02-Java是如何解析xml文件的(DOM)
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了02-Java是如何解析xml文件的(DOM)相关的知识,希望对你有一定的参考价值。
Java解析xml文件
在Java程序中读取xml文件的过程也称为“解析xml文件”;
解析的目的:
- 获取 节点名和节点值
- 获取 属性名、属性值。
四中解析方式:
- DOM
- SAX
- DOM4J
- JDOM
(其中DOM、SAX是官方提供的解析方式,不需要额外的jar包,后两种则需要)
例:DOM方式解析books.xml文件
<?xml version="1.0" encoding="UTF-8" ?><bookstore><book type="fiction" id="1"><name>冰与火之歌</name><author>乔治马丁</author><year>2014</year><price>89</price></book><book id="2"><name>安徒生童话</name><year>2004</year><price>77</price><language>English</language></book></bookstore>
以上是我们需要解析的xml文件,我们的目的是:通过Java获取xml文件的所有数据。
准备工作
准备工作:
- (1)创建一个DocumentBuilderFactory对象
- (2)创建一个DocumentBuilder对象
- (3)通过DocumentBuilder对象的parse(String fileName)方法解析xml文件
public class DomTest {public static void main(String[] args) {//(1)创建DocumentBuilderFactory对象DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();try {//(2)创建DocumentBuilder对象DocumentBuilder db = dbf.newDocumentBuilder();//(3)通过DocumentBuilder对象的parse方法加载book.xmlDocument document = db.parse("books.xml");- } catch (ParserConfigurationException e) {
e.printStackTrace();} catch (SAXException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}- }
}
解析xml文件属性
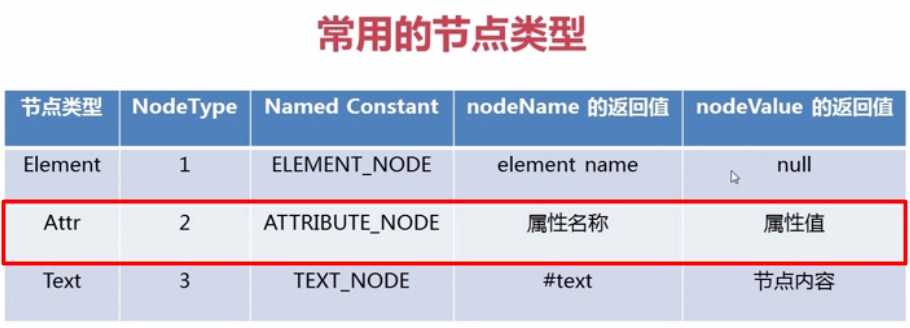
解析属性:
- (1)Document类来获取节点集合
- (2)遍历节点集合
- (3)通过item(i)获取节点Node
- (4)通过Node的getAttributes获取节点的属性集合
- (5)遍历属性
- (6)获取属性和属性名
public class DomTest {public static void main(String[] args) {//创建DocumentBuilderFactory对象DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();try {//创建DocumentBuilder对象DocumentBuilder db = dbf.newDocumentBuilder();//通过DocumentBuilder对象的parse方法加载book.xmlDocument document = db.parse("books.xml");//(1)获取所有book节点的集合NodeList booklist = document.getElementsByTagName("book");System.out.println("共有" + booklist.getLength() + "本书");System.out.println("-------------------------------------");//(2)遍历每个book节点for (int i = 0; i < booklist.getLength(); i++) {//(3)通过item(i)获取book节点,nodelist索引从0开始Node book = booklist.item(i);//(4)获取book节点的所有属性集合NamedNodeMap attrs = book.getAttributes();//获取属性的数量System.out.println("第" + (i + 1) + "本书有" + attrs.getLength() + "个属性");System.out.print("分别是:");//(5)遍历book的属性for (int j = 0; j < attrs.getLength(); j++) {//(6)获取属性Node att = attrs.item(j);//(6)获取属性的名称String attName = att.getNodeName();System.out.print(attName + ", ");}System.out.println();System.out.println("-------------------------------------");}} catch (ParserConfigurationException e) {e.printStackTrace();} catch (SAXException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}}
打印结果:
共有2本书-------------------------------------第1本书有2个属性分别是:id, type,-------------------------------------第2本书有1个属性分别是:id,-------------------------------------
解析xml文件属性的子节点
解析子节点:
- (1)使用getChildNodes()获取子节点集合
- (2)遍历子节点
- (3)获取子节点
- (4)输出子节点名称和内容
public class DomTest {public static void main(String[] args) {//创建DocumentBuilderFactory对象DocumentBuilderFactory dbf = DocumentBuilderFactory.newInstance();try {//创建DocumentBuilder对象DocumentBuilder db = dbf.newDocumentBuilder();//通过DocumentBuilder对象的parse方法加载book.xmlDocument document = db.parse("books.xml");//获取所有book节点的集合NodeList booklist = document.getElementsByTagName("book");System.out.println("共有" + booklist.getLength() + "本书");System.out.println("-------------------------------------");//遍历每个book节点for (int i = 0; i < booklist.getLength(); i++) {//通过item(i)获取book节点,nodelist索引从0开始Node book = booklist.item(i);//获取book节点的所有属性集合NamedNodeMap attrs = book.getAttributes();//获取属性的数量System.out.println("第" + (i + 1) + "本书有" + attrs.getLength() + "个属性");System.out.print("分别是:");//遍历book的属性for (int j = 0; j < attrs.getLength(); j++) {//获取属性Node att = attrs.item(j);//获取属性的名称String attName = att.getNodeName();System.out.print(attName + ", ");}System.out.println();System.out.println("子节点:");//(1)解析book节点的子节点NodeList bookChildNodes = book.getChildNodes();//(2)遍历bookChildNodes获取每个子节点for (int k = 0; k < bookChildNodes.getLength(); k++) {//(3)获取子节点Node bookChild = bookChildNodes.item(k);//注(a)//区分text类型的node以及element类型的node(子节点含我们不需要的文本型,所以我们要筛选)if (bookChild.getNodeType() == Node.ELEMENT_NODE) {//注(b)//(4)获取和输出节点名和节点内容//方法1:System.out.println(bookChild.getNodeName() + ", " + bookChild.getTextContent());//方法2://System.out.println(bookChild.getNodeName() + ", " + bookChild.getFirstChild().getNodeValue());}}System.out.println("-------------------------------------");}} catch (ParserConfigurationException e) {e.printStackTrace();} catch (SAXException e) {e.printStackTrace();} catch (IOException e) {e.printStackTrace();}}}
打印结果:
共有2本书-------------------------------------第1本书有2个属性分别是:id, type,子节点:name, test冰与火之歌author, 乔治马丁year, 2014price, 89-------------------------------------第2本书有1个属性分别是:id,子节点:name, 安徒生童话year, 2004price, 77language, English-------------------------------------

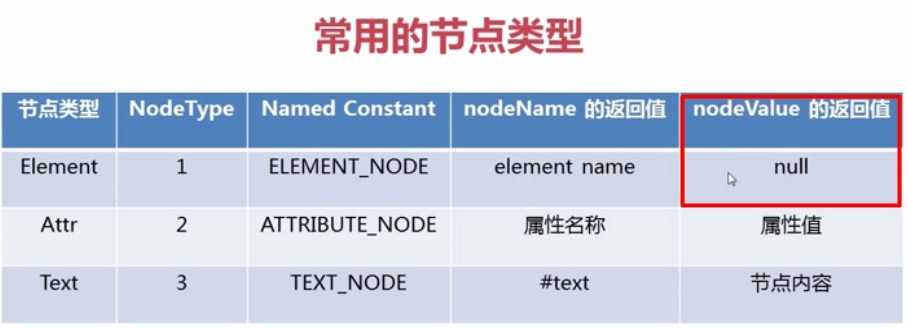
注(a):解析时是把空白也算为文本型的子节点,如下看似只有4个子节点,算上空白会输出9个子节点。
<bookstroe><book id="1"><name>冰与火之歌</name><author>乔治马丁</author><year>2014</year><price>89</price></book></bookstroe
如上图所示,黄色和橙色也都算成了text类型的节点,这是我们不需要的,往往需要判断筛选。
<bookstroe><book id="1"><name>冰与火之歌</name><author>乔治马丁</author><year>2014</year><price>89</price></book></bookstroe>
注(b):假如此时我们想要获取<name>中的“冰与火之歌”
1)获取子节点的内容的时候,不是使用getNodeValue(),如上图,该方法只会返回null;我们要使用getTextContent()来获取两个标签中间的内容;
2)另外,也可以使用获取这个子节点的子节点,之前有提到,text也被视为子节点,这里的“冰与火之歌”被视为<name>的子节点,所以获取子节点的子节点以后,再使用getNodeValue()才有意义,即先获取book的子节点<name>,再获取name的子节点;
3)这两种方法的区别:
假如有<name><a>test</a>冰与火之歌</name>
getTextContext() --> test冰与火之歌(获取name下所有的文本并拼接起来)
getFirstChild().getNodeValue() --> null(获得子节点并输出其值)
如何在Java中保留xml数据的结构?
创建一个Book类,包含属性name、author、year、price等,在解析该xml的同时,就对该对象中的属性进行赋值。
当然,多个对象的时候,自然还需要存到集合中去。
附件:源码
附件列表
以上是关于02-Java是如何解析xml文件的(DOM)的主要内容,如果未能解决你的问题,请参考以下文章