深度学习方法(二十一):常用权重初始化方法Xavier,He initialization的推导
Posted 大饼博士X
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习方法(二十一):常用权重初始化方法Xavier,He initialization的推导相关的知识,希望对你有一定的参考价值。
文章目录
交叉熵目标函数更陡峭
在论文[1]中给了一个图示,一定程度上说明了为什么Cross Entropy用的很多,效果很好。图中上面的曲面表示的是交叉熵代价函数,下面的曲面表示的是二次代价函数,W1和W2分别表示层与层之间的连接权值。
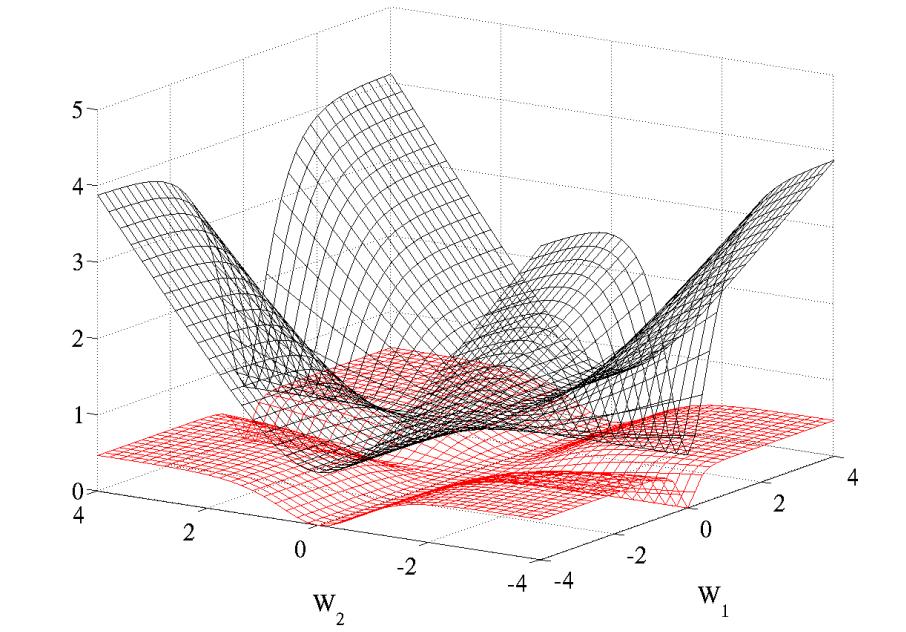 )
)
在1986年 Rumelhart 已经发现:logistic function 或者叫 conditional log-likelihood function: -log P(y|x) 的效果比 quadratic cost function(平方代价函数)的效果好很多的,原因在于 quadratic cost function(平方代价函数)在训练过程中会出现更多的 plateaus(平坦区域)。文章给出了一个两个参数下的图,图中采用的是具有单隐层的神经网络,激活函数使用的是 tanh 函数,对于输入信号进行随机初始化,可以看到二次代价函数具有更多的 plateaus (平坦区域)。
Xavier initialization [1][4]
早期的参数初始化方法普遍是将数据和参数初始化为标准高斯分布(均值0方差1),但随着神经网络深度的增加,这方法并不能解决梯度消失问题。

那么我们应该怎么通过初始化来缓解这个问题呢?
论文中首先给出了一个启发式的方法,想法是初始化值和神经元的输入个数有关:
We initialized the biases to be 0 and the weights Wij at each layer with the following commonly used heuristic, where U[−a, a] is the uniform distribution in the interval (−a, a) and n is the size of the previous layer (the number of columns of W)
W ∼ U [ − 1 n , 1 n ] V a r ( W ) = 1 3 n W \\sim U[-\\frac1\\sqrt n,\\frac1\\sqrt n]\\\\ Var(W) = \\frac13n W∼U[−n1,n1]Var(W)=3n1
上面式子中,
W
∼
W \\sim
W∼表示其中的每一个元素
W
i
j
W_ij
Wij都是符合一个均匀分布的。其中n表示本层的输入size,也就是上一层的输出size。我们知道随机变量在[a,b] 间的均匀分布的方差为
V
a
r
=
(
b
−
a
)
2
12
Var= \\frac(b-a)^212
Var=12(b−a)2
所以得到权重参数的方差是1/3n。先记一下,后面分析会讲到。
为了便于研究,作者假设使用线性激活函数 f ( x ) f(x) f(x),且在零点导数 f ′ ( 0 ) = 1 f'(0)=1 f′(0)=1。实际上,作者研究的是参数的线性区域,可以认为是对任务的一个简化。
对于一层网络:
f
(
x
)
=
∑
i
n
w
i
x
i
+
b
f(\\textbf x) = \\sum_i^n w_ix_i + b
f(x)=i∑nwixi+b
输出的方差:
V
a
r
(
f
(
x
)
)
=
∑
i
n
V
a
r
(
w
i
x
i
)
Var(f(\\textbf x)) = \\sum_i^n Var(w_i x_i)
Var(f(x))=i∑nVar(wixi)
其中每一项:
V
a
r
(
w
i
x
i
)
=
E
[
w
i
]
2
V
a
r
(
x
i
)
+
E
[
x
i
]
2
V
a
r
(
w
i
)
+
V
a
r
(
w
i
)
V
a
r
(
x
i
)
Var(w_i x_i) = E[w_i]^2Var(x_i) + E[x_i]^2Var(w_i)+Var(w_i)Var(x_i)
Var(wixi)=E[wi]2Var(xi)+E[xi]2Var(wi)+Var(wi)Var(xi)
当我们假设输入和权重都是0均值时(目前有了BN之后,每一层的输入也较容易满足),即 E [ x i ] = E [ w i ] = 0 E[x_i] = E[w_i] = 0 E[xi]=E[wi]=0,上式可以简化为:
V a r ( w i x i ) = V a r ( w i ) V a r ( x i ) Var(w_i x_i) =Var(w_i)Var(x_i) Var(wixi)=Var(wi)Var(xi)
由于w和x独立同分布,那么输出的方差就是
V a r ( f ( x ) ) = n V a r ( w i ) V a r ( x i ) Var(f(\\textbf x)) = n Var(w_i) Var(x_i) Var(f(x))=nVar(wi)Var(xi)
我们发现,输出的方差是和输入的方差是一个线性倍数关系。假设 z i z^i zi是第 i i i层的输入向量, s i s^i si是第 i i i层激活函数的输入, f f f表示激活函数
s i = z i W i + b i z i + 1 = f ( s i ) s i + 1 = z i + 1 W i + 1 + b i + 1 \\textbf s^i = \\textbf z^i W^i + \\textbf b^i \\\\ \\textbf z^i+1 = f(\\textbf s^i)\\\\ \\textbf s^i+1 = \\textbf z^i+1 W^i+1 + \\textbf b^i+1 si=ziWi+bizi+1=f(si)si+1=zi+1Wi+1+bi+1
可以得到:
对于一个多层的网络,某一层的方差可以用累积的形式表达:
V
a
r
[
z
i
]
=
V
a
r
[
x
]
∏
i
′
=
0
i
−
1
n
i
′
V
a
r
[
W
i
′
]
Var[z^i] = Var[x] \\prod_i'=0^i-1n_i' Var[W^i']
Var[zi]=Var[x]i′=0∏i−1ni′Var[Wi′]
求反向我们可以得到(假设
f
′
(
s
k
i
)
≈
以上是关于深度学习方法(二十一):常用权重初始化方法Xavier,He initialization的推导的主要内容,如果未能解决你的问题,请参考以下文章