增强学习Reinforcement Learning经典算法梳理1:policy and value iteration
Posted songrotek
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了增强学习Reinforcement Learning经典算法梳理1:policy and value iteration相关的知识,希望对你有一定的参考价值。
前言
就目前来看,深度增强学习(Deep Reinforcement Learning)中的很多方法都是基于以前的增强学习算法,将其中的value function价值函数或者Policy function策略函数用深度神经网络替代而实现。因此,本文尝试总结增强学习中的经典算法。
本文主要参考:
1 Reinforcement Learning: An Introduction
2 Reinforcement Learning Course by David Silver
1 预备知识
对增强学习有所理解,知道MDP,Bellman方程
详细可见:Deep Reinforcement Learning 基础知识(DQN方面)
很多算法都是基于求解Bellman方程而形成:
- Value Iteration
- Policy Iteration
- Q-Learning
- SARSA
2 Policy Iteration 策略迭代
Policy Iteration的目的是通过迭代计算value function 价值函数的方式来使policy收敛到最优。
Policy Iteration本质上就是直接使用Bellman方程而得到的:

那么Policy Iteration一般分成两步:
- Policy Evaluation 策略评估。目的是 更新Value Function
- Policy Improvement 策略改进。 使用 greedy policy 产生新的样本用于第一步的策略评估。

本质上就是使用当前策略产生新的样本,然后使用新的样本更新当前的策略,然后不断反复。理论可以证明最终策略将收敛到最优。
具体算法:

那么这里要注意的是policy evaluation部分。这里的迭代很重要的一点是需要知道state状态转移概率p。也就是说依赖于model模型。而且按照算法要反复迭代直到收敛为止。所以一般需要做限制。比如到某一个比率或者次数就停止迭代。
3 Value Iteration 价值迭代
Value Iteration则是使用Bellman 最优方程得到

然后改变成迭代形式
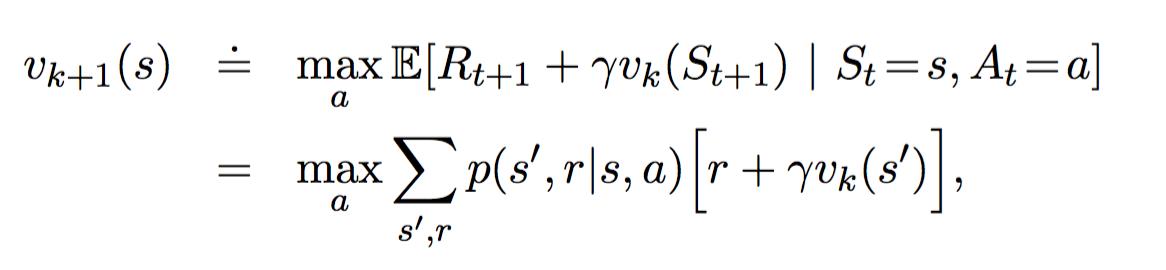
value iteration的算法如下:

那么问题来了:
- Policy Iteration和Value Iteration有什么本质区别?
- 为什么一个叫policy iteration,一个叫value iteration呢?
原因其实很好理解,policy iteration使用bellman方程来更新value,最后收敛的value 即 vπ 是当前policy下的value值(所以叫做对policy进行评估),目的是为了后面的policy improvement得到新的policy。
而value iteration是使用bellman 最优方程来更新value,最后收敛得到的value即 v∗ 就是当前state状态下的最优的value值。因此,只要最后收敛,那么最优的policy也就得到的。因此这个方法是基于更新value的,所以叫value iteration。
从上面的分析看,value iteration较之policy iteration更直接。不过问题也都是一样,需要知道状态转移函数p才能计算。本质上依赖于模型,而且理想条件下需要遍历所有的状态,这在稍微复杂一点的问题上就基本不可能了。
4 异步更新问题
那么上面的算法的核心是更新每个状态的value值。那么可以通过运行多个实例同时采集样本来实现异步更新。
而基于异步更新的思想,DeepMind出了一篇不错的paper:
Asynchronous Methods for Deep Reinforcement Learning
该文对于Atari游戏的效果得到大幅提升。
5 小结
Reinforcement Learning有很多经典算法,很多算法都基于以上衍生。鉴于篇幅问题,下一个blog再分析基于蒙特卡洛的算法。
以上是关于增强学习Reinforcement Learning经典算法梳理1:policy and value iteration的主要内容,如果未能解决你的问题,请参考以下文章
增强学习Reinforcement Learning经典算法梳理3:TD方法
增强学习Reinforcement Learning经典算法梳理1:policy and value iteration
增强学习Reinforcement Learning经典算法梳理1:policy and value iteration