Hadoop Security机制下跨集群日志分离认证问题解决方案
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop Security机制下跨集群日志分离认证问题解决方案相关的知识,希望对你有一定的参考价值。
参考技术A概述:为解决临时数据导致的集群资源争用问题,我们采用了container日志分离方案,但在Hadoop Security机制下,该方案存在跨集群的认证问题。经过对Hadoop Security机制及NodeMagager日志聚集功能源码的分析,探索了两种解决方案:1)在各计算框架以个人用户独立认证;2)在日志聚集功能模块以Yarn用户统一认证,并对两种解决方案的优劣进行了对比。
1 、概述
集群上的数据可以拆分为业务数据、临时数据(日志、 app jars等),两类数据(或其操作)共同争用RPC, 存储等资源。经统计,每天NN RPC总量约为9.06亿,其中,存储日志数据导致的RPC约占RPC总量的10%,为了降低计算集群的RPC压力,我们结合 YARN-3269 提出了Container日志分离方案:将Container日志数据进行聚集,然后存储至独立的用于存放冷数据的集群,从而消除日志存储对计算集群的影响。
目前,集群采用了基于Kerberos的Hadoop Security机制,而该安全机制会导致日志聚集功能中HDFSClient访问冷数据集群NameNode认证失败,从而影响分离方案实施。
为了解决该问题,保障分离方案顺利实施,对Hadoop Security机制做了深入研究,并结合NodeManager日志聚集功能源码分析,探索了两种解决方案:
1) 在各计算框架以个人用户独立认证。
2) 在日志聚集功能模块以Yarn用户统一认证。
下文将对Hadoop Security 机制,日志分离功能遇到的问题的原因及解决方案进行详细分析,不足之处,也请批评指正。
2 、Hadoop Security
Hadoop Security机制采用Kerberos 与Delegation Tokens(代理Token)相结合的方案。
2.1 Kerberos
2.1.1 Kerberos 原理
为了更加形象的说明Kerberos的原理,我们采用举例的方式进行说明(官方示例)。
比如:用户要去游乐场,首先要在门口检查用户的身份(即 CHECK 用户的 ID 和 PASS), 如果用户通过验证,游乐场的门卫 (AS) 即提供给用户一张门卡 (TGT)。
这张卡片的用处就是告诉游乐场的各个场所,用户是通过正门进来,而不是后门偷爬进来的,并且也是获取进入场所一把钥匙。
现在用户有张卡,但是这对用户来不重要,因为用户来游乐场不是为了拿这张卡的而是为了游览游乐项目,这时用户摩天楼,并想游玩。
这时摩天轮的服务员 (client) 拦下用户,向用户要求摩天轮的 (ST) 票据,用户说用户只有一个门卡 (TGT), 那用户只要把 TGT 放在一旁的票据授权机 (TGS) 上刷一下。 票据授权机 (TGS) 就根据用户现在所在的摩天轮,给用户一张摩天轮的票据 (ST), 这样用户有了摩天轮的票据,现在用户可以畅通无阻的进入摩天轮里游玩了。
当然如果用户玩完摩天轮后,想去游乐园的咖啡厅休息下,那用户一样只要带着那张门卡 (TGT). 到相应的咖啡厅的票据授权机 (TGS) 刷一下,得到咖啡厅的票据 (ST) 就可以进入咖啡厅。
当用户离开游乐场后,想用这张 TGT 去刷打的回家的费用,对不起,用户的 TGT 已经过期了,在用户离开游乐场那刻开始,用户的 TGT 就已经销毁了。
如图1所示,Kerberos认证的过程可以分为三步:1)Client获取KDC访问许可TGT(我是谁),2)向TGS请求要访问的目标服务的票具(我要干什么),3)访问目标服务(干什么),图中具体流程与举例说明相仿,下面我们结合HDFS的访问过程对其进行描述。
2.1.2 HDFS Client 的认证流程
下面以大家常用的hdfs dfs – ls dir(或 hadoop fs –ls dir) 为例,描述Kerberos的认证流程。
1) 首先使用kinit进行登录,输入密码后,Kerberos 客户端收集user-principle(kinit时产生,可以使用Klist进行查看) 和password,发送至KDC(AS)进行认证。
2) KDC认证通过后,下发TGT(user-kdc-ticket)给客户端。客户端收到TGT进行校验通过后,将TGT缓存在本地(用户只读)。
3) 将执行hdfs dfs –ls dir时,首先从缓存中取出TGT, 然后向KDC(TGS)获取连接NameNode(NN)访问许可。KDC收到请求,用户身份校验通过后,下发User-NN-Ticket.
4) HDFS客户端使用得到的User-NN-Ticket连接NN。NN收到请求后,对Ticket进行验证,认证通过后,使用加密数据回复客户端,客户端收到信任信息后,发送listFiles(dir)请求,并等待响应。
以上为HDFS Client简要流程,。
2.2 Delegation Token
理论上,可以单独使用Kerberos进行身份认证,然而,在Hadoop这样的分布式系统中使用时,存在一个问题:对于每一个Job, 如果所有的工作任务者使用TGT通过Kerberos TGS进行身份认证,那么Kerberos将很快成为瓶颈。图2中的红线说明了问题:一个作业可能有数千个节点到节点的通信,导致相同的KDC通信量。事实上,在大集群中会不经意地在KDC上执行分布式拒绝服务攻击。
因此,引入了Delegation Token作为一种轻量级的认证方法来补充Kerberos身份验证。Kerberos是三方协议;相比之下,Delegation Token认证是两方认证协议。引入Delegation Token之后的认证过程如图3所示。
为了简洁起见,图3省略了Kerberos身份验证的步骤和任务分配的细节。假设,现在已经完成了Kerberos的三步式认证,后续流程如下(KMS Delegation与HDFS Delegation协同,下面统一以HDFS的角度进行说明):
1)Client在进行完Kerberos的三步式认证后,获得NameNode产生的HDFS Delegation Token,并缓存于UGI.
2)Client 向RM(ResourceManager)提交App时,会携带该Token信息。
3)RM接到Token之后, 会马上对Token进行Renew操作已验证其合法性,并将其持久化到要启动ApplicationMaster的Worker(NodeManager),Worker在启动ApplicationMaster加载该Token(后续Worker类似)。
4)Worker 通过Token 对HDFS进行访问。
5)运行结束,RM撤销Token.
图3 Delegation Token 补充方案认证流程
值得注意的是,Token具有超时时间,默认为24小时。在不对Token更新的情况下,超过24小时的App将会失败。因此,存在Renewer对Token进行更新以保证长任务执行(token最终超时时间由yarn参数delegation.token.max-lifetime决定)。
3 、日志聚集功能
3.1 日志分离失败case
在原有配制基础上,开启日志分离功能(跨集群日志聚集)后,发现未按预期进行日志分离,且NodeManager节点存在以下异常信息:
通过观察日志,可以清晰的发现,该异常系权限认证失败所致。通过分析源码,该异常发生的位置进行的操作为:通过userUGI.doAs创建AppLogDir。日志显示的结果可能为userUGI中没有访问远程集群的Token,导致失败。
3.1.1 UGI 追踪(UGI****从哪里来)
分析userUGI中是否具有访问冷数据集群的Token, 我们需要对UGI的来源进行跟踪。通过分析源码,我们发现UGI关联的User及Token(图中Credentials为工具类,用于读写存储在内存或磁盘中密钥和令牌)是通过解析LogAggregationServicer接收的APPLICATION_STARTED Event 得到的,具体跟踪流程如图4所示,其中Hander, Initializer为方便说明,抽象出来的对象。
根据时序图中访问流程,结合异常日志信息,可以确定异常原因的确userUGI没有访问远程集群的Toket(Credentials)
3.1.2 Credentials ( 或Tokens) 追踪(Creadential 从哪里来)
本节从Spark计算引擎的角度,对Credentials(或Tokens)来源进行追踪。通过分析yarn/Client源码,Client在启动AM (ApplicationMaster)前,会进行一系列准备工作。准备工作过程中存在与其它组件的通信,其中包括准备本地资源时(prepareLocalResources)与NN(NameNode)的通信:1)通过TGT 获取user-nn-ticket(Client启动在客户机,可以使用TGT) ;2)使用user-nn-ticket 访问NN,并获取Delegation Tokens. 获取到Tokens后会通过Credentials将Tokens(不含TGT)存储在ContainerLaunchContext中。并随同ApplicationSubmissionContext一起提交至Yarn,请求启动AM;Yarn收到请求后,会为其选择NodeManager,使用ContainerLaunchContext 拉起AM.
从上图可知,最后LogAggregationServicer可使用的Tokens是客户端(Agent)初始化时,获取的。换句话说,客户端获取了访问某NN的Token时,LogAggregationServicer才具有访问该NN的Token. 而默认情况下,客户端仅会获取fs.defaultFS(HADOOP_CONF:core-site.xml中配置),因此,跨集群访问时无访问日志集群的权限。
3.2 解决方案
通过上述分析可知,若想访问某服务,需具备以下一种条件:
1) 拥有该服务授予的合法Token.
2) 角色持用TGT(password认证或keytabs),可以通过Kerberos完成完整的服务认证。
基于以上分析,我们对日志分离认证问题提出了两种方案:
1) 各计算框架以个人用户独立认证
该方案的核心思想是向Yarn提交应用前,使客户端(Agent)获取所有必要的Token。客户端启动在使用kinit进行登录的客户机,因此其可使用TGT 完成Kerberos认证,并可以获取到任务想访问的服务(类2.1.1节流程)。
因此,针对日志分离跨集群认证问题,应使客户端在向Yarn提交应用前,获取到所有NN 的Token,以便传递到NM以用户身份进行日志聚集操作。
该方案需要在各计算引擎进行配置或修改,以使在提交应用前,获取到所需的Tokens.目前,Spark(“spark.yarn.access.namenodes”)及MR(“ mapreduce.job.hdfs-servers”)引擎,自带配制参数,用于指定额外的NN,以获取Tokens。其它引擎目前未进行调研。
2 )日志聚集功能模块以Yarn****用户统一认证
该方案的核心思想是使用NodeManager的启动用户Yarn进行日志聚集,从而使用Yarn统一进行认证。
NodeManager使用KeyTabs方式进行登录,其可以通过Kerberos认证访问所有服务(包括NN);另外,日志聚集功能,以AbstractService方式运行于NodeManger。因此,理论上可以使用NodeManager获取的Tokens 访问远程NN,创建日志目录或上传日志等。
日志聚集不仅包括日志上传等工作,还包括container本地日志清理工作,而Container日志的管理是以应用提交用户的名义进行的管理,若直接将UserUGI简单的更换成NodeManager LoginUGI,则日志后处理工作将无法进行,因此,我们采用Token劫持方案进行实现(若集群支持ProxyUser,可使用ProxyUser),即:使用用户的UGI + NodeManager 获取的Token方式进行实现,具体如下:
3.3 方案对比
表1 跨集群日志分离认证问题解决方案对比
综上,我们采用 日志聚集功能模块以Yarn用户统一认证 的方式来解决跨集群日志分离认证问题。
4 结论
本文分析了Hadoop Security的原理,提出了两种跨集群日志分离认证问题解决方案。并对比了两种方案的优劣,最终选用 日志聚集功能模块以Yarn用户统一认证方案 解决跨集群日志分离认证问题,现该方案已上线验证,截止目前运行良好。
基于Keepalived高可用集群的MariaDB读写分离机制实现
一 MariaDB读写分离机制
在实现读写分离机制之前先理解一下三种主从复制方式:
1.异步复制:
MariaDB默认的复制即是异步的,主库在执行完客户端提交的事务后会立即将结果返给给客户端,并不关心从库是否已经接收并处理,这样就会有一个问题,主节点如果挂掉了,此时主上已经提交的事务可能并没有传到从上,如果此时,强行将从提升为主,可能导致新主上的数据不完整。
2.全同步复制:
指当主库执行完一个事务,所有的从库都执行了该事务才返回给客户端。因为需要等待所有从库执行完该事务才能返回,所以全同步复制的性能必然会收到严重的影响。
3.半同步复制:
介于异步复制和全同步复制之间,主库在执行完客户端提交的事务后不是立刻返回给客户端,而是等待至少一个从库接收到并写到relay log中才返回给客户端。相对于异步复制,半同步复制提高了数据的安全性,同时它也造成了一定程度的延迟,这个延迟最少是一个TCP/IP往返的时间。所以,半同步复制最好在低延时的网络中使用。
在本次实验中我们采用一主两从的方式实现MySQL读写分离机制,而在主从复制中采用异步复制和半同复制两种方式来保证数据的安全性和完整性。为了保证读写分离器高可用,还可利用Keepalived实现高可用集群。
二 常用读写分离器的介绍
mysql-proxy:MySQL官方出品;
atlas:奇虎360公司二次开发产品;
amoeba:Alibaba集团开发的可实现读写分离、分片功能的读写分离器;
OneProxy:读写分离框架,由平民架构开发并维护;
ProxySQL:一款高性能读写分离器;
MaxScale:Mariadb官方,稳定可靠,比较有影响力。
本实验我们采用ProxySQL来实现读写分离。
三 架构拓扑图
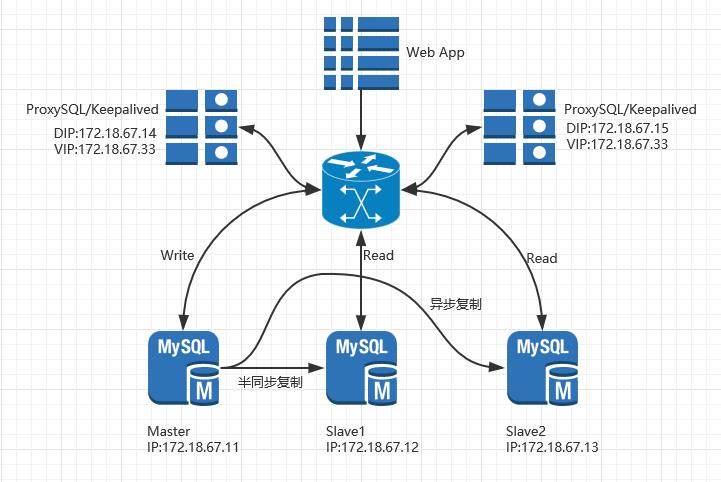
四 主从复制配置
#分别在三台主从节点配置如下的内容 [root@node1 ~]# vim /etc/my.cnf.d/server.cnf [mysqld] skip_name_resolve=ON innodb_file_per_table=ON server_id=1 log_bin=mysql-bin [root@node2 ~]# vim /etc/my.cnf.d/server.cnf [mysqld] skip_name_resolve=ON innodb_file_per_table=ON server_id=2 relay_log=relay-log [root@node3 ~]# vim /etc/my.cnf.d/server.cnf [mysqld] skip_name_resolve=ON innodb_file_per_table=ON server_id=3 relay_log=relay-log #启动MariaDB服务 [root@node1 ~]# systemctl start mariadb.service #登入MariaDB [root@node1 ~]# mysql MariaDB [(none)]> SHOW MASTER STATUS; +------------------+----------+--------------+------------------+ | File | Position | Binlog_Do_DB | Binlog_Ignore_DB | +------------------+----------+--------------+------------------+ | mysql-bin.000003 | 245 | | | +------------------+----------+--------------+------------------+ #创建MariaDB复制账号 MariaDB [(none)]> GRANT REPLICATION SLAVE,REPLICATION CLIENT ON *.* TO \'repluser\'@\'172.18.67.%\' IDENTIFIED BY \'replpass\'; #安装半同步主从复制插件并启动主从复制功能 MariaDB [(none)]> INSTALL PLUGIN rpl_semi_sync_master SONAME \'semisync_master.so\'; MariaDB [(none)]> SET @@global.rpl_semi_sync_master_enabled=ON; #启动MariaDB服务 [root@node2 ~]# systemctl start mariadb.service #登入MariaDB [root@node2 ~]# mysql #安装半同步主从复制插件并启动主从复制功能 MariaDB [(none)]> INSTALL PLUGIN rpl_semi_sync_slave SONAME \'semisync_slave.so\'; MariaDB [(none)]> set @@global.rpl_semi_sync_slave_enabled=ON; #配置slave1节点的master节点 MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST=\'172.18.67.11\',MASTER_USER=\'repluser\',MASTER_PASSWORD=\'replpass\',MASTER_LOG_FILE=\'mysql-bin.000003\',MASTER_LOG_POS=442; MariaDB [(none)]> START SLAVE; MariaDB [(none)]> SHOW SLAVE STATUS\\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 172.18.67.11 Master_User: repluser Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000003 Read_Master_Log_Pos: 422 Relay_Log_File: relay-log.000002 Relay_Log_Pos: 529 Relay_Master_Log_File: mysql-bin.000003 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 422 Relay_Log_Space: 817 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 1 #启动MariaDB服务 [root@node3 ~]# systemctl start mariadb.service #登入MariaDB [root@node3 ~]# mysql #配置slave2节点的master节点 MariaDB [(none)]> CHANGE MASTER TO MASTER_HOST=\'172.18.67.11\',MASTER_USER=\'repluser\',MASTER_PASSWORD=\'replpass\',MASTER_LOG_FILE=\'mysql-bin.000003\',MASTER_LOG_POS=442; MariaDB [(none)]> START SLAVE; MariaDB [(none)]> SHOW SLAVE STATUS\\G; *************************** 1. row *************************** Slave_IO_State: Waiting for master to send event Master_Host: 172.18.67.11 Master_User: repluser Master_Port: 3306 Connect_Retry: 60 Master_Log_File: mysql-bin.000003 Read_Master_Log_Pos: 422 Relay_Log_File: relay-log.000002 Relay_Log_Pos: 529 Relay_Master_Log_File: mysql-bin.000003 Slave_IO_Running: Yes Slave_SQL_Running: Yes Replicate_Do_DB: Replicate_Ignore_DB: Replicate_Do_Table: Replicate_Ignore_Table: Replicate_Wild_Do_Table: Replicate_Wild_Ignore_Table: Last_Errno: 0 Last_Error: Skip_Counter: 0 Exec_Master_Log_Pos: 422 Relay_Log_Space: 817 Until_Condition: None Until_Log_File: Until_Log_Pos: 0 Master_SSL_Allowed: No Master_SSL_CA_File: Master_SSL_CA_Path: Master_SSL_Cert: Master_SSL_Cipher: Master_SSL_Key: Seconds_Behind_Master: 0 Master_SSL_Verify_Server_Cert: No Last_IO_Errno: 0 Last_IO_Error: Last_SQL_Errno: 0 Last_SQL_Error: Replicate_Ignore_Server_Ids: Master_Server_Id: 1 #进行测试 [root@node1 ~]# mysql -e "SHOW GLOBAL STATUS LIKE \'%semi%\'" | grep \'Rpl_semi_sync_master_clients\' Rpl_semi_sync_master_clients 1 #在主节点创建数据库mydb [root@node1 ~]# mysql -e "CREATE DATABASE mydb;" #在从节点查看主节点创建的数据库mydb是否复制过来 [root@node2 ~]# mysql -e "SHOW DATABASES;" | grep mydb mydb [root@node3 ~]# mysql -e "SHOW DATABASES;" | grep mydb mydb #从节点已经将主节点创建的数据库复制过来了
五 读写分离ProxySQL的配置
1.节点一
[root@node4 ~]# vim /etc/proxysql.cnf
datadir="/var/lib/proxysql"
admin_variables=
{
admin_credentials="admin:admin"
mysql_ifaces="127.0.0.1:6032;/tmp/proxysql_admin.sock"
}
mysql_variables=
{
threads=4
max_connections=2048
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:3306;/tmp/mysql.sock"
default_schema="information_schema"
stacksize=1048576
server_version="5.5.30"
connect_timeout_server=3000
monitor_history=600000
monitor_connect_interval=60000
monitor_ping_interval=10000
monitor_read_only_interval=1500
monitor_read_only_timeout=500
ping_interval_server=120000
ping_timeout_server=500
commands_stats=true
sessions_sort=true
connect_retries_on_failure=10
}
mysql_servers =
(
{
address = "172.18.67.11" # no default, required . If port is 0 , address is interpred as a Unix Socket Domain
port = 3306 # no default, required . If port is 0 , address is interpred as a Unix Socket Domain
hostgroup = 0 # no default, required
status = "ONLINE" # default: ONLINE
weight = 1 # default: 1
compression = 0 # default: 0
},
{
address = "172.18.67.12"
port = 3306
hostgroup = 1
status = "ONLINE" # default: ONLINE
weight = 1 # default: 1
compression = 0 # default: 0
},
{
address = "172.18.67.13"
port = 3306
hostgroup = 1
status = "ONLINE" # default: ONLINE
weight = 1 # default: 1
compression = 0 # default: 0
}
)
mysql_users:
(
{
username = "root"
password = "mrlapulga"
default_hostgroup = 0
max_connections=1000
active = 1
}
)
mysql_replication_hostgroups=
(
{
writer_hostgroup=0
reader_hostgroup=1
}
)
#在主节点对用户进行授权:
MariaDB [(none)]> GRANT ALL ON *.* TO \'root\'@\'172.18.67.%\' IDENTIFIED BY \'mrlapulga\';
MariaDB [(none)]> FLUSH PRIVILEGES;
#启动读写分离器的节点1
[root@node4 ~]# systemctl start proxysql
#使用管理接口验证:
[root@node4 ~]# mysql -uadmin -h127.0.0.1 -padmin -P6032
MySQL [(none)]> SELECT hostgroup_id,hostname,hostname,status FROM mysql_servers;
+--------------+--------------+--------------+--------+
| hostgroup_id | hostname | hostname | status |
+--------------+--------------+--------------+--------+
| 0 | 172.18.67.11 | 172.18.67.11 | ONLINE |
| 1 | 172.18.67.12 | 172.18.67.12 | ONLINE |
| 1 | 172.18.67.13 | 172.18.67.13 | ONLINE |
+--------------+--------------+--------------+--------+
#测试读操作
[root@node4 ~]# mysql -uroot -pmrlapulga -h 127.0.0.1 -P3306
MySQL [OA]> use mydb;
MySQL [mydb]> DESC tbl1;
+-------+---------------------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+-------+---------------------+------+-----+---------+----------------+
| id | tinyint(3) unsigned | NO | PRI | NULL | auto_increment |
| name | char(20) | YES | | NULL | |
+-------+---------------------+------+-----+---------+----------------+
#测试写操作,在proxysql节点插入一条字段
MySQL [mydb]> INSERT INTO mydb.tbl1 (name) VALUES (\'jack\');
#在从节点一查看
[root@node2 ~]# mysql -e "SELECT * FROM mydb.tbl1;"
+----+------+
| id | name |
+----+------+
| 1 | jack |
+----+------+
#在从节点二查看
[root@node3 ~]# mysql -e "SELECT * FROM mydb.tbl1;"
+----+------+
| id | name |
+----+------+
| 1 | jack |
+----+------+
2.节点二
#将配置文件复制到ProxySQL节点二 [root@node4 ~]# scp /etc/proxysql.cnf 172.18.67.15:/etc/ #启动节点二的服务 [root@node5 ~]# systemctl start proxysql
六 配置高可用集群
#在ProxySQL1节点配置keepalived
[root@node4 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id proxysql
vrrp_macst_group4 224.0.67.67
}
vrrp_instance HA_mysql {
state MASTER
interface eno16777736
virtual_router_id 67
priority 100
advert_int 1
authentication {
auth_type PASS
auth_pass lKZvQVv9
}
virtual_ipaddress {
172.18.67.33/16 dev eno16777736
}
}
[root@node4 ~]# systemctl start keepalived
#在ProxySQL2节点配置keepalived
[root@node5 ~]# vim /etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
notification_email_from keepalived@localhost
smtp_server 127.0.0.1
smtp_connect_timeout 30
router_id proxysql
vrrp_macst_group4 224.0.67.67
}
vrrp_instance HA_mysql {
state BACKUP
interface eno16777736
virtual_router_id 67
priority 98
advert_int 1
authentication {
auth_type PASS
auth_pass lKZvQVv9
}
virtual_ipaddress {
172.18.67.33/16 dev eno16777736
}
}
[root@node5 ~]# systemctl start keepalived
七 测试
#在ProxySQL节点1登录MySQL [root@node4 ~]# mysql -uroot -h172.18.67.33 -pmrlapulga -P 3306 MySQL [(none)]> use mydb; #查看数据库及表 MySQL [mydb]> SELECT * FROM tbl1; +----+------+ | id | name | +----+------+ | 1 | jack | +----+------+ #在ProxySQL节点2登录MySQL [root@node5 ~]# mysql -uroot -h172.18.67.33 -pmrlapulga -P 3306 MySQL [(none)]> use mydb; #查看数据库及表 MySQL [mydb]> SELECT * FROM tbl1; +----+------+ | id | name | +----+------+ | 1 | jack | +----+------+ #测试在ProxySQL1节点写操作 MySQL [mydb]> CREATE TABLE tbl2 (id TINYINT UNSIGNED NOT NULL AUTO_INCREMENT, name CHAR(20) NOT NULL, PRIMARY KEY(id)); #分别在两个从节点查看 [root@node2 ~]# mysql -e "DESC mydb.tbl2;" +-------+---------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+---------------------+------+-----+---------+----------------+ | id | tinyint(3) unsigned | NO | PRI | NULL | auto_increment | | name | char(20) | NO | | NULL | | +-------+---------------------+------+-----+---------+----------------+ [root@node3 ~]# mysql -e "DESC mydb.tbl2;" +-------+---------------------+------+-----+---------+----------------+ | Field | Type | Null | Key | Default | Extra | +-------+---------------------+------+-----+---------+----------------+ | id | tinyint(3) unsigned | NO | PRI | NULL | auto_increment | | name | char(20) | NO | | NULL | | +-------+---------------------+------+-----+---------+----------------+
以上是关于Hadoop Security机制下跨集群日志分离认证问题解决方案的主要内容,如果未能解决你的问题,请参考以下文章
Nginx之反向代理日志格式集群缓存压缩URl 重写,读写分离配置
开发环境Vue访问后端代码(前后端分离开发,端口不同下跨域访问)
cloudera learning6:Hadoop Security