hadoop离线day07--Hadoop YARNHA机制
Posted Vics异地我就
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了hadoop离线day07--Hadoop YARNHA机制相关的知识,希望对你有一定的参考价值。
目录
今日内容大纲
#HDFS
安全模式
#Hadoop集群动态扩容与缩容 运维
#Hadoop YARN
介绍:集群资源管理 任务调度
3大组件 架构
程序在yarn运行流程:以mr程序提交为例
yarn调度器
核心调度策略(算法)
Fair调度:多租户资源隔离问题 运维
#Hadoop HA集群
高可用概念 持续可用 一直可用
解决单点故障问题 主备集群
Hadoop: NN RM
Hadoop HA实现方案--QJM
搭建HA集群
#Hadoop federation联邦集群
#今日课程重点:
YARN HA
对于涉及运维操作 听清原理很重要 可以不实操HDFS 安全模式
-
安全模式(safe mode)是HDFS集群处于一种保护状态,文件系统只可以读,不可以写。
-
安全模式如何进入离开的?
-
自动进入离开
#在HDFS集群刚启动时候 会自动进入 为了演示方便 使用单个进程逐个启动方式 #step1:启动namenode hadoop-daemon.sh start namenode #step2: 执行事务性操作 报错 [root@node1 ~]# hadoop fs -mkdir /aaaa mkdir: Cannot create directory /aaaa. Name node is in safe mode. Safe mode is ON. The reported blocks 0 needs additional 52 blocks to reach the threshold 0.9990 of total blocks 52. The number of live datanodes 0 has reached the minimum number 0. Safe mode will be turned off automatically once the thresholds have been reached. #1、条件1:已经汇报的block达到总数据块的 0.999 #2、条件2:存活的dn数量大于等于0 说明这个条件不严格 #step3:依次手动启动datanode hadoop-daemon.sh start datanode Safe mode is ON. The reported blocks 52 has reached the threshold 0.9990 of total blocks 52. The number of live datanodes 2 has reached the minimum number 0. In safe mode extension. Safe mode will be turned off automatically in 25 seconds. #3、条件3:满足12条件的情况下 持续30s 结束自动离开安全模式 Safemode is off. #为什么集群刚启动的时候 要进入安全模式 文件系统元数据不完整 无法对外提供可高的文件服务 属于内部的元数据汇报、校验、构建的过程。 -
手动进入离开
hdfs dfsadmin -safemode enter hdfs dfsadmin -safemode leave Safe mode is ON. It was turned on manually. Use "hdfs dfsadmin -safemode leave" to turn safe mode off. #运维人员可以手动进入安全模式 进行集群的维护升级等动作 避免了群起群停浪费时间。
-
-
安全模式的注意事项
-
刚启动完hdfs集群之后 等安全模式介绍才可以正常使用文件系统 文件系统服务才是正常可用。
-
后续如果某些软件依赖HDFS工作,必须先启动HDFS且等安全模式结束才可以使用你的软件。
-
Hadoop集群动态扩容、缩容
-
所谓动态扩容、缩容指的是集群在正常的运行下、增加节点、删除节点
-
其他称呼:节点上线、节点下线 节点服役 节点退役
-
针对的角色是谁
-
HDFS datanode
-
YARN nodemanager
-
-
集群扩容
-
新机器的服务器基础环境和已有集群保存一致
ip处于同一网段 hosts 防火墙关闭 -
把已有集群的安装包scp一份到新机器上
-
手动启动新集群上的角色
hadoop-daemon.sh start datanode yarn-daemon.sh start nodemanager -
集群负载均衡服务
hdfs dfsadmin -setBalancerBandwidth 67108864 sbin/start-balancer.sh -threshold 5 -
Q:可选机制 白名单机制
dfs.hosts 指向一个文件,只有文件列表中的机器才可以加入集群 准入机制 默认值为空,所有的机器都允许加入集群
-
-
集群缩容
-
需要添加黑名单 列出待下线的节点的IP
dfs.hosts.exclude -
刷新集群信息
hdfs dfsadmin -refreshNodes yarn rmadmin -refreshNodes #等待节点的状态变成 decommissioned 正式停用的 -
手动关闭节点进程
-
还可以针对已有的节点再进行负载均衡
-
-
扩展:在Hadoop3 还支持在同一个机器上不同的磁盘之间的负载均衡。 disk balancer
Apache YARN
-
YARN的概述
-
yarn是一个通用资源管理系统和调度平台。 详细解释见课堂画图
资源指的跟程序运行相关的硬件资源 比如:CPU RAM
-
-
YARN组件--3大组件
-
物理层面上-2个组件
-
主角色 resourcemanager RM
ResourceManager 负责整个集群的资源管理和分配,是一个全局的资源管理系统。 是程序申请资源的唯一入口 负载调度。 -
从角色 nodemanager NM
nodemanager 负责每台机器上具体的资源管理 负责启动 关闭container容器
-
-
程序内部--1个组件
-
ApplicationMaster AM
yarn作为通用资源管理系统 不关心程序的种类和程序内部的执行情况? 谁来关心程序内部执行情况? 比如MapReduce程序来说,先maptask 再运行reducetask. 需要一个组件来管理程序执行情况 程序内部的资源申请 各阶段执行情况的监督 #为了解决这个问题 yarn提供了第三个组件 applicationmaster (男)主人,雇主; 主宰; 主人; 有控制力的人; 能手; 擅长…者; #把applicationmaster称之为程序内部的老大角色 负责程序内部的执行情况 #AM针对不同类型的程序有不同的具体实现 yarn默认实现了MapReduce的AM 名字叫做MrAppMaster. 其他软件比如spark flink需要实现自己的AM 才能在yarn运行。 #结论:在上述设计模式下 任何种类程序在yarn运行,首先都是申请资源运行AM角色,然后由AM控制程序内部具体的执行。 -
-
-
client提交程序到yarn运行流程
-
以MapReduce程序为例
-
-
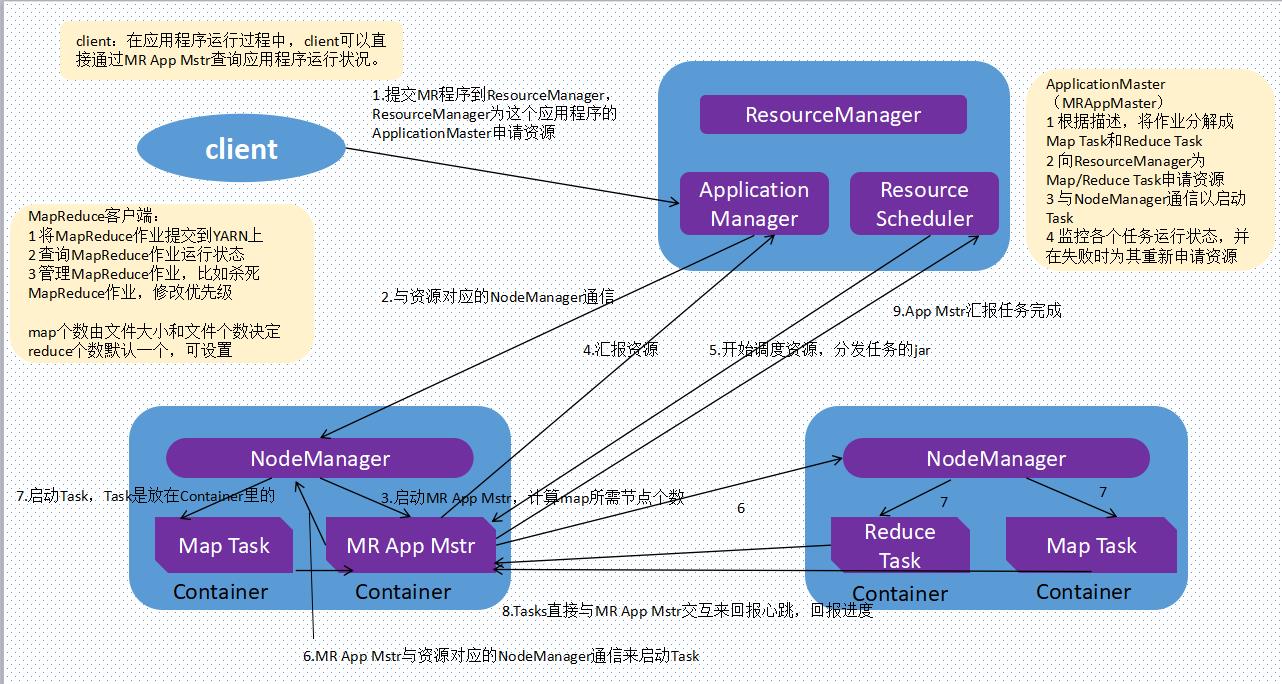
YARN schduler
-
所谓的调度器指的是当集群繁忙的时候 如何给申请资源的程序分配资源
-
scheduler属于ResourceManager功能
-
YARN3大调度策略
-
FIFO Scheduler 先进先出策略
-
capacity Scheduler 容量调度策略
-
Fair Sheduler 公平调度策略
-
-
Apache Hadoop版本默认策略是capacity 。CDH商业版本默认策略是Fair。
-
默认情况下,整个yarn集群在capacity策略下,划分为一个队列 名字叫做default,占整个集群资源的100.
-
-
决定调度策略的参数
#yarn-site.xml yarn.resourcemanager.scheduler.class=org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler #还可以在yarn 8088页面查看 -
案例:Fair调度器多租户资源隔离
-
给不同的用户划分不同的队列 实现资源隔离并且共享集群资源
-
属于大数据运维操作。
-
听到原理即可,可以不实操。因为我们使用的是虚拟机环境,每个机器的内存本来就小的可怜,你在划分4个不同的队列,后面的程序都凉凉。
-
你可以练习完之后 恢复成之前的样子。
#1、关闭yarn集群 stop-yarn.sh #2、删除yarn-site.xml中增加的参数 #3、同步yarn-site.xml到其他机器上
-
Hadoop HA集群
-
HA叫做高可用模式 注意解决的是单点故障问题。 SPOF
-
Hadoop中单点故障
-
NameNode
-
Resourcemanager
-
-
NameNode HA ---QJM共享日志集群方案
-
zkfc 实现主备切换避免脑裂
-
jn集群 editslog编辑日志同步
-
-
Resourcemanager HA --基于zk实现
-
RM需要维护的数据量很少 不像NN需要同步文件系统大量的元数据。直接基于zk即可完成
-
别忘了 zk也是一个分布式小文件存储系统。
-
-
Hadoop HA集群搭建 难点就是配置文件的编写
-
听懂原理 可以不搭建 后面使用非HA集群。
-
针对当下集群进行逻辑删除 备份
-
使用新的安装包进行编辑
-
-
HA 主备切换错误 缺少依赖
2021-05-30 17:02:40,372 WARN org.apache.hadoop.ha.SshFenceByTcpPort: PATH=$PATH:/sbin:/usr/sbin fuser -v -k -n tcp 8020 via ssh: bash: fuser: command not found #yum install -y fuser 猜想行为 yum install -y psmisc
以上是关于hadoop离线day07--Hadoop YARNHA机制的主要内容,如果未能解决你的问题,请参考以下文章