第三节:DCGAN人脸图像生成
Posted 快乐江湖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第三节:DCGAN人脸图像生成相关的知识,希望对你有一定的参考价值。
文章目录
一:CelebFaces Attribute(CelebA)数据集介绍
CelebA数据集:CeleA是香港中文大学的开放数据,包含10177个名人身份的202599张图片,并且都做好了特征标记,这对人脸相关的训练是非常好用的数据集
这个数据集做了很多的标记,所以非常实用

有如下40种属性
- 01 5_o_Clock_Shadow 胡子,(清晨刮脸的人傍晚已长出的短髭 ) -1
- 02 Arched_Eyebrows 柳叶眉 1
- 03 Attractive 有魅力的 1
- 04 Bags_Under_Eyes 眼袋 -1
- 05 Bald 秃头的 -1
- 06 Bangs 刘海 -1
- 07 Big_Lips 大嘴唇 -1
- 08 Big_Nose 大鼻子 -1
- 09 Black_Hair 黑发 -1
- 10 Blond_Hair 金发 -1
- 11 Blurry 睡眼惺松的 -1
- 12 Brown_Hair 棕发 1
- 13 Bushy_Eyebrows 浓眉 -1
- 14 Chubby 丰满的 -1
- 15 Double_Chin 双下巴 -1
- 16 Eyeglasses 眼镜 -1
- 17 Goatee 山羊胡子 -1
- 18 Gray_Hair 白发,灰发 -1
- 19 Heavy_Makeup 浓妆 1
- 20 High_Cheekbones 高颧骨 1
- 21 Male 男性 -1
- 22 Mouth_Slightly_Open 嘴轻微的张开 1
- 23 Mustache 胡子 -1
- 24 Narrow_Eyes 窄眼 -1
- 25 No_Beard 没有胡子 1
- 26 Oval_Face 瓜子脸,鹅蛋脸 -1
- 27 Pale_Skin 白皮肤 -1
- 28 Pointy_Nose 尖鼻子 1
- 29 Receding_Hairline 发际线; 向后梳得发际线 -1
- 30 Rosy_Cheeks 玫瑰色的脸颊 -1
- 31 Sideburns 连鬓胡子,鬓脚 -1
- 32 Smiling 微笑的 1
- 33 Straight_Hair 直发 1
- 34 Wavy_Hair 卷发; 波浪发 -1
- 35 Wearing_Earrings 戴耳环 1
- 36 Wearing_Hat 带帽子 -1
- 37 Wearing_Lipstick 涂口红 1
- 38 Wearing_Necklace 带项链 -1
- 39 Wearing_Necktie 戴领带 -1
- 40 Young 年轻人 1
下载后你会看到下面三个文件夹及一个README.md文件

Anno和Eval文件夹是关于图片特征描述的,这里不再介绍,因为这是无监督学习。Img文件夹存放图片。点进去之后它含有两个文件夹和一个压缩包,含义如下
| img_celeba.7z | 纯“野生”文件,也就是从网络爬取的没有做裁剪的图片 |
|---|---|
| img_align_celeba_png.7z | 把“野生”文件裁剪出人脸部分之后的图片,png格式 |
| img_align_celeba.zip | jpg格式的,比较小(推荐使用,直接解压即可) |
将zip解压后就是我们需要的图片,它是按照编号命名的,差不多20万张图片
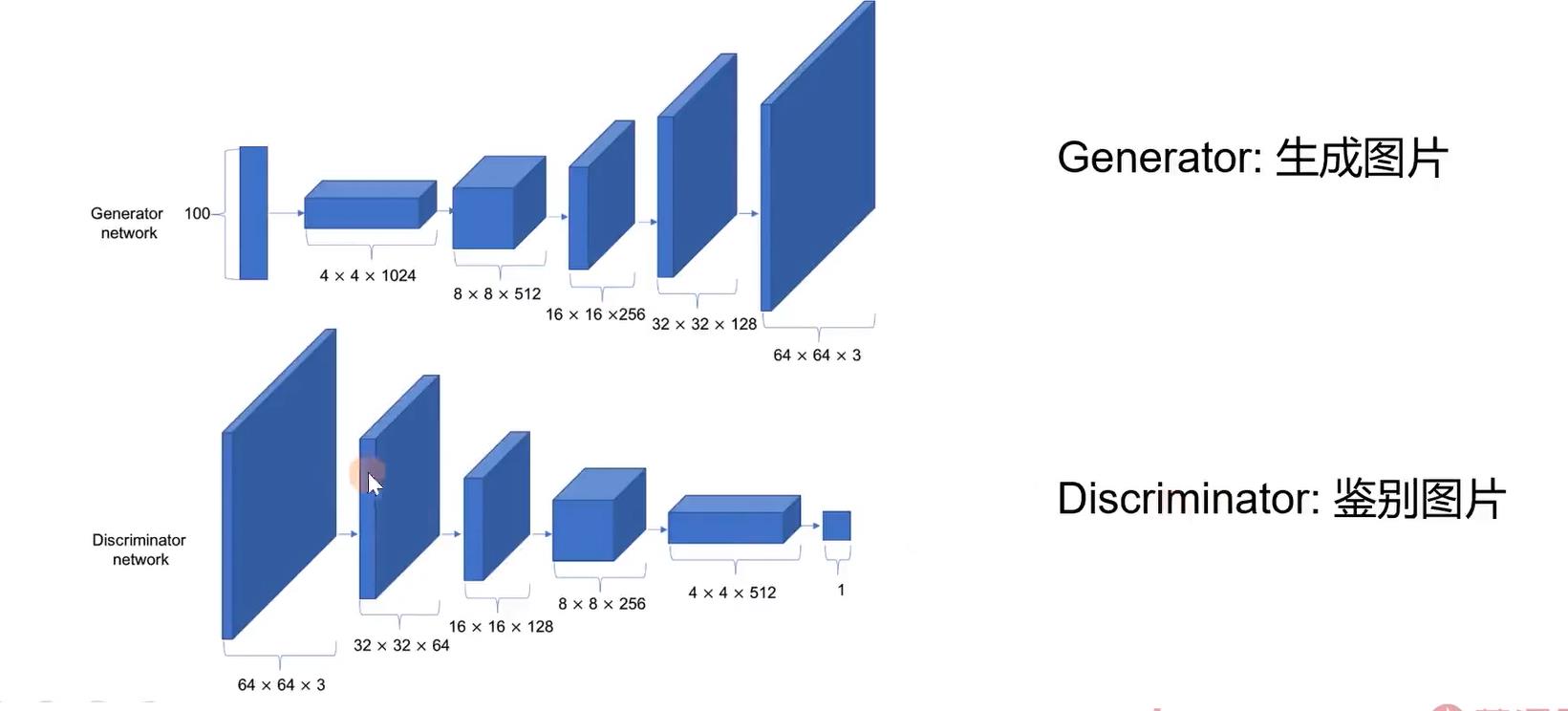
二:模型结构
三:代码编写
(1)参数配置
import torch
class Parameteres:
device = 'cuda' if torch.cuda.is_available() else 'cpu'
data_root = '~/autodl-tmp/dataset/celeba'
image_size = 64 # 生成人脸图片大小
z_dim = 100 # latent z dimension
data_channels = 3
batch_size = 64 # 8×8网格图片
beta = 0.5 # Adam参数1
init_lr = 0.0002 # Adam参数2
epochs = 1000
verbose_step = 250 # save image
save_step = 1000 # save model
parameters = Parameteres()
(2)数据集加载脚本
- GAN和以往的CNN等模型结构不同,因为是无监督学习,所以不需要标签,也没有验证集
import torchvision.utils
from torchvision import transforms
import torchvision.datasets as datasets
from torch.utils.data import DataLoader
from Parameteres import parameters
import os
# 环境变量(If use Windows)
# os.environ['KMP_DUPLICATE_LIB_OK'] = 'True'
# 变换
data_transform = transforms.Compose(
[
transforms.Resize(parameters.image_size), # 64 × 3 × 3
transforms.CenterCrop(parameters.image_size), #
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
]
)
# 反标准化,以便我们查看图片
invtrans = transforms.Compose(
[
transforms.Normalize(mean=[0., 0., 0.], std=[1/0.5, 1/0.5, 1/0.5]),
transforms.Normalize(mean=[-0.5, -0.5, -0.5], std=[1., 1., 1.])
]
)
# 数据集
data_set = datasets.ImageFolder(
root=parameters.data_root,
transform=data_transform
)
# dataloader
data_loader = DataLoader(dataset=data_set, batch_size=parameters.batch_size, shuffle=True, num_workers=8, drop_last=True)
if __name__ == '__main__':
for data, _ in data_loader:
# NCHW
print(data.size())
data = invtrans(data)
torchvision.utils.save_image(data, "./test1.png", nrow=8)
break
上面代码中标准化的目的是为了进行训练,但是最终查看图片时一定要进行“反标准化”
- 下图1是没有进行反标准化的图片
- 下图2是进行了反标准化(也即恢复为正常显示)的图片


(3)模型脚本
生成器:
import torch
import torch.nn as nn
from Parameteres import parameters
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# 输入为100维高斯向量然后送入一个Linear,然后resahpe为(4×4×1024)
self.projectionlayer = nn.Linear(parameters.z_dim, 4*4*1024)
# 转置卷积堆叠
self.generator = nn.Sequential(
nn.ConvTranspose2d(
in_channels=1024, # [N, 512, 8, 8]
out_channels=512,
kernel_size=(4, 4),
stride=(2, 2),
padding=(1,1),
bias=False),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.ConvTranspose2d(
in_channels=512, # [N, 256, 16, 16]
out_channels=256,
kernel_size=(4, 4),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.ConvTranspose2d(
in_channels=256, # [N, 128, 32, 32]
out_channels=128,
kernel_size=(4, 4),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.ConvTranspose2d(
in_channels=128, # [N, 3, 64, 64]
out_channels=parameters.data_channels,
kernel_size=(4, 4),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.Tanh() # [0, 1]
)
def forward(self, latet_z):
z = self.projectionlayer(latet_z)
z_projected = z.view(-1, 1024, 4, 4) # [N, 1024, 4, 4] NCHW
return self.generator(z_projected)
# 初始化参数
@staticmethod
def weights_init(layer):
layer_class_name = layer.__class__.__name__
if 'Conv' in layer_class_name: # 卷积层初始化方法
nn.init.normal_(layer.weight.data, 0.0, 0.02)
elif 'BatchNorm' in layer_class_name: # BatchNorm初始化方法
nn.init.normal_(layer.weight.data, 1.0, 0.02)
nn.init.normal_(layer.bias.data, 0.)
if __name__ == '__main__':
z = torch.randn(size=(64, 100))
G = Generator()
g_out = G(z)
print(g_out.size())
判别器:
import torch
import torch.nn as nn
from Parameteres import parameters
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.discriminator = nn.Sequential(
nn.Conv2d(
in_channels=parameters.data_channels, # [N, 16, 32, 32]
out_channels=16,
kernel_size=(3, 3),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.LeakyReLU(0.2),
nn.Conv2d(
in_channels=16, # [N, 32, 16, 16]
out_channels=32,
kernel_size=(3, 3),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.BatchNorm2d(32),
nn.LeakyReLU(0.2),
nn.Conv2d(
in_channels=32, # [N, 64, 8, 8]
out_channels=64,
kernel_size=(3, 3),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2),
nn.Conv2d(
in_channels=64, # [N, 128, 4, 4]
out_channels=128,
kernel_size=(3, 3),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
nn.Conv2d(
in_channels=128, # [N, 256, 2, 2]
out_channels=256,
kernel_size=(3, 3),
stride=(2, 2),
padding=(1, 1),
bias=False),
nn.BatchNorm2d(256),
nn.LeakyReLU(0.2),
)
self.linear = nn.Linear(256*2*2, 1)
self.out_ac = nn.Sigmoid()
def forward(self, image):
out_d = self.discriminator(image)
out_d = out_d.view(-1, 256*2*2)
out_d = self.linear(out_d)
out = self.out_ac(out_d)
return out
# 初始化参数
@staticmethod
def weights_init(layer):
layer_class_name = layer.__class__.__name__
if 'Conv' in layer_class_name: # 卷积层初始化方法
nn.init.normal_(layer.weight.data, 0.0, 0.02)
elif 'BatchNorm' in layer_class_name: # BatchNorm初始化方法
nn.init.normal_(layer.weight.data, 1.0, 0.02)
nn.init.normal_(layer.bias.data, 0.)
(4)训练脚本
DCGAN训练过程和最原始的GAN一样,如下,先训练判别器再训练生成器

代码如下
import os
import torch
import numpy as np
import torch.nn as nn
from tensorboardX import SummaryWriter
from model_generator import Generator
from model_discriminator import Discriminator
import torchvision
from Parameteres import parameters
from MyDataSet import data_loader, invtrans
logger = SummaryWriter('./log')
# 训练
def train():
# 模型初始化
G = Generator() # 生成器
G.apply(G.weights_init)
D = Discriminator() # 判别器
D.apply(D.weights_init)
G.to(parameters.device)
D.to(parameters.device)
# BCE损失函数
loss_function = nn.BCELoss()
# 优化器(两个)
optimizer_g = torch.optim.Adam(G.parameters(), lr=parameters.init_lr, betas=(parameters.beta, 0.999))
optimizer_d = torch.optim.Adam(D.parameters(), lr=parameters.init_lr, betas=(parameters.beta, 0.999))
# 训练步数
step = 0
# 训练标志
G.train()
D.train()
# 生成64×100的高斯分布数据,用于最后生成图片
fixed_latent_z = torch.randn(size=(64, 100), device=parameters.device)
# 主循环
for epoch in range(0, parameters.epochs):
print("-----------当前epoch:-----------".format(epoch)) # [N, 3, 64, 64]
for batch, _ in data_loader:
"""
先更新D:log(D(x)) + log(1-D(G(z)))
""" optimizer_d.zero_grad()
# 真实人脸鉴别
true_face = torch.full(size=(64, ), fill_value=0.9, dtype=torch.float, device=parameters.device)
predict_true_face = D(batch.to(parameters.device)).squeeze()
loss_d_of_true_face = loss_function(predict_true_face, true_face)
# 假人脸鉴别
fake_face = torch.full(size=(64, ), fill_value=0.1, dtype=torch.float, device=parameters.device)
latent_z = torch.randn(size=(64, 100), device=parameters.device)
predict_fake_face = D(G(latent_z)).squeeze() # G生成假人脸
loss_d_of_fake_face = loss_function(predict_fake_face, fake_face)
# 两部分加和
loss_D = loss_d_of_true_face + loss_d_of_fake_face
loss_D.backward()
optimizer_d.step()
logger.add_scalar('loSS/D', loss_D.mean().item(), step) # 有64个loss,使用均值
"""
再更新G:log(1-D(G(z)))
""" optimizer_g.zero_grad()
latent_z = torch.randn(size=[64, 100], device=parameters.device)
# 生成器要生成“真”数据尽可能瞒过判别器
true_face_of_g = torch.full(size=(64, ), fill_value=0.9, dtype=torch.float, device=parameters.device)
predict_true_face_of_g = D(G(latent_z)).squeeze()
loss_G = loss_function(predict_true_face_of_g, true_face_of_g)
loss_G.backward()
optimizer_g.step()
logger.add_scalar('loss/G', loss_G.mean().item(), step)
if not step % parameters.verbose_step: # 每250步保存一张8×8图片
print("第步".format(step))
with torch.no_grad():
fake_image = G(fixed_latent_z)
fake_image = invtrans(fake_image)
torchvision.utils.save_image(fake_image, "./img_save/face_step.png".format(step), nrow=8)
step += 1
logger.flush()
logger.close()
if __name__ == '__main__':
if parameters.device == 'cuda':
print("GPU上训练")
else:
print("CPU上训练")
train()
# 训练完成后关机
os.system("shutdown")
以上是关于第三节:DCGAN人脸图像生成的主要内容,如果未能解决你的问题,请参考以下文章