hibernate hibernate中查询方式详解
Posted 路虽远,梦还在!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hibernate hibernate中查询方式详解相关的知识,希望对你有一定的参考价值。
序言
之前对hibernate中的查询总是搞混淆,不明白里面具体有哪些东西。就是因为缺少总结。在看这篇文章之前,你应该知道的是数据库的一些查询操作,多表查询等,如果不明白,可以先去看一下 MySQL数据表查询操作详解 ,以至于看这篇文章不用那么吃力。
--WZY
一、hibernate中的5种检索方式
1.1、导航对象图检索方式
根据已经加载的对象导航到其他对象
例如:在前面的各种映射关系中,实体类包含对其他类对象的引用。
Dept d = (Dept) session.get(Dept.class,2);
d.getStaffSet().size(); //d对象关联Staff集合,hibernate会自动检索Staff数据。如何检索的,看下面图中发送的sql语句。
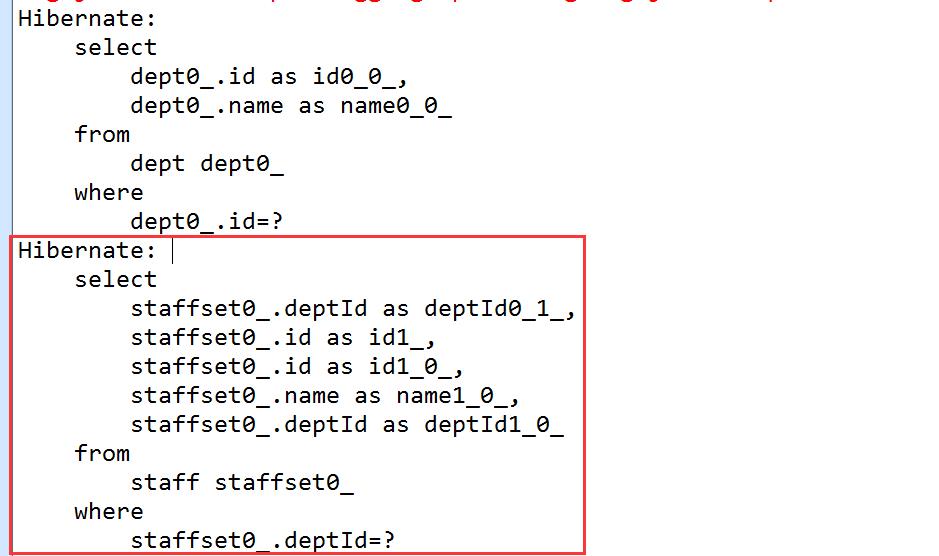
1.2、OID检索方式
按照对象的OID来检索对象
例如:session.get()/session.load()
这个大家度很熟悉了,就不用在这里过多的阐述了。
1.3、HQL检索方式
HQL:Hibernate Query Language ,是面向对象的查询语言,它和SQL查询语言有些相似,在Hibernate提供的各种检索方式中,HQL是使用的最广的一种检索方式,
注意:HQL操作的全是POJO类中的属性,而不是操作数据库表中的字段。
1.3.1、在查询语句中设定各种查询条件
1.3.2、支持投影查询,即仅检索出对象的部分属性
1.3.3、支持分页查询
1.3.4、支持连接查询
1.3.5、支持分组查询,允许使用HAVING 和 GROUP BY 关键字
1.3.6、提供内置聚集函数,如SUM(),MIN(),MAX()等
1.3.7、能够调用用户定义的SQL函数或标准的SQL函数
1.3.8、支持子查询
1.3.9、支持动态绑定参数
使用HQL检索步骤:
1>获得session
2>编写HQL
3>通过session.createQuery(HQL)创建Query对象
4>为Query对象设置条件参数(如果HQL中需要填充参数的话)
5>执行查询
list():返回一个集合列表,有可能集合中装的是数组,有可能是POJO对象。
uniqueResult():返回一个查询结果,在已知查询结果只有一个或者0个时,使用是没有问题的,如果返回结果有多个,那么就会报异常
实验
创建环境,使用Dept和Staff的双向一对多关系,其中具体的代码就不在列举出来了。重点不在这里。原始记录Staff中有9条记录,都指向了Dept中id为2的部门。
1.3.1、在查询语句中设定各种查询条件
1.3.1.1、查询全部记录,没有查询条件


1 //没有条件的hql,也就是查询全部记录。 2 String hql = "from Staff"; 3 Query hqlQuery = session.createQuery(hql); 4 List<Staff> list = hqlQuery.list(); 5 for(Staff staff : list){ 6 System.out.println(staff.toString()); 7 }
结果
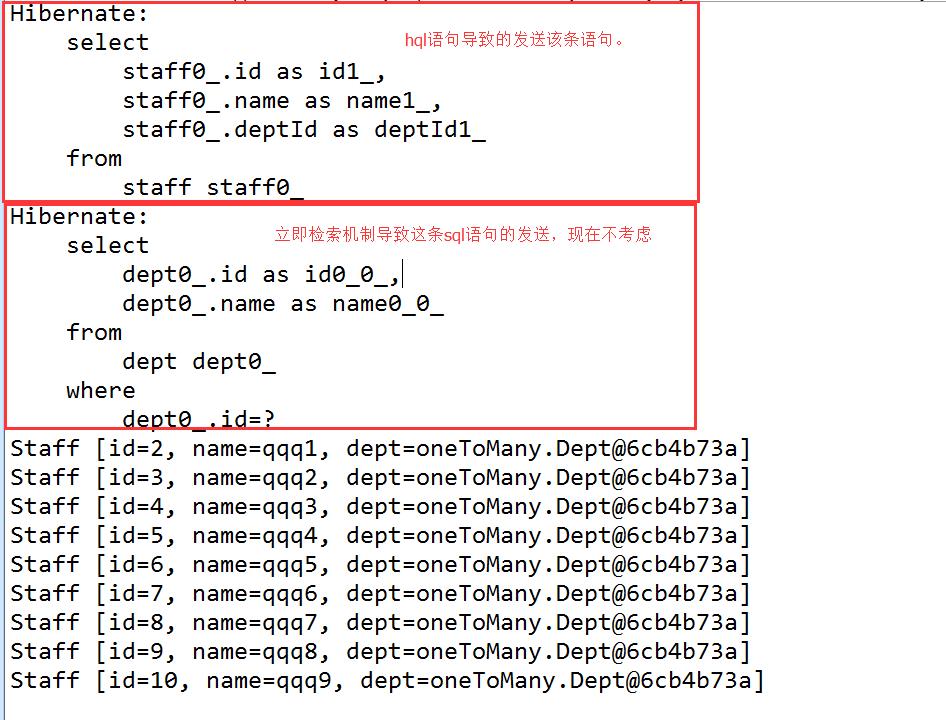
1.3.1.2、条件查询,查找出id=3的staff信息
1 String hql = "from Staff where id = 3"; 2 Query hqlQuery = session.createQuery(hql); 3 //方式一 4 // List<Staff> list = hqlQuery.list(); 5 // for(Staff staff : list){ 6 // System.out.println(staff.toString()); 7 // } 8 //方式二,已知只有一条数据,使用uniqueResult 9 Staff staff = (Staff) hqlQuery.uniqueResult(); 10 System.out.println(staff.toString()); 11 12 //结果 13 Hibernate: 14 select 15 staff0_.id as id1_, 16 staff0_.name as name1_, 17 staff0_.deptId as deptId1_ 18 from 19 staff staff0_ 20 where 21 staff0_.id=3 22 //因为是立即检索,所有有了这条语句,这里不做解释, 23 Hibernate: 24 select 25 dept0_.id as id0_0_, 26 dept0_.name as name0_0_ 27 from 28 dept dept0_ 29 where 30 dept0_.id=? 31 //查询到了响应结果 32 Staff [id=3, name=qqq2, dept=oneToMany.Dept@cc0e21a]
1.3.2、支持投影查询,即仅检索出对象的部分属性
也就是不需要将表中所有的字段度查询出来,只查询出对象的部分属性,这就是投影查询
1.3.2.1、什么度不使用,直接查询,得到的结果就是将查到的属性全放到list集合中。这只使用于检索对象的一个属性,如果多个属性,就得需要用别的方式进行封装
1 String hql = "select name from Staff"; 2 Query hqlQuery = session.createQuery(hql); 3 List list = hqlQuery.list(); //集合中存放的是String,也就是name属性值。 4 System.out.println(list); 5 6 //结果 7 Hibernate: 8 select 9 staff0_.name as col_0_0_ 10 from 11 staff staff0_ 12 [qqq1, qqq2, qqq3, qqq4, qqq5, qqq6, qqq7, qqq8, qqq9]
1.3.2.2、使用new List()或者new Map()或new Staff()将返回的值给封装起来
使用new Staff()
1 //使用new Staff(id,name)的前提是Staff的实体类中id和name这个构造器。反则报错 2 String hql = "select new Staff(id,name) from Staff"; 3 Query hqlQuery = session.createQuery(hql); 4 List<Staff> list = hqlQuery.list(); //集合中存放的是Staff数组。。 5 System.out.println(list); 6 //结果 7 Hibernate: 8 select 9 staff0_.id as col_0_0_, 10 staff0_.name as col_1_0_ 11 from 12 staff staff0_ 13 [Staff [id=2, name=qqq1, dept=null], Staff [id=3, name=qqq2, dept=null], Staff [id=4, name=qqq3, dept=null], Staff [id=5, name=qqq4, dept=null], 14 Staff [id=6, name=qqq5, dept=null], Staff [id=7, name=qqq6, dept=null], Staff [id=8, name=qqq7, dept=null], Staff [id=9, name=qqq8, dept=null], 15 Staff [id=10, name=qqq9, dept=null]]
使用new List()
1 //将查询到的结果存放在list集合中,形式如 List[数组1,数组2...] 数组1[id,name] 2 String hql = "select new List(id,name) from Staff"; 3 Query hqlQuery = session.createQuery(hql); 4 List list = hqlQuery.list(); //集合中存放的是id,name数组。。 5 System.out.println(list); 6 7 //结果 8 Hibernate: 9 select 10 staff0_.id as col_0_0_, 11 staff0_.name as col_1_0_ 12 from 13 staff staff0_ 14 [[2, qqq1], [3, qqq2], [4, qqq3], [5, qqq4], [6, qqq5], 15 [7, qqq6], [8, qqq7], [9, qqq8], [10, qqq9]]
使用new Map()
//将查询到的结果用map封装,然后放到list集合中, String hql = "select new Map(id,name) from Staff"; Query hqlQuery = session.createQuery(hql); List list = hqlQuery.list(); //集合中存放的是id,name数组。。 System.out.println(list); //结果 Hibernate: select staff0_.id as col_0_0_, staff0_.name as col_1_0_ from staff staff0_ [{1=qqq1, 0=2}, {1=qqq2, 0=3}, {1=qqq3, 0=4}, {1=qqq4, 0=5}, {1=qqq5, 0=6}, {1=qqq6, 0=7}, {1=qqq7, 0=8}, {1=qqq8, 0=9}, {1=qqq9, 0=10}]
1.3.3、支持分页查询
使用setFirst()和setMaxResult()分别设置起始索引和拿去数据的总数。跟limit m,n 是一样的
String hql = "from Staff"; Query hqlQuery = session.createQuery(hql); //从数据库表中取出第三条到第六条记录来。相当于mysql的limit 2,3; hqlQuery.setFirstResult(2); hqlQuery.setMaxResults(3); List<Staff> list = hqlQuery.list(); //集合中存放的是id,name数组。。 for(Staff staff : list){ System.out.println(staff.toString()); } //结果 Hibernate: select staff0_.id as id1_, staff0_.name as name1_, staff0_.deptId as deptId1_ from staff staff0_ limit ?, ? Hibernate: select dept0_.id as id0_0_, dept0_.name as name0_0_ from dept dept0_ where dept0_.id=? //由于数据库表中没有id=1的数据,所以拿到的记录是从id=4开始。也就是从第三条到第六条 Staff [id=4, name=qqq3, dept=oneToMany.Dept@2bf11e9f] Staff [id=5, name=qqq4, dept=oneToMany.Dept@2bf11e9f] Staff [id=6, name=qqq5, dept=oneToMany.Dept@2bf11e9f]
1.3.4、支持连接查询
支持7种连接写法。
1.3.4.1、内连接 inner join 可以省略inner,直接join
1 //注意,hql操作的是POJO,而不是表中字段,所以s.dept这里不能写成Dept或者dept, 2 //不用写ON后面的连接条件,因为hibernate映射文件我们已经全部写好了。 3 String hql = "from Dept d inner join d.staffSet"; 4 Query hqlQuery = session.createQuery(hql); 5 //这里的泛型不能是Staff了。结合了两张表,集合中存放的是Object[],数组中存放的是Staff和Dept实体 6 List<Object[]> list = hqlQuery.list(); //集合中存放的是id,name数组。。 7 Object[] o = list.get(0); 8 System.out.println(o); 9 //注意:其中Dept和Staff中都没有对方实体的引用。因为这个是左外连接,生成了新的表。 10 System.out.println(((Dept)o[0]).getName());//获得Dept实体的name 11 System.out.println(((Staff)o[1]).getName());//或者Staff的name 12 13 //结果 14 //左外连接的语句,并且为我们加上了ON之后的语句 15 Hibernate: 16 select 17 dept0_.id as id0_0_, 18 staffset1_.id as id1_1_, 19 dept0_.name as name0_0_, 20 staffset1_.name as name1_1_, 21 staffset1_.deptId as deptId1_1_ 22 from 23 dept dept0_ 24 inner join 25 staff staffset1_ 26 on dept0_.id=staffset1_.deptId 27 //这个是list中第一个Object[] 不用看他的格式,只要知道他有代表着Dept和Staff实体 28 [Ljava.lang.Object;@44eef74f 29 1部门 30 qqq1
1.3.4.2、迫切内连接 inner join fetch
内连接返回的list中是Object[],而迫切内连接返回的list中是POJO类对象
1 //注意,hql操作的是POJO,而不是表中字段,所以s.dept这里不能写成Dept或者dept, 2 //不用写ON后面的连接条件,因为hibernate映射文件我们已经全部写好了。 3 String hql = "from Dept d inner join fetch d.staffSet"; 4 Query hqlQuery = session.createQuery(hql); 5 //使用的是迫切内连接,其list中放的就是Dept对象了,注意并没有包含staffSet。放的是from后面跟的POJO,如果是Staff。那么这里就放的Staff。 6 //所以自己重写了toString方法的人这里会报错, 7 List list = hqlQuery.list(); //集合中存放的是Dept。 8 System.out.println(list); 9 10 //结果 11 Hibernate: 12 select 13 dept0_.id as id0_0_, 14 staffset1_.id as id1_1_, 15 dept0_.name as name0_0_, 16 staffset1_.name as name1_1_, 17 staffset1_.deptId as deptId1_1_, 18 staffset1_.deptId as deptId0_0__, 19 staffset1_.id as id0__ 20 from 21 dept dept0_ 22 inner join 23 staff staffset1_ 24 on dept0_.id=staffset1_.deptId 25 //返回那么多相同的原因是内连接,Staff中有9条记录,则部门这边也会显示9条,所以这里重复了9次。可以是用DISTINCT关键字去除重复的记录 26 [Dept [id=2, name=1部门], Dept [id=2, name=1部门], Dept [id=2, name=1部门], Dept [id=2, name=1部门], Dept [id=2, name=1部门], Dept [id=2, name=1部门], Dept [id=2, name=1部门], Dept [id=2, name=1部门], Dept [id=2, name=1部门]]
要想得到不重复的记录,那么就将hql改为"select distinct d from Dept d inner join fetch d.staffSet";
1.3.4.3、隐式内连接 不写任何关键字,完成表连接
其实就是通过where连接两张表。很简单。
1 //隐式内连接,其实就是最普通的通过where来连接两张表,如何看了MySQL的表查询操作, 2 //这个应该很简单,但是这里只能通过多方找一方,因为一方存放的是集合,就不能向下面这样赋值 3 String hql = "from Staff s where s.dept.name = ?"; 4 Query hqlQuery = session.createQuery(hql); 5 hqlQuery.setParameter(0, "1部门"); 6 7 List list = hqlQuery.list(); //集合中存放的是Dept。 8 System.out.println(list); 9 //结果 10 Hibernate: 11 select 12 staff0_.id as id1_, 13 staff0_.name as name1_, 14 staff0_.deptId as deptId1_ 15 from 16 staff staff0_ cross 17 join 18 dept dept1_ 19 where 20 staff0_.deptId=dept1_.id 21 and dept1_.name=? 22 [Staff [id=2, name=qqq1], Staff [id=3, name=qqq2], Staff [id=4, name=qqq3], Staff [id=5, name=qqq4], Staff [id=6, name=qqq5], Staff [id=7, name=qqq6], Staff [id=8, name=qqq7], Staff [id=9, name=qqq8], Staff [id=10, name=qqq9]]
1.3.4.4、左外连接,left outer join,可以省略outer,直接left join
1 //左外连接,自己脑袋里想一下在左外连接的时候,表会是什么样子。通过前面看到的内连接 2 //和迫切内连接就应该知道这里左外连接list中存放的是什么,就是Object[] 3 String hql = "from Staff s left outer join s.dept"; 4 Query hqlQuery = session.createQuery(hql); 5 6 List<Object[]> list = hqlQuery.list(); 7 Object[] object = list.get(0); 8 System.out.println(((Staff)object[0]).getName()); 9 System.out.println(((Dept)object[1]).getName()); 10 11 //结果 12 Hibernate: 13 select 14 staff0_.id as id1_0_, 15 dept1_.id as id0_1_, 16 staff0_.name as name1_0_, 17 staff0_.deptId as deptId1_0_, 18 dept1_.name as name0_1_ 19 from 20 staff staff0_ 21 left outer join 22 dept dept1_ 23 on staff0_.deptId=dept1_.id 24 qqq1 25 1部门
1.3.4.5、迫切左外连接, left outer join fetch
一样的区别,就是list中存放的是POJO对象了
1 //迫切左外连接,就是list中存放的是POJO对象。在这里存放的是Staff。 2 String hql = "from Staff s left outer join fetch s.dept"; 3 Query hqlQuery = session.createQuery(hql); 4 5 List list = hqlQuery.list(); 6 System.out.println(list); 7 8 //结果 9 Hibernate: 10 select 11 staff0_.id as id1_0_, 12 dept1_.id as id0_1_, 13 staff0_.name as name1_0_, 14 staff0_.deptId as deptId1_0_, 15 dept1_.name as name0_1_ 16 from 17 staff staff0_ 18 left outer join 19 dept dept1_ 20 on staff0_.deptId=dept1_.id 21 [Staff [id=2, name=qqq1], Staff [id=3, name=qqq2], Staff [id=4, name=qqq3], Staff [id=5, name=qqq4], Staff [id=6, name=qqq5], 22 Staff [id=7, name=qqq6], Staff [id=8, name=qqq7], Staff [id=9, name=qqq8], Staff [id=10, name=qqq9]]
1.3.4.6、右外连接:right outer join
知道左外连接,右外连接也就会了。
1 //右外连接,就是list中存放的是Object[] 2 String hql = "from Staff s right outer join s.dept"; 3 Query hqlQuery = session.createQuery(hql); 4 5 List<Object[]> list = hqlQuery.list(); 6 System.out.println(list); 7 8 //结果 9 Hibernate: 10 select 11 staff0_.id as id1_0_, 12 dept1_.id as id0_1_, 13 staff0_.name as name1_0_, 14 staff0_.deptId as deptId1_0_, 15 dept1_.name as name0_1_ 16 from 17 staff staff0_ 18 right outer join 19 dept dept1_ 20 on staff0_.deptId=dept1_.id 21 [[Ljava.lang.Object;@11e04129, [Ljava.lang.Object;@19d5f3ea, [Ljava.lang.Object;@2d8094e6, [Ljava.lang.Object;@54af9f60, [Ljava.lang.Object;@5608830f, [Ljava.lang.Object;@48d479e9, [Ljava.lang.Object;@758fd559, [Ljava.lang.Object;@3600025b, [Ljava.lang.Object;@3a9ac00f]
1.3.4.7、交叉连接,会产生笛卡尔积。
什么是笛卡尔积?将两张表连接起来,比如一张表中有3条记录,另一张表中也有3条记录,那么连接之后,就会出现9条数据,其中就有一些重复的数据,拿实例说话,班级和学生,有三个学生A,B,C,有两个班级E,F,连接起来后,就会出现笛卡尔积,6条数据,其中会出现这样的数据,A,E 、A,F、B,E、B,F、C,E、C,F, A,B,C就重复出现了,即在E班级,又在F班级,这样就不合理。这就是所说的笛卡尔积。
由于dept中就一条记录,无法展示出笛卡尔积,所以手动增加一条dept的记录。然后在进行交叉连接。就会出现笛卡尔积,
1 //直接将两张表简单相连,出现笛卡尔积,因为从结果中可以看到,list集合中有18个数组,说明有18条记录 2 String hql = "from Staff,Dept"; 3 Query hqlQuery = session.createQuery(hql); 4 5 List list = hqlQuery.list(); 6 System.out.println(list); 7 8 //结果 9 Hibernate: 10 select 11 staff0_.id as id1_0_, 12 dept1_.id as id0_1_, 13 staff0_.name as name1_0_, 14 staff0_.deptId as deptId1_0_, 15 dept1_.name as name0_1_ 16 from 17 staff staff0_ cross 18 join 19 dept dept1_ 20 //18个数组 21 [[Ljava.lang.Object;@42064d82, [Ljava.lang.Object;@2bcab3ab, [Ljava.lang.Object;@8d9b603, [Ljava.lang.Object;@d3c837f, [Ljava.lang.Object;@7fdd0da2, [Ljava.lang.Object;@9aa4843, [Ljava.lang.Object;@a6e2baa, [Ljava.lang.Object;@46f4ab3f, [Ljava.lang.Object;@6916d97d, [Ljava.lang.Object;@5b20d371, [Ljava.lang.Object;@4819ce74, [Ljava.lang.Object;@164146a7, [Ljava.lang.Object;@1785895b, [Ljava.lang.Object;@3ffcc16d, [Ljava.lang.Object;@6afefbec, [Ljava.lang.Object;@a4d79d5, [Ljava.lang.Object;@6479943b, [Ljava.lang.Object;@69f2e105]
注意:上面的连接中很多是使用一个引用就代表了相对应的表,比如" from Dept d inner join d.staffSet " d.staffSet就好像代表了Staff的这张表,实际上就是代表了Staff这张表,这样理解,from Dept 就从Dept表中找出了所有记录,就打比方,找到了Dept表中的2部门,在2部门中有多少staff呢,可以全部找出来,在我们所说的环境下,正好就staff就全部在该部门中,那么就找到了Staff表中的所有staff,也就是相当于是Staff这张表了,就算2部门没有包括所有的staff,那么还有其他部门,肯定包括了剩下的staff,也就是说,不管怎么样,度能把staff全部找到,所以d.staffSet就相当于Staff表了。以此类推,其他hql语句中的这里也是这样理解的。
1.3.5、支持分组查询,允许使用HAVING 和 GROUP BY 关键字
1 //s.dept.id 就相当于操作Staff表中的deptId。看发送的sql语句就能知道。 2 //原因是Staff这个类中并没有deptId表字段属性,但是有dept的引用变量,其dept的id 3 //也就是Staff中的deptId值,只是中间转换了一步,也不是很难理解。 4 String hql = "from Staff s group by s.dept.id"; 5 Query hqlQuery = session.createQuery(hql); 6 List list = hqlQuery.list(); 7 System.out.println(list); 8 9 //结果 10 Hibernate: 11 select 12 staff0_.id as id1_, 13 staff0_.name as name1_, 14 staff0_.deptId as deptId1_ 15 from 16 staff staff0_ 17 group by 18 staff0_.deptId 19 //分组后显示的就是第一个值。由于数据问题,9个staff度是在一个部门,所以通过部门分组,就只能得到一个分组。 20 [Staff [id=2, name=qqq1]]
1.3.6、提供内置聚集函数,如SUM(),MIN(),MAX()等
这个例子中不好使用这几个函数。。。所以这里不演示了,很简单。hql和sql差不太多。
1.3.7、能够调用用户定义的SQL函数或标准的SQL函数
这个跟上面的一样,SQL中函数有很多。也就是说hql能够使用sql中的函数
1.3.8、支持子查询
1 //子查询操作,实际意义:Staff表中的staff所在的部门编号,跟Dept中所有的部门编号有对应的,就将其staff取出。 2 String hql = "from Staff s where s.dept.id IN (select id from Dept)"; 3 Query hqlQuery = session.createQuery(hql); 4 List list = hqlQuery.list(); 5 System.out.println(list); 6 //结果 7 Hibernate: 8 select 9 staff0_.id as id1_, 10 staff0_.name as name1_, 11 staff0_.deptId as deptId1_ 12 from 13 staff staff0_ 14 where 15 staff0_.deptId in ( 16 select 17 dept1_.id 18 from 19 dept dept1_ 20 ) 21 [Staff [id=2, name=qqq1], Staff [id=3, name=qqq2], Staff [id=4, name=qqq3], Staff [id=5, name=qqq4], Staff [id=6, name=qqq5], Staff [id=7, name=qqq6], Staff [id=8, name=qqq7], Staff [id=9, name=qqq8], Staff [id=10, name=qqq9]]
Hibernate学习———— 二级缓存和事务级别详讲