医学中都有哪些问题可以用马尔科夫、隐马尔科夫、贝叶斯模型来建模?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了医学中都有哪些问题可以用马尔科夫、隐马尔科夫、贝叶斯模型来建模?相关的知识,希望对你有一定的参考价值。
参考技术A HIV_Ab抗体筛检试剂。马尔可夫模型(Markov Model)是一种统计模型,广泛应用在语音识别,词性自动标注,音字转换,概率文法等各个自然语言处理等应用领域。经过长期发展,尤其是在语音识别中的成功应用,使它成为一种通用的统计工具。隐马尔可夫模型(Hidden Markov Model,HMM)是统计模型,它用来描述一个含有隐含未知参数的马尔可夫过程。其难点是从可观察的参数中确定该过程的隐含参数。然后利用这些参数进一步的分析,例如模式识别。是在被建模的系统被认为是一个马尔可夫过程与未观测到的(隐藏的)的状态的统计马尔可夫模型。贝叶斯预测模型是运用贝叶斯统计进行的一种预测。贝叶斯统计不同于一般的统计方法,其不仅利用模型信息和数据信息,而且充分利用先验信息。通过实证分析的方法,将贝叶斯预测模型与普通回归预测模型的预测结果进行比较,结果表明贝叶斯预测模型具有明显的优越性。NLP重剑篇之朴素贝叶斯与隐马尔可夫
-
判别式与生成式模型 -
朴素贝叶斯 -
基于大数定律估计 -
极大似然估计 -
贝叶斯估计 -
参数估计 -
朴素贝叶斯算法 -
隐马尔可夫模型 -
近似算法 -
维特比算法 -
监督学习算法 -
非监督学习算法 -
直接计算法 -
前向概率 -
后向概率 -
隐马尔可夫模型的基本概念 -
概率计算问题 -
EM算法 -
学习问题 -
预测问题 -
参考文献
朴素贝叶斯章节请查看:
隐马尔可夫模型
上面所讲的是一个文本只有一个类别,如果扩展一下,让每个字都有一个类别,将会怎样呢?
根据上图以及朴素贝叶斯公式,我们可以类比得到上图的预测公式:
其中C式一个长度为
的列表,
是一个文本(样本)的y序列长度。
根据上式可以观察到,
只跟
有关系,这式因为模型有一个基本假设:观测独立性假设。
因为C是一个序列,所以P(C)的计算为:
这样P(C)的计算异常麻烦,为了简化计算,引入了另外一个假设:齐次马尔可夫行假设
此时P(C)的计算为:
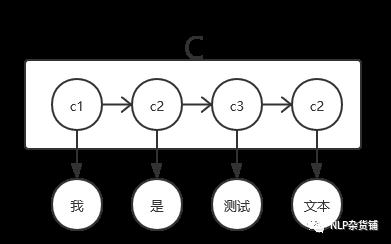
那么整体的预测公式为:
隐马尔可夫模型的基本概念
根据上述推导,稍加改变,可以得到隐马尔可夫模型的定义:
设 是所有可能的状态(类别)集合, 是所有可能的观测(特征)集合,N是状态数,M是观测数。 是状态序列, 是观测序列。 是状态转移概率矩阵,其中 。 ,是观测概率矩阵,其中 。 是初始概率状态,其中 。隐马尔可夫模型由 决定,即 。
因此模型被定义为:
import numpy as np
class HMM(object):
def __init__(self, samples, num_hidden, num_obj, labels=None, _lambda=1, num_cycle=500):
self.samples = samples
self.labels = labels
self.A = np.random.randn(num_hidden, num_hidden)
self.B = np.random.randn(num_hidden, num_obj)
self.pie = np.random.randn(num_hidden)
self.num_hidden = num_hidden
self.num_obj = num_obj
self._lambda = _lambda
self.num_cycle = num_cycle # 无监督学习时迭代的最大次数
self.tem_alpha = {}
self.tem_beta = {}
if labels:
self.unsupervised_learning()
else:
self.supervised_learning()
观测预测生成算法
输入:隐马尔可夫模型 ,序列长度T
输出:观测序列
1)根据 产生状态
2)令t=1
3)根据 生成
4)根据 生成
5)令t=t+1,如果 ,则转3,否则终止。
隐马尔可夫模型的三个基本问题
1)概率计算问题:已知 与 ,计算在 条件下 的出现概率 。
2)学习问题:已知 ,估计 模型参数。
3)预测问题(解码问题):已知,求使得最大的状态序列 。
概率计算问题
直接计算法
隐马尔可夫模型的第一个问题,概率计算问题,可以使用暴力方法直接计算:
暴力计算概率的方法非常直接,也很简单,但如果序列长度较长,则时间复杂度就非常高,其复杂度为 。所以在序列有一定长度的情况下,这种计算方式基本不可能,为此人们基于动态规划的思想,提出了前向概率计算与后向概率计算。
前向概率
给定模型 ,定义到时刻t时且状态为 的概率为前向概率,记作
根据定义,观测序列概率的前向算法为:
输入:模型 ,观测s序列X
输出:
1)
2)递推:
3)
由此我们得到前向概率计算代码:
def compute_alpha(self, t, o_list):
# 前向计算
if t in self.tem_alpha.keys():
return self.tem_alpha[t]
alpha = []
o_i = o_list[t - 1] # index从0开始,比实际少1
if t == 1:
for i, b_i in enumerate(self.B):
alpha.append(self.pie[i] * b_i[o_i])
else:
last_alpha = self.compute_alpha(t - 1, o_list)
for i , b_i in enumerate(self.B):
tem_alpha = [last_alpha[j] * self.A[j, i] for j in range(len(last_alpha))]
tem_alpha = sum(tem_alpha) * b_i[o_i]
alpha.append(tem_alpha)
return alpha
def alpha_p(self, o_list):
# 前向算法计算总概率
alpha = self.compute_alpha(len(o_list), o_list)
p = sum(alpha)
self.tem_alpha = {i:v for i, v in enumerate(alpha)}
return p
后向概率
给定模型 ,定义时刻t,状态为 的条件下,观测序列从t+1到T为 的概率为后向概率,记作:
根据定义,观测序列的后向算法为:
输入:模型 ,观测s序列X
输出:
1)
2)地推:
3)
由此我们得到后向概率计算代码:
def compute_beta(self, t, o_list):
# 后向计算
if t in self.tem_beta.keys():
return self.tem_beta[t]
beta = []
if t == len(o_list):
for b in self.B:
beta.append(1)
else:
last_beta = self.compute_beta(t + 1, o_list)
o_i_1 = o_list[t + 1 - 1] # index从0开始,比实际少1
for i, b_i in enumerate(self.B):
tem_beta = [self.A[i, j] * last_beta[j] * self.B[j, o_i_1] for j in range(len(last_beta))]
tem_beta = sum(tem_beta)
beta.append(tem_beta)
return beta
def beta_p(self, o_list):
# 后向算法计算总概率
beta = self.compute_beta(1, o_list)
o_1 = o_list[0] # index从0开始,比实际少1
p = [self.pie[i] * self.B[i, o_1] * beta[i] for i in range(len(beta))]
p = sum(p)
self.tem_beta = {i:v for i, v in enumerate(beta)}
return p
直接计算概率的方法,其实重复计算了很多次,前向概率与后向概率方法,使用动态规划的思想避免了重复计算,其时间复杂度为
,而前向后向概率的区别也很明显,一个从前往后算(如果t时刻是最后时刻,那么t时刻转态为j的概率是多少),一个从后往前算(如果前一时刻转态为j,那么生成所有后续时刻的概率是多少),基于此,我们还可以得到一些情况的概率计算公式。
1)在时刻t状态为
的概率:
2)在时刻t状态处于 ,时刻t+1状态处于 的概率:
根据前向后向概率计算,我们容易得到:
def p_t_i(self, t, i, p, o_list):
#t步时,隐状态为i的概率
alpha = self.compute_alpha(t, o_list)
beta = self.compute_beta(t, o_list)
return alpha[i] * beta[i] / p
def p_t_i_j(self, t, i, j, p, o_list):
#t步隐状态为i,t+1步隐状态为j的概率
alpha = self.compute_alpha(t, o_list)
beta = self.compute_beta(t+1, o_list)
o_t_1 = o_list[t + 1 - 1]
return alpha[i] * self.A[i, j] * beta[j] * self.B[j, o_t_1] / p
EM算法
EM算法是包含隐变量的概率模型参数的估计方法。这边插入讲解EM算法的定义,因为隐马尔可夫的无监督学习算法需要用到,EM算法是十大经典算法之一,具体细节后续会另写一篇详细讲解。
输入:观测变量数据Y,隐变量数据Z,联合概率分布 ,条件分布
输出:模型参数
1)选择参数的初始值
2)E步:记 为第i次迭代参数 的估计值,在第i+1次迭代的E步,计算:3)M步:求使得 极大化的 :
4)重复2、3两步,直到收敛。
学习问题
监督学习算法
当训练数据包含状态(类别)序列时,此时是监督学习问题,跟上面朴素贝叶斯相似,可以根据最大似然概率的方法,估计参数值(推导过程可以参考上面):
其中
表示从状态i转为状态j的频数,
表示状态为i观测为k的频数,
表示所有样本中初始状态为
的频率。
因此监督学习代码为:
def supervised_learning(self):
#监督学习
label_num_dict = {}
each_feature_num4label = {}
first_label = [0 for i in range(self.num_hidden)]
for sample, label in zip(self.samples, self.labels):
first_label[label[0]] = first_label[label[0]] + 1
pre_l = -1
for s, l in zip(sample, label):
if l not in label_num_dict.keys():
label_num_dict[l] = {}
each_feature_num4label[l] = {}
each_feature_num4label[l][s] = each_feature_num4label[l].get(s, 0) + 1
if pre_l > -1:
label_num_dict[pre_l][l] = label_num_dict[pre_l].get(l, 0) + 1
pre_l = l
self.pie = first_label
label_dis = []
for i in range(self.num_hidden):
tem_label_dis = [0 for i in range(self.num_hidden)]
i_label_num_dict = label_num_dict.get(i, {})
i_sum = sum([v for k, v in i_label_num_dict.items()]) + self.num_hidden * self._lambda
for j in range(self.num_hidden):
tem_label_dis[j] = (i_label_num_dict.get(j, 0) + self._lambda)/i_sum
label_dis.append(tem_label_dis)
self.A = np.array(label_dis)
label_feature_dis = []
for i in range(self.num_hidden):
tem_label_feature_dis = [0 for i in range(self.num_obj)]
i_label_feature_num = each_feature_num4label.get(i, {})
i_sum = sum([v for k, v in i_label_feature_num.items()]) + self.num_obj * self._lambda
for j in range(self.num_obj):
tem_label_feature_dis[j] = (i_label_feature_num.get(j, 0) + self._lambda)/i_sum
label_feature_dis.append(tem_label_feature_dis)
self.B = np.array(label_feature_dis)
非监督学习算法
由于监督学习需要用到状态序列,而获得状态序列的获取代价往往很高,有时就会利用非监督学习的方法。根据上面介绍的EM算法,可以得到:
因为 是常数,所以Q可以等价于:
根据概率和为1,即:
利用拉个朗日乘子法,可得Q为极值时:
由此得到具体算法为:
输入:观测数据
输出:模型参数
1)初始化
2)递推,n=1,2,...其中右边各值都是有观测值X与 计算。
3)到达终止条件,得到模型参数 。
因此非监督学习算法代码为:
def unsupervised_learning(self):
# 非监督学习
for epoch in range(self.num_cycle):
for sample in self.samples:
p_o = self.alpha_p(sample)
self.beta_p(sample)
for i in range(self.num_hidden):
for j in range(self.num_hidden):
self.A[i, j] = sum([self.p_t_i_j(t, i, j, p_o, sample) for t in range(len(sample))])/p_o
for k in range(self.num_obj):
self.B[i, k] = sum([self.p_t_i(t, i, p_o, sample) for t in range(len(sample))])/p_o
self.pie[i] = self.p_t_i(0, i, p_o, sample)
预测问题
近似算法
根据上面的概率计算公式,我们可以用贪婪的方式计算出每个节点最大概率的状态(类别):
所以近似算法代码为:
def predict_(self, sample):
# 近似解法
hidden = []
p = self.alpha_p(sample)
self.beta_p(sample)
for hi, obj in sample:
p_list = [self.p_t_i(hi, i, p, sample) for i in range(len(self.num_hidden))]
hidden.append(np.argmax(p_list))
return hidden
维特比算法
近似算法计算简单,但不保证序列的最优化,而且会有不可能出现的序列的情况,比如计算结果时[2,1,2,3],而实际上2后面不可能出现1,这就产生很多不合理,所以依然用动态规划,可以计算整个序列的最优化结果。
为了计算整体最优,我们先定义几个式子:
其中
表示t时间步上状态为i时的最大概率,
表示t时间步上使得状态为i时概率最大的t-1时的状态j。
根据上面我们得到维特比算法:
输入:模型 ,观测
输出:最优化路径
1)初始化:
2)递推:3)终止:
4)路径回溯:
因此维特比算法代码为:
def predict(self, sample):
# 维特比解法
a = [[]]
b = [[]]
for i in range(self.num_hidden):
a[0][i] = self.pie[i]*self.B[i, sample[0]]
b[0][i] = 0
for t in range(1, len(sample)):
for i in range(self.num_hidden):
tem_a = [a[t-1][i] * self.A[j, i] for j in range(self.num_hidden)]
max_ind = np.argmax(tem_a)
a[t][i] = tem_a[max_ind] * self.B[i, sample[t]]
b[t][i] = max_ind
last_a = a[-1]
hidden = []
index = np.argmax(last_a)
hidden.insert(0, index)
t = len(sample) - 1
while t >= 0:
t -= 1
index = b[t][index]
hidden.index(0, index)
return hidden
阅读原文可查看全部内容
参考文献
【1】数学 · 朴素贝叶斯(二*)· 推导与推广
【2】统计学习方法,李航
以上是关于医学中都有哪些问题可以用马尔科夫、隐马尔科夫、贝叶斯模型来建模?的主要内容,如果未能解决你的问题,请参考以下文章