java网络爬虫基础学习
Posted 芒果绿
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java网络爬虫基础学习相关的知识,希望对你有一定的参考价值。
jsoup的使用
jsoup介绍
jsoup是一款Java的html解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,css以及类似于Jquery的操作方法来取出和操作数据。
主要功能
- 从一个URL,文件或字符串中解析出HTML。
- 使用DOM或css选择器来查找、取出数据。
- 可操作HTML元素、属性、文本。
直接请求URL
一开始直接使用jsonp的connect方法调用上节说的请求电影json数据会报错

错误如下:

这里不太清楚发生错误的原因,毕竟换了一个连接变成http://www.w3school.com.cn/b.asp就可以正常输出html页面
如下
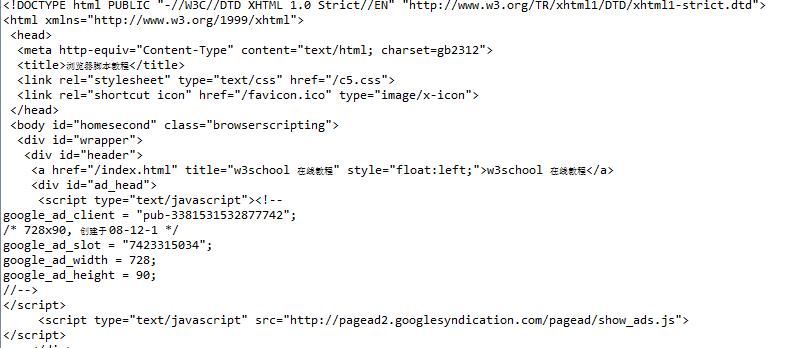
后来看了下网上,又看了看异常代码,发现是缺少contentType设置,于是加ignoreContentType(true)设置
public class Simple { public static void main(String[] args) { try { Document doc = Jsoup .connect("https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=time&page_limit=20&page_start=0") .ignoreContentType(true).userAgent("Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36") .timeout(5000) .get(); //Document doc1 = Jsoup //.connect("http://www.w3school.com.cn/b.asp").get(); System.out.println(doc); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } } }
成功

整合一下,用jsoup来抓取电影信息如下
main里运行:
public static void test2(){ try { Response res = Jsoup .connect("https://movie.douban.com/j/search_subjects?type=movie&tag=%E7%83%AD%E9%97%A8&sort=time&page_limit=20&page_start=0") .header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8") .header("Host", "movie.douban.com") .header("Accept-Encoding", "gzip, deflate") .header("Accept-Language","zh-cn,zh;q=0.5") //.header("Content-Type", "application/json;charset=UTF-8") .header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36") .header("Connection", "keep-alive") .header("Cache-Control", "max-age=0") .ignoreContentType(true) .timeout(5000) .execute(); String body = res.body(); JSONObject jsonObject = JSONObject.parseObject(body); JSONArray array = jsonObject.getJSONArray("subjects"); for(int i=0;i<array.size();i++){ //循环projects的json数组 JSONObject jo = array.getJSONObject(i); Movie movie = jo.toJavaObject(Movie.class); System.out.println(movie); } //System.out.println(array.get(1)); } catch (IOException e) { // TODO Auto-generated catch block e.printStackTrace(); } }
Movie.java:
public class Movie implements Serializable{ /** * */ private static final long serialVersionUID = 1L; private String rate; private String cover_x; private String title; private String url; private String playable; private String cover; private String id; private String cover_y; private String is_new; public Movie() { // TODO Auto-generated constructor stub } public Movie(String rate, String cover_x, String title, String url, String playable, String cover, String id, String cover_y, String is_new) { super(); this.rate = rate; this.cover_x = cover_x; this.title = title; this.url = url; this.playable = playable; this.cover = cover; this.id = id; this.cover_y = cover_y; this.is_new = is_new; } public String getRate() { return rate; } public void setRate(String rate) { this.rate = rate; } public String getCover_x() { return cover_x; } public void setCover_x(String cover_x) { this.cover_x = cover_x; } public String getTitle() { return title; } public void setTitle(String title) { this.title = title; } public String getUrl() { return url; } public void setUrl(String url) { this.url = url; } public String getPlayable() { return playable; } public void setPlayable(String playable) { this.playable = playable; } public String getCover() { return cover; } public void setCover(String cover) { this.cover = cover; } public String getId() { return id; } public void setId(String id) { this.id = id; } public String getCover_y() { return cover_y; } public void setCover_y(String cover_y) { this.cover_y = cover_y; } public String getIs_new() { return is_new; } public void setIs_new(String is_new) { this.is_new = is_new; } @Override public String toString() { return "Movie [评分:" + rate + ", 电影:" + title +"]"; } }
输出
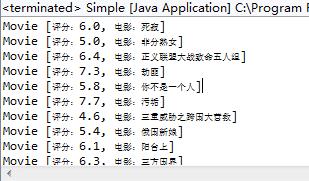
到此,简单的jsoup测试~
以上是关于java网络爬虫基础学习的主要内容,如果未能解决你的问题,请参考以下文章