ELK+zookeeper+kafka收集springcould日志配置文档
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ELK+zookeeper+kafka收集springcould日志配置文档相关的知识,希望对你有一定的参考价值。
####
####
####

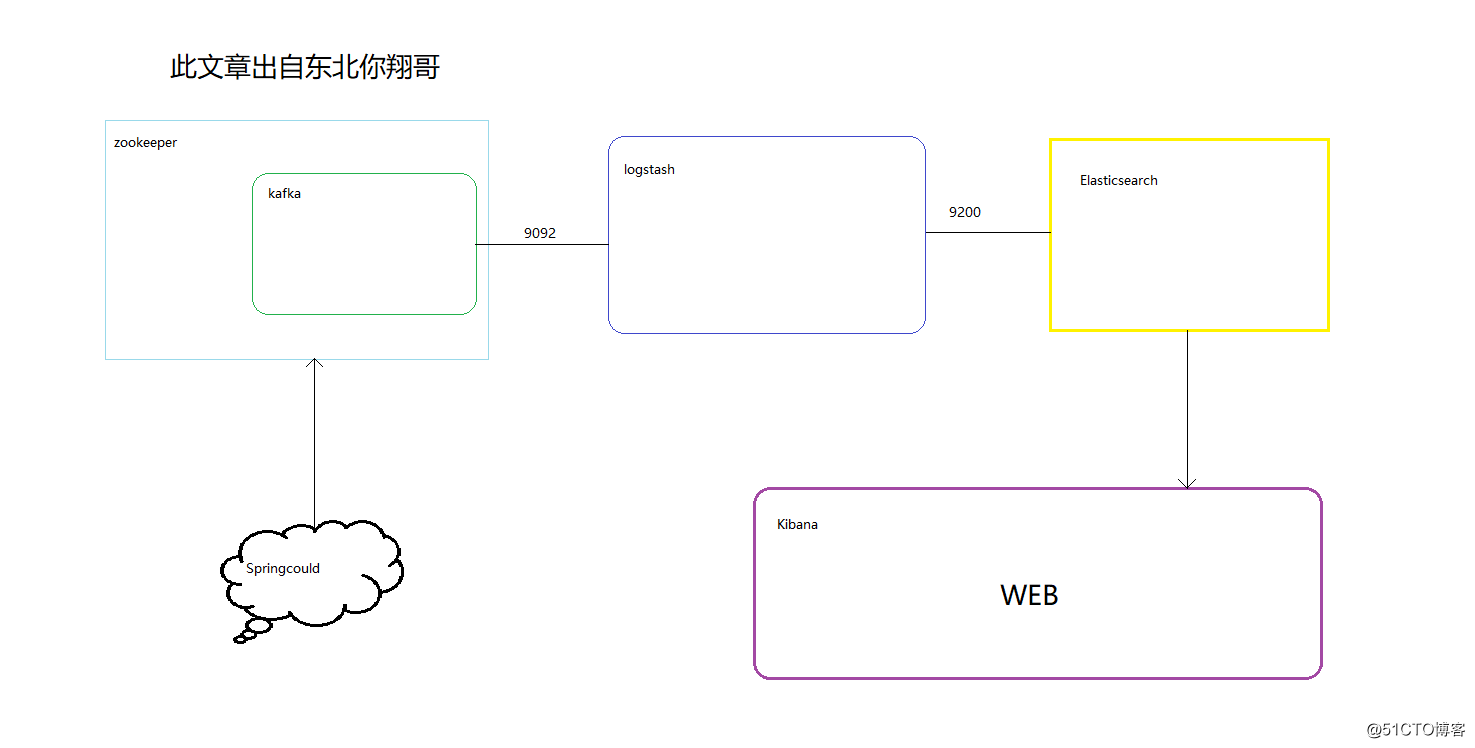
本文介绍使用ELK(elasticsearch、logstash、kibana) + kafka来搭建一个日志系统。主要演示使用spring aop进行日志收集,然后通过kafka将日志发送给logstash,logstash再将日志写入elasticsearch,这样elasticsearch就有了日志数据了,最后,则使用kibana将存放在elasticsearch中的日志数据显示出来,并且可以做实时的数据图表分析等等。
最开始我些项目的时候,都习惯用log4j来把日志写到log文件中,后来项目有了高可用的要求,我们就进行了分布式部署web,这样我们还是用log4j这样的方式来记录log的话,那么就有N台机子的N个log目录,ELK正常使用时需要在每台机器上都安装logstash等收集日志的客户端,这个时候查找log起来非常麻烦,不知道问题用户出错log是写在哪一台服务器上的,后来,想到一个办法,干脆把log直接写到数据库中去,这样做,虽然解决了查找异常信息便利性的问题了,但存在两个缺陷:
1,log记录好多,表不够用啊,又得分库分表了,
2,连接db,如果是数据库异常,那边log就丢失了,那么为了解决log丢失的问题,那么还得先将log写在本地,然后等db连通了后,再将log同步到db,这样的处理办法,感觉是越搞越复杂。
现在ELK的做法
好在现在有了ELK这样的方案,可以解决以上存在的烦恼,首先是,使用elasticsearch来存储日志信息,对一般系统来说可以理解为可以存储无限条数据,因为elasticsearch有良好的扩展性,然后是有一个logstash,可以把理解为数据接口,为elasticsearch对接外面过来的log数据,它对接的渠道,有kafka,有log文件,有redis等等,足够兼容N多log形式,最后还有一个部分就是kibana,它主要用来做数据展现,log那么多数据都存放在elasticsearch中,我们得看看log是什么样子的吧,这个kibana就是为了让我们看log数据的,但还有一个更重要的功能是,可以编辑N种图表形式,什么柱状图,折线图等等,来对log数据进行直观的展现。

ELK职能分工
logstash做日志对接,接受应用系统的log,然后将其写入到elasticsearch中,logstash可以支持N种log渠道,kafka渠道写进来的、和log目录对接的方式、也可以对reids中的log数据进行监控读取,等等。
elasticsearch存储日志数据,方便的扩展特效,可以存储足够多的日志数据。
kibana则是对存放在elasticsearch中的log数据进行:数据展现、报表展现,并且是实时的。
此次安装的软件:es,kibana,logstash,kafka,zookeeper
ELK版本最好选用5以上的版本,es需要用普通用户起服务还需要注意系统的最大打开文件数等参数,索引的应用基本都是解压即可。
修改系统参数
vi /etc/security/limits.conf
* soft nproc 65536
* hard nproc 65536
* soft nofile 65536
* hard nofile 65536
vi /etc/sysctl.conf
vm.max_map_count= 262144
sysctl -p ####
####
es: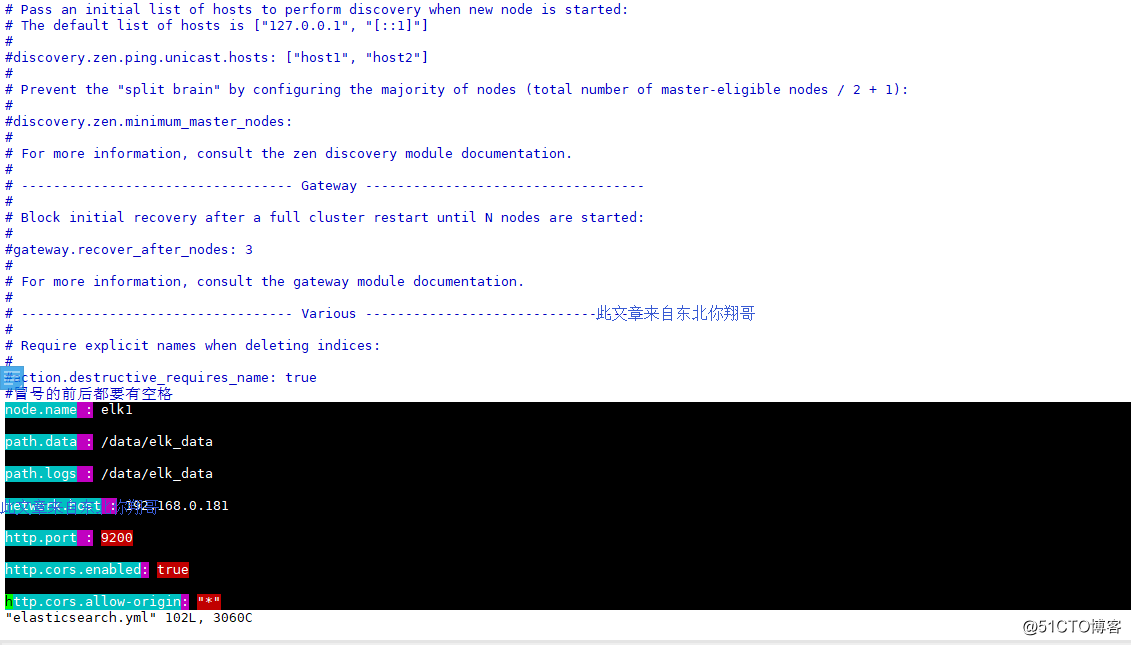
vim elasticsearch.yml
node.name : elk1
path.data : /data/elk_data
path.logs : /data/elk_data
network.host : 192.168.0.181
http.port : 9200
http.cors.enabled: true
http.cors.allow-origin: "*"
##
由于head插件本质上还是一个nodejs的工程,因此需要安装node,使用npm来安装依赖的包。(npm可以理解为maven)
下载node-v6.10.3-linux-x64.tar.gz ,nodejs下载地址
把“node-v6.10.3-linux-x64.tar.gz”拷贝到centos上,本示例目录为:/opt/es/
cd /opt/es/
tar -xzvf node-v6.10.3-linux-x64.tar.gz
ln -s /opt/es/node-v6.10.3-linux-x64/bin/node /usr/local/bin/node
ln -s /opt/es/node-v6.10.3-linux-x64/bin/npm /usr/local/bin/npm
cd /opt/es/node-v6.10.3-linux-x64/bin/
测试是否安装成功
npm -v#####
#####
kibana:
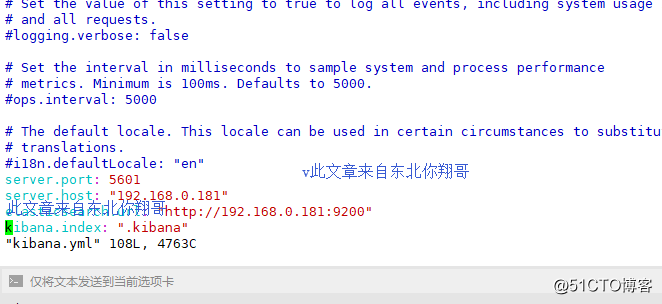
vim kibana.yml
server.port: 5601
server.host: "192.168.0.181"
elasticsearch.url: "http://192.168.0.181:9200"
kibana.index: ".kibana"
#####
#####
kafka:
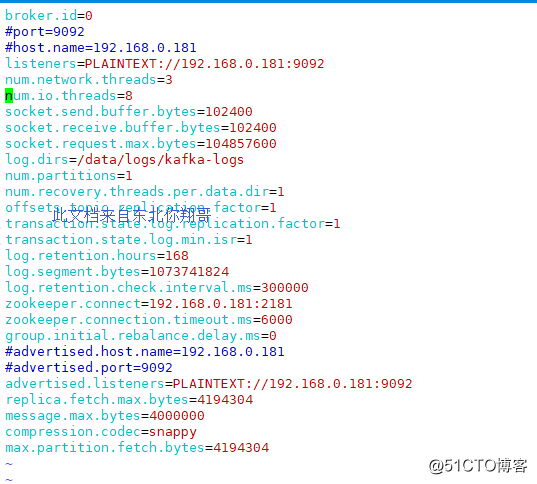
vim server.properties
broker.id=0
#port=9092
#host.name=192.168.0.181
listeners=PLAINTEXT://192.168.0.181:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/data/logs/kafka-logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=192.168.0.181:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
#advertised.host.name=192.168.0.181
#advertised.port=9092
advertised.listeners=PLAINTEXT://192.168.0.181:9092
replica.fetch.max.bytes=4194304
message.max.bytes=4000000
compression.codec=snappy
max.partition.fetch.bytes=4194304#
#
添加topic
./kafka-topics.sh --create --topic app-log --replication-factor 1 --partitions 1 --zookeeper localhost:2181
./kafka-topics.sh --list --zookeeper localhost:2181
#
./kafka-console-producer.sh --broker-list 192.168.0.181:9092 --topic app-log
./kafka-console-consumer.sh --zookeeper 192.168.0.181:2181 --topic app-log --from-beginning //查看输出

####
####
logstash:
添加配置文件,启动logstash时-f指定配置文件
[[email protected] config]# cat kafka.conf
input {
kafka {
bootstrap_servers => "192.168.0.181:9092"
group_id => "app-log"
topics => ["app-log"]
consumer_threads => 5
decorate_events => false
auto_offset_reset => "earliest" #latest最新的;earliest最开始的
}
}
filter {
json {
source => "message"
}
if [severity] == "DEBUG" {
drop {}
}
}
output {
elasticsearch {
action => "index" #The operation on ES
hosts => "192.168.0.181:9200" #ElasticSearch host, can be array.
# index => "applog" #The index to write data to.
index => "applog-%{+YYYY.MM.dd}"
}
}####
####
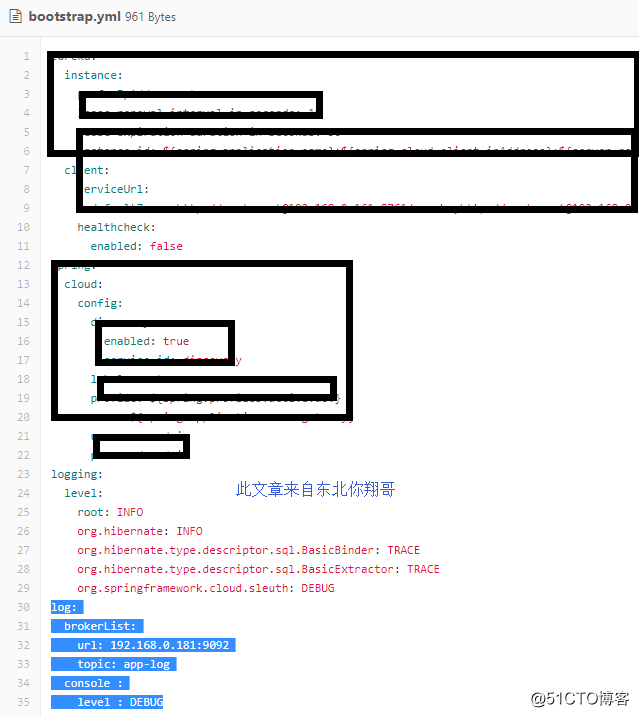
springcould日志配置
###
###

log:
brokerList:
url: 192.168.0.181:9092
topic: app-log
console :
level : DEBUG#
#
#
#
<appender name="KAFKA" class="com.skong.core.logs.KafkaAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
以上是关于ELK+zookeeper+kafka收集springcould日志配置文档的主要内容,如果未能解决你的问题,请参考以下文章
elk6.3.1+zookeeper+kafka+filebeat收集dockerswarm容器日志
ELK+Kafka+Filebeat企业级日志收集系统 #yyds干货盘点#