kerberos环境下parcel方式部署flink1.15.3 基于CDH6.3.2 Flink on Yarn
Posted Mumunu-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kerberos环境下parcel方式部署flink1.15.3 基于CDH6.3.2 Flink on Yarn相关的知识,希望对你有一定的参考价值。
1.1 Flink on Yarn的优势
相对于 Standalone 模式,在Yarn 模式下有以下几点好处:
1.资源按需使用,提高集群的资源利用率;
2.任务有优先级,根据优先级运行作业;
3.基于 Yarn 调度系统,能够自动化地处理各个角色的 Failover:
JobManager 进程和 TaskManager 进程都由 Yarn NodeManager 监控;
如果 JobManager 进程异常退出,则 Yarn ResourceManager 会重新调度 JobManager 到其他机器;
如果 TaskManager 进程异常退出,JobManager 会收到消息并重新向 Yarn ResourceManager 申请资源,重新启动 TaskManager。
第2章 Flink on Yarn模式运行的方式
2.1 Application
Application模式:简答的说就是直接run job,每次提交的任务Yarn都会分配一个JobManager,执行完之后整个资源会释放,包括JobManager和TaskManager。
Application模式适合比较大的任务、执行时间比较长的任务。
2.2 Session
Session模式:在Session模式中, Dispatcher 和 ResourceManager 是可以复用的;当执行完Job之后JobManager并不会释放,Session 模式也称为多线程模式,其特点是资源会一直存在不会释放。使用时先启动yarn-session,然后再提交job,每次提交job,也都会分配一个JobManager。
Session模式适合比较小的任务、执行时间比较短的任务。该模式不用频繁的申请资源和释放资源。
所以一般生产情况下我们都会选取 on Yarn 部署Application方式运行
废话不多说开始部署
2、准备环境
jdk1.8
maven3.6.3
parcel制作工具
3、制作parcel
下载制作工具
git clone https://github.com/pkeropen/flink-parcel.git
网络有问题也可以直接下载代码包传过去再解压
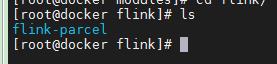
修改配置文件
cd ./flink-parcel
vim flink-parcel.properties
进行相应修改,内容如下:
#FLINK 下载地址
FLINK_URL=https://archive.apache.org/dist/flink/flink-1.15.3/flink-1.15.3-bin-scala_2.12.tgz
#flink版本号
FLINK_VERSION=1.15.3
#扩展版本号
EXTENS_VERSION=BIN-SCALA_2.12
#操作系统版本,以centos为例
OS_VERSION=7
#CDH 小版本
CDH_MIN_FULL=6.3.2
CDH_MAX_FULL=6.3.2
#CDH大版本
CDH_MIN=6
CDH_MAX=6flink-1.15.3-bin-scala_2.12.tgz这个文件也可以先下载好,因为通过脚本下载的话网速比较慢,建议通过迅雷下载,下载好后直接放到flink-parcel目录下
# 赋予执行权限
chmod +x ./build.sh
然后进行build
./build.sh parcel
执行过程中需要去git下载文件,如果你的网络有问题也可以直接下载到flink-parcel下
https://github.com/cloudera/cm_ext 下载下来应该是叫cm_ext_master,记得改名为cm_ext
下载并打包完成后会在当前目录生成FLINK-1.15.3-BIN-SCALA_2.12_build文件
构建flink-yarn csd包
./build.sh csd_on_yarn
执行完成后会生成FLINK_ON_YARN-1.15.3.jar,csd文件是组件的导航文件
将FLINK-1.15.3-BIN-SCALA_2.12_build打包
tar -cvf ./FLINK-1.15.3-BIN-SCALA_2.12.tar ./FLINK-1.15.3-BIN-SCALA_2.12_build/
将FLINK-1.15.3-BIN-SCALA_2.12.tar FLINK_ON_YARN-1.15.3.jar下载,这两个包就是目标包集成工作我们需要做的就是以下两点:
在部署了cloudera server的节点
(1)将FLINK-1.13.2-BIN-SCALA_2.11_build里的文件放到/opt/cloudera/parcel-repo

就是这两个文件,那个manifest.json 好像不放也行 。稍等一会系统会自动生成 torrent文件,生成好就可以在web上刷到了

(2) cp FLINK_ON_YARN-1.15.3.jar /opt/cloudera/csd/
在CDH里面配置flink
提示:注意:这里一定要用自己编译的包,不要用从链接下载的包!!!

按照提示点击分配、激活就可以了
点击添加服务
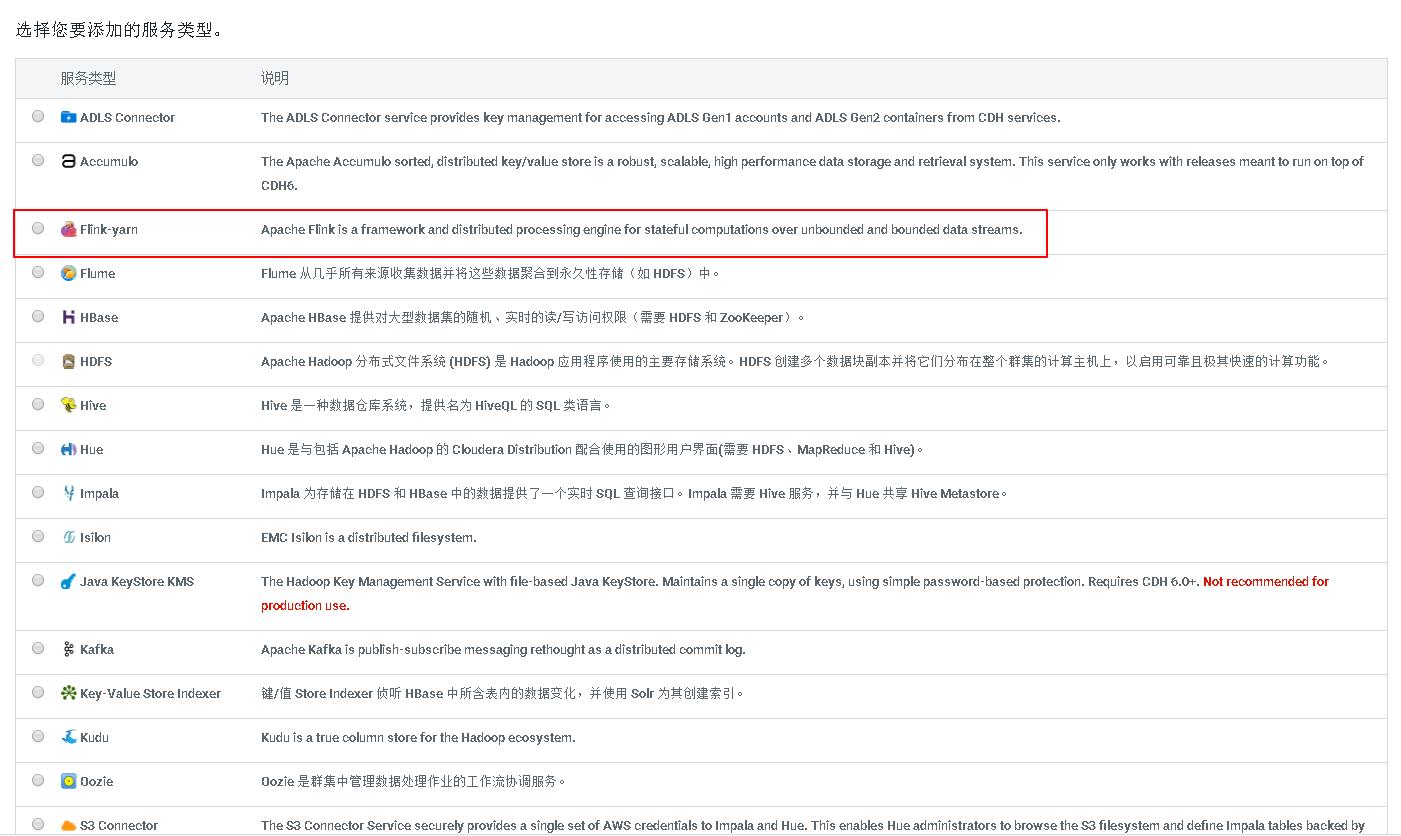
如果没有看到flink的组件,可以通过重启一下cdh,我之前就试过,flink分配、激活成功后,没有看见flink组件的图标,可以通过重启CDH服务,
在CDH的主节点上执行以下命令
systemctl stop cloudera-scm-server //停止
systemctl start cloudera-scm-server //启动为flink选择机器
注意端口号是否被占用
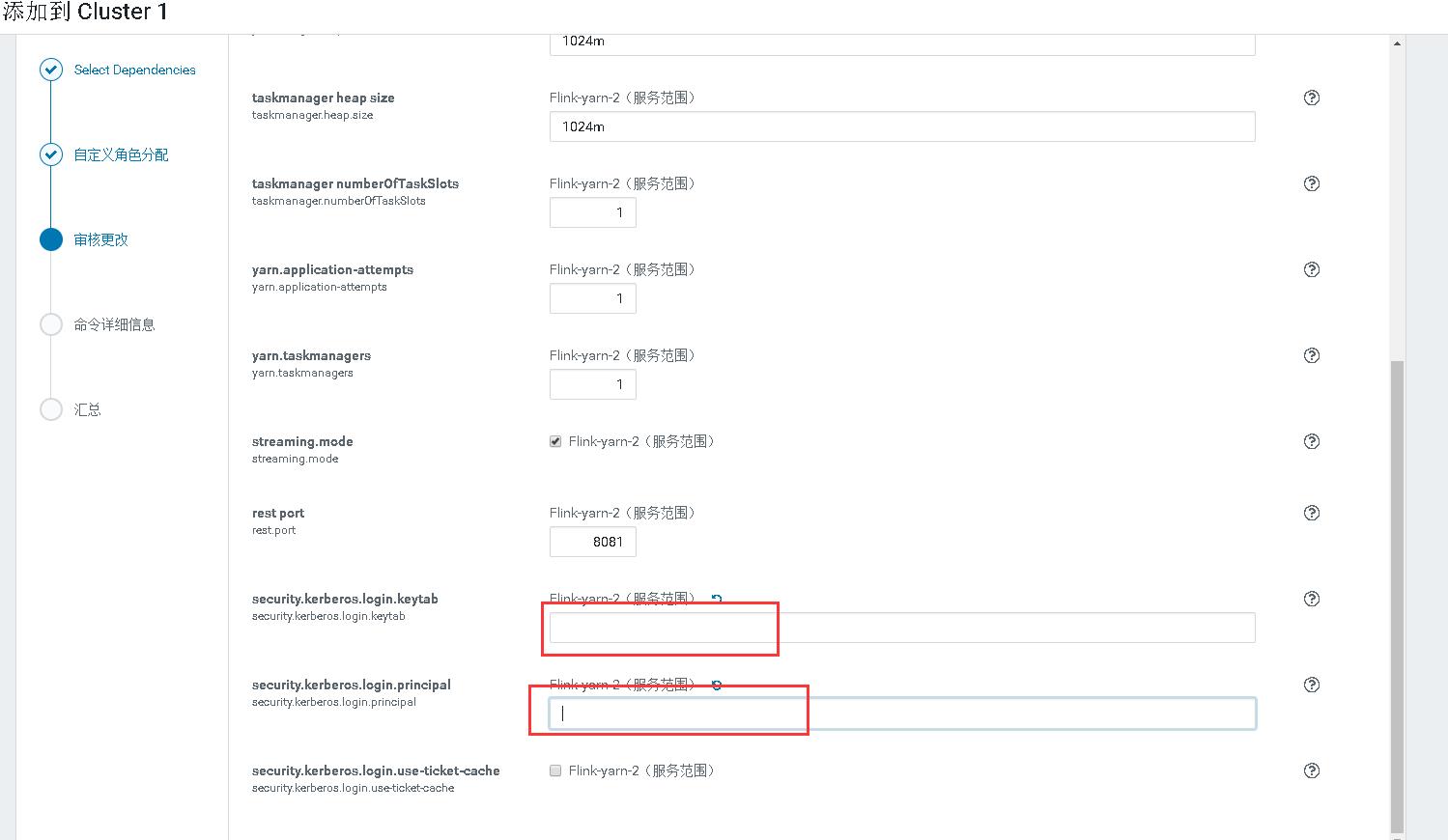
如图两个框上面填写你使用的keytab文件路径。下面则是principal名字,那个勾不要打
应该会遇到一些报错
错误1
/opt/cloudera/parcels/FLINK/lib/flink/bin/flink-yarn.sh: line 17: rotateLogFilesWithPrefix: command not found
解决
vim /opt/cloudera/parcels/FLINK/lib/flink/bin/config.sh:391 加入
rotateLogFilesWithPrefix()
dir=$1
prefix=$2
while read -r log ; do
rotateLogFile "$log"
# find distinct set of log file names, ignoring the rotation number (trailing dot and digit)
done < <(find "$dir" ! -type d -path "$prefix*" | sed s/\\.[0-9][0-9]*$// | sort | uniq)
# 旋转日志文件
rotateLogFile()
log=$1;
num=$MAX_LOG_FILE_NUMBER
if [ -f "$log" -a "$num" -gt 0 ]; then
while [ $num -gt 1 ]; do
prev=`expr $num - 1`
[ -f "$log.$prev" ] && mv "$log.$prev" "$log.$num"
num=$prev
done
mv "$log" "$log.$num";
fi
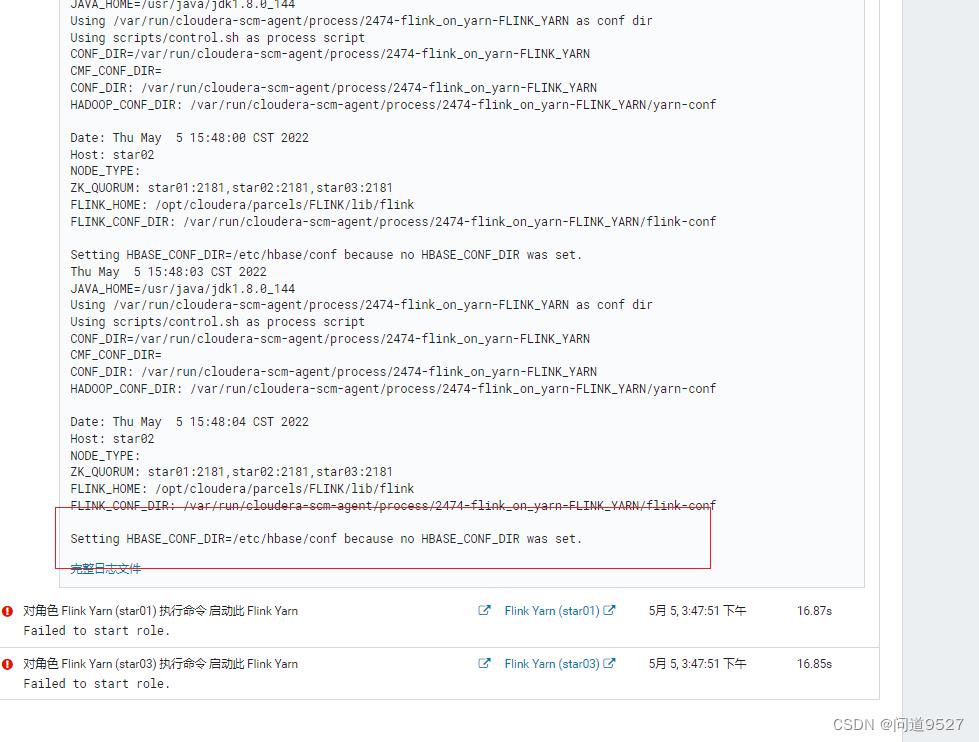
错误2
没有具体的错误输出,但是通过日志,可以看到提示HBASE环境变量未设置
no HBASE_CONF_DIR was set
解决:
再开一个页面。主页里找到flink
Flink-yarn -> 配置 -> 高级 -> Flink-yarn 服务环境高级配置代码段(安全阀)Flink-yarn(服务范围)加入以下内容即可:
HADOOP_USER_NAME=flink
HADOOP_CONF_DIR=/etc/hadoop/conf
HADOOP_HOME=/opt/cloudera/parcels/CDH
HADOOP_CLASSPATH=/opt/cloudera/parcels/CDH/jars/*
HBASE_CONF_DIR=/etc/hbase/conf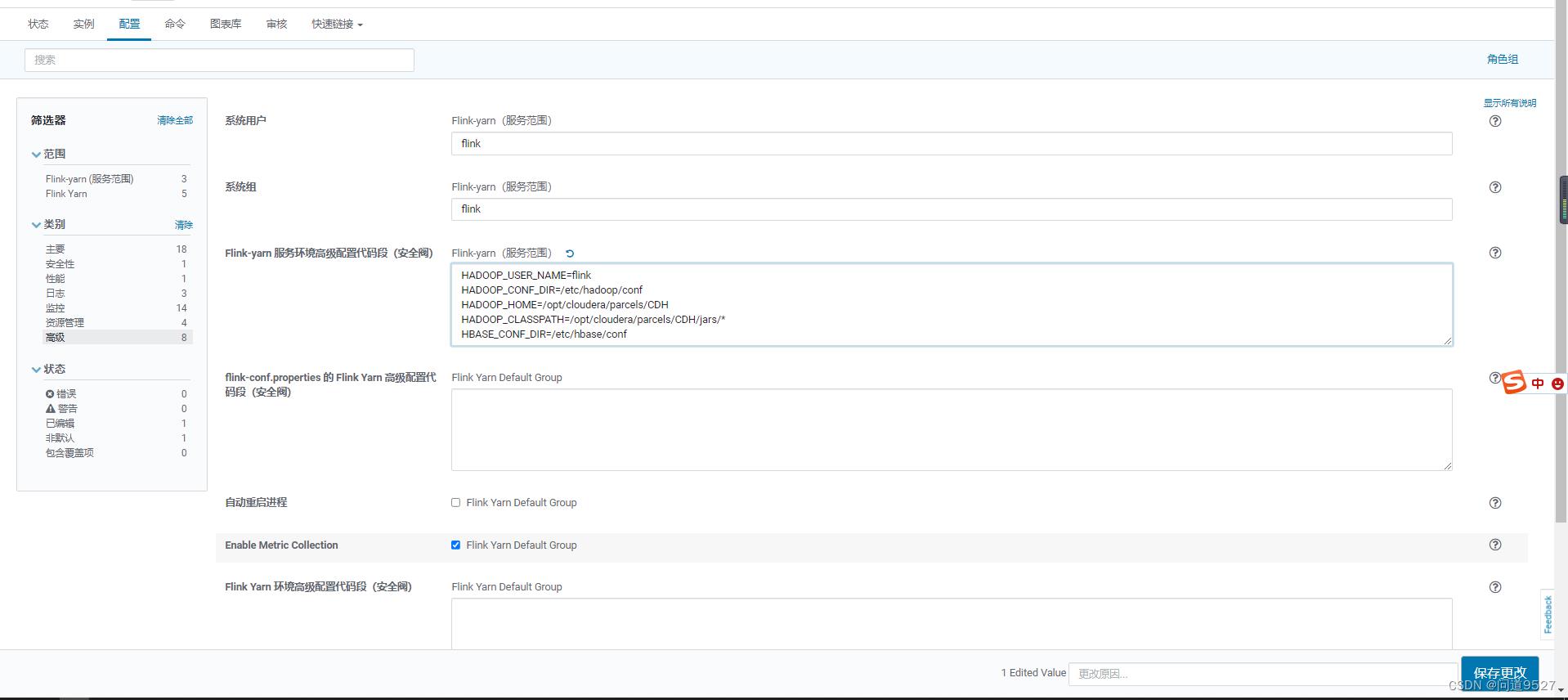
需要在yarn-session.sh 文件中添加 或者在环境变量中添加
加在yarn-session.sh 文件第一行就行
export HADOOP_CLASSPATH=`hadoop classpath`
错误4、Error found before invoking supervisord: 'getpwnam(): name not found: flink'
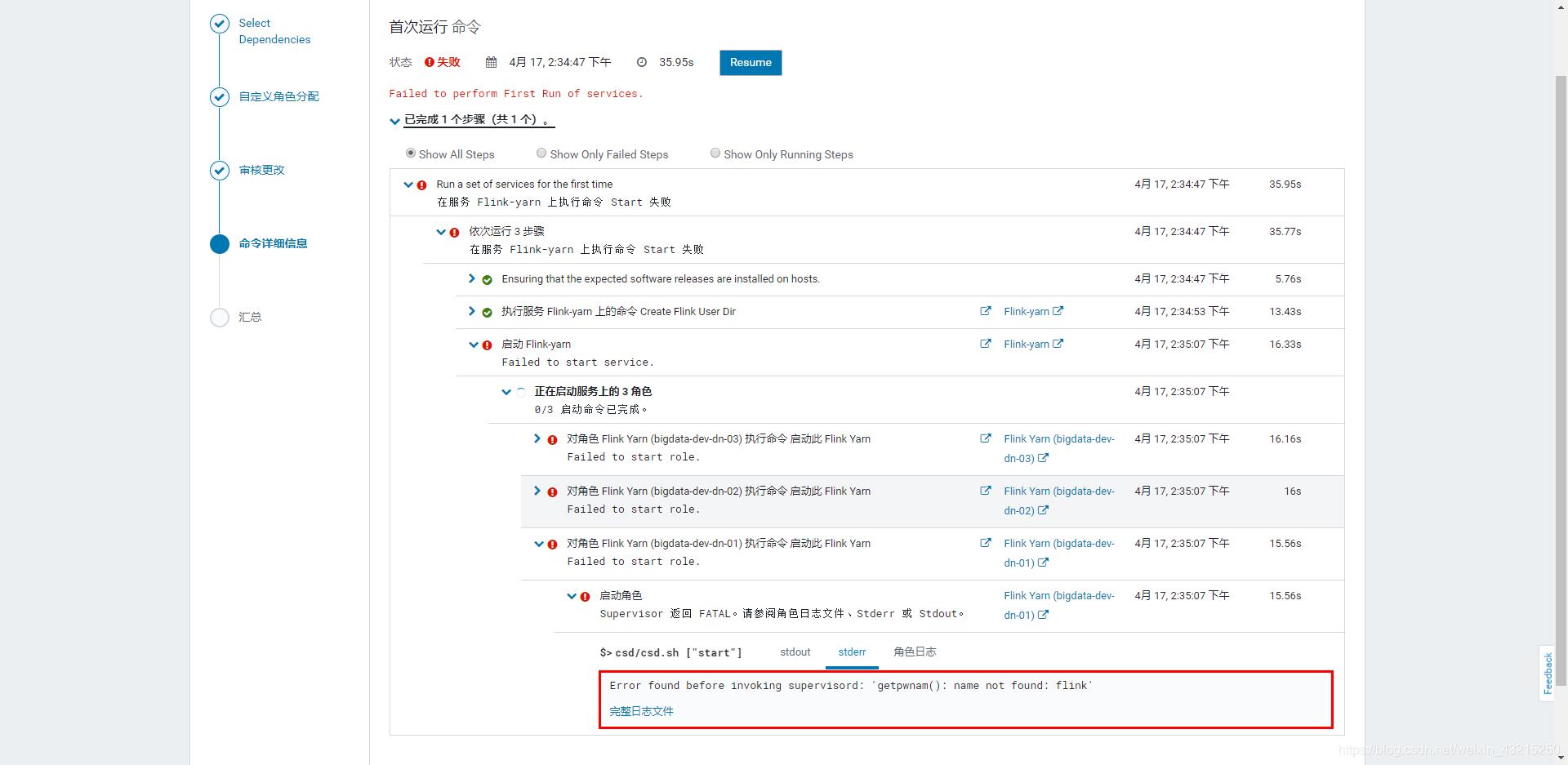
解决办法:
在 Flink-yarn 服务所在的节点添加 flink 用户和角色:
[root@node01 ~]# groupadd flink
[root@node01 ~]# useradd flink -g flink部署完成后测试一下
运行一个WordCount测试
./flink run -t yarn-per-job /opt/cloudera/parcels/FLINK/lib/flink/examples/batch/WordCount.jar可能会有报错 :Retrying connect to server: 0.0.0.0/0.0.0.0:8032. Already tried 3 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=10, sleepTime=1000 MILLISECONDS)
在 CDH 的 yarn 服务中添加 Gateway 服务即可
可能有一些权限问题,具体问题具体解决即可
没报错 出来一堆
就是安装成功了
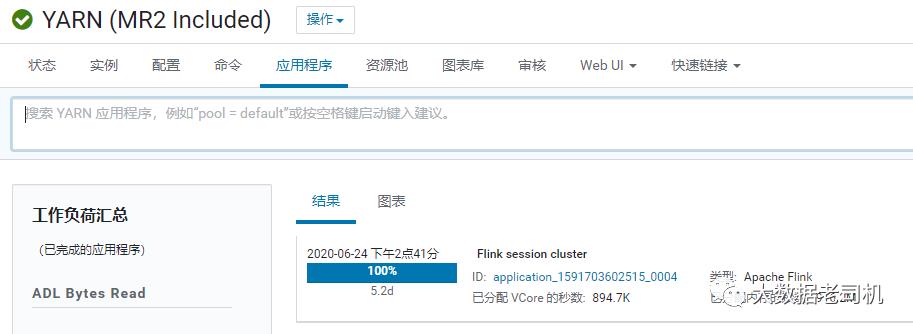
可以在yarn的界面和cdh的界面查到flink的任务


编辑
如果测试flink session模式,或者运行sql-client
必须首先启动一个session任务
yarn-session.sh -s 2 -jm 1024 -tm 2048 -nm test1 -d
-tm 表示每个TaskManager的内存大小
-s 表示每个TaskManager的slots数量
-d 表示以后台程序方式运行
启动了一个名叫test1的flink 常驻集群
一些参数如下
-n,--container <arg> 表示分配容器的数量(也就是 TaskManager 的数量)。
-D <arg> 动态属性。
-d,--detached 在后台独立运行。
-jm,--jobManagerMemory <arg>:设置 JobManager 的内存,单位是 MB。
-nm,--name:在 YARN 上为一个自定义的应用设置一个名字。
-q,--query:显示 YARN 中可用的资源(内存、cpu 核数)。
-qu,--queue <arg>:指定 YARN 队列。
-s,--slots <arg>:每个 TaskManager 使用的 Slot 数量。
-tm,--taskManagerMemory <arg>:每个 TaskManager 的内存,单位是 MB。
-z,--zookeeperNamespace <arg>:针对 HA 模式在 ZooKeeper 上创建 NameSpace。
-id,--applicationId <yarnAppId>:指定 YARN 集群上的任务 ID,附着到一个后台独立运行的 yarn session 中然后提交job
flink run ./example/batch/WordCount.jarsql-client则
sql-client.sh
建表
跑select等语句即可web ui会生成在某个固定节点上 根据你的配置登陆查看即可,如果忘记了也可以根据提交任务之后的输出查看
或者在yarn里面查看应用程序,点击进去
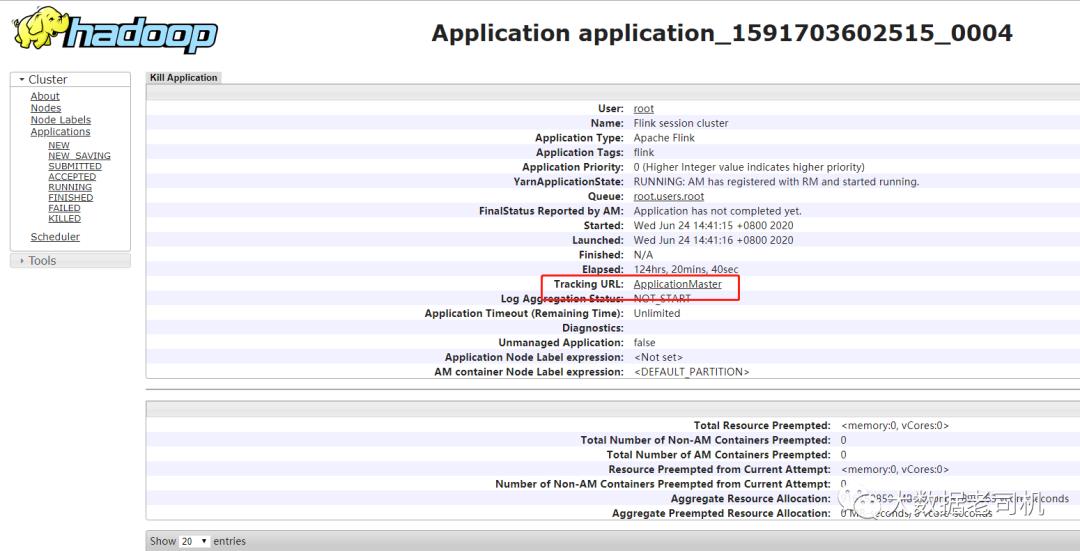
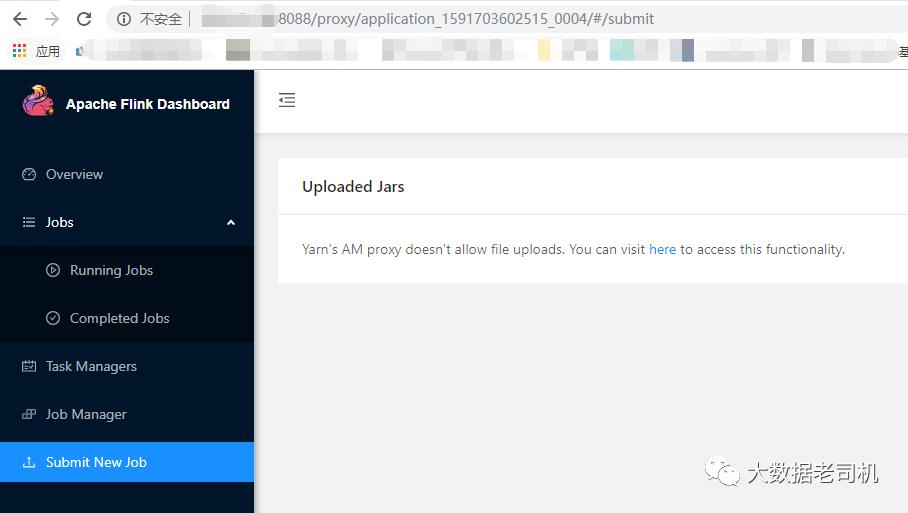
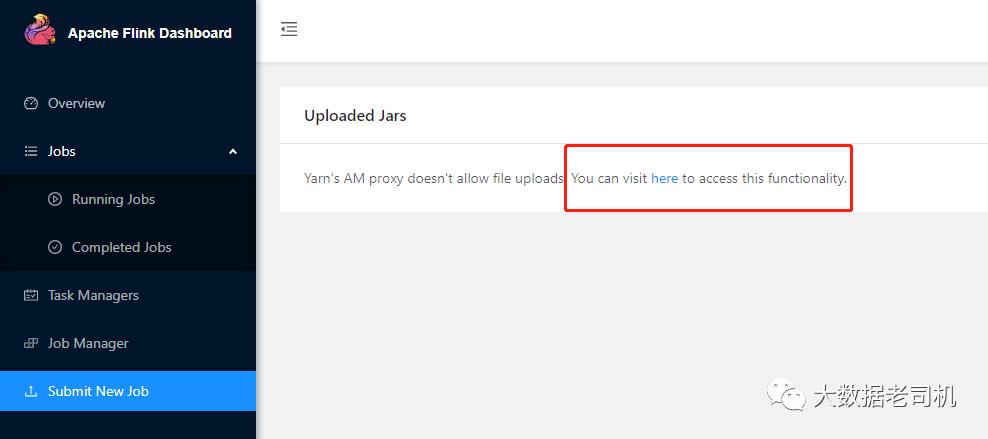
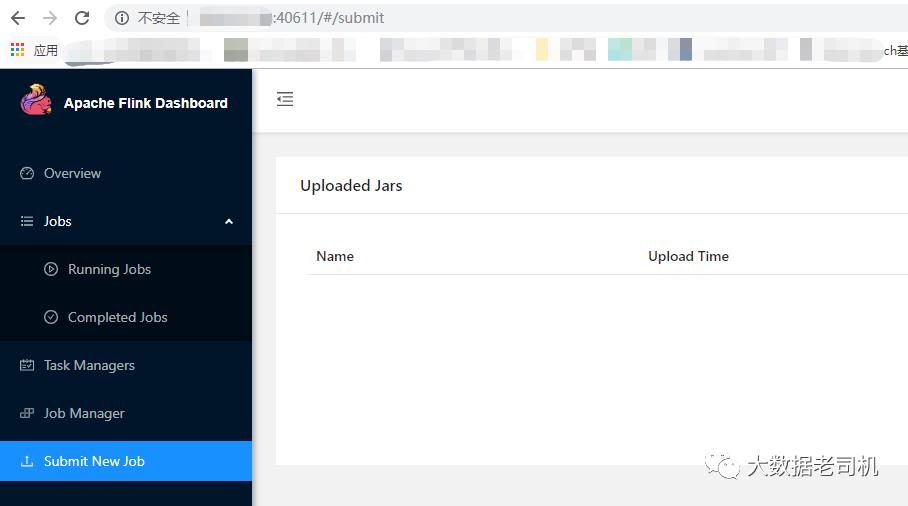
以上是关于kerberos环境下parcel方式部署flink1.15.3 基于CDH6.3.2 Flink on Yarn的主要内容,如果未能解决你的问题,请参考以下文章
0110-如何给Kerberos环境下的CDH集群添加Gateway节点