JAVA集合框架 - Map接口
Posted zuojing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JAVA集合框架 - Map接口相关的知识,希望对你有一定的参考价值。
Map
接口大致说明(jdk11):
整体介绍:
一个将键映射到值的(key-value)对象, 键值(key)不能重复, 每个键值只能影射一个对象(一一对应).
这个接口取代了Dictionary类,后者是一个完全抽象的类,而不是一个接口。
Map接口提供了三个集合视图(Set<K> keySet(); Collection<V> values();, Set<Map.Entry<K, V>> entrySet();),允许将Map的内容视为一组键、一组值或一组键-值映射。映射的顺序被定义为映射集合视图上的迭代器返回元素的顺序。一些映射实现,比如TreeMap类,对它们的顺序做出了特定的保证;其他类,比如HashMap,则不需要。
注意: 如果使用可变对象作为映射键,必须非常小心。这种情况下equals和hashCode方法会很难定义...最好别用.
所有通用映射实现类都应该提供两个“标准”构造函数:一个是void(无参数)构造函数,它创建一个空映射;另一个是带有一个类型为map的参数的构造函数,它创建一个具有与它的参数相同的键-值映射的新映射。实际上,后一个构造函数允许用户复制任何映射,生成所需类的等效映射。虽然没有办法强制执行这一规范(因为接口不能包含构造函数),但是JDK中的所有通用映射实现都遵循这一规范。
此接口中包含的“破坏性”方法,即修改它们所操作的映射的方法,被指定为在该映射不支持操作时抛出UnsupportedOperationException。如果调用对映射没有影响,这些方法可能(但不是必需的)抛出UnsupportedOperationException。例如,在不可修改的映射上调用putAll(Map)方法,如果要“叠加”的映射为空的映射可能(但不是必需的)抛出异常。
有些map实现对它们可能包含的键和值有限制。例如,有些实现禁止空键和值,而有些则限制其键的类型。试图插入不合格的键或值会抛出未检查的异常,通常是NullPointerException或ClassCastException。试图查询是否存在不合格的键或值可能会抛出异常,或者它可能仅仅返回false;有些实现会显示前一种行为,有些则会显示后一种行为。更普遍的情况是,尝试对不符合条件的键或值执行操作,如果完成操作不会导致在映射中插入不符合条件的元素,则可能会抛出异常或成功,具体取决于实现的选项。这种异常在该接口的规范中被标记为“可选”。
集合框架接口中的许多方法都是根据equals方法定义的。
例如,containsKey(对象键)方法的规范说:“当且仅当这个映射包含一个键k的映射,这样(key==null ?k = = null: key.equals (k))。”此规范不应被解释为暗示调用映射。包含一个非空参数key的containsKey会导致key.equals(k)被任何key k调用。实现可以自由地实现优化,从而避免调用equals.
例如,首先比较两个key的哈希码。(Object.hashCode()规范保证两个哈希码不相等的对象不能相等。)更普遍的是,在实现者认为合适的地方,各种集合框架接口的实现可以自由地利用底层对象方法的指定行为。
不可变的Map:
Map.of, Map.ofEntries, Map.copyOf静态工厂方法提供了一种创建不可修改映射的方便方法。这些方法创建的映射实例具有以下特征:
- 他们是无法改变的。不能添加、删除或更新键和值。调用映射上的任何mutator方法总是会导致抛出UnsupportedOperationException。但是,如果包含的键或值本身是可变的,这可能会导致映射的行为不一致或其内容似乎发生了变化。
- 它们不允许空键和值。尝试使用空键或值创建它们会导致NullPointerException。
- 如果所有键和值都是可序列化的,则它们是可序列化的。
- 它们在创建时拒绝重复的key。传递给静态工厂方法的重复键会导致IllegalArgumentException异常。
- 映射的迭代顺序是未指定的,并且可能会更改
- value值如果是对象的话,是不完全可靠的.有可能会发生变化.
- 它们被序列化为在序列化表单页面上指定的格式。
常用类继承结构
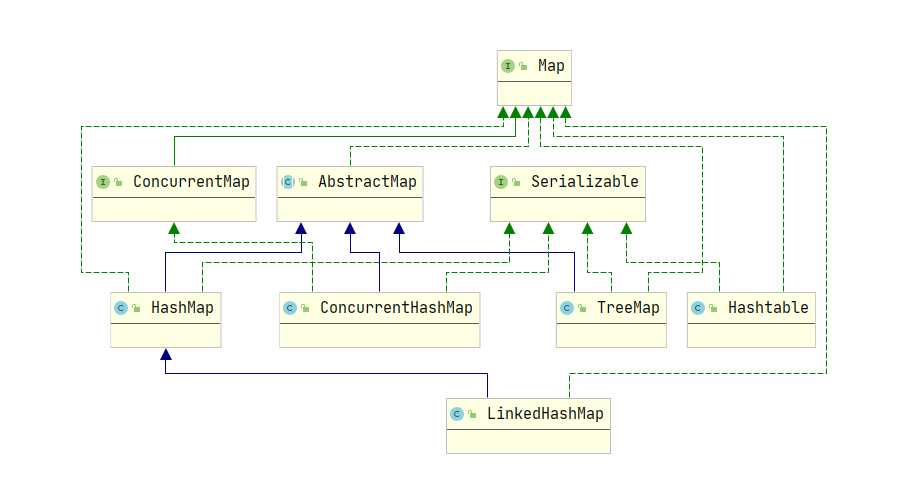
方法介绍
查询操作
/**
* 返回此映射中键-值映射的数目。如果映射包含超过整数。MAX_VALUE元素,返回整数。MAX_VALUE。
* @return 该映射中键-值映射的数量
*/
int size();
/**
* 判断是否为空
*/
boolean isEmpty();
/**
* 判断传入的键值在该map中是否存在.
* 等于 Objects.equals(key, k) (最多只能有一个这样的映射)
*/
boolean containsKey(Object key);
/**
* 如果此映射将一个或多个键映射到指定的值,则返回true。
* 更正式地说,当且仅当这个映射包含至少一个到值v的映射时,返回true。
* 对于大多数map接口的实现来说,这个操作可能需要映射大小的线性时间。(时间复杂度为O(n))
*/
boolean containsValue(Object value);
/**
* 返回指定键映射到的值,如果该映射不包含该键的映射,则返回null。
*/
V get(Object key);
修改操作
/**
* 将此映射中的指定值与指定键关联(可选操作)。
* 如果映射以前包含该键的映射,则旧值将被指定的值替换。
* (当且仅当m. containskey (k)返回true时,映射m被称为包含键k的映射。
*/
V put(K key, V value);
/**
* 如果密钥存在,则从该映射中删除该密钥的映射(可选操作)。
* 返回此映射以前与键关联的值,如果映射不包含该键的映射,则返回null。
* 如果该映射允许空值,那么null的返回值并不一定表明该映射不包含该键的映射;映射也可能显式地将键映射为null。
* 一旦调用返回,映射将不包含指定键的映射
*/
V remove(Object key);
批量处理
/**
* 将指定映射中的所有映射复制到此映射(可选操作)。
* 这个调用的效果相当于对指定映射中从键k到值v的每个映射在这个映射上调用一次put(k, v)。
* 如果在操作过程中修改了指定的映射,则此操作的行为未定义。
*/
void putAll(Map<? extends K, ? extends V> m);
/**
* 从该映射中删除所有映射(可选操作)。此调用返回后映射将为空。
*/
void clear();
视图
/**
* 返回此映射中包含的键的Set视图。
* 集合受到映射的支持,因此对映射的更改反映在集合中,反之亦然。
* 如果在对集合进行迭代时修改了映射(迭代器自己的删除操作除外),那么迭代的结果是未定义的。
* 这个集合支持元素删除,从Map中删除相应的映射,
* 通过remove、Set.remove、removeAll、retainAll和clear操作。
* 它不支持add或addAll操作。
*/
Set<K> keySet();
/**
* 返回此映射中包含的值的Collection视图。
* 映射支持集合,因此对映射的更改反映在集合中,反之亦然。
* 如果在对集合进行迭代时修改了映射(迭代器自己的删除操作除外),那么迭代的结果是未定义的。
* 集合支持元素删除,元素删除通过迭代器从映射中删除相应的映射,通过Iterator.remove, Set.remove, removeAll, retainAll和clear操作。
* 它不支持add或addAll操作。
*/
Collection<V> values();
/**
* 迭代的是map中的key-val映射实体(Entry), 其它的与上面俩差不多
*/
Set<Map.Entry<K, V>> entrySet();
比较和散列
/**
* 比较指定的对象与此映射是否相等。
* 如果给定的对象也是映射,并且这两个映射表示相同的映射,则返回true。
* 更正式地说,两个映射m1和m2表示相同的映射,如果m1. entryset ().equals(m2. entryset())。
* 这确保了equals方法在Map接口的不同实现之间正常工作。
*/
boolean equals(Object o);
/**
* 返回此映射的哈希码值。
* 映射的哈希码被定义为映射的entrySet()视图中每个条目的哈希码的和。
* 这确保了m1.equals(m2)意味着对于任意两个映射m1和m2, m1. hashcode ()==m2. hashcode(),这是Object.hashCode的一般契约所要求的。
*/
int hashCode();
缺省方法 (jdk1.8提供的)
/**
* 获取key对应的值, 如果没有就返回传入的默认值
*/
default V getOrDefault(Object key, V defaultValue) {
V v;
return (((v = get(key)) != null) || containsKey(key))
? v
: defaultValue;
}
/**
* foreach迭代
* 例子:
* for (Map.Entry<K, V> entry : map.entrySet())
* action.accept(entry.getKey(), entry.getValue());
* }
*/
default void forEach(BiConsumer<? super K, ? super V> action) {
Objects.requireNonNull(action);
for (Map.Entry<K, V> entry : entrySet()) {
K k;
V v;
try {
k = entry.getKey();
v = entry.getValue();
} catch (IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
action.accept(k, v);
}
}
/**
* 遍历过程中对值进行替换
* 例子:
* for (Map.Entry<K, V> entry : map.entrySet())
* entry.setValue(function.apply(entry.getKey(), entry.getValue()));
* }
*/
default void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {
Objects.requireNonNull(function);
for (Map.Entry<K, V> entry : entrySet()) {
K k;
V v;
try {
k = entry.getKey();
v = entry.getValue();
} catch (IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
// ise thrown from function is not a cme.
v = function.apply(k, v);
try {
entry.setValue(v);
} catch (IllegalStateException ise) {
// this usually means the entry is no longer in the map.
throw new ConcurrentModificationException(ise);
}
}
}
/**
* 如果指定的键尚未与值关联(或映射为null),则将其与给定值关联并返回null,否则返回当前值。
*/
default V putIfAbsent(K key, V value) {
V v = get(key);
if (v == null) {
v = put(key, value);
}
return v;
}
/**
* 仅当指定键项当前映射到指定值时才删除该项。
*/
default boolean remove(Object key, Object value) {
Object curValue = get(key);
if (!Objects.equals(curValue, value) ||
(curValue == null && !containsKey(key))) {
return false;
}
remove(key);
return true;
}
/**
* 只有在key对应的value值与传入的oldvalue相等时才替换并返回true, 否则返回false
*/
default boolean replace(K key, V oldValue, V newValue) {
Object curValue = get(key);
if (!Objects.equals(curValue, oldValue) ||
(curValue == null && !containsKey(key))) {
return false;
}
put(key, newValue);
return true;
}
/**
* 如果key/value键值对存在就替换
*/
default V replace(K key, V value) {
V curValue;
if (((curValue = get(key)) != null) || containsKey(key)) {
curValue = put(key, value);
}
return curValue;
}
// 用于流处理的
// 之后写流处理的时候再整理吧...
default V computeIfAbsent(K key,
Function<? super K, ? extends V> mappingFunction) {
Objects.requireNonNull(mappingFunction);
V v;
if ((v = get(key)) == null) {
V newValue;
if ((newValue = mappingFunction.apply(key)) != null) {
put(key, newValue);
return newValue;
}
}
return v;
}
default V computeIfPresent(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
V oldValue;
if ((oldValue = get(key)) != null) {
V newValue = remappingFunction.apply(key, oldValue);
if (newValue != null) {
put(key, newValue);
return newValue;
} else {
remove(key);
return null;
}
} else {
return null;
}
}
default V compute(K key,
BiFunction<? super K, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
V oldValue = get(key);
V newValue = remappingFunction.apply(key, oldValue);
if (newValue == null) {
// delete mapping
if (oldValue != null || containsKey(key)) {
// something to remove
remove(key);
return null;
} else {
// nothing to do. Leave things as they were.
return null;
}
} else {
// add or replace old mapping
put(key, newValue);
return newValue;
}
}
default V merge(K key, V value,
BiFunction<? super V, ? super V, ? extends V> remappingFunction) {
Objects.requireNonNull(remappingFunction);
Objects.requireNonNull(value);
V oldValue = get(key);
V newValue = (oldValue == null) ? value :
remappingFunction.apply(oldValue, value);
if (newValue == null) {
remove(key);
} else {
put(key, newValue);
}
return newValue;
}
// 十一个of方法
static <K, V> Map<K, V> of() {
return ImmutableCollections.emptyMap();
}
static <K, V> Map<K, V> of(K k1, V v1) {
return new ImmutableCollections.Map1<>(k1, v1);
}
static <K, V> Map<K, V> of(K k1, V v1, K k2, V v2) {
return new ImmutableCollections.MapN<>(k1, v1, k2, v2);
}
static <K, V> Map<K, V> of(K k1, V v1, K k2, V v2, K k3, V v3) {
return new ImmutableCollections.MapN<>(k1, v1, k2, v2, k3, v3);
}
// ...剩下的都是ImmutableCollections.MapN<>接收可变长参数进行实现的
// ImmutableCollections 中的Map1 MapN
// static final class Map1<K,V> extends AbstractImmutableMap<K,V>
// static final class MapN<K,V> extends AbstractImmutableMap<K,V>
// 这俩都是继承自AbstractImmutableMap
// 而AbstractImmutableMap继承自AbstractMap, 把所有跟put相关的方法都默认返回UnsupportedOperationException()
// 在Map1 MapN中,都是只有构造函数可以接收参数并创建好需要的集合.
// 除构造方法之外没有别的修改以创建好集合的方法.
abstract static class AbstractImmutableMap<K,V> extends AbstractMap<K,V> implements Serializable {
@Override public void clear() { throw uoe(); }
@Override public V compute(K key, BiFunction<? super K,? super V,? extends V> rf) { throw uoe(); }
@Override public V computeIfAbsent(K key, Function<? super K,? extends V> mf) { throw uoe(); }
@Override public V computeIfPresent(K key, BiFunction<? super K,? super V,? extends V> rf) { throw uoe(); }
@Override public V merge(K key, V value, BiFunction<? super V,? super V,? extends V> rf) { throw uoe(); }
@Override public V put(K key, V value) { throw uoe(); }
@Override public void putAll(Map<? extends K,? extends V> m) { throw uoe(); }
@Override public V putIfAbsent(K key, V value) { throw uoe(); }
@Override public V remove(Object key) { throw uoe(); }
@Override public boolean remove(Object key, Object value) { throw uoe(); }
@Override public V replace(K key, V value) { throw uoe(); }
@Override public boolean replace(K key, V oldValue, V newValue) { throw uoe(); }
@Override public void replaceAll(BiFunction<? super K,? super V,? extends V> f) { throw uoe(); }
}
// 创建一个不可变的映射
static <K, V> Entry<K, V> entry(K k, V v) {
// KeyValueHolder checks for nulls
return new KeyValueHolder<>(k, v);
}
/**
* 返回包含给定映射项的不可修改映射。给定的映射不能为空,也不能包含任何空键或值。
* 如果给定的映射随后被修改,返回的映射将不会反映这种修改。
*/
static <K, V> Map<K, V> copyOf(Map<? extends K, ? extends V> map) {
if (map instanceof ImmutableCollections.AbstractImmutableMap) {
return (Map<K,V>)map;
} else {
return (Map<K,V>)Map.ofEntries(map.entrySet().toArray(new Entry[0]));
}
}
Map.Entity接口
Map.Entity接口定义了Map集合中的实际存储节点.
Map的实现类, 诸如Hashmap, TreeMap等, 存储节点都是实现了Map.Entity的静态内部类.
上面提到的Map.entrySet循环方法, 得到的就是所有Map.Entry<K, V>的集合.
interface Entry<K, V> {
/**
* 返回节点存储的key值
*/
K getKey();
/**
* 返回节点存储的value值
*/
V getValue();
/**
* 将与此项对应的值替换为指定的值
*/
V setValue(V value);
/**
* 比较指定的对象与此条目是否相等。
* 如果给定的对象也是映射项,并且这两个项表示相同的映射,则返回true。
*/
boolean equals(Object o);
/**
* 返回此映射项的哈希码值。
*/
int hashCode();
// 用于流处理的比较器
// 之后写流处理的时候再整理吧...
public static <K extends Comparable<? super K>, V> Comparator<Map.Entry<K, V>> comparingByKey() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getKey().compareTo(c2.getKey());
}
public static <K, V extends Comparable<? super V>> Comparator<Map.Entry<K, V>> comparingByValue() {
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> c1.getValue().compareTo(c2.getValue());
}
public static <K, V> Comparator<Map.Entry<K, V>> comparingByKey(Comparator<? super K> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getKey(), c2.getKey());
}
public static <K, V> Comparator<Map.Entry<K, V>> comparingByValue(Comparator<? super V> cmp) {
Objects.requireNonNull(cmp);
return (Comparator<Map.Entry<K, V>> & Serializable)
(c1, c2) -> cmp.compare(c1.getValue(), c2.getValue());
}
}
哈希洪水攻击
概念
哈希洪水攻击(Hash-Flooding Attack)是一种拒绝服务攻击(Denial of Service),一旦后端接口存在合适的攻击面,攻击者就能轻松让整台服务器陷入瘫痪。
哈希表的时间复杂性
哈希表(Hash Table)的‘平均运行时间‘和‘最差运行时间‘会差很远。
假设我们想要连续插入n个元素到哈希表中:
- 如果这些元素的键(Key)极少出现相同哈希值,这项任务就只需
O(n)的时间。 - 如果这些键频繁出现相同的哈希值(频繁发生碰撞),这项任务就需要
O(n^2)的时间。
衍生出的奇思妙想:
既然哈希表数据结构的最差运行时间这么废物,我们有没有可能通过算法上的漏洞,强行构造出一个最差情况,让服务器把全部的资源都浪费在处理这个最差情况上?
由哈希map的默认计算哈希值和Object类的计算哈希值策略可以看到, 如果不做自定义的话, 默认就是使用Java自带的字符串哈希函数 :“DJBX33A算法”的变种.
// hashmap计算哈希值的策略
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
// Object类的计算哈希值策略
@HotSpotIntrinsicCandidate
public native int hashCode();
而根据这个算法定义,就可以轻松地构造出一批具有一样哈希值的字符串, 这样只要构造出足够多的哈希的字符串,把它们提交给服务器做哈希表, 就能用很低的成本将服务器打瘫.
如何防御
哈希洪水攻击的根本在于黑客可以通过已知的哈希算法算出哈希值相同的数.
所以我们可以使用带密钥哈希算法(Keyed Hash Function), 在算法中加入一个秘密参数 - 哈希种子(Hash Seed), 让黑客无法掌握具体的哈希算法,就可以进行有效的防御了.
来自Google、UIC等机构的众多研究人员设计了许多新的哈希函数:SipHash、MurmurHash、CityHash等等。这些算法不停地被推翻,不停地更新版本,到现在已经形成了一套稳定的算法标准,被众多编程语言和开源项目所采纳。
Java提出的解决方案:
从JDK 8开始,HashMap、LinkedHashMap和ConcurrentHashMap三个类引入了一套新的策略来处理哈希碰撞。
- 当一个位置存储的元素个数小于8个时,仍然使用链表存储。
- 当一个位置存储的元素个数大于等于8个时,改为使用平衡树来存储。
这样一来,就能保证最差的运行时间是O(n log n)了。
为什么要设立“8个元素”(TREEIFY threshold):
因为平衡树相比链表而言有着更高的开销,以及更散乱的内存布局(影响缓存命中率)。在正常情况下,哈希表的一个位置大约只会存储1~4个左右的元素,所以没有必要专门开一个平衡树来存储冲突的元素,对一些性能敏感的应用来说会造成显著的负面影响。
哈希洪水概念说明整理自知乎大佬的回复:
什么是哈希洪水攻击(Hash-Flooding Attack)? - Gh0u1L5的回答 - 知乎
代码测试
测试了一下最极端的每次的哈希值都相同和正常插入哈希值做对比:
public static void main(String[] args) {
Map<TestString, Integer> map = new HashMap();
Long l = System.currentTimeMillis();
System.out.println(l);
for (int i = 0; i < 100000; i++ ) {
map.put(new TestString("ddd" + i), i);
}
System.out.println(System.currentTimeMillis() - l);
Long c = System.currentTimeMillis();
map.get(new TestString("ddd"+5000));
System.out.println("-------" + (System.currentTimeMillis() - c));
Map<TestStringNom, Integer> mapNom = new HashMap();
Long ll = System.currentTimeMillis();
System.out.println(l);
for (int i = 0; i < 100000; i++ ) {
mapNom.put(new TestStringNom("ddd" + i) , i);
}
System.out.println(System.currentTimeMillis() - ll);
Long cc = System.currentTimeMillis();
mapNom.get(map.get(new TestStringNom("ddd5000")));
System.out.println("-------" + (System.currentTimeMillis() - cc));
}
public class TestString {
final String val;
public TestString(String val) {
this.val = val;
}
@Override
public int hashCode() {
super.hashCode();
return 88590;
}
}
public class TestStringNom {
final String val;
public TestStringNom(String val) {
this.val = val;
}
@Override
public int hashCode() {
return super.hashCode();
}
}
| 数量级 | 模拟洪水插入时间(ms) | 正常插入时间(ms) | 模拟洪水查询时间(ms) | 正常查询时间(ms) |
|---|---|---|---|---|
| 1000 | 24 | 1 | 0 | 0 |
| 10000 | 749 | 2 | 0 | 0 |
| 100000 | 154941 | 42 | 4 | 0 |
以上是关于JAVA集合框架 - Map接口的主要内容,如果未能解决你的问题,请参考以下文章
Java知识33 集合框架 List接口 Map 和set多测师