RecursiveTask和RecursiveAction的使用 以及java 8 并行流和顺序流(转)
Posted 木西 - Muxy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RecursiveTask和RecursiveAction的使用 以及java 8 并行流和顺序流(转)相关的知识,希望对你有一定的参考价值。
什么是Fork/Join框架
Fork/Join框架是Java7提供了的一个用于并行执行任务的框架, 是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
我们再通过Fork和Join这两个单词来理解下Fork/Join框架,Fork就是把一个大任务切分为若干子任务并行的执行,Join就是合并这些子任务的执行结果,最后得到这个大任务的结果。比如计算1+2+。。+10000,可以分割成10个子任务,每个子任务分别对1000个数进行求和,最终汇总这10个子任务的结果。Fork/Join的运行流程图如下:
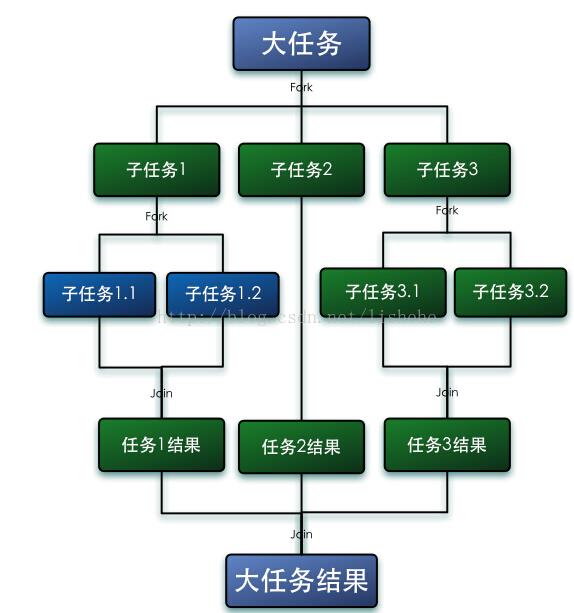
工作窃取算法
工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。工作窃取的运行流程图如下:
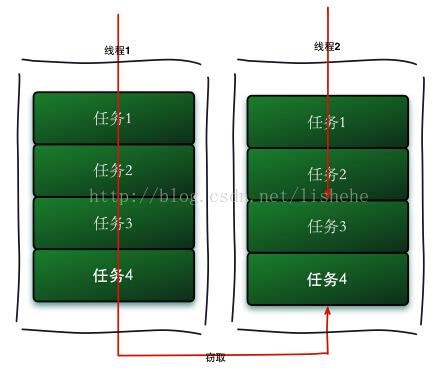
那么为什么需要使用工作窃取算法呢?假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
ForkJoinPool
Java提供了ForkJoinPool来支持将一个任务拆分成多个“小任务”并行计算,再把多个“小任务”的结果合成总的计算结果。
ForkJoinPool是ExecutorService的实现类,因此是一种特殊的线程池。ForkJoinPool提供了如下两个常用的构造器。
public ForkJoinPool(int parallelism):创建一个包含parallelism个并行线程的ForkJoinPool
public ForkJoinPool() :以Runtime.getRuntime().availableProcessors()的返回值作为parallelism来创建ForkJoinPool
创建ForkJoinPool实例后,可以钓鱼ForkJoinPool的submit(ForkJoinTask<T> task)或者invoke(ForkJoinTask<T> task)来执行指定任务。其中ForkJoinTask代表一个可以并行、合并的任务。ForkJoinTask是一个抽象类,它有两个抽象子类:RecursiveAction和RecursiveTask。
RecursiveTask代表有返回值的任务
RecursiveAction代表没有返回值的任务。
RecursiveAction
下面以一个没有返回值的大任务为例,介绍一下RecursiveAction的用法。
大任务是:打印0-100的数值。
小任务是:每次只能打印20个数值。
代码执行
package com.example.jedis.test; import java.util.concurrent.RecursiveAction; /** * * @Author : Wukn * @Date : 2018/2/5 */ public class RaskDemo extends RecursiveAction { /** * 每个"小任务"最多只打印20个数 */ private static final int MAX = 20; private int start; private int end; public RaskDemo(int start, int end) { this.start = start; this.end = end; } @Override protected void compute() { //当end-start的值小于MAX时,开始打印 if((end-start) < MAX) { for(int i= start; i<end;i++) { System.out.println(Thread.currentThread().getName()+"i的值"+i); } }else { // 将大任务分解成两个小任务 int middle = (start + end) / 2; RaskDemo left = new RaskDemo(start, middle); RaskDemo right = new RaskDemo(middle, end); left.fork(); right.fork(); } } }
public static void main(String[] args) throws Exception{ // 创建包含Runtime.getRuntime().availableProcessors()返回值作为个数的并行线程的ForkJoinPool ForkJoinPool forkJoinPool = new ForkJoinPool(); // 提交可分解的PrintTask任务 forkJoinPool.submit(new RaskDemo(0, 1000)); //阻塞当前线程直到 ForkJoinPool 中所有的任务都执行结束 forkJoinPool.awaitTermination(2, TimeUnit.SECONDS); // 关闭线程池 forkJoinPool.shutdown(); }
运行结果
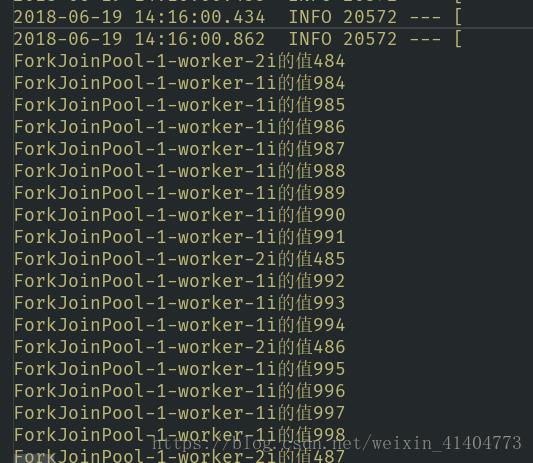
从上面结果来看,ForkJoinPool启动了四个线程来执行这个打印任务,我的计算机的CPU是四核的。大家还可以看到程序虽然打印了0-999这一千个数字,但是并不是连续打印的,这是因为程序将这个打印任务进行了分解,分解后的任务会并行执行,所以不会按顺序打印。
RecursiveTask
下面以一个有返回值的大任务为例,介绍一下RecursiveTask的用法。
大任务是:计算随机的1000个数字的和。
小任务是:每次只能70个数值的和。
package com.example.jedis.test; import java.util.concurrent.RecursiveTask; /** * * @Author : Wukn * @Date : 2018/2/5 */ public class RecursiveTaskDemo extends RecursiveTask<Integer> { /** * 每个"小任务"最多只打印70个数 */ private static final int MAX = 70; private int arr[]; private int start; private int end; public RecursiveTaskDemo(int[] arr, int start, int end) { this.arr = arr; this.start = start; this.end = end; } @Override protected Integer compute() { int sum = 0; // 当end-start的值小于MAX时候,开始打印 if((end - start) < MAX) { for (int i = start; i < end; i++) { sum += arr[i]; } return sum; }else { System.err.println("=====任务分解======"); // 将大任务分解成两个小任务 int middle = (start + end) / 2; RecursiveTaskDemo left = new RecursiveTaskDemo(arr, start, middle); RecursiveTaskDemo right = new RecursiveTaskDemo(arr, middle, end); // 并行执行两个小任务 left.fork(); right.fork(); // 把两个小任务累加的结果合并起来 return left.join() + right.join(); } } }
@Test public void dfs() throws Exception{ int arr[] = new int[1000]; Random random = new Random(); int total = 0; // 初始化100个数字元素 for (int i = 0; i < arr.length; i++) { int temp = random.nextInt(100); // 对数组元素赋值,并将数组元素的值添加到total总和中 total += (arr[i] = temp); } System.out.println("初始化时的总和=" + total); // 创建包含Runtime.getRuntime().availableProcessors()返回值作为个数的并行线程的ForkJoinPool ForkJoinPool forkJoinPool = new ForkJoinPool(); // 提交可分解的PrintTask任务 // Future<Integer> future = forkJoinPool.submit(new RecursiveTaskDemo(arr, 0, arr.length)); // System.out.println("计算出来的总和="+future.get()); Integer integer = forkJoinPool.invoke( new RecursiveTaskDemo(arr, 0, arr.length) ); System.out.println("计算出来的总和=" + integer); // 关闭线程池 forkJoinPool.shutdown(); }

从上面结果来看,ForkJoinPool将任务分解了15次,程序通过SumTask计算出来的结果,和初始化数组时统计出来的总和是相等的,这表明计算结果一切正常。
总结
第一步分割任务
首先我们需要有一个fork类来把大任务分割成子任务,有可能子任务还是很大,所以还需要不停的分割,直到分割出的子任务足够小。
第二步执行任务并合并结果。
分割的子任务分别放在双端队列里,然后几个启动线程分别从双端队列里获取任务执行。子任务执行完的结果都统一放在一个队列里,启动一个线程从队列里拿数据,然后合并这些数据。
能够轻松的利用多个 CPU 提供的计算资源来协作完成一个复杂的计算任务,提高运行效率!
java8新的写法
/************************************** 并行流 与 顺序流 ******************************************************/ /** *并行流 与 顺序流 */ @Test public void test03() { Instant start = Instant.now(); LongStream.rangeClosed( 0,110 ) //并行流 .parallel() .reduce( 0,Long::sum ); LongStream.rangeClosed( 0,110 ) //顺序流 .sequential() .reduce( 0,Long::sum ); Instant end = Instant.now(); System.out.println("耗费时间"+ Duration.between( start,end ).toMillis()); }
谈谈Fork-Join编程中RecursiveTask类的常用方法
解决方法:
·方法hasQueuedSubmissions()判断队列中是否有未执行的任务;
·方法getActiveThreadCount()获得活动的线程个数;
·方法getQueuedTaskCount()获得任务的总个数;
·方法getStealCount()获得偷窃的任务个数;
·方法getRunningThreadCount()获得正在运行并且不在阻塞状态下的线程个
·方法getParallelism()获得并行的数量,与CPU的内核数有关;
·方法getPoolSize()获得任务池的大小;
·方法getQueuedSubmissionCount()取得已经提交但尚未被执行的任务数量;
·方法isQuiescent():判断任务池是否是静止未执行任务的状态。
————————————————
版权声明:本文为CSDN博主「托尼吴」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_41404773/article/details/80733324
以上是关于RecursiveTask和RecursiveAction的使用 以及java 8 并行流和顺序流(转)的主要内容,如果未能解决你的问题,请参考以下文章