这就是所谓的自我监督学习。
这将意味着我们可以非常容易地扩大训练数据,只需向模型展示尽可能多的原始文本。例如,GPT-3 使用了来自互联网和书籍的 3000 亿个文本标记上进行训练。
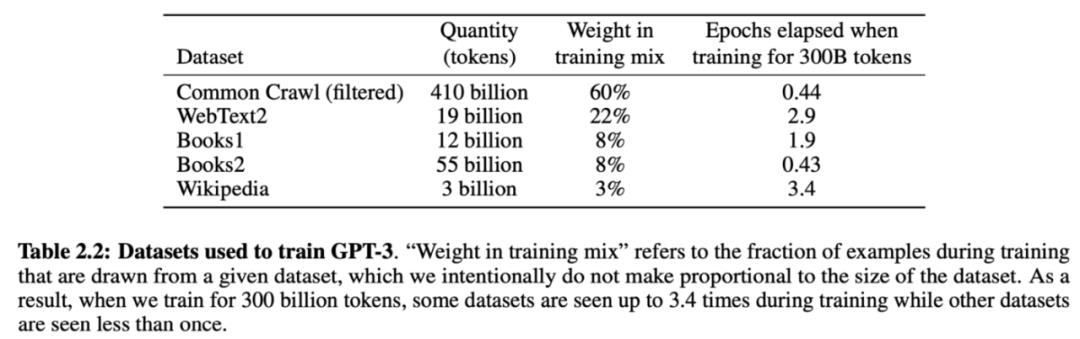
GPT-2 论文中的表 2.3
你需要一个足够大的模型,以便能够从所有数据中学习,这就是为什么 GPT-3 有 1750 亿个参数,并且可能需要花费 100 万到 1000 万美元的计算成本来训练。
这种自我监督的训练步骤被称为预训练,因为我们可以重复使用 "预训练 "的模型权重,以便在下游任务上进一步训练模型,例如分类推文是否有毒。
在下游任务上训练模型被称为微调,因为模型的权重已经被预训练成能够理解语言,所以它只是针对当前的具体任务进行微调。
这种 "一般任务进行预训练+特定任务进行微调 "的策略被称为转移学习。
提示
原则上,最初的 GPT 只是关于预训练转换学习的转化器模型的益处,类似于 BERT。
直到在 GPT-2 和 GPT-3 的论文中,我们才意识到一个预训练好的 GPT 模型本身能够执行任何任务,只需提示它并进行自回归语言建模,不需要微调。这被称为语境学习,因为该模型只是利用提示的语境来执行任务。语境学习可以是零次、一次或几次。

当然,你可以将 GPT 看作是一个聊天机器人,而不是让它明确地做 "任务"。对话历史被作为提示传递到模型中,也许会在前面加上一些描述,如 "你是一个聊天机器人等"。如果你改变了提示,你甚至可以给你的聊天机器人一个角色。
有了这些,让我们最后来看看实际的实现吧。

安装
克隆本教程的存储库:
git clone https://github.com/jaymody/picoGPT
cd picoGPT安装依赖项:
pip install -r requirements.txt请注意,如果你使用的是 M1 Macbook,则在运行 pip 安装之前,需要在 requirements.txt 中将 tensorflow 更改为 tensorflow macos。此代码在 Python 3.9.10上 进行了测试。
每个文件的快速细分:
encoder.py 包含 OpenAI 的 BPE Tokenizer 的代码;
utils.py 包含下载和加载 GPT-2 模型权重、标记器和超参数的代码;
gpt2.py 包含实际的 GPT 模型和生成代码,我们可以将其作为 python 脚本运行;
gpt2pico.py 与 gpt2.py 相同,但代码行更少。
我们将从头开始重新实现 gpt2.py,因此让我们删除它并将其重新创建为空文件:
rm gpt2.py
touch gpt2.py首先,将以下代码粘贴到 :gpt2.py
import numpy as np
def gpt2(inputs, wte, wpe, blocks, ln_f, n_head):
pass # TODO: implement this
def generate(inputs, params, n_head, n_tokens_to_generate):
from tqdm import tqdm
for _ in tqdm(range(n_tokens_to_generate), "generating"): # auto-regressive decode loop
logits = gpt2(inputs, **params, n_head=n_head) # model forward pass
next_id = np.argmax(logits[-1]) # greedy sampling
inputs = np.append(inputs, [next_id]) # append prediction to input
return list(inputs[len(inputs) - n_tokens_to_generate :]) # only return generated ids
def main(prompt: str, n_tokens_to_generate: int = 40, model_size: str = "124M", models_dir: str = "models"):
from utils import load_encoder_hparams_and_params
# load encoder, hparams, and params from the released open-ai gpt-2 files
encoder, hparams, params = load_encoder_hparams_and_params(model_size, models_dir)
# encode the input string using the BPE tokenizer
input_ids = encoder.encode(prompt)
# make sure we are not surpassing the max sequence length of our model
assert len(input_ids) + n_tokens_to_generate < hparams["n_ctx"]
# generate output ids
output_ids = generate(input_ids, params, hparams["n_head"], n_tokens_to_generate)
# decode the ids back into a string
output_text = encoder.decode(output_ids)
return output_text
if __name__ == "__main__":
import fire
fire.Fire(main)细分为 4 个部分:
1、gpt2 函数是我们将要实现的实际 GPT 代码。您会注意到,除了输入之外,函数签名还包含一些额外的内容:
wte、wpe、block 和 lnf 是我们模型的参数。
n_head 是正向传递期间需要的超参数。
2、该函数是我们此前了解的自回归解码算法。为了简单起见,我们使用贪婪采样。tqdm 是一个进度条,帮助我们可视化解码过程,因为它一次生成一个指令。
3、main( )主函数处理:
加载标记器(编码器)、模型权重(参数)和超参数(hparam)
使用 tokenizer 将输入提示编码为指令 ID
调用生成函数
将输出 ID 解码为字符串
4、fire.fire(main)只是将我们的文件转换成一个 CLI 应用程序,因此我们最终可以使用:python-gpt2.py“some prompt here”运行代码
让我们仔细看看编码器、hparam 和 params,在笔记本或交互式 Python 会话中,运行:
from utils import load_encoder_hparams_and_params
encoder, hparams, params = load_encoder_hparams_and_params("124M", "models")这将把必要的模型和标记器文件下载到我们的代码中,并将编码器、hparam 和 params 加载到我们的代码中。
编码器
encoder 是 GPT-2 使用的 BPE tokenizer。
>>> ids = encoder.encode("Not all heroes wear capes.")
>>> ids
[3673, 477, 10281, 5806, 1451, 274, 13]
>>> encoder.decode(ids)
"Not all heroes wear capes."使用 tokenize r的词汇(存储在 encoder.decoder 中),我们可以看一下实际的指令是什么。
>>> [encoder.decoder[i] for i in ids]
['Not', 'Ġall', 'Ġheroes', 'Ġwear', 'Ġcap', 'es', '.']注意,有时我们的指令是单词(如Not),有时是单词但前面会有空格(如 Ġall,Ġ 代表空格),有时是单词的一部分(如 capes 被分成 Ġcap 和 es),有时是标点符号(如.)。
BPE 的一个好处是它可以对任何任意的字符串进行编码。如果它遇到了词汇表中没有的东西,它只是将其分解为它所理解的子字符串:
>>> [encoder.decoder[i] for i in encoder.encode("zjqfl")]
['z', 'j', 'q', 'fl']我们还可以检查词汇的大小:
>>> len(encoder.decoder)
50257当我们加载 tokenizer 时,我们正在从一些文件中加载已经训练好的词汇和字节对合并,这些文件是在运行 load_encoder_hparams_and_param 时与模型文件一起下载。
超参数
hparams 是一个字典,包含模型的超参数:
>>> hparams
"n_vocab": 50257, # number of tokens in our vocabulary
"n_ctx": 1024, # maximum possible sequence length of the input
"n_embd": 768, # embedding dimension (determines the "width" of the network)
"n_head": 12, # number of attention heads (n_embd must be divisible by n_head)
"n_layer": 12 # number of layers (determines the "depth" of the network)
我们将在代码的注释中使用这些符号来显示事物的基本形态。我们还将使用 n_seq 来表示我们输入序列的长度(即n_seq = len(inputs))。
参数
params 是一个嵌套的 Json 字典,用来保存我们模型的训练权重。Json 的叶节点是 NumPy 数组。如果我们打印 params,用它们的形状替换数组,我们会得到:
>>> import numpy as np
>>> def shape_tree(d):
>>> if isinstance(d, np.ndarray):
>>> return list(d.shape)
>>> elif isinstance(d, list):
>>> return [shape_tree(v) for v in d]
>>> elif isinstance(d, dict):
>>> return k: shape_tree(v) for k, v in d.items()
>>> else:
>>> ValueError("uh oh")
>>>
>>> print(shape_tree(params))
"wpe": [1024, 768],
"wte": [50257, 768],
"ln_f": "b": [768], "g": [768],
"blocks": [
"attn":
"c_attn": "b": [2304], "w": [768, 2304],
"c_proj": "b": [768], "w": [768, 768],
,
"ln_1": "b": [768], "g": [768],
"ln_2": "b": [768], "g": [768],
"mlp":
"c_fc": "b": [3072], "w": [768, 3072],
"c_proj": "b": [768], "w": [3072, 768],
,
,
... # repeat for n_layers
]
这些都是从最初的 OpenAI tensorflow 检查点加载的:
>>> import tensorflow as tf
>>> tf_ckpt_path = tf.train.latest_checkpoint("models/124M")
>>> for name, _ in tf.train.list_variables(tf_ckpt_path):
>>> arr = tf.train.load_variable(tf_ckpt_path, name).squeeze()
>>> print(f"name: arr.shape")
model/h0/attn/c_attn/b: (2304,)
model/h0/attn/c_attn/w: (768, 2304)
model/h0/attn/c_proj/b: (768,)
model/h0/attn/c_proj/w: (768, 768)
model/h0/ln_1/b: (768,)
model/h0/ln_1/g: (768,)
model/h0/ln_2/b: (768,)
model/h0/ln_2/g: (768,)
model/h0/mlp/c_fc/b: (3072,)
model/h0/mlp/c_fc/w: (768, 3072)
model/h0/mlp/c_proj/b: (768,)
model/h0/mlp/c_proj/w: (3072, 768)
model/h1/attn/c_attn/b: (2304,)
model/h1/attn/c_attn/w: (768, 2304)
...
model/h9/mlp/c_proj/b: (768,)
model/h9/mlp/c_proj/w: (3072, 768)
model/ln_f/b: (768,)
model/ln_f/g: (768,)
model/wpe: (1024, 768)
model/wte: (50257, 768)以下代码将上述 tensorflow 变量转换为 params 字典。
作为参考,以下是参数的形状,但数字由它们所代表的 hparams 代替:
"wpe": [n_ctx, n_embd],
"wte": [n_vocab, n_embd],
"ln_f": "b": [n_embd], "g": [n_embd],
"blocks": [
"attn":
"c_attn": "b": [3*n_embd], "w": [n_embd, 3*n_embd],
"c_proj": "b": [n_embd], "w": [n_embd, n_embd],
,
"ln_1": "b": [n_embd], "g": [n_embd],
"ln_2": "b": [n_embd], "g": [n_embd],
"mlp":
"c_fc": "b": [4*n_embd], "w": [n_embd, 4*n_embd],
"c_proj": "b": [n_embd], "w": [4*n_embd, n_embd],
,
,
... # repeat for n_layers
]
当我们实现 GPT 时,你可能会需要回来参考这个字典来检查权重的形状。为了一致性,我们将把代码中的变量名与此字典的关键字进行匹配。

基本层
在我们进入实际的 GPT 架构本身之前,让我们实现一些对 GPT 不特定的更基本的神经网络层。
GELU
GPT-2 选择的非线性(激活函数)是 GELU(高斯误差线性单位),是 ReLU 的替代方案。
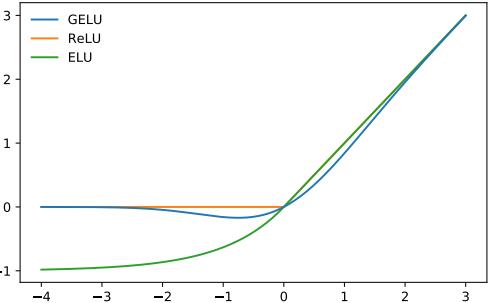
该图来自 GELU 论文
它与以下函数近似:
def gelu(x):
return 0.5 * x * (1 + np.tanh(np.sqrt(2 / np.pi) * (x + 0.044715 * x**3)))与 ReLU 一样,GELU 对输入元素进行操作:
>>> gelu(np.array([[1, 2], [-2, 0.5]]))
array([[ 0.84119, 1.9546 ],
[-0.0454 , 0.34571]])BERT 普及了 GeLU 在 transformer 模型中的使用。
Softmax
好的 Softmax:
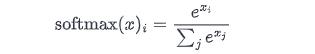
def softmax(x):
exp_x = np.exp(x - np.max(x, axis=-1, keepdims=True))
return exp_x / np.sum(exp_x, axis=-1, keepdims=True)我们使用 max(x) 的技巧来实现数值的稳定性。
Softmax 用于将一组实数转换为概率(在 0 和 1 之间,数字的总和为 1)。我们在输入的最后一个轴上应用 softmax。
>>> x = softmax(np.array([[2, 100], [-5, 0]]))
>>> x
array([[0.00034, 0.99966],
[0.26894, 0.73106]])
>>> x.sum(axis=-1)
array([1., 1.])层标准化
层标准化将值标准化为平均值为 0,方差为 1:
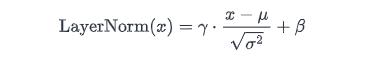
def layer_norm(x, g, b, eps: float = 1e-5):
mean = np.mean(x, axis=-1, keepdims=True)
variance = np.var(x, axis=-1, keepdims=True)
x = (x - mean) / np.sqrt(variance + eps) # normalize x to have mean=0 and var=1 over last axis
return g * x + b # scale and offset with gamma/beta params层标准化确保每层的输入始终在一致的范围内,这可以加快和稳定训练过程。与批量标准化一样,标准化输出随后被缩放,并用两个可学习向量 gamma 和 beta 进行偏移。分母中的小 ε 项用于避免除以零的误差。
我们在输入的最后一个轴上应用层标准化。
>>> x = np.array([[2, 2, 3], [-5, 0, 1]])
>>> x = layer_norm(x, g=np.ones(x.shape[-1]), b=np.zeros(x.shape[-1]))
>>> x
array([[-0.70709, -0.70709, 1.41418],
[-1.397 , 0.508 , 0.889 ]])
>>> x.var(axis=-1)
array([0.99996, 1. ]) # floating point shenanigans
>>> x.mean(axis=-1)
array([-0., -0.])线性
标准矩阵乘法 + 偏差:
def linear(x, w, b): # [m, in], [in, out], [out] -> [m, out]
return x @ w + b线性层通常被称为投影(因为它们是从一个矢量空间投射到另一个矢量空间)。

GPT 架构
GPT 架构遵循 transformer 的架构:
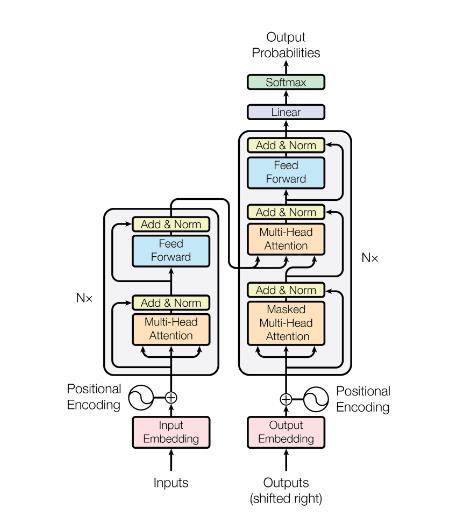
但仅使用解码器堆栈(图表的右侧部分):
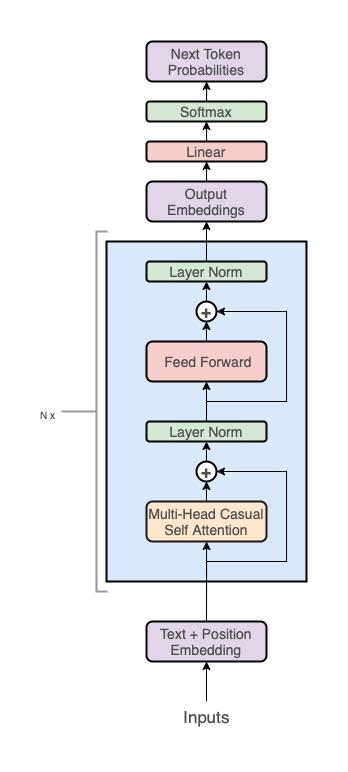
GPT架构
概括来说,GPT 架构有三个部分:
文本+位置嵌入
一个 transformer 解码器栈
一个投射到词汇的步骤
在代码中,它看起来像这样:
def gpt2(inputs, wte, wpe, blocks, ln_f, n_head): # [n_seq] -> [n_seq, n_vocab]
# token + positional embeddings
x = wte[inputs] + wpe[range(len(inputs))] # [n_seq] -> [n_seq, n_embd]
# forward pass through n_layer transformer blocks
for block in blocks:
x = transformer_block(x, **block, n_head=n_head) # [n_seq, n_embd] -> [n_seq, n_embd]
# projection to vocab
x = layer_norm(x, **ln_f) # [n_seq, n_embd] -> [n_seq, n_embd]
return x @ wte.T # [n_seq, n_embd] -> [n_seq, n_vocab]接下来我们将这三部分的内容逐一细化。
嵌入
指令嵌入
对于神经网络来说,指令 ID 本身并不是很好的表示。首先,指令 ID 的相对大小错误地传达了信息(例如,如果在我们的词汇中Apple = 5Table = 10 ,那么我们就意味着 2 * Table = Apple)。其次,对于神经网络来说,单个数字的维度并不高。
为了解决这些限制,我们将利用词向量的优势,尤其是通过学习嵌入矩阵:
wte[inputs] # [n_embd] -> [n_seq, n_embd]会想一下,wte 是一个 [n_vocab, n_embd] 矩阵。它作为一个查找表,矩阵中的第 3 行对应于我们词汇中第 1 个指令的学习向量。wte[inputs] 使用整数数组索引来检索对应于我们输入中每个指令的向量。
像我们网络中的其他参数一样,wte 是学习的。也就是说,它在训练开始时是随机初始化的,然后通过梯度下降进行更新。
位置嵌入
Transformer 架构的一个怪癖是它没有考虑到位置。也就是说,如果我们随机打乱输入,然后相应地取消打乱输出,输出将与我们一开始从未打乱输入的情况相同(输入的排序对输出没有任何影响)。
当然,单词的排序是语言的一个关键部分(duh),所以我们需要一些方法来将位置信息编码到我们的输入中。为此,我们可以直接使用另一个学习的嵌入矩阵:
wpe[range(len(inputs))] # [n_seq] -> [n_seq, n_embd]回想一下,wpe 是一个 [n_ctx, n_embd] 矩阵。矩阵的第 3 行包含一个矢量,编码输入中第 1 个位置的信息。与 wte 类似,这个矩阵是在梯度下降过程中学习的。
注意,这将我们的模型限制在最大序列长度为 n_ctx。也就是说,len(inputs)<= n_ctx 必须成立。
组合
我们可以把我们的标记和位置嵌入加在一起,得到一个同时编码标记和位置信息的组合嵌入。
# token + positional embeddings
x = wte[inputs] + wpe[range(len(inputs))] # [n_seq] -> [n_seq, n_embd]
# x[i] represents the word embedding for the ith word + the positional
# embedding for the ith position解码器栈
这是所有魔法发生的地方,也是深度学习中的 "深度 "所在。我们将传递 n_layer 转化器-解码器块传递嵌入。
# forward pass through n_layer transformer blocks
for block in blocks:
x = transformer_block(x, **block, n_head=n_head) # [n_seq, n_embd] -> [n_seq, n_embd]堆叠更多的层使我们能够控制我们的网络深度。例如,GPT-3 有高达 96 层。另一方面,选择一个更大的 n_embd 值可以让我们控制我们的网络的宽度(例如,GPT-3 使用的嵌入尺寸为 12288)。
投影到Vocab
在我们的最后一步中,我们将最后的 transformer 块的输出投射到我们的词汇表的概率分布上。
# projection to vocab
x = layer_norm(x, **ln_f) # [n_seq, n_embd] -> [n_seq, n_embd]
return x @ wte.T # [n_seq, n_embd] -> [n_seq, n_vocab]注意:
1、在进行投射到 vocab 之前,我们首先将 x 通过最后一层标准化层。这是 GPT-2 架构所特有的。
2、我们正在重新使用嵌入矩阵 wte 进行投影。其他 GPT 实现可以选择使用单独的学习权重矩阵进行投影,但是共享嵌入矩阵有几个好处。
你可以节省一些参数(尽管在GPT-3的规模下,也忽略不计)。
由于该矩阵既负责到词的映射,又负责从词的映射,所以从理论上讲,与拥有两个单独的矩阵相比,它可能会学到更丰富的表示。
3、我们不在最后应用 softmax,所以我们的输出将是逻辑,而不是 0 和 1 之间的概率。这样做有以下几个原因:
softmax 是单调,所以对于贪婪采样来说,np.argmax(logits) 等同于np.argmax(softmax(logits)),使得 softmax 成为多余。
softmax 是不可逆,这意味着我们总是可以通过应用 softmax 从逻辑到概率,但我们不能从概率回到逻辑,所以为了获得最大的灵活性,我们输出逻辑数值稳定(例如,为了计算交叉熵损失,与 log_softmax(logits)相比,取log(softmax(logits))在数值上是不稳定的。
投射到词汇表的步骤有时也被称为语言建模的头。"头 "是什么意思?一旦你的 GPT 被预训练,你可以用其他类型的投影来替换语言建模头,比如分类头,用于在某些分类任务上对模型进行微调。所以你的模型可以有多个头,有点像九头蛇。
这就是高水平的 GPT 架构,让我们实际深入了解一下解码器块在做什么。
解码器块
transformer 解码器块由两个子层组成:
多头因果自我关注
定位的前馈神经网络
def transformer_block(x, mlp, attn, ln_1, ln_2, n_head): # [n_seq, n_embd] -> [n_seq, n_embd]
# multi-head causal self attention
x = x + mha(layer_norm(x, **ln_1), **attn, n_head=n_head) # [n_seq, n_embd] -> [n_seq, n_embd]
# position-wise feed forward network
x = x + ffn(layer_norm(x, **ln_2), **mlp) # [n_seq, n_embd] -> [n_seq, n_embd]
return x每个子层在其输入上以及剩余连接都利用了层标准化(即将子层的输入加到子层的输出上)。
注意:
1、多头因果自我关注是促进输入之间交流的因素。在网络的其他任何地方,该模型都不允许输入 "看到 "对方。嵌入、位置前馈网络、层规范和 vocab 的投影都是基于我们的输入位置上操。对输入之间的关系进行建模的任务完全由注意力来完成。
2、位置式前馈神经网络只是一个普通的 2 层完全连接神经网络。这只是为我们的模型增加了一堆可学习的参数,以促进学习。
3、在最初的变压器论文中,层范数被放在输出层 _norm(x + sublayer(x)) 上,而我们将层规范放在输入 x + sublayer(layer_norm(x)) 上以匹配 GPT-2。这被称为预规范,已被证明对提高变压器的性能很重要。
4、剩余连接(由ResNet推广)有不同的用途:
更容易优化深度神经网络(即有很多层的网络)。这里的想法是,我们为梯度回流网络提供 "捷径",使其更容易优化网络中的早期层。
如果没有剩余连接,更深的模型在增加层数时性能会下降(可能是因为梯度很难在不丢失信息的情况下全部流回深度网络)。剩余连接似乎给深层网络带来了一些准确性的提升。
可以帮助解决梯度消失/爆炸的问题。
让我们对这两个子层进行更深入地了解。
位置式前馈网络
这只是一个具有 2 层的简单多层感知器:
def ffn(x, c_fc, c_proj): # [n_seq, n_embd] -> [n_seq, n_embd]
# project up
a = gelu(linear(x, **c_fc)) # [n_seq, n_embd] -> [n_seq, 4*n_embd]
# project back down
x = linear(a, **c_proj) # [n_seq, 4*n_embd] -> [n_seq, n_embd]
return x我们只是从 n_embd 投射到一个更高的维度 4*n_embd,然后再回落到 n_embd。
回顾一下,在我们的参数字典中,我们的 mlp 参数是这样的:
"mlp":
"c_fc": "b": [4*n_embd], "w": [n_embd, 4*n_embd],
"c_proj": "b": [n_embd], "w": [4*n_embd, n_embd],
多头因果的自我关注
这一层可能是 transformer 中最难理解的部分。因此,让我们通过把每个词分解成自己的部分,来达到 "多头因果的自我关注"。
注意力
自身
因果
多头
注意力
我们从头开始推导出原始变压器论文中提出的缩放点积方程:
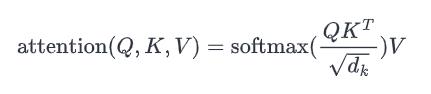
我们只需从博文中改编我们的注意力实现:
def attention(q, k, v): # [n_q, d_k], [n_k, d_k], [n_k, d_v] -> [n_q, d_v]
return softmax(q @ k.T / np.sqrt(q.shape[-1])) @ v自我
当 q、k 和 v 都来自同一来源时,我们正在进行自我关注(即让我们的输入序列关注自己):
def self_attention(x): # [n_seq, n_embd] -> [n_seq, n_embd]
return attention(q=x, k=x, v=x)我们可以通过引入 q、k、v 和注意力输出的投射来加强自我注意。
def self_attention(x, w_k, w_q, w_v, w_proj): # [n_seq, n_embd] -> [n_seq, n_embd]
# qkv projections
q = x @ w_k # [n_seq, n_embd] @ [n_embd, n_embd] -> [n_seq, n_embd]
k = x @ w_q # [n_seq, n_embd] @ [n_embd, n_embd] -> [n_seq, n_embd]
v = x @ w_v # [n_seq, n_embd] @ [n_embd, n_embd] -> [n_seq, n_embd]
# perform self attention
x = attention(q, k, v) # [n_seq, n_embd] -> [n_seq, n_embd]
# out projection
x = x @ w_proj # [n_seq, n_embd] @ [n_embd, n_embd] -> [n_seq, n_embd]
return x这使我们的模型能够学习一个 q、k 和 v 的映射,最好地帮助注意力区分输入之间的关系。
如果我们把 w_q、w_k 和 w_v 合并成一个单一的矩阵 w_fc,进行投影,然后分割结果,就可以把矩阵乘法的次数从 4 次减少到 2 次:
def self_attention(x, w_fc, w_proj): # [n_seq, n_embd] -> [n_seq, n_embd]
# qkv projections
x = x @ w_fc # [n_seq, n_embd] @ [n_embd, 3*n_embd] -> [n_seq, 3*n_embd]
# split into qkv
q, k, v = qkv = np.split(x, 3, axis=-1) # [n_seq, 3*n_embd] -> 3 of [n_seq, n_embd]
# perform self attention
x = attention(q, k, v) # [n_seq, n_embd] -> [n_seq, n_embd]
# out projection
x = x @ w_proj # [n_seq, n_embd] @ [n_embd, n_embd] = [n_seq, n_embd]
return x这样做的效率更高一些,因为现代加速器(GPU)可以更好地利用一个大的矩阵乘法,而不是 3 个独立的小的矩阵乘法顺序发生。
最后,我们添加偏置向量以匹配 GPT-2 的实现,使用我们的线性函数,并重新命名我们的参数以匹配我们的字典 linearparams。
def self_attention(x, c_attn, c_proj): # [n_seq, n_embd] -> [n_seq, n_embd]
# qkv projections
x = linear(x, **c_attn) # [n_seq, n_embd] -> [n_seq, 3*n_embd]
# split into qkv
q, k, v = qkv = np.split(x, 3, axis=-1) # [n_seq, 3*n_embd] -> 3 of [n_seq, n_embd]
# perform self attention
x = attention(q, k, v) # [n_seq, n_embd] -> [n_seq, n_embd]
# out projection
x = linear(x, **c_proj) # [n_seq, n_embd] @ [n_embd, n_embd] = [n_seq, n_embd]
return x回顾一下,从我们的参数字典中,我们的 attn 参数看起来像这样:
"attn":
"c_attn": "b": [3*n_embd], "w": [n_embd, 3*n_embd],
"c_proj": "b": [n_embd], "w": [n_embd, n_embd],
,因果关系
我们目前的自我注意力设置有一点问题,我们的输入可以看到未来!例如,如果我们的输入是 ["not", "all", "heroes", "wear", "capes"],在自我关注期间,我们允许 "wear" 看到 "capes"。这意味着我们对 "wear" 的输出概率会有偏差,因为模型已经知道正确答案是 "capes"。这是不好的,由于我们的模型刚刚学会,输入的正确答案可以从输入中得到。
为了防止这种情况,我们需要以某种方式修改我们的注意力矩阵,以隐藏或掩盖我们的输入,使其无法看到未来。例如,让我们假装我们的注意力矩阵看起来像这样:
not all heroes wear capes
not 0.116 0.159 0.055 0.226 0.443
all 0.180 0.397 0.142 0.106 0.175
heroes 0.156 0.453 0.028 0.129 0.234
wear 0.499 0.055 0.133 0.017 0.295
capes 0.089 0.290 0.240 0.228 0.153每一行对应于一个查询,每一列对应于一个键。在这种情况下,看一下 "wear"这一行,你可以看到它在最后一列参加 "capes",权重为0.295。为了防止这种情况,我们要将该条目设置为0.0。
not all heroes wear capes
not 0.116 0.159 0.055 0.226 0.443
all 0.180 0.397 0.142 0.106 0.175
heroes 0.156 0.453 0.028 0.129 0.234
wear 0.499 0.055 0.133 0.017 0.
capes 0.089 0.290 0.240 0.228 0.153一般来说,为了防止我们的输入中的所有查询看向未来,我们把所有的位置都设置为0。
not all heroes wear capes
not 0.116 0. 0. 0. 0.
all 0.180 0.397 0. 0. 0.
heroes 0.156 0.453 0.028 0. 0.
wear 0.499 0.055 0.133 0.017 0.
capes 0.089 0.290 0.240 0.228 0.153我们将这称为掩蔽。上述掩蔽方法的一个问题是,我们的行数之和不再是 1(因为我们在应用 softmax 后将其设置为 0)。为了确保我们的行之和为 1,我们需要在应用 softmax 之前修改我们的注意矩阵。
这可以通过在 softmax 之前设置要被屏蔽的条目来实现:
def attention(q, k, v, mask): # [n_q, d_k], [n_k, d_k], [n_k, d_v], [n_q, n_k] -> [n_q, d_v]
return softmax(q @ k.T / np.sqrt(q.shape[-1]) + mask) @ v其中矩阵(用于):maskn_seq=5
我们使用 -1e10 而不是 -np.inf,因为 -np.inf 会导致 nans。
在我们的注意力矩阵中加入掩码,而不是明确地将数值设置为 -1e10,因为实际上,任何数字加上 -inf 就是 -inf。
我们可以在 NumPy 中用(1-np.tri(n_seq))计算掩码矩阵 * -1e10.
综上所述,我们得到:
def attention(q, k, v, mask): # [n_q, d_k], [n_k, d_k], [n_k, d_v], [n_q, n_k] -> [n_q, d_v]
return softmax(q @ k.T / np.sqrt(q.shape[-1]) + mask) @ v
def causal_self_attention(x, c_attn, c_proj): # [n_seq, n_embd] -> [n_seq, n_embd]
# qkv projections
x = linear(x, **c_attn) # [n_seq, n_embd] -> [n_seq, 3*n_embd]
# split into qkv
q, k, v = qkv = np.split(x, 3, axis=-1) # [n_seq, 3*n_embd] -> 3 of [n_seq, n_embd]
# causal mask to hide future inputs from being attended to
causal_mask = (1 - np.tri(x.shape[0])) * -1e10 # [n_seq, n_seq]
# perform causal self attention
x = attention(q, k, v, causal_mask) # [n_seq, n_embd] -> [n_seq, n_embd]
# out projection
x = linear(x, **c_proj) # [n_seq, n_embd] @ [n_embd, n_embd] = [n_seq, n_embd]
return x多头
我们可以通过执行 n_head 单独的注意力计算来进一步改进我们的实现,将我们的查询、键和值分割成头:
def mha(x, c_attn, c_proj, n_head): # [n_seq, n_embd] -> [n_seq, n_embd]
# qkv projection
x = linear(x, **c_attn) # [n_seq, n_embd] -> [n_seq, 3*n_embd]
# split into qkv
qkv = np.split(x, 3, axis=-1) # [n_seq, 3*n_embd] -> [3, n_seq, n_embd]
# split into heads
qkv_heads = list(map(lambda x: np.split(x, n_head, axis=-1), qkv)) # [3, n_seq, n_embd] -> [3, n_head, n_seq, n_embd/n_head]
# causal mask to hide future inputs from being attended to
causal_mask = (1 - np.tri(x.shape[0])) * -1e10 # [n_seq, n_seq]
# perform attention over each head
out_heads = [attention(q, k, v, causal_mask) for q, k, v in zip(*qkv_heads)] # [3, n_head, n_seq, n_embd/n_head] -> [n_head, n_seq, n_embd/n_head]
# merge heads
x = np.hstack(out_heads) # [n_head, n_seq, n_embd/n_head] -> [n_seq, n_embd]
# out projection
x = linear(x, **c_proj) # [n_seq, n_embd] -> [n_seq, n_embd]
return x这里增加了三个步骤:
1.将 q、k、v 分成 n_head 头:
# split into heads
qkv_heads = list(map(lambda x: np.split(x, n_head, axis=-1), qkv)) # [3, n_seq, n_embd] -> [n_head, 3, n_seq, n_embd/n_head]2.计算每个头部的注意力:
# perform attention over each head
out_heads = [attention(q, k, v) for q, k, v in zip(*qkv_heads)] # [n_head, 3, n_seq, n_embd/n_head] -> [n_head, n_seq, n_embd/n_head]3.合并每个头的输出:
# merge heads
x = np.hstack(out_heads) # [n_head, n_seq, n_embd/n_head] -> [n_seq, n_embd]注意,这将每个注意力计算的维度从 n_embd 减少到 n_embd/n_head。为了降低维度,我们的模型在通过注意力建立关系模型时得到了额外的子空间。例如,也许一个注意力头负责将代词与代词所指的人联系起来。也许另一个可能负责按时期对句子进行分组。另一个可能只是负责识别哪些词是实体,哪些不是。虽然,它可能只是另一个神经网络黑盒子。
我们编写的代码在一个循环中按顺序对每个头进行注意力计算(一次一个),这样的效率并不高。在实践中,你会希望并行地进行这些计算。为了简单起见,我们还是让它按顺序进行。
至此,我们终于完成了我们的 GPT 实现,剩下的就是把它放在一起并运行我们的代码。

整合
将所有内容放在一起,我们得到 gpt2.py,整个代码只有 120 行(如果删除注释和空格,则为 60 行)。
我们将通过一下的方式测试实现:
python gpt2.py \\
"Alan Turing theorized that computers would one day become" \\
--n_tokens_to_generate 8输出:
the most powerful machines on the planet.结果证明,它是有效的!
我们可以使用以下 Dockerfile 测试我们的实现是否与 OpenAI 的官方 GPT-2 存储库给出相同的结果:
docker build -t "openai-gpt-2" "https://gist.githubusercontent.com/jaymody/9054ca64eeea7fad1b58a185696bb518/raw/Dockerfile"
docker run -dt "openai-gpt-2" --name "openai-gpt-2-app"
docker exec -it "openai-gpt-2-app" /bin/bash -c 'python3 src/interactive_conditional_samples.py --length 8 --model_type 124M --top_k 1'
# paste "Alan Turing theorized that computers would one day become" when prompted这应该给出相同的结果:
the most powerful machines on the planet.以上就是 Jay Mody 在博客的内容,大家有兴趣的可以自己试一下~忽略规模,GPT 的训练是非常标准的,相对于语言建模损失的梯度下降。当然还有很多技巧,但这些都是标准的东西。训练一个好的 GPT 模型的真正秘诀是能够扩展数据和模型。对此,你有哪些看法呢~


☞别光骂谷歌了!新版 Bing 花式“翻车”,还让用户向它道歉?
☞“C# 不停止膨胀,必将走向灭亡”
☞个人掏5000万美元、获2.3亿美金认购,造中国版OpenAI,45岁前美团联合创始人王慧文再创业!以上是关于高能技巧!60 行 NumPy 代码 从头实现一个 GPT的主要内容,如果未能解决你的问题,请参考以下文章
PPT总是做得很慢?这5个高能技巧,能让你毫不费力的完成PPT