Keras深度学习实战(23)——DCGAN详解与实现
Posted 盼小辉丶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Keras深度学习实战(23)——DCGAN详解与实现相关的知识,希望对你有一定的参考价值。
Keras深度学习实战(23)——DCGAN详解与实现
0. 前言
在生成对抗网络 (Generative Adversarial Networks, GAN) 一节中,我们使用原始 GAN 生成了数字图片。从之前的相关学习中,我们已经知道,使用卷积神经网络 (Convolutional Neural Network, CNN) 体系结构能够更好地学习图像中的特征,因为 CNN 中的卷积核能够学习图像中的特定细节。深度卷积生成对抗网络 (Deep Convolutional GAN, DCGAN) 正是基于上述思想来生成图像,其将卷积神经网络引入 GAN 中,以代替原始 GAN 中的全连接网络。
1. 使用 DCGAN 生成手写数字图像
DCGAN 的原理与 GAN 基本相同,主要区别在于 DCGAN 的生成器和鉴别器使用卷积神经网络体系结构:
def generator():
model = Sequential()
model.add(Dense(1024, input_dim=100))
model.add(LeakyReLU(0.2))
model.add(Dense(128*7*7))
model.add(BatchNormalization())
model.add(LeakyReLU(0.2))
model.add(Reshape((7,7,128)))
model.add(Conv2DTranspose(128, (5, 5), strides=(1, 1), padding='same', use_bias=False))
model.add(BatchNormalization())
model.add(LeakyReLU(0.2))
model.add(Conv2DTranspose(64, (5, 5), strides=(2, 2), padding='same', use_bias=False))
model.add(BatchNormalization())
model.add(LeakyReLU(0.2))
model.add(Conv2DTranspose(1, (5, 5), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
return model
def discriminator():
model = Sequential()
model.add(Conv2D(64, (3, 3), padding='same', input_shape=(28,28,1)))
model.add(LeakyReLU(0.2))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(128, (3,3)))
model.add(LeakyReLU(0.2))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(512, (3,3)))
model.add(LeakyReLU(0.2))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(512))
model.add(LeakyReLU(0.2))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
在 DCGAN 中,我们对输入数据执行多个卷积和池化操作,而其它步骤与原始 GAN 中的步骤完全相同,区别仅在于使用卷积和池化架构定义的 GAN 模型,模型训练后生成的图像如下所示:

生成器和鉴别器训练损失值随 epoch 的增加而变化,如下所示:
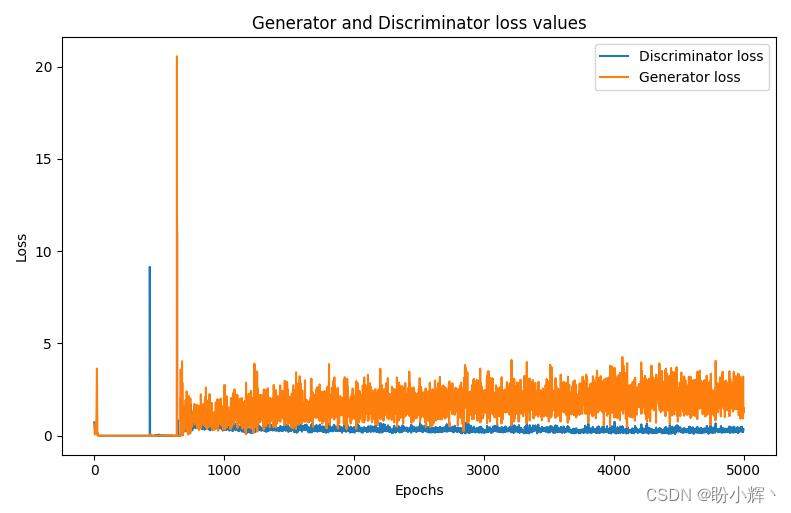
与原始 GAN 相比,可以看到,尽管其他条件保持不变,仅模型体系结构发生了变化,但是通过 DCGAN 生成的图像比原始 GAN 的图像更加真实。
2. 使用 DCGAN 生成面部图像
我们已经学习了如何使用 DCGAN 生成新手写数字图像。本节中,我们将继续学习如何从现有的面部数据集中生成一组新的面部图像。所用的面部数据集与在性别分类中所用数据集相同。
2.1 模型分析
在介绍了 DCGAN 的核心思想后,我们将在本节中使用 DCGAN 架构生成面部图像,所用策略如下:
- 使用包含面部图像的数据集
- 生成器开始时只能生成随机图像
- 通过向鉴别器输入真实面部图像和生成器生成图像来训练鉴别器,鉴别器应学会区分真实面部图像和生成的虚假面部图像
- 鉴别器模型训练完成后,将冻结其权重,并训练生成器网络,以使鉴别器以较高的概率将生成的虚假图片识别为真实图像
- 多次迭代以上前两个步骤,直到生成器能够生成足够逼真的图像
2.2 从零开始实现 DCGAN 生成面部图像
(1) 下载数据集,与在性别分类中所用数据集相同,图像样本如下:

(2) 定义模型架构与所用超参数:
shape = (56, 56, 3)
epochs = 10000
batch_size = 64
save_interval = 100
def generator():
model = Sequential()
model.add(Dense(1024, input_dim=100))
model.add(LeakyReLU(0.2))
model.add(Dense(128*7*7))
model.add(BatchNormalization())
model.add(LeakyReLU(0.2))
model.add(Reshape((7,7,128)))
model.add(Conv2DTranspose(128, (3, 3), strides=(1, 1), padding='same', use_bias=False))
model.add(BatchNormalization())
model.add(LeakyReLU(0.2))
model.add(Conv2DTranspose(64, (3, 3), strides=(2, 2), padding='same', use_bias=False))
model.add(BatchNormalization())
model.add(LeakyReLU(0.2))
model.add(Conv2DTranspose(32, (3, 3), strides=(2, 2), padding='same', use_bias=False))
model.add(BatchNormalization())
model.add(LeakyReLU(0.2))
model.add(Conv2DTranspose(3, (3, 3), strides=(2, 2), padding='same', use_bias=False, activation='tanh'))
return model
def discriminator():
model = Sequential()
model.add(Conv2D(64, (3, 3), padding='same', input_shape=(56,56,3)))
model.add(LeakyReLU(0.2))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(128, (3,3)))
model.add(LeakyReLU(0.2))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(512, (3,3)))
model.add(LeakyReLU(0.2))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(1024, (3,3)))
model.add(LeakyReLU(0.2))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(1024))
model.add(LeakyReLU(0.2))
model.add(Dense(1))
model.add(Activation('sigmoid'))
return model
def gan(discriminator, generator):
discriminator.trainable = False
model = Sequential()
model.add(generator)
model.add(discriminator)
return model
(3) 定义预处理函数、反处理函数以及绘制图像等实用函数:
import time
noise = np.random.normal(0, 1, (16, 100))
def plot_images(noise=noise, samples=16, step=0):
images = generator.predict(noise)
images = deprocess(images)
images = np.clip(images, 0, 255)
plt.figure(figsize=(10, 10))
for i in range(images.shape[0]):
plt.subplot(4, 4, i + 1)
image = images[i, :, :, :]
image = np.reshape(image, [56, 56,3])
plt.imshow(image)
plt.axis('off')
plt.tight_layout()
plt.show()
在此模型中,我们在将图像调整为较小的尺寸,这是由于 DCGAN 并不适合生成较大尺寸的图片,同时也可以减少模型的参数量:
def preprocess(x):
return (x / 255) * 2 - 1
def deprocess(x):
return np.uint8((x + 1) / 2 * 255)
(4) 导入数据集,创建输入数据将其转换为数组,并对其进行预处理:
import os
from glob import glob
root_dir = 'man_woman/b_resized/'
all_img = glob(os.path.join(root_dir, '*.jpg'))
x_train = []
for i in range(len(all_img)):
img = cv2.imread(all_img[i])#, cv2.COLOR_BGR2RGB)
img = cv2.resize(img, (56, 56))
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
img = preprocess(img)
x_train.append(img)
x_train = np.array(x_train)
(5) 编译生成器,鉴别器和 GCGAN 模型:
generator = generator()
generator.summary()
generator.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5, decay=8e-8))
discriminator = discriminator()
discriminator.summary()
discriminator.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5, decay=8e-8), metrics=['acc'])
gan = gan(discriminator, generator)
gan.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.0002, beta_1=0.5, decay=8e-8))
生成器模型简要的架构信息如下所示:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense (Dense) (None, 1024) 103424
_________________________________________________________________
leaky_re_lu (LeakyReLU) (None, 1024) 0
_________________________________________________________________
dense_1 (Dense) (None, 6272) 6428800
_________________________________________________________________
batch_normalization (BatchNo (None, 6272) 25088
_________________________________________________________________
leaky_re_lu_1 (LeakyReLU) (None, 6272) 0
_________________________________________________________________
reshape (Reshape) (None, 7, 7, 128) 0
_________________________________________________________________
conv2d_transpose (Conv2DTran (None, 7, 7, 128) 147456
_________________________________________________________________
batch_normalization_1 (Batch (None, 7, 7, 128) 512
_________________________________________________________________
leaky_re_lu_2 (LeakyReLU) (None, 7, 7, 128) 0
_________________________________________________________________
conv2d_transpose_1 (Conv2DTr (None, 14, 14, 64) 73728
_________________________________________________________________
batch_normalization_2 (Batch (None, 14, 14, 64) 256
_________________________________________________________________
leaky_re_lu_3 (LeakyReLU) (None, 14, 14, 64) 0
_________________________________________________________________
conv2d_transpose_2 (Conv2DTr (None, 28, 28, 32) 18432
_________________________________________________________________
batch_normalization_3 (Batch (None, 28, 28, 32) 128
_________________________________________________________________
leaky_re_lu_4 (LeakyReLU) (None, 28, 28, 32) 0
_________________________________________________________________
conv2d_transpose_3 (Conv2DTr (None, 56, 56, 3) 864
=================================================================
Total params: 6,798,688
Trainable params: 6,785,696
Non-trainable params: 12,992
_________________________________________________________________
鉴别器模型简要的架构信息如下所示:
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 56, 56, 64) 1792
_________________________________________________________________
batch_normalization_4 (Batch (None, 56, 56, 64) 256
_________________________________________________________________
leaky_re_lu_5 (LeakyReLU) (None, 56, 56, 64) 0
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 28, 28, 64) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 26, 26, 128) 73856
_________________________________________________________________
batch_normalization_5 (Batch (None, 26, 26, 128) 512
_________________________________________________________________
leaky_re_lu_6 (LeakyReLU) (None, 26, 26, 128) 0
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 13, 13, 128) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 11, 11, 512) 590336 以上是关于Keras深度学习实战(23)——DCGAN详解与实现的主要内容,如果未能解决你的问题,请参考以下文章