嵌入式C语言自我修养分享课件
Posted 菠萝印象威
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了嵌入式C语言自我修养分享课件相关的知识,希望对你有一定的参考价值。
一.异构计算
1.背景:
随着物联网、大数据、人工智能时代的到来,海量的数据分析和大量复杂的运算对CPU 的算力要求越来越高,CPU 的大部分资源用于缓存和逻辑控制,适合运行各种复杂的串行程序,但是单核或者多核CPU处理性能的提升空间已经达到极限了(也就是说,单靠CPU很难满足现代科技发展的需求)。
2.异构计算简介:
异构计算就是在SoC 芯片内部集成不同架构的Core,比如DSP、GPU、NPU、TPU、BPU等不同架构的处理单元,各个核心协同运算,等于CPU找来了一系列的伙伴来共同协助自己的工作。
CPU适合处理分支、跳转等复杂逻辑的程序。
GPU擅长处理图片、视频数据。
NPU 和FPGA以及BPU负责人工智能领域。
soc芯片介绍:
一般说来, SoC称为系统级芯片,也有称片上系统,意指它是一个产品,是一个有专用目标的集成电路,其中包含完整系统并有嵌入软件的全部内容。
core介绍:
Intel旗下的酷睿处理器
Core(酷睿)微体系架构,其针对桌面、笔记本和服务器推出的产品代号分别是,Conroe、Merom和Woodcrest,都拥有64位处理能力,并且是双核产品
3.部分处理器介绍:
GPU (Graphic Process Unit,图形处理单元)

GPU通俗的讲就是我们所说的显卡,英伟达是其发明者,它主要用来处理图像数据。显卡将数字图像信号转换为模拟信号,并输出到屏幕上,早期的显卡都是直接集成到主板 上,只充当适配器的角色。处理一些简单的图像,CPU能够轻松应对,不需要显卡的参与,随着大型3D游戏、制图和视频渲染软件的流行,数据运算量成倍增加,CPU 已经越来越力不从心,独立显卡开始承担图像处理和视频渲染的工作。GPU 天然多线程,特别适合大数据并行处理,在现在的计算机中被广泛使用,目前最火的就是NVIDIA(英伟达)。
DSP (Digital Signal Processing,数字信号处理器)

世界上第一个单片DSP芯片应当是1978年AMI公司发布的S2811,1979年美国Intel公司发布的商用可编程器件2920是DSP芯片的一个主要里程碑。
DSP主要用在音频信号处理和通信领域,相
比CPU, DSP 有三个优势:
1.DSP 采用哈弗架构,指令和数据独立存储,并行存取,执行效率更高。
2.对指令进行优化,提高了对信号的处理效率 , DSP 有专门的硬件乘法器,可以在一个时钟周期内完成乘法运算。
3.没有冗余的逻辑电路,功耗可以做得更小。
劣势:
DSP 的缺陷是只适合做大量重复运算,无法像CPU 那样提供一个通用的平台,DSP 处理器虽然有自己的指令集和C 语言编译器,但对操作系统的支持一般。目前DSP 市场被严重蚕食,在高速信号采集处理领域被FPGA 抢去一部分市场, 目前大多数以协处理器的形式与ARM 协同工作。
FPGA (Field Programmable Gate Array,现场可编程门阵列)

Xilinx (赛灵思)于 1984 年发明了世界首款 FPGA,主要用于数据处理,在专用集成电路领域中是以一种半定制电路的形式出现。
FPGA 芯片内部集成了大量的逻辑门电路和存储器,用户可以通过VHDL, Verilog 甚至高级语言编写代码来描述它们之间的连线,将这些连线配置文件写入芯片内部,就可以构成具有特定功能的电路。
FPGA直接将硬件描述语言翻译为晶体管门电路的组合,实现特定的算法和给能,可编程逻辑器件通过配套的集成开发工具,可以随时修改代码,下载到芯片内部,重新连线生成新的功能。
工作原理:
CPU 负责采集模拟信号,通过A/D 转换,将模拟信号转换成数字信号;然后将数字信号送到FPGA 进行处理;FPGA 依靠自身硬件电路的性能优势,对数字信号进行快速处理;最后将处理结果发送回CPU 处理器,以便CPU 做进一步的后续处理。
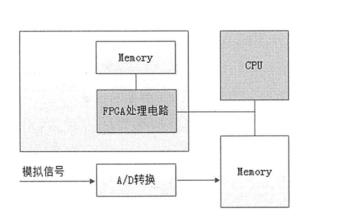
简而言之:FPGA是一个很灵活,并且能够跟其它芯片更好适配的一个处理器,在数字芯片验证、 ASIC 设计的前期验证、人工智能领域广受欢迎。
BPU(Brain Processor Unit,大脑处理器单元)

地平线科技提出的嵌入式人工智能处理器架构,第一代是高斯架构,第二代是伯努利架构,第三代是贝叶斯架构。
BPU是一款典型的异构多指令多数据的系统,架构中心处理器是完整的系统,存储器架构设计进行了特别优化,能使数据自由传递,进行多种计算,让不同部件同时运转起来,提高AI运算的效率。
BPU要做的不仅仅包括图像和视频感知,还包括语音、语义处理,以及决策、规划等比较复杂比较高阶的人工智能程序。
BPU架构能够在像素级别进行感知,能够更精确地分辨出路面、人体、汽车、建筑、树木等物体,进行图像分割。此外,更精准、更多路的感知结果将最终为环境的建模服务,可以从各个角度进行观测。
目前征程5芯片主要解决的三个痛点是算力浪费、生态缺失、数据风险。
征程5芯片采用8核心ARM Cortex A55核心、两个贝叶斯架构BPU实现AI运算,还有安全岛设计,支持丰富的接口。在视频输入方面,单颗征程5芯片就能够实现16路视频输入,并且支持毫米波雷达、激光雷达、超声波雷达等多种传感器。
总结:
对于一颗自动驾驶芯片来说,最重要的就是AI计算,地平线征程5采用双核心贝叶斯架构BPU,能够实现大规模异构近存计算,以实现高效率计算;同时拥有高灵活大并发数据桥,片上带宽非常大;此外,还有脉动张量计算核心,得以实现高算力。
| 名称 | 简介 |
|---|---|
| APU | 加速处理器,AMD 推出的加速图像处理芯片 |
| DPU | 深鉴科技设计的深度学习处理器 |
| EPU | 情绪处理单元,通过情绪合成引擎让机器人具有情绪 |
| FPU | 浮点计算单元,通用处理器中的浮点运算模块 |
| HPU | 全息图像处理器,微软出品的全息计算芯片与设备 |
| IPU | Graphcore 公司 设计 的 AI 处理器 |
| KPU | 杭州嘉楠耘智推出的人工智能边缘计算芯片 |
| MPU | 微处理器 |
| NPU | 神经网络处理器 |
| OPU | 光流处理器 |
| TPU | 张量处理器,Google 公司推出的人工智能专用处理器 |
| VPU | 视频处理单元,主要用于视频硬解码 |
| WPU | 可穿戴处理片上系统芯片 |
| XPU | 百度与Xihnx 公司 在 2017 年Hotchips 大会上发布的FPGA 智能云加速 |
| ZPU | 由挪威Zylin 公司 推 出的一款 32 位开源处理器 |
二.总线和地址
CPU 与内存 、 各种外部设备等IP 之间都是通过总线相连,CPU 如果想访问内存,或控制外部设备的运行是通过地址访问。
1.地址简介
地址的本质就是由CPU 管脚发出的一组地址控制信号,这些信号是由CPU 管脚直接发出的,因此也被称为物理地址
在带有MMU的CPU 平台下,程序运行一般使用的是虚拟地址, MMU 会把虚拟地址转换为物理地址,然后通过CPU 管脚发送出去,地址信号通过译码,选中指定的内存存储单元,再进行读写操作。
MMU:
MMU是内存管理单元,它是一种负责处理CPU的内存访问请求的计算机硬件。它的功能包括虚拟地址到物理地址的转换(即虚拟内存管理)、内存保护、CPU高速缓存的控制,在较为简单的计算机体系结构中,负责总线的仲裁以及存储体切换。
译码器
一组输入信号,通过译码转换,会选中一个输出信号,输出信号可以是高电平、低电平,甚至是一个脉冲。计算机的内存简单点理解,其实就是将一系列存储单元和译码器组装在一起。内存中包含很多存储单元,为了方便管理,我们需要将这些存储单元进行编号管理,每一个存储单元对应一个编号。当CPU 想访问其中一个存储单元时,可通过CPU 管脚发出一组信号,经过译码器译码,选中与这个信号对应的存储单元,然后就可以直接读写这块内存了。CPU 管脚发出的这组信号,也就是存储单元对应的编号,即地址。
2.总线简介
如果CPU 和内存RAM 直接相连,那么内存RAM 中的每一个存储单元的地址也就确定了。
现在的CPU一般通过总线与内容RAM、外部设备想连。CPU 和各个设备之间可以通过共享总线的方式进行通信。
总线其实就是各种数字信号的集合,包括地址信号、数据信号、控制信号等,由于遵循相同的总线协议和通信标准,不同厂家生产的显卡、CPU、鼠标、键盘等外设都能够即插即用。
也就是说CPU通过一些信号来和内存或者设备进行联系。
3.总线编址方式
内存RAM 和外部设备都挂到同一个总线上,计算机一般采用两种编址 方式:统一编址和独立编址
统一编址:内存 RAM 和外部设备共享CPU 的寻址空间。
在统一编址模式下,CPU 可以像操作内存一样去读写外部
设备的寄存器和内部RAM。
独立编址:内存RAM 和外部设备的寄存器独立编址,分别占用不同的地址空间。
三.指令集与微架构
1).什么是指令集?
图灵原型机的基本思想是:任何复杂的运算都可以分解为有限个基本指令的组合来完成。 CPU的设计是只支持有限个基本的运算指令,如加、减、乘、与、或、 非、移位、跳转等。这些指令通过不同的组合,可以构成不同的指令序列(程序) ,实现不同的逻辑功能。
不同架构的处理器支持的指令类型是不同。
ARM 架构的处理器只支持ARM 指令,X86架构的处理器只支持X86 指令。如果你在ARM 架构的处理器上运行X86 指令,就无法运行,报未定义指令的错误,因为ARM 架构的处理器只支持ARM 指令集中定义的指令。
指令集作为CPU 和编译器的设计规范和参考标准,主要用来定义指令的格式、操作数的类型、 寄存器的分配、地址的格式等
CPU 支持的有限个指令的集合,我们称之为指令集。
指令集是芯片设计者制定的一种规范标准。
2).指令集的基本构成

指令集不是一成不变的,随着迭代更新会不断扩充新的指令。
例如ARM指令集,已经从ARM V1发展到目前的ARM V8。
| 名称 | 介绍 |
|---|---|
| ARM V1 | 初版本, 26 位寻址空间,无乘法指令,没有商业化。 |
| ARM V2 | 加了乘法指令,支持协处理器。 |
| ARM V3 | 址范围从26 位扩展到32 位。 |
| ARM V4 | 次增加Thumb 指令集。 |
| ARM V5 | 加了增强型DSP 指令、 Java 指令 。 |
| ARM V6 | 首次增加60 多条SIMD 指令。 |
| ARM V7 | 增加长乘法指令、NEON 指令。 |
| ARM V8 | 首次增加64 位指令集、寄存器数量增加到31 个。 |
什么是微架构?
微架构,也就是处理器架构,指令集在CPU处理器内部的具体硬件电路的实现,我们就称为微架构。
设计微架构需要考虑的问题:
1.处理器是否支 持分支预测?
2.单发射还是多发射?
3.顺序执行还是乱序执行
4.流水线需要多少级?
5.主频需要多高?
6.Cache 需要多大?
7.需要几级Cache?
根据不同的配置选项,我们可以基于一套指令集设计出不同的微架构。
在X86 处理器领域, 目前能获得X86 指令集授权,并基于该指令集设计微架构和处理器的厂商有三家: Intel、AMD 和上海的兆芯
这三家厂商一般会根据新版本的X86 指令集设计出各自的
微架构,然后基于各自的微架构设计出不同的CPU。
X86微架构的缺点:
除了上述三家公司,其他公司一般无法获得授权去设计和生产自己的X86 处理器。
而ARM 则不同,通过开放ARM 指令集授权,其他公司可以基于授权的指令集去设计自己的微架构和SoC芯片,或者基于 ARM 官方的微架构直接去设计自己的SoC处理器。
所以微架构一般也称为CPU内核。
题目:
选择题:
1.以下哪个是图形处理单元( )
a. IPU b.VPU c.GPU d.APU
2.目前地平线使用的微架构是( )
a.X86
b.SoC
c.Cortex-A8
d.ARM V8
填空题
1.目前的微架构领域主要包括( )和( )。
2.计算机一般采用( )和( )编址方式。
3.地平线自研处理器叫( )。
4.目前公司采用的显卡名称叫( )。

以上是关于嵌入式C语言自我修养分享课件的主要内容,如果未能解决你的问题,请参考以下文章