非Kerberos环境下Kafka数据到Flume进Hive表
Posted Hadoop实操
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了非Kerberos环境下Kafka数据到Flume进Hive表相关的知识,希望对你有一定的参考价值。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
Fayson的github:https://github.com/fayson/cdhproject
1.文档编写目的
前面Fayson讲过《》,本篇文章主要讲述如何在非Kerberos环境下将Kafka数据接入Flume并写入Hive表。本文的数据流如下:
内容概述
1.环境准备及配置Flume Agent
2.配置Hive支持事务
3.流程测试
测试环境
1.CM和CDH版本为5.13.1
2.采用root用户操作
前置条件
1.集群已安装Kafka
2.集群已安装Flume
2.Java生产消息
1.消息生产者代码
package com.cloudera;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.io.File;
import java.io.FileInputStream;
import java.util.Properties;
/**
* package: com.cloudera
* describe: 非Kerberos环境下向指定Topic生产消息
* creat_user: Fayson
* email: htechinfo@163.com
* creat_date: 2017/12/15
* creat_time: 下午11:38
* 公众号:Hadoop实操
*/
public class NoneKBProducerTest {
public static String confPath = System.getProperty("user.dir") + File.separator + "conf";
public static void main(String[] args) {
try {
Properties appProperties = new Properties();
appProperties.load(new FileInputStream(new File(confPath + File.separator + "app.properties")));
String brokerlist = String.valueOf(appProperties.get("bootstrap.servers"));
String topic_name = String.valueOf(appProperties.get("topic.name"));
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, brokerlist);
props.put(ProducerConfig.ACKS_CONFIG, "all");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<String, String>(props);
for (int i = 0; i < 10; i++) {
String message = i + "\t" + "fayson" + i + "\t" + 22+i;
ProducerRecord record = new ProducerRecord<String, String>(topic_name, message);
producer.send(record);
System.out.println(message);
}
producer.flush();
producer.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
2.将工程编译打包kafka-demo-1.0-SNAPSHOT.jar
mvn clean package
3.使用mvn命令将工程依赖库导出
mvn dependency:copy-dependencies -DoutputDirectory=/Users/fayson/Desktop/lib
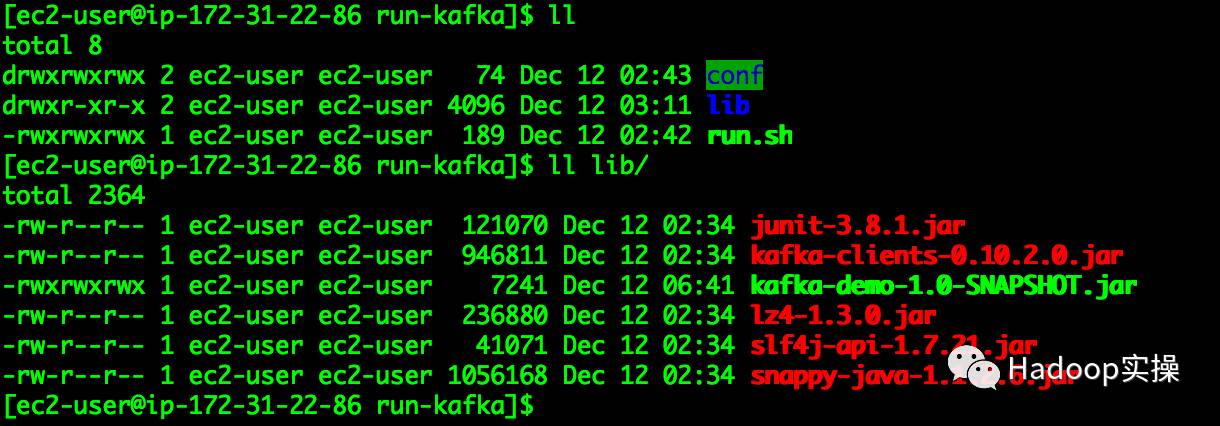
将导出的jar包放在run-kafka/lib目录下。
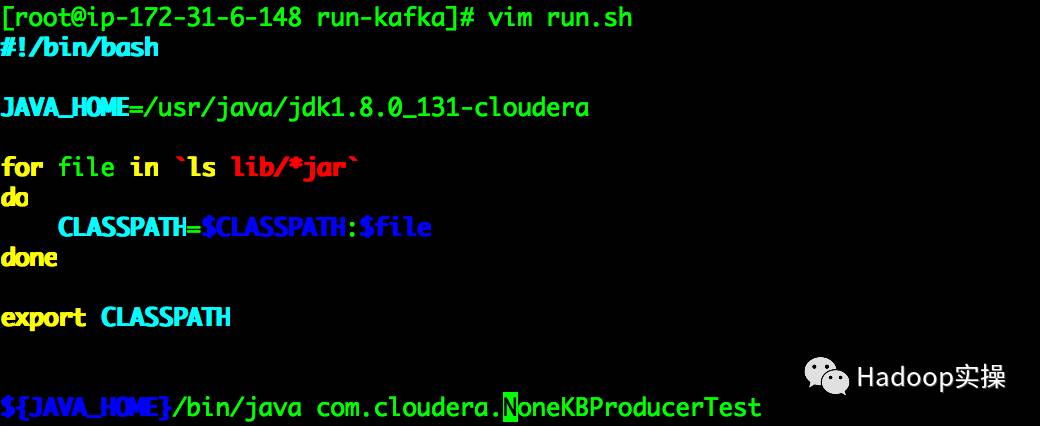
4.编写run.sh脚本,运行测试jar包
#!/bin/bash
JAVA_HOME=/usr/java/jdk1.8.0_131-cloudera
for file in `ls lib/*jar`
do
CLASSPATH=$CLASSPATH:$file
done
export CLASSPATH
${JAVA_HOME}/bin/java com.cloudera.NoneKBProducerTest
5.conf目录文件

app.properties:Kafka的Broker和Topic配置信息
3.配置Hive支持事务
Hive从0.13开始加入了事务支持,在行级别提供完整的ACID特性,Hive在0.14时加入了对INSERT...VALUES,UPDATE,and DELETE的支持。对于在Hive中使用ACID和Transactions,主要有以下限制:
不支持BEGIN,COMMIT和ROLLBACK
只支持ORC文件格式
表必须分桶
不允许从一个非ACID连接写入/读取ACID表
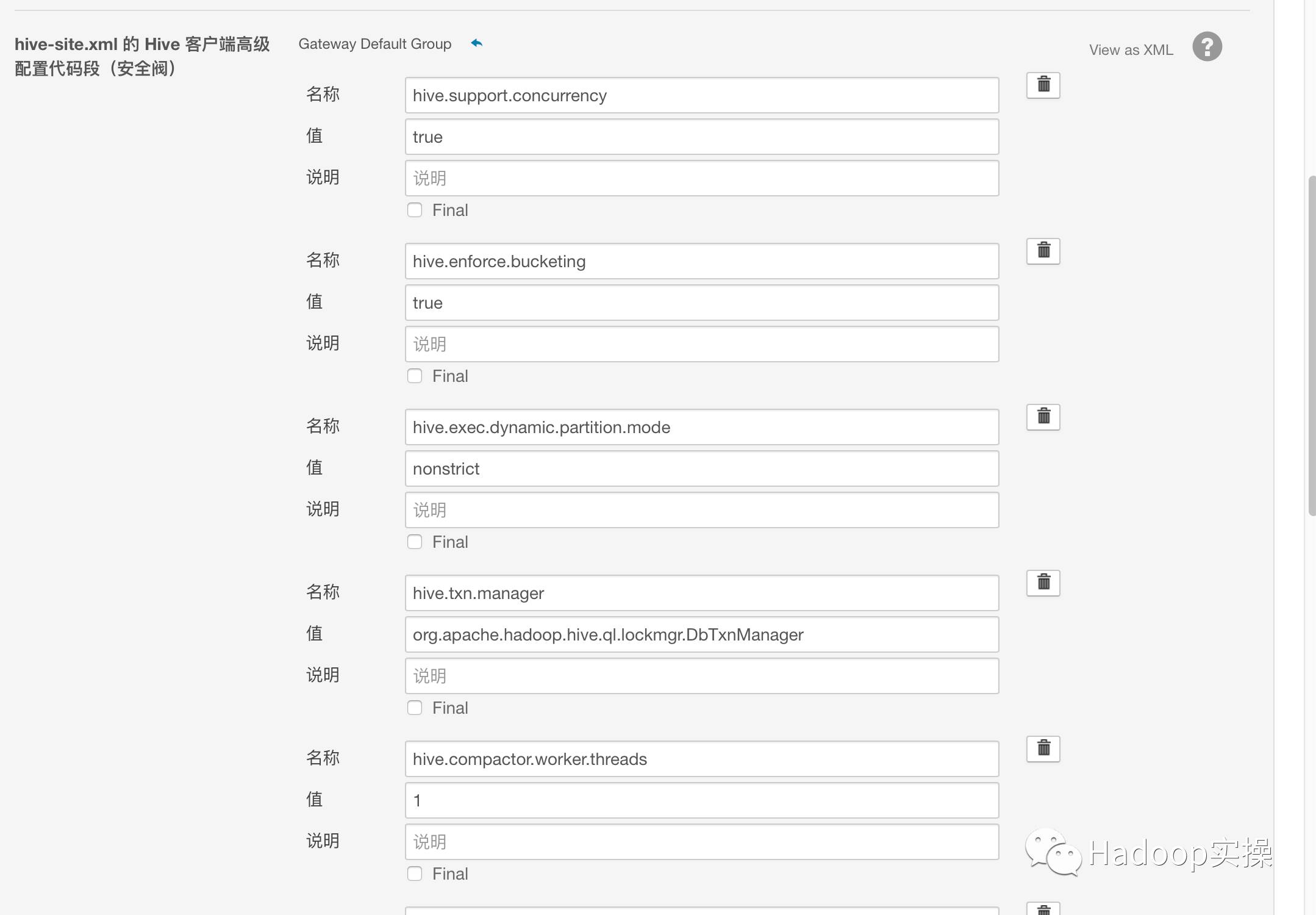
为了使Hive支持事务操作,需将以下参数加入到hive-site.xml文件中。
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.enforce.bucketing</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads </name>
<value>1</value>
</property>
可以在Cloudera Manager进行以下配置:
为了让beeline支持还需要配置:
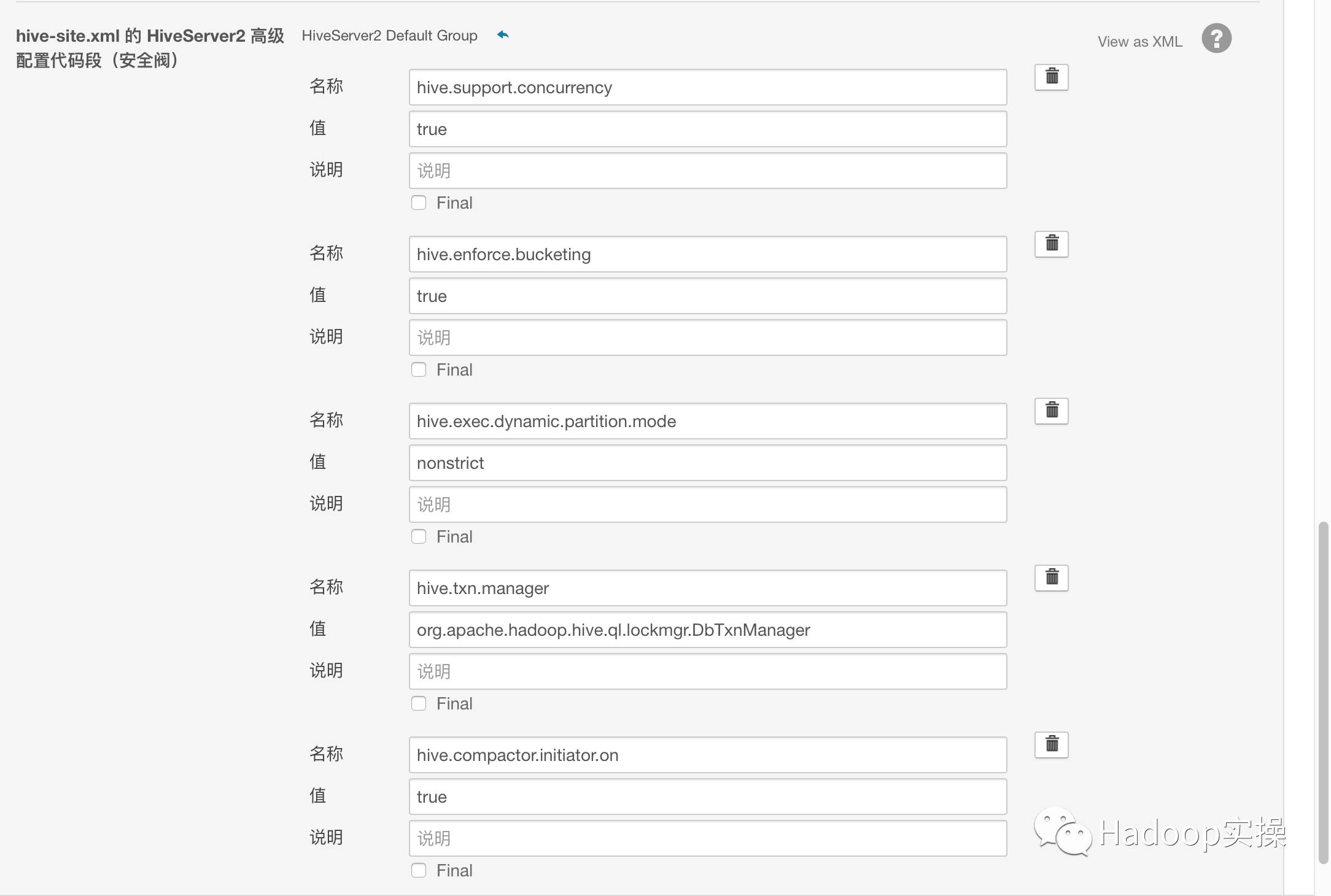
保存配置回到CM主页重启相应服务。
4.配置Flume Agent
1.配置Flume Agent读取Kafka数据写入Hive
kafka.channels = c1
kafka.sources = s1
kafka.sinks = k1
kafka.sources.s1.type = org.apache.flume.source.kafka.KafkaSource
kafka.sources.s1.kafka.bootstrap.servers=cdh04.fayson.com:9092,ip-172-31-5-190.fayson.com:9020,ip-172-31-10-118.fayson.com:9020
kafka.sources.s1.kafka.topics = flumetopic
kafka.sources.s1.kafka.consumer.group.id= flume-consumer
kafka.sources.s1.channels = c1
kafka.channels.c1.type = memory
kafka.sinks.k1.type = hive
kafka.sinks.k1.channel = c1
kafka.sinks.k1.hive.metastore = thrift://ip-172-31-6-148.fayson.com:9083
kafka.sinks.k1.hive.database = default
kafka.sinks.k1.hive.table = flume_kafka_logs
kafka.sinks.k1.hive.partition = %y-%m-%d
kafka.sinks.k1.serializer = DELIMITED
kafka.sinks.k1.serializer.delimiter="\t"
kafka.sinks.k1.serializer.serdeSeparator= '\t'
kafka.sinks.k1.serializer.fieldnames =id,name,age
注意黄色标注部分,如果分割符为特殊字符则需要使用双引号”\t”
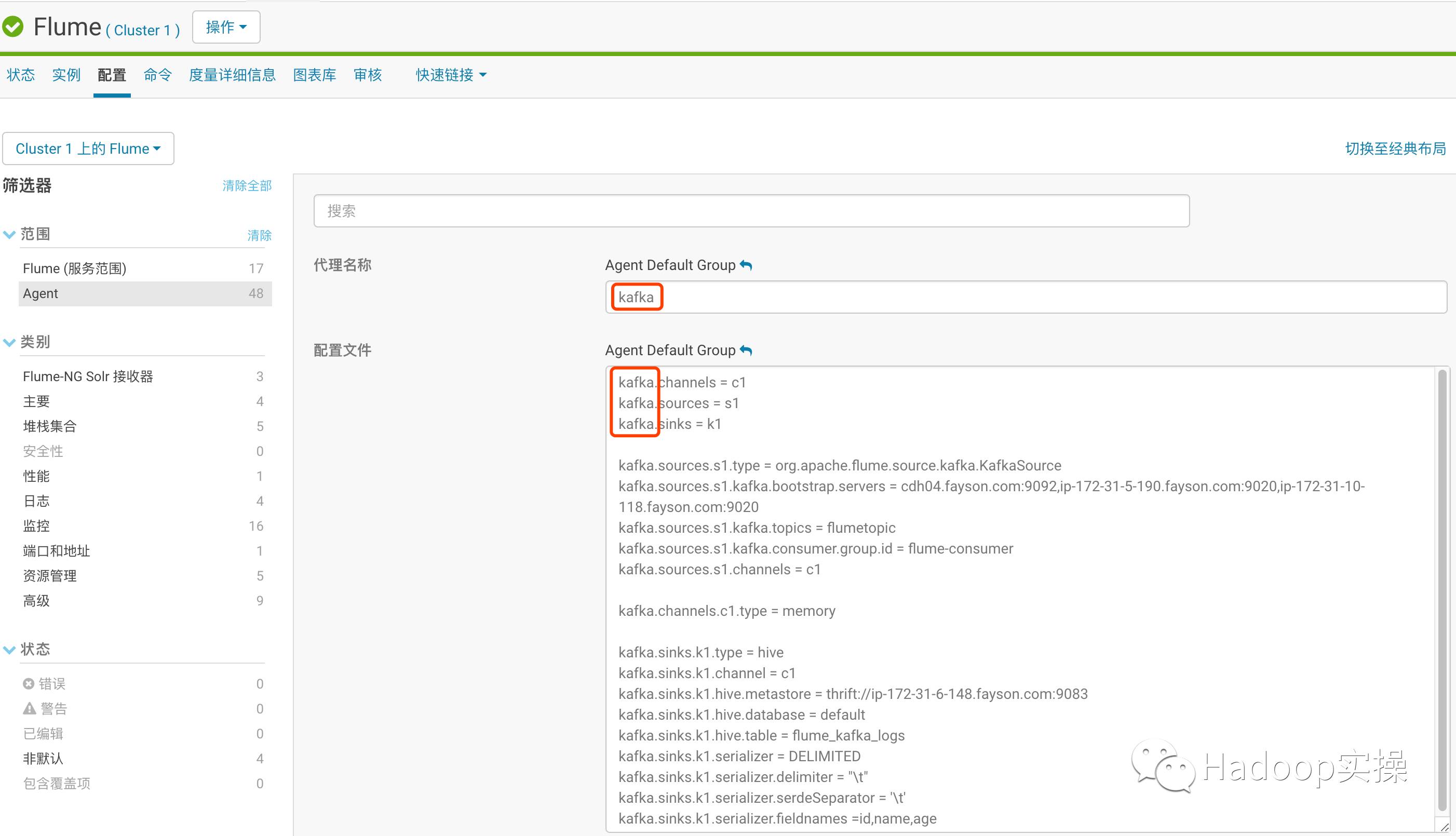
配置完成后保存更改并重启Flume Agent服务。
5.测试环境准备
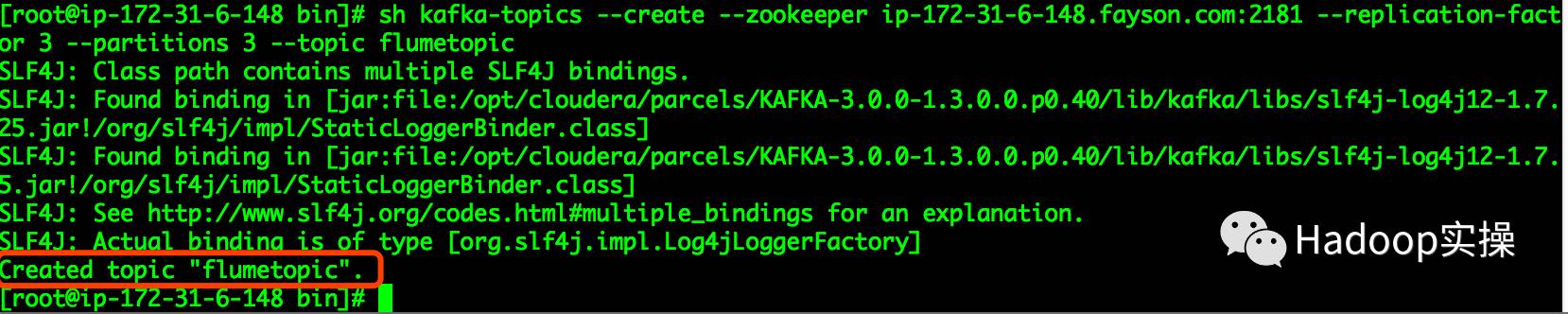
1.创建一个测试的topic名为flumetopic
[root@ip-172-31-6-148 bin]# sh kafka-topics --create --zookeeper ip-172-31-6-148.fayson.com:2181 --replication-factor 3 --partitions 3 --topic flumetopic
2.将编写好的Java代码打包部署

3.创建Hive表
create table flume_kafka_logs(
id int,
name string,
age int
) PARTITIONED BY(year STRING)
clustered by (id) into 5 buckets
stored as orc;
注意:这里的Hive表必须是orc格式且表必须分桶。
6.Kafka->Flume->Hive流程测试
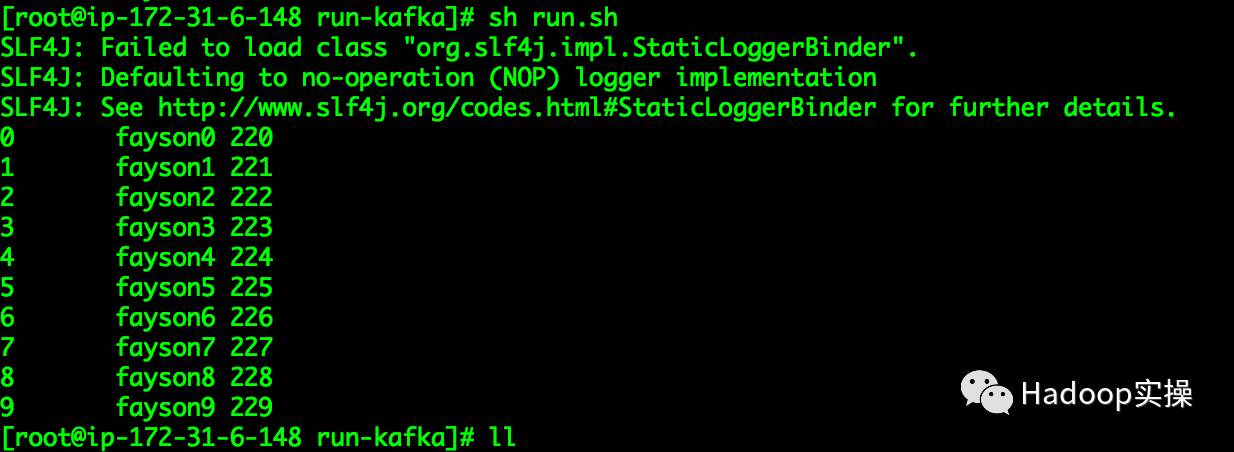
1.将开发好的Java代码编译打包部署在CDH集群的GateWay节点

2.执行run.sh
[root@ip-172-31-6-148 run-kafka]# sh run.sh
3.使用Hue查看flume_kafka_logs表数据
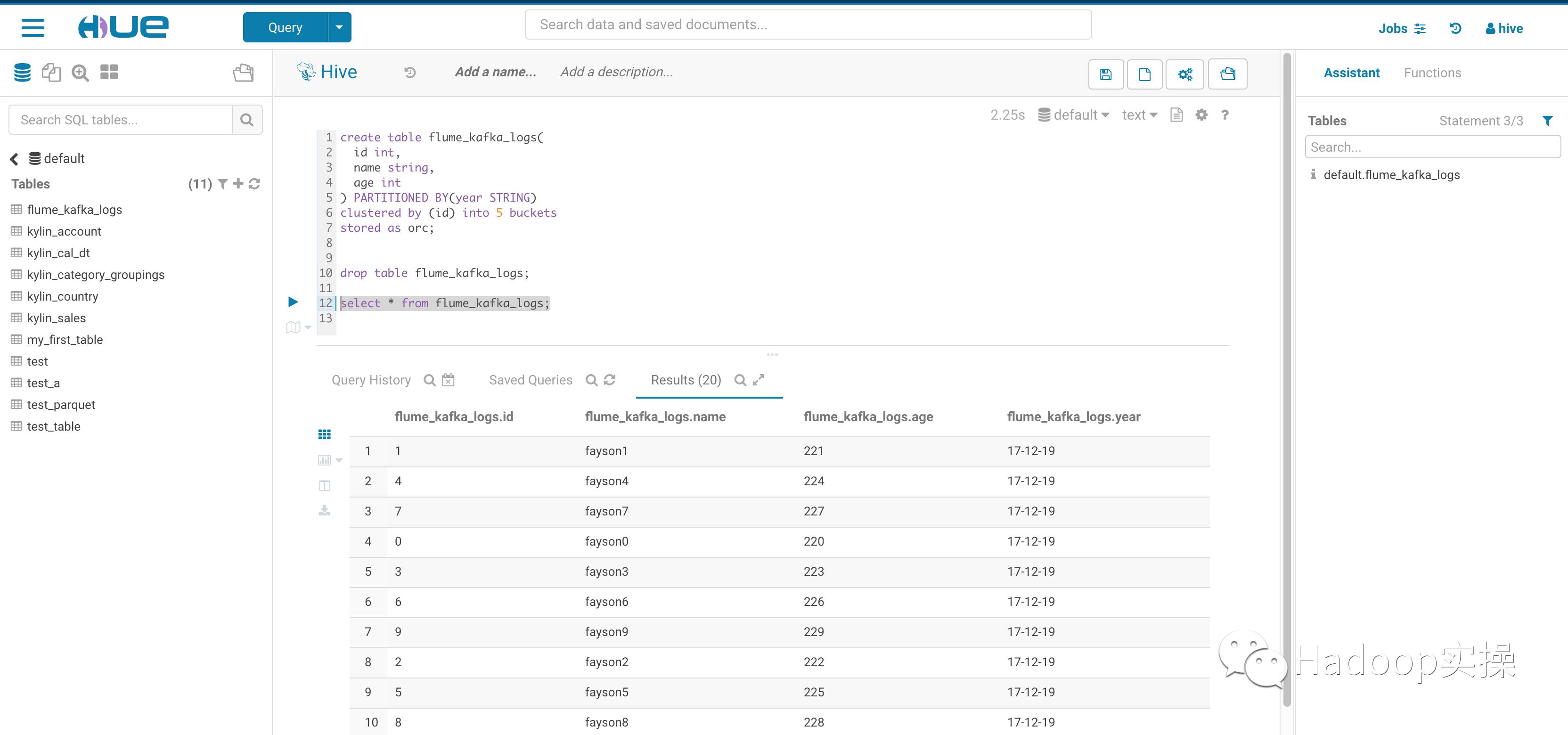
可以看到数据已写入flume_kafka_logs表中。
7.常见问题
1.Flume配置了Sink为Hive类型时,启动报错
2017-12-19 03:37:52,135 ERROR org.apache.flume.node.PollingPropertiesFileConfigurationProvider: Failed to start agent because dependencies were not found in classpath. Error follows.
java.lang.NoClassDefFoundError: org/apache/hive/hcatalog/streaming/RecordWriter
at org.apache.flume.sink.hive.HiveSink.createSerializer(HiveSink.java:219)
at org.apache.flume.sink.hive.HiveSink.configure(HiveSink.java:202)
at org.apache.flume.conf.Configurables.configure(Configurables.java:41)
at org.apache.flume.node.AbstractConfigurationProvider.loadSinks(AbstractConfigurationProvider.java:411)
at org.apache.flume.node.AbstractConfigurationProvider.getConfiguration(AbstractConfigurationProvider.java:102)
at org.apache.flume.node.PollingPropertiesFileConfigurationProvider$FileWatcherRunnable.run(PollingPropertiesFileConfigurationProvider.java:141)
at java.util.concurrent.Executors$RunnableAdapter.call(Executors.java:511)
at java.util.concurrent.FutureTask.runAndReset(FutureTask.java:308)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.access$301(ScheduledThreadPoolExecutor.java:180)
at java.util.concurrent.ScheduledThreadPoolExecutor$ScheduledFutureTask.run(ScheduledThreadPoolExecutor.java:294)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:748)
Caused by: java.lang.ClassNotFoundException: org.apache.hive.hcatalog.streaming.RecordWriter
at java.net.URLClassLoader.findClass(URLClassLoader.java:381)
at java.lang.ClassLoader.loadClass(ClassLoader.java:424)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:335)
at java.lang.ClassLoader.loadClass(ClassLoader.java:357)
... 13 more
原因:由于Flume的HiveSink有依赖Hive项目,所以需要将Hive相关的依赖包加入Flume的lib目录下。
解决方法:
[root@ip-172-31-6-148 conf]# scp /opt/cloudera/parcels/CDH/jars/hive-* /opt/cloudera/parcels/CDH/lib/flume-ng/lib/
8.总结
Flume向Hive中写入数据时,Hive必须支持事物,创建的flume_kafka_logs表必须分桶且文件格式为ORC。具体参考:
http://flume.apache.org/FlumeUserGuide.html#hive-sink
HiveSink只支持有分隔符的文本或JSON数据
HiveSink支持向Hive表或分区中写入数据,当分区不存在时Flume会自动创建。
为天地立心,为生民立命,为往圣继绝学,为万世开太平。
温馨提示:要看高清无码套图,请使用手机打开并单击图片放大查看。
您可能还想看
安装
安全
数据科学
其他
推荐关注Hadoop实操,第一时间,分享更多Hadoop干货,欢迎转发和分享。
以上是关于非Kerberos环境下Kafka数据到Flume进Hive表的主要内容,如果未能解决你的问题,请参考以下文章