java中采用dom4j解析xml文件
Posted 独具匠心
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java中采用dom4j解析xml文件相关的知识,希望对你有一定的参考价值。
一.前言
在最近的开发中用到了dom4j来解析xml文件,以前听说过来解析xml文件的几种标准方式;但是从来的没有应用过来,所以可以在google中搜索dmo4j解析xml文件的方式,学习一下dom4j解析xml的具体操作。
二.代码详情
dom4j是一个第三方开发组开发出的插件,所以在我们使用dom4jf的时候我们要去下载一下dom4j对应版本的jar导入在我们项目中。
1)xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<books>
<book id="001">
<title>Harry Potter</title>
<author>J K. Rowling</author>
</book>
<book id="002">
<title>Learning XML</title>
<author>Erik T. Ray</author>
</book>
</books>
示例一:用List列表的方式来解析xml
SAXReader就是一个管道,用一个流的方式,把xml文件读出来
import java.io.File;
import java.util.List;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Demo {
public static void main(String[] args) throws Exception {
SAXReader reader = new SAXReader();
File file = new File("books.xml");
Document document = reader.read(file);
Element root = document.getRootElement();
List<Element> childElements = root.elements();
for (Element child : childElements) {
//未知属性名情况下
/*List<Attribute> attributeList = child.attributes();
for (Attribute attr : attributeList) {
System.out.println(attr.getName() + ": " + attr.getValue());
}*/
//已知属性名情况下
System.out.println("id: " + child.attributeValue("id"));
//未知子元素名情况下
/*List<Element> elementList = child.elements();
for (Element ele : elementList) {
System.out.println(ele.getName() + ": " + ele.getText());
}
System.out.println();*/
//已知子元素名的情况下
System.out.println("title" + child.elementText("title"));
System.out.println("author" + child.elementText("author"));
//这行是为了格式化美观而存在
System.out.println();
}
}
}
示例二:使用Iterator迭代器的方式来解析xml
import java.io.File;
import java.util.Iterator;
import org.dom4j.Attribute;
import org.dom4j.Document;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Demo {
public static void main(String[] args) throws Exception {
SAXReader reader = new SAXReader();
Document document = reader.read(new File("books.xml"));
Element root = document.getRootElement();
Iterator it = root.elementIterator();
while (it.hasNext()) {
Element element = (Element) it.next();
//未知属性名称情况下
/*Iterator attrIt = element.attributeIterator();
while (attrIt.hasNext()) {
Attribute a = (Attribute) attrIt.next();
System.out.println(a.getValue());
}*/
//已知属性名称情况下
System.out.println("id: " + element.attributeValue("id"));
//未知元素名情况下
/*Iterator eleIt = element.elementIterator();
while (eleIt.hasNext()) {
Element e = (Element) eleIt.next();
System.out.println(e.getName() + ": " + e.getText());
}
System.out.println();*/
//已知元素名情况下
System.out.println("title: " + element.elementText("title"));
System.out.println("author: " + element.elementText("author"));
System.out.println();
}
}
}
运行结果:
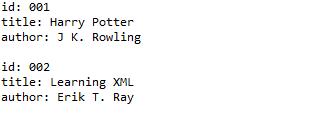
示例三:创建xml文档并输出到文件
import java.io.File;
import java.io.FileOutputStream;
import org.dom4j.Document;
import org.dom4j.DocumentHelper;
import org.dom4j.Element;
import org.dom4j.io.OutputFormat;
import org.dom4j.io.XMLWriter;
public class Demo {
public static void main(String[] args) throws Exception {
Document doc = DocumentHelper.createDocument();
//增加根节点
Element books = doc.addElement("books");
//增加子元素
Element book1 = books.addElement("book");
Element title1 = book1.addElement("title");
Element author1 = book1.addElement("author");
Element book2 = books.addElement("book");
Element title2 = book2.addElement("title");
Element author2 = book2.addElement("author");
//为子节点添加属性
book1.addAttribute("id", "001");
//为元素添加内容
title1.setText("Harry Potter");
author1.setText("J K. Rowling");
book2.addAttribute("id", "002");
title2.setText("Learning XML");
author2.setText("Erik T. Ray");
//实例化输出格式对象
OutputFormat format = OutputFormat.createPrettyPrint();
//设置输出编码
format.setEncoding("UTF-8");
//创建需要写入的File对象
File file = new File("D:" + File.separator + "books.xml");
//生成XMLWriter对象,构造函数中的参数为需要输出的文件流和格式
XMLWriter writer = new XMLWriter(new FileOutputStream(file), format);
//开始写入,write方法中包含上面创建的Document对象
writer.write(doc);
}
}
运行结果:

以上是关于java中采用dom4j解析xml文件的主要内容,如果未能解决你的问题,请参考以下文章