纳尼???我JVM优化过头了,直接把异常信息优化没了?怎么办
Posted Java架构没有996
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了纳尼???我JVM优化过头了,直接把异常信息优化没了?怎么办相关的知识,希望对你有一定的参考价值。
你好呀,我是why。
你猜这次我又要写个啥没有卵用的知识点呢?

不好意思,问的稍微有点早了,啥提示都没给,咋猜呢,对吧?
先给你上个代码:
public class ExceptionTest
public static void main(String[] args)
String msg = null;
for (int i = 0; i < 500000; i++)
try
msg.toString();
catch (Exception e)
e.printStackTrace();
来,就这代码,你猜猜写出个什么花儿来?
当然了,有猜到的朋友,也有没猜到的朋友。
很好,那么请猜出来了的同学迅速拉到文末,完成一键三连的任务后,就可以出去了。
没有猜出来的同学,我把代码一跑起来,你就知道我要说啥了:
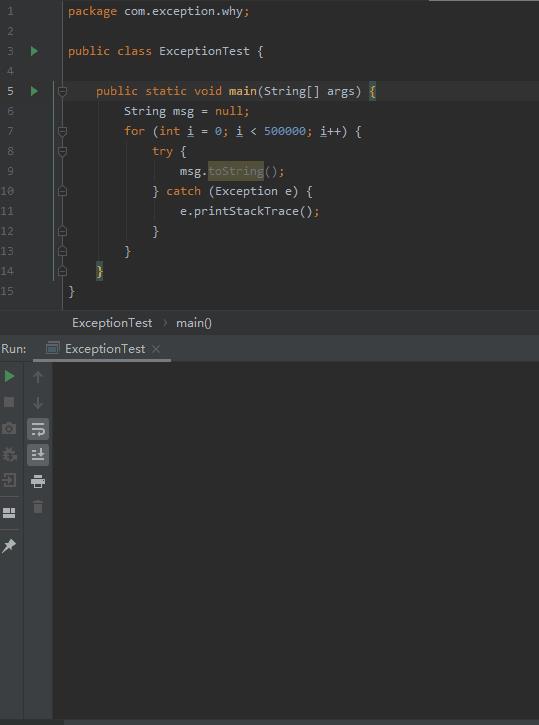
一瞬间的事儿,瞅见了吗?神奇吗?产生疑问了吗?

没关系,你要没看清楚,我还能给你截个图:
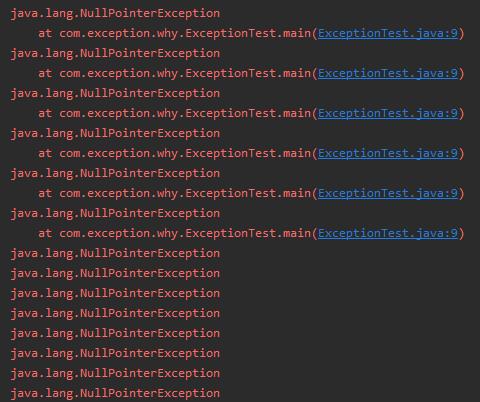
在抛出一定次数的空指针异常后,异常堆栈没了。
这就是我标题说的:太扯了吧?异常信息突然就没了。

你说为啥?
为啥?
这事就得从 2004 年讲起了。
那一年,SUN 公司于 9 月 30 日 18 点发布了 JDK 5。
在其 release-notes 中有这样一段话:
https://www.oracle.com/java/technologies/javase/release-notes-introduction.html
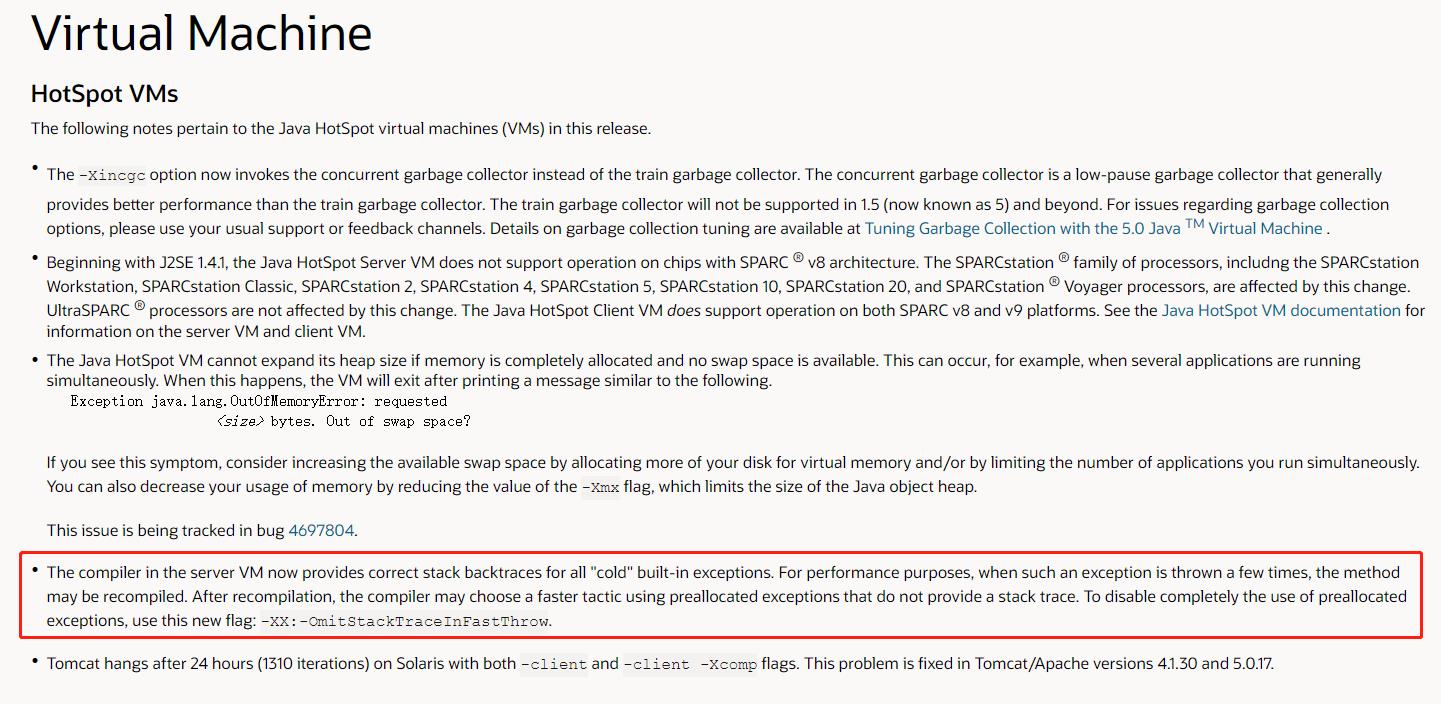
主要是框起来的这句话,看不明白没关系,我用我八级半的英语给你翻译一下。
我们一句句的来:
The compiler in the server VM now provides correct stack backtraces for all “cold” built-in exceptions.
对于所有的内置异常,编译器都可以提供正确的异常堆栈的回溯。
For performance purposes, when such an exception is thrown a few times, the method may be recompiled.
出于性能的考虑,当一个异常被抛出若干次后,该方法可能会被重新编译。(重要)
After recompilation, the compiler may choose a faster tactic using preallocated exceptions that do not provide a stack trace.
在重新编译之后,编译器可能会选择一种更快的策略,即不提供异常堆栈跟踪的预分配异常。(重要)
To disable completely the use of preallocated exceptions, use this new flag: -XX:-OmitStackTraceInFastThrow.
如果要禁止使用预分配的异常,请使用这个新参数:-XX:-OmitStackTraceInFastThrow。
这几句话先不管理解没有。但是至少知道它这里描述的场景不就是刚刚代码演示的场景吗?
它最后提到了一个参数 -XX:-OmitStackTraceInFastThrow,二话不说,先拿来用了,看看效果再说:
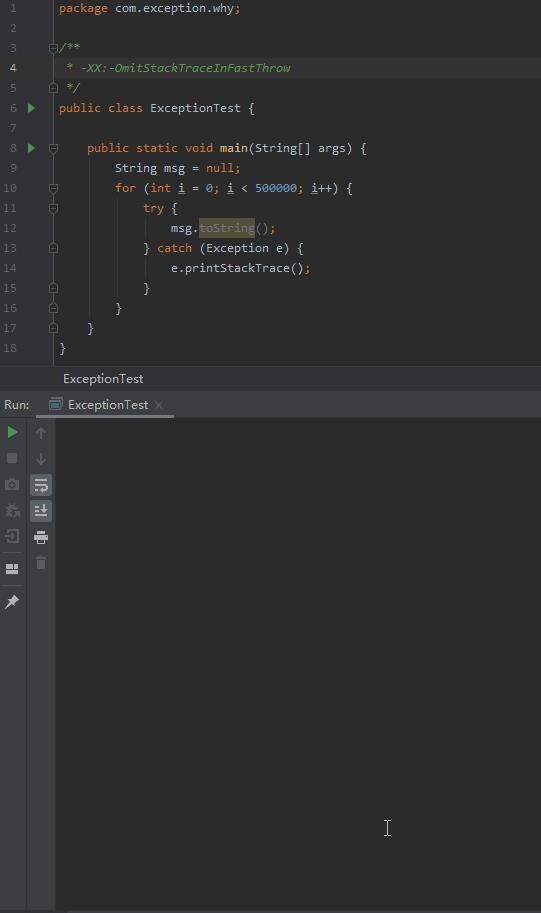
同样的代码,加入该启动参数后,异常堆栈确实会从头到尾一直打印。
不知道你感觉到没有,加入该启动参数后,程序运行时间明显慢了很多。
在我的机器上没加该参数,程序运行时间是 2826 ms,加上该参数运行时间是 5885 ms。
说明确实是有提升性能的功能。
到底是咋提升的,下一节说。
先说个其他的。
这里都提到 JVM 参数了,我顺便再分享一个网站:
https://club.perfma.com/topic/OmitStackTraceInFastThrow
该网站提供了很多功能,这是其中的几个功能:

JVM 参数查询功能那必须得有:
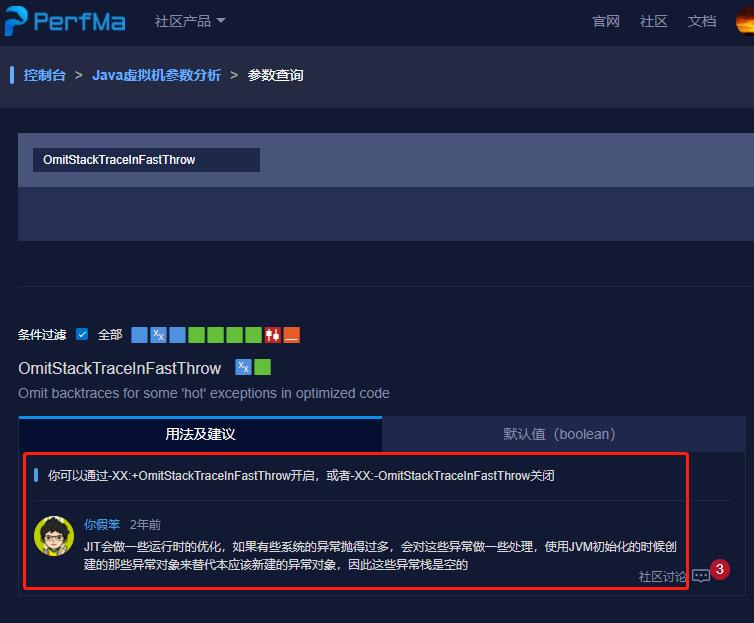
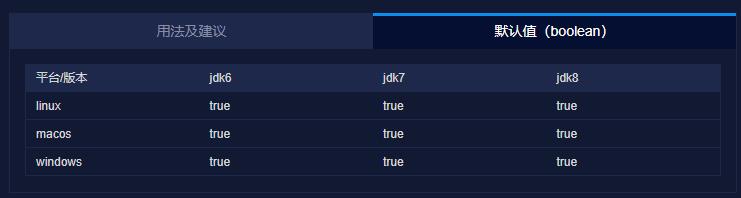
很好用的,你以后遇到不知道是干啥用的 JVM 参数,可以在这个网站上查询一下。
到底为啥?
前面讲了是出于性能原因,从 JDK 5 开始会出现异常堆栈丢失的现象。
那么性能问题到底在哪?
来,我们一起看一下最常见的空指针异常。
以本文为例,看一下异常抛出的时候调用路径:
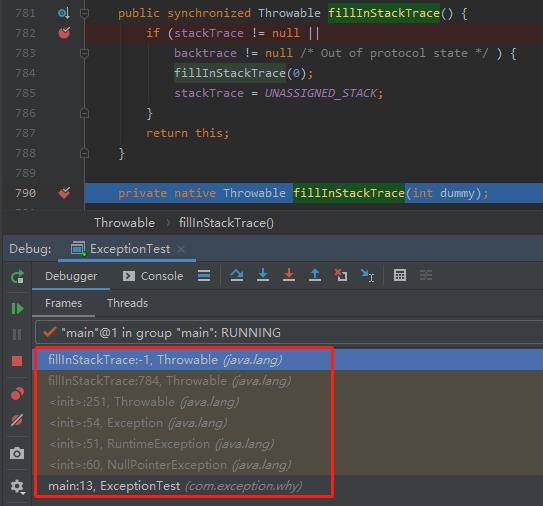
最终会走到这个 native 方法:
java.lang.Throwable#fillInStackTrace(int)
fill In Stack Trace,顾名思义,填入堆栈跟踪。
这个方法会去爬堆栈,而这个过程就是一个相对比较消耗性能的过程。
为啥比较耗时呢?
给你看个比较直观的:
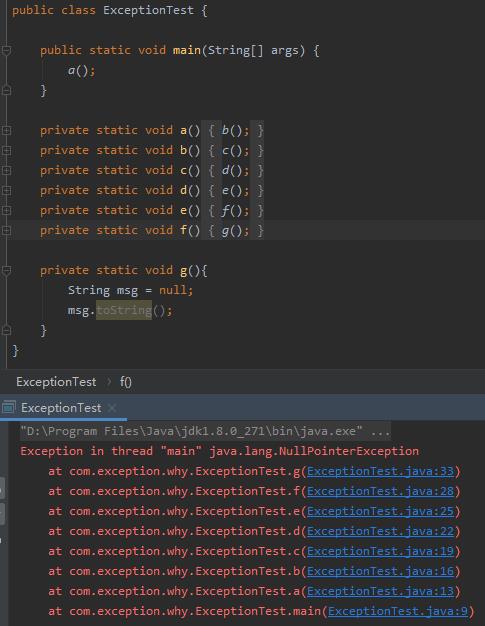
这类的异常堆栈才是我们比较常见的,这么长的堆栈信息,可不消耗性能吗。
现在,我们现在再回去看这句话:
For performance purposes, when such an exception is thrown a few times, the method may be recompiled. After recompilation, the compiler may choose a faster tactic using preallocated exceptions that do not provide a stack trace.
出于性能的考虑,当一个异常被抛出若干次后,该方法可能会被重新编译。在重新编译之后,编译器可能会选择一种更快的策略,即不提供异常堆栈跟踪的预分配异常。
所以,你能明白,这个“出于性能的考虑”这句话,具体指的就是节约 fillInStackTrace(爬堆栈)的这个性能消耗。
更加深入一点的研究对比,你可以看看这个链接:
http://java-performance.info/throwing-an-exception-in-java-is-very-slow

我这里贴一下结论:

关于消除异常的性能消耗,他提出了三个解决方案:
重构你的代码不使用它们。
缓存异常实例。
重写 fillInStackTrace 方法。
通过小日…小日子过的还不错的日本的站点,输入关键信息后,知乎的这个链接排在第二个:
https://www.zhihu.com/question/21405047

这个问题下面,有一个R大的回答,粘贴给你看看:
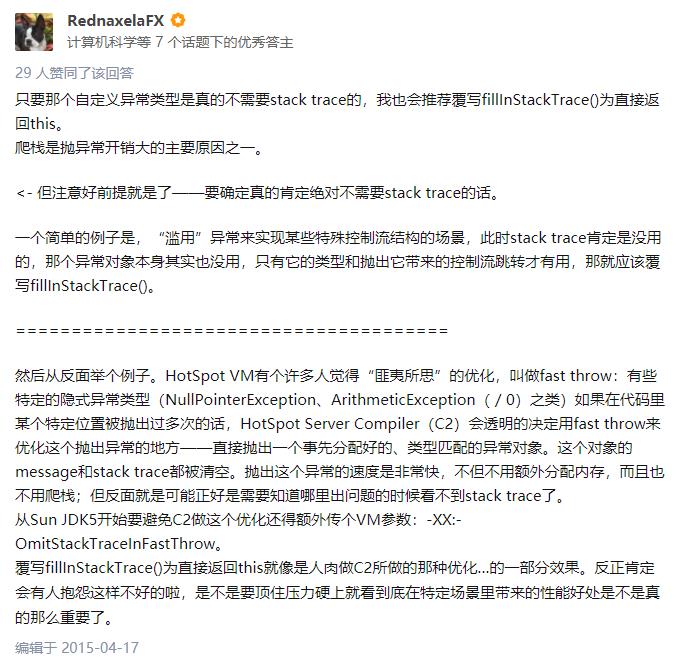
大家都不约而同的提到了重写 fillInStackTrace 方法,这个性能优化小技巧,也就是我们可以这样去自定义异常:
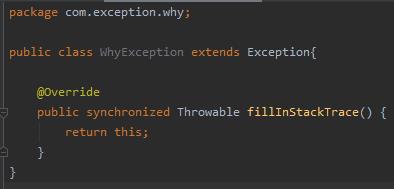
用一个不严谨的方式测试一下,你就看这个意思就行:
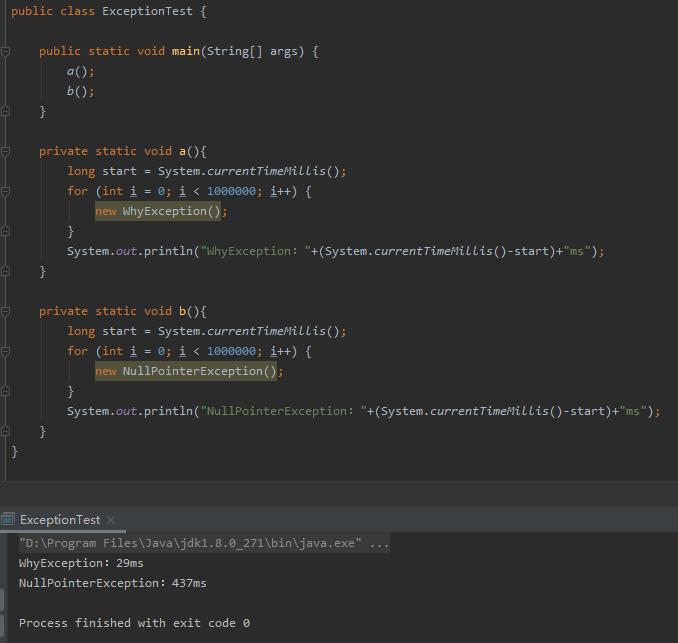
重写了 fillInStackTrace 方法,直接返回 this 的对象,比调用了爬栈方法的原始方法,快了不是一星半点儿。
其实除了重写 fillInStackTrace 方法之外,JDK 7 之后还提供了这样的一个方法:
java.lang.Throwable#Throwable(java.lang.String, java.lang.Throwable, boolean, boolean)
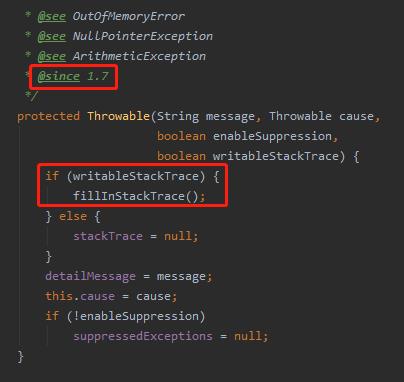
可以通过 writableStackTrace 入参来控制是否需要去爬栈。
那么到底什么时候才应该去用这样的一个性能优化手段呢?
其实R大的回答里面说的很清楚了:

其实我们写业务代码的,异常信息打印还是非常有必要的。
但是对于一些追求性能的框架,就可以利用这个优势。
比如我在 disruptor 和 kafka 的源码里面都找到了这样的优化落地源码。
先看 disruptor 的:
com.lmax.disruptor.AlertException
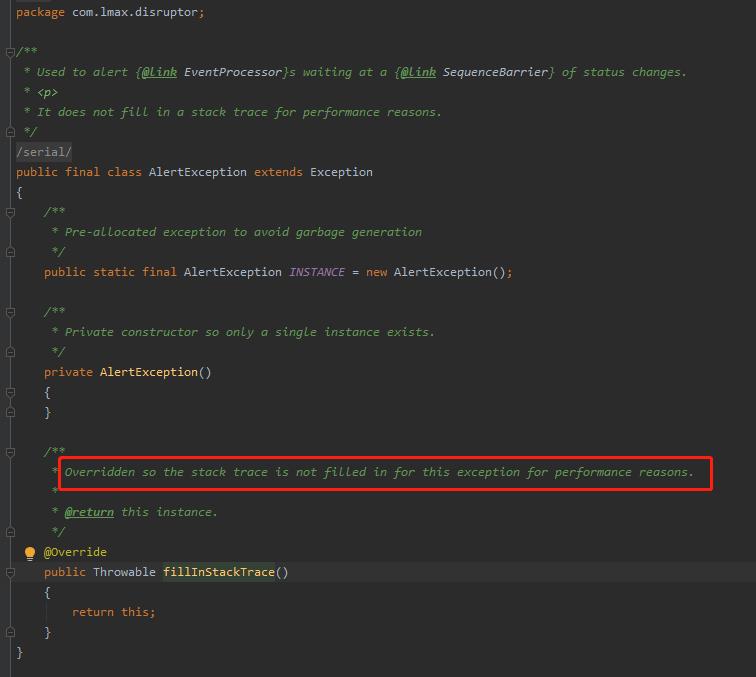
- Overridden so the stack trace is not filled in for this exception for performance reasons.
- 由于性能的原因,重载后的堆栈跟踪不会被填入这个异常。
再看 kafka 的:
org.apache.kafka.common.errors.ApiException
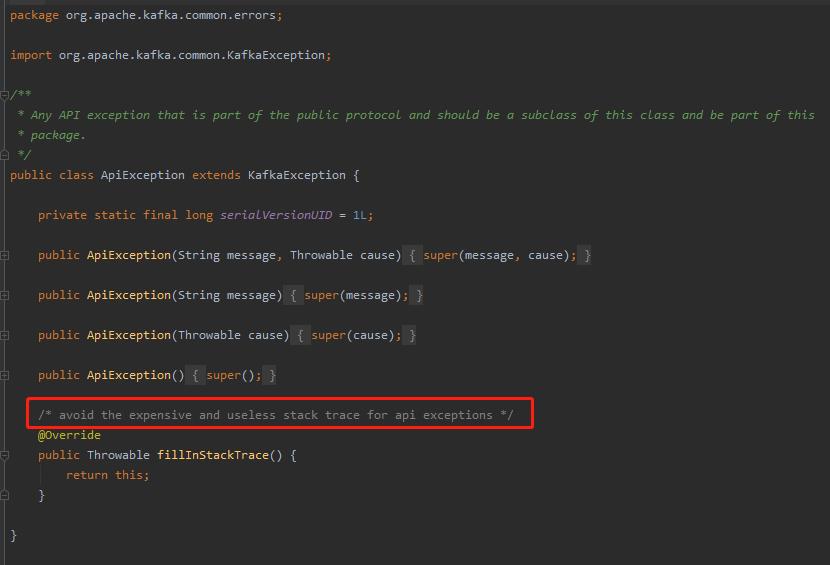
- avoid the expensive and useless stack trace for api exceptions
- 避免对api异常进行昂贵而无用的堆栈跟踪
而且你注意到了吗,上面着两个框架中,直接把 synchronized 都干掉了。如果你也打算重写,那么也可以分析一下你的场景中是否可以去掉 synchronized,性能又可以来一点提升。
另外,R大的回答里面还提到了这个优化是 C2 的优化。
我们可以简单的证明一下。
分层编译
前面提到的 C2,其实还有一个对应的 C1。这里说的 C1、C2 都是即时编译器。
你要是不熟悉 C1、C2,那我换个说法。
C1 其实就是 Client Compiler,即客户端编译器,特点是编译时间较短但输出代码优化程度较低。
C2 其实就是 Server Compiler,即服务端编译器,特点是编译耗时长但输出代码优化质量也更高。
大家常常提到的 JVM 帮我们做的很多“激进”的为了提升性能的优化,比如内联、快慢速路径分析、窥孔优化,包括本文说的“不显示异常堆栈”,都是 C2 搞的事情。
多说一句,在 JDK 10 的时候呢,又推出了 Graal 编译器,其目的是为了替代 C2。
至于为什么要替换 C2,额,原因之一是这样的…
http://icyfenix.cn/tricks/2020/graalvm/graal-compiler.html
C2 的历史已经非常长了,可以追溯到 Cliff Click 大神读博士期间的作品,这个由 C++ 写成的编译器尽管目前依然效果拔群,但已经复杂到连 Cliff Click 本人都不愿意继续维护的程度。
你看前面我说的 C1、C1 的特点,刚好是互补的。
所以为了在程序启动、响应速度和程序运行效率之间找到一个平衡点,在 JDK 6 之后,JVM 又支持了一种叫做分层编译的模式。
也是为什么大家会说:“Java 代码运行起来会越来越快、Java 代码需要预热”的根本原因和理论支撑。
在这里,我引用《深入理解Java虚拟机HotSpot》一书中 7.2.1 小节[分层编译]的内容,让大家简单了解一下这是个啥玩意。
首先,我们可以使用 -XX:+TieredCompilation 开启分层编译,它额外引入了四个编译层级。
- 第 0 级:解释执行。
- 第 1 级:C1 编译,开启所有优化(不带 Profiling)。Profiling 即剖析。
- 第 2 级:C1 编译,带调用计数和回边计数的 Profiling 信息(受限 Profiling).
- 第 3 级:C1 编译,带所有Profiling信息(完全Profiling).
- 第 4 级:C2 编译。
常见的分层编译层级转换路径如下图所示:
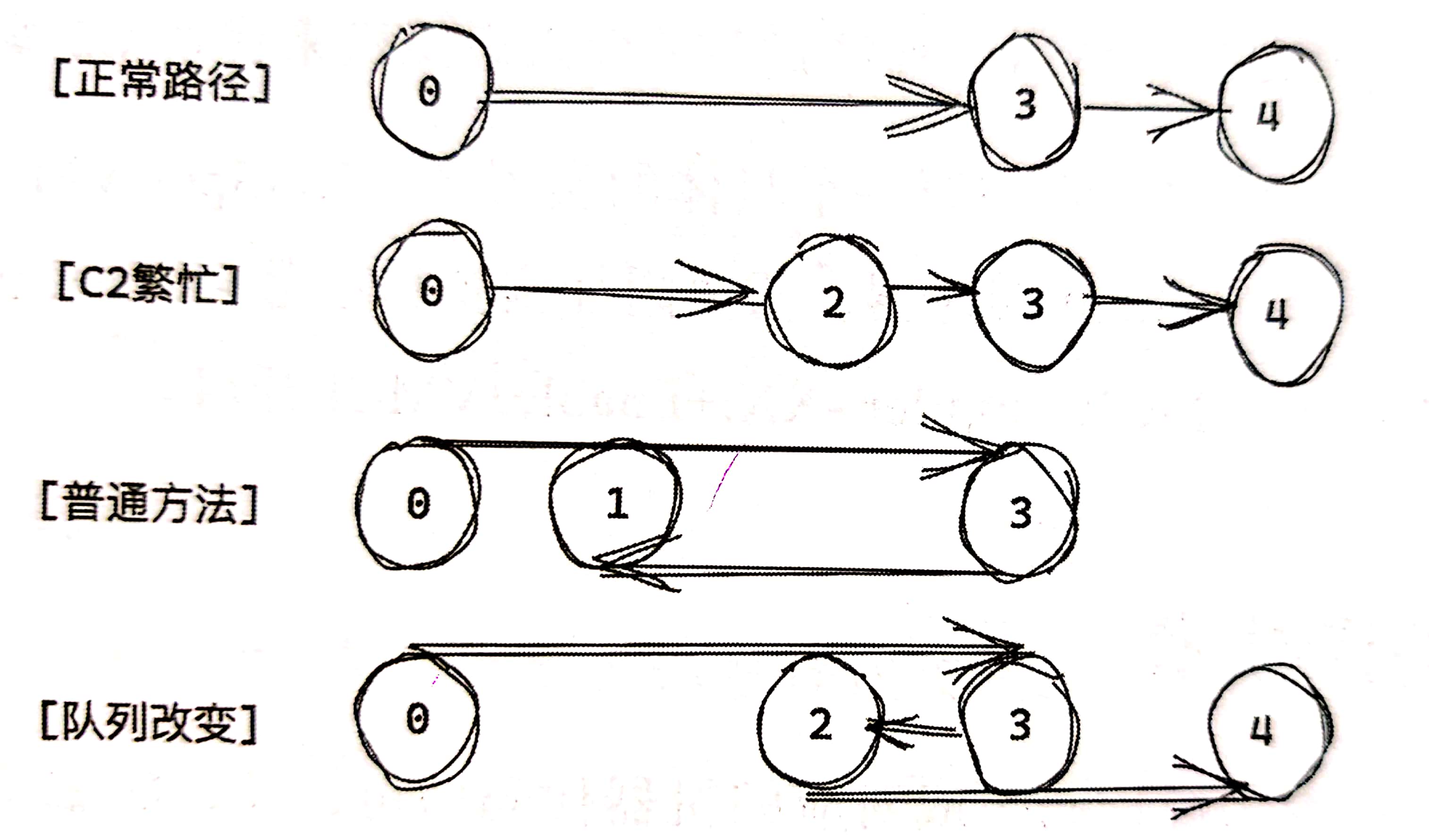
- 0→3→4:常见层级转换。用 C1 完全编译,如果后续方法执行足够频繁再转入 4 级。
- 0→2→3→4:C2 编译器繁忙。先以 2 级快速编译,等收集到足够的 Profiling 信息后再转为3级,最终当 C2 不再繁忙时再转到 4 级。
- 0→3→1/0→2→1:2/3级编译后因为方法不太重要转为 1 级。如果 C2 无法编译也会转到 1 级。
- 0→(3→2)→4:C1 编译器繁忙,编译任务既可以等待 C1 也可以快速转到 2 级,然后由 2 级转向 4 级。
如果你之前不知道分层编译这回事,没关系,现在有这样的一个概念就行了。面试不会考的,放心。
接下来,就要提到一个参数了:
-XX:TieredStopAtLevel=___

看名字你也知道了,这个参数的作用是让分层编译停在某一层,默认值为 4,也就是到 C2 编译。
那我把该值修改为 3,岂不是就只能用 C1 了,那就不能利用 C2 帮我优化异常啦?
实验一波:
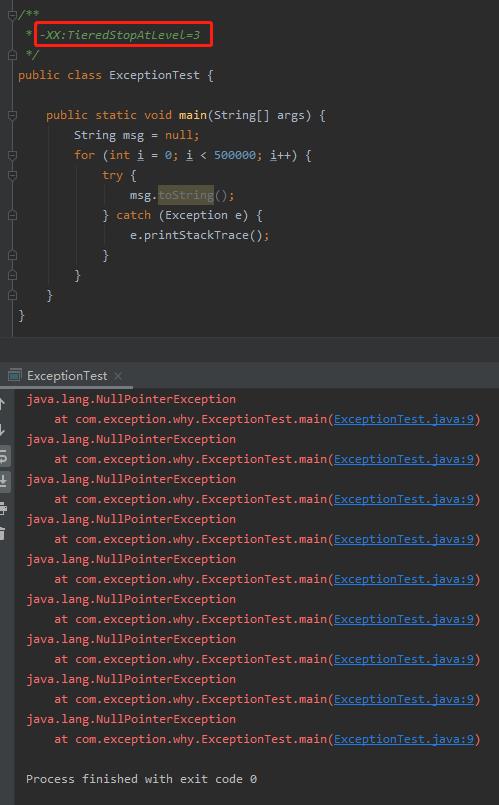
果然如此,R大诚不欺我。

以上是关于纳尼???我JVM优化过头了,直接把异常信息优化没了?怎么办的主要内容,如果未能解决你的问题,请参考以下文章
纳尼???我JVM优化过头了,直接把异常信息优化没了?怎么办