C++产生随机数的
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C++产生随机数的相关的知识,希望对你有一定的参考价值。
#include <iostream.h>
#include <stdlib.h>
void main()
int a = rand()%10;
int b = rand()%100;
int temp;
temp=int(b/a);
for(int i=0;i<10;i++)
cout<<a<<'\\'<<b<<"="<<temp<<endl;
我看书自学的,不知道rand()这个到底怎么用?
我这样写为什么10次的结果都是一样的呢?
rand()%100;产生0-99的随机数。高级点的,假如要产生16-59之间的数,你可以这样写:rand()%44+16(这里44由59-16+1得到)。其他情况如法炮制!
下面是搜回来的:
问题1: 怎样获得一个真正的随机数?要知道,rand()是不能产生真正的随机数的!即使不能产生真正的随机数,也要大概接近呀!而rand()好象每次的随机都一样。
专家解答:
之所以rand()每次的随机数都一样是因为rand()函数使用不正确。各种编程语言返回的随机数(确切地说是伪随机数)实际上都是根据递推公式计算的一组数值,当序列足够长,这组数值近似满足均匀分布。如果计算伪随机序列的初始数值(称为种子)相同,则计算出来的伪随机序列就是完全相同的。这个特性被有的软件利用于加密和解密。加密时,可以用某个种子数生成一个伪随机序列并对数据进行处理;解密时,再利用种子数生成一个伪随机序列并对加密数据进行还原。这样,对于不知道种子数的人要想解密就需要多费些事了。当然,这种完全相同的序列对于你来说是非常糟糕的。要解决这个问题,需要在每次产生随机序列前,先指定不同的种子,这样计算出来的随机序列就不会完全相同了。你可以在调用rand()函数之前调用srand( (unsigned)time( NULL ) ),这样以time函数值(即当前时间)作为种子数,因为两次调用rand函数的时间通常是不同的,这样就可以保证随机性了。你也可以使用srand函数来人为指定种子数。Windows 9x/NT的游戏FreeCell就允许用户指定种子数,这样用户如果一次游戏没有成功,下次还可以以同样的发牌结果再玩一次。
问题2: 我按照上述方法并不能产生随机数,仅产生公差为3或4的等差数列:
#include <stdlib.h>
#include <iostream.h>
#include <conio.h>
#include <time.h>
void main()
for(int i=0;i<100000;i++)
srand( (unsigned)time( NULL ) );
cout<<rand()<<endl;
专家解答:
你的程序是有问题的,你每产生一个随机数之前,都调用一次srand,而由于计算机运行很快,所以你每次用time得到的时间都是一样的(time的时间精度较低,只有55ms)。这样相当于使用同一个种子产生随机序列,所以产生的随机数总是相同的。你应该把srand放在循环外:
srand( (unsigned)time( NULL ) );
for(int i=0;i<100000;i++)
//相关语句
参考技术B
1、第一步,先定义int一个数组和int一个指针变量。
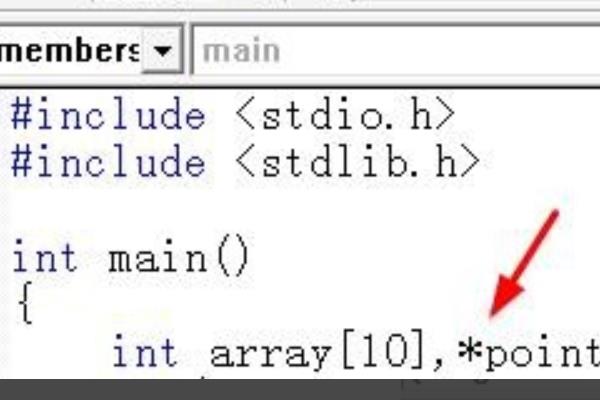
2、接着我们选择让指针指向数组的第一元素的地址。
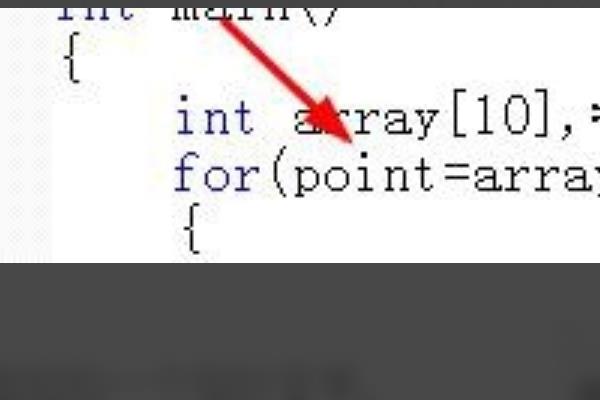
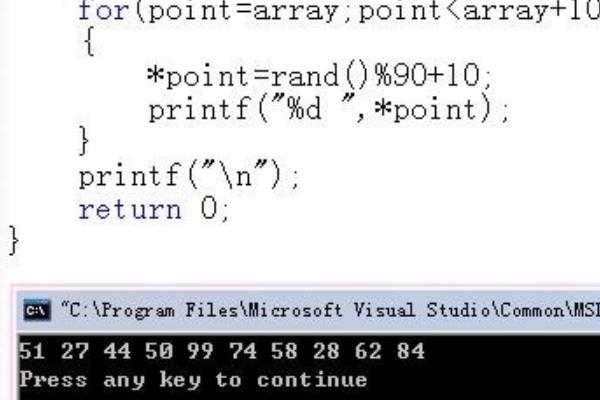
3、接着使循环的条件为指针的尾地址。

4、并且因为这段代码每次循环后指针+1。

5、最后,让他进行输出。

6、最后编译运行完成后,便可以看到运行结果。
C++中常用rand()函数生成随机数,但严格意义上来讲生成的只是伪随机数(pseudo-random integral number)。生成随机数时需要我们指定一个种子,如果在程序内循环,那么下一次生成随机数时调用上一次的结果作为种子。但如果分两次执行程序,那么由于种子相同,生成的“随机数”也是相同的。
在工程应用时,我们一般将系统当前时间(Unix时间)作为种子,这样生成的随机数更接近于实际意义上的随机数。给一下例程如下:
#include <iostream>
#include <ctime>
#include <cstdlib>
using namespace std;
int main()
double random(double,double);
srand(unsigned(time(0)));
for(int icnt = 0; icnt != 10; ++icnt)
cout << "No." << icnt+1 << ": " << int(random(0,10))<< endl;
return 0;
double random(double start, double end)
return start+(end-start)*rand()/(RAND_MAX + 1.0);
/* 运行结果
* No.1: 3
* No.2: 9
* No.3: 0
* No.4: 9
* No.5: 5
* No.6: 6
* No.7: 9
* No.8: 2
* No.9: 9
* No.10: 6
*/
利用这种方法能不能得到完全意义上的随机数呢?似乎9有点多哦?却没有1,4,7?!我们来做一个概率实验,生成1000万个随机数,看0-9这10个数出现的频率是不是大致相同的。程序如下:
#include <iostream>
#include <ctime>
#include <cstdlib>
#include <iomanip>
using namespace std;
int main()
double random(double,double);
int a[10] = ;
const int Gen_max = 10000000;
srand(unsigned(time(0)));
for(int icnt = 0; icnt != Gen_max; ++icnt)
switch(int(random(0,10)))
case 0: a[0]++; break;
case 1: a[1]++; break;
case 2: a[2]++; break;
case 3: a[3]++; break;
case 4: a[4]++; break;
case 5: a[5]++; break;
case 6: a[6]++; break;
case 7: a[7]++; break;
case 8: a[8]++; break;
case 9: a[9]++; break;
default: cerr << "Error!" << endl; exit(-1);
for(int icnt = 0; icnt != 10; ++icnt)
cout << icnt << ": " << setw(6) << setiosflags(ios::fixed) << setprecision(2) << double(a[icnt])/Gen_max*100 << "%" << endl;
return 0;
double random(double start, double end)
return start+(end-start)*rand()/(RAND_MAX + 1.0);
/* 运行结果
* 0: 10.01%
* 1: 9.99%
* 2: 9.99%
* 3: 9.99%
* 4: 9.98%
* 5: 10.01%
* 6: 10.02%
* 7: 10.01%
* 8: 10.01%
* 9: 9.99%
*/
可知用这种方法得到的随机数是满足统计规律的。
另:在Linux下利用GCC编译程序,即使我执行了1000000次运算,是否将random函数定义了inline函数似乎对程序没有任何影响,有理由相信,GCC已经为我们做了优化。但是冥冥之中我又记得要做inline优化得加O3才行...
不行,于是我们把循环次数改为10亿次,用time命令查看执行时间:
chinsung@gentoo ~/workspace/test/Debug $ time ./test
0: 10.00%
1: 10.00%
2: 10.00%
3: 10.00%
4: 10.00%
5: 10.00%
6: 10.00%
7: 10.00%
8: 10.00%
9: 10.00%
real 2m7.768s
user 2m4.405s
sys 0m0.038s
chinsung@gentoo ~/workspace/test/Debug $ time ./test
0: 10.00%
1: 10.00%
2: 10.00%
3: 10.00%
4: 10.00%
5: 10.00%
6: 10.00%
7: 10.00%
8: 10.00%
9: 10.00%
real 2m7.269s
user 2m4.077s
sys 0m0.025s
前一次为进行inline优化的情形,后一次为没有作inline优化的情形,两次结果相差不大,甚至各项指标后者还要好一些,不知是何缘由...
本回答被提问者和网友采纳 参考技术D 具体代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <time.h> //用到了time函数
int main()
int i,number;
srand((unsigned) time(NULL)); //用时间做种,每次产生随机数不一样
for (i=0; i<50; i++)
number = rand() % 101; //产生0-100的随机数
printf("%d ", number);
return 0;
有以下几种情况:
(1) 如果你只要产生随机数而不需要设定范围的话,你只要用rand()就可以了:rand()会返回一随机数值, 范围在0至RAND_MAX 间。RAND_MAX定义在stdlib.h, 其值为2147483647。
(2) 如果你要随机生成一个在一定范围的数,你可以在宏定义中定义一个random(int number)函数,然后在main()里面直接调用random()函数:
例如:
rand()%100是产生0-99的随机数。
(3)但是上面两个例子所生成的随机数都只能是一次性的,如果你第二次运行的时候输出结果仍和第一次一样。这与srand()函数有关。srand()用来设置rand()产生随机数时的随机数种子。在调用rand()函数产生随机数前,必须先利用srand()设好随机数种子(seed), 如果未设随机数种子, rand()在调用时会自动设随机数种子为1。上面的两个例子就是因为没有设置随机数种子,每次随机数种子都自动设成相同值1 ,进而导致rand()所产生的随机数值都一样。
srand()函数定义 : void srand (unsigned int seed);
通常可以利用geypid()或time(0)的返回值来当做seed。如果你用time(0)的话,要加入头文件#include<time.h>
C++产生随机数
站在巨人的肩膀上!
c++随机数生成函数rand(),实质生成伪随机数列。
c/c++ 产生随机数函数介绍及用法
1) 给srand()提供一个种子,它是一个unsigned int类型;
2) 调用rand(),它会根据提供给srand()的种子值返回一个随机数(在0到RAND_MAX之间);
3) 根据需要多次调用rand(),从而不间断地得到新的随机数;
4) 无论什么时候,都可以给srand()提供一个新的种子,从而进一步“随机化”rand()的输出结果。
#include <stdlib.h>
#include <time.h>
using namespace std;
int main()
{
srand((unsigned)time(NULL));
for(int i = 0; i < 10;i++ )
cout << rand() << ‘\\t‘;
cout << endl;
return 0;
}
要取得[a,b)的随机整数,使用(rand() % (b-a))+ a;
要取得[a,b]的随机整数,使用(rand() % (b-a+1))+ a;
要取得(a,b]的随机整数,使用(rand() % (b-a))+ a + 1;
通用公式:a + rand() % n;其中的a是起始值,n是整数的范围。
要取得a到b之间的随机整数,另一种表示:a + (int)b * rand() / (RAND_MAX + 1)。
要取得0~1之间的浮点数,可以使用rand() / double(RAND_MAX)。
http://hi.baidu.com/silyt/blog/item/f1a0bf03e0784ce809fa9309.html
如果让你用C++来生成0——N-1之间的随机数,你会怎么做?你可能会说,很简单,看:
srand( (unsigned)time( NULL ) );
rand() % N;
仔细想一下,这个结果是随机的吗(当然,我们不考虑rand()函数的伪随机性)?
不是的,因为rand()的上限是RAND_MAX,而一般情况下,RAND_MAX并不是N的整数倍,那么如果RAND_MAX % = r,则0——r之间的数值的概率就要大一些,而r+1——N-1之间的数值的概率就要小一些。还有,如果N > RAND_MAX,那该怎么办?
下面给出一种比较合适的方案,可以生成任意范围内的等概率随机数 result。最后还有一个更简单的方法。
1、如果N<RAND_MAX+1,则要去除尾数,
R = RAND_MAX-(RAND_MAX+1)%N; //去除尾数
t = rand();
while( t > R ) t = rand();
result = t % N; // 符合要求的随机数
2、如果 N>RAND_MAX,可以考虑分段抽样,分成[n/(RNAD_MAX+1)]段,先等概率得到段再得到每段内的某个元素,这样分段也类似地有一个尾数问题,不是每次都刚好分到整数段,一定或多或少有一个余数段,这部分的值如何选取?
选到余数段的数据拿出来选取,先进行一次选到余数段概率的事件发生,然后进行单独选取:
r = N % (RAND_MAX+1); //余数
if ( happened( (double)r/N ) )//选到余数段的概率
result = N-r+myrandom(r); // myrandom可以用情况1中的代码实现
else
result = rand()+myrandom(N/(RAND_MAX+1))*(RAND_MAX+1); // 如果选不到余数段再进行分段选取
完整的代码:
#include<iostream.h>
#include<time.h>
#include<stdlib.h>
const double MinProb=1.0/(RAND_MAX+1);
bool happened(double probability)//probability 0~1
{
if(probability<=0)
{
return false;
}
if(probability<MinProb)
{
return rand()==0&&happened(probability*(RAND_MAX+1));
}
if(rand()<=probability*(RAND_MAX+1))
{
return true;
}
return false;
}
long myrandom(long n)//产生0~n-1之间的等概率随机数
{
t=0;
if(n<=RAND_MAX)
{
long R=RAND_MAX-(RAND_MAX+1)%n;//尾数
t = rand();
while ( t > r )
{
t = rand();
}
return t % n;
}
else
{
long r = n%(RAND_MAX+1);//余数
if( happened( (double)r/n ) )//取到余数的概率
{
return n-r+myrandom(r);
}
else
{
return rand()+myrandom(n/(RAND_MAX+1))*(RAND_MAX+1);
}
}
}
还有另外一种非常简单的方式,那就是使用
random_shuffle( RandomAccessIterator _First, RandomAccessIterator _Last ).
例如,生成0——N-1之间的随机数,可以这么写
#include <algorithm>
#include <vector>
long myrandom( long N )
{
std::vector<long> vl( N ); // 定义一个大小为N的vector
for ( long i=0; i<N; ++i )
{
vl[i] = i;
}
std::random_shuffle( vl.begin(), vl.end() );
return (*vl.begin());
}
random_shuffle 还有一个三参数的重载版本
random_shuffle( RandomAccessIterator _First, RandomAccessIterator _Last, RandomNumberGenerator& _Rand )
第三个参数可以接受一个自定义的随机数生成器来把前两个参数之间的元素随机化。
这个方法的缺陷就是,如果只是需要一个随机数的话,当N很大时,空间消耗很大!
以上是关于C++产生随机数的的主要内容,如果未能解决你的问题,请参考以下文章